Recentemente, por necessidade, examinei todas as vagas para desenvolvedores Go, e metade delas (pelo menos) menciona a plataforma de processamento de mensagens
Apache Kafka e o banco de dados
Redis NoSQL. Bem, todo mundo, é claro, quer que o candidato conheça Docker e outros como ele. Todos esses requisitos para nós, que viram as opiniões dos engenheiros de sistemas, parecem de alguma forma mesquinhos ou algo assim. Bem, de fato, como uma linha difere da outra? A situação com os bancos de dados NoSQL é, obviamente, mais diversificada, mas ainda parece mais simples do que qualquer MS SQL Server. Tudo isso, é claro, é o meu efeito pessoal, o
efeito Dunning-Kruger , mencionado muitas vezes no Habré.
Portanto, como todos os empregadores exigem, é necessário estudar essas tecnologias. Mas começar com a leitura de toda a documentação do começo ao fim não é muito interessante. Na minha opinião, é mais produtivo ler a introdução, criar um protótipo funcional, corrigir erros, encontrar problemas, resolvê-los. E depois de tudo isso, com compreensão, leia a documentação ou até um livro separado.

Aqueles que estiverem interessados em um curto período de tempo para se familiarizar com os recursos básicos desses produtos, por favor, continue lendo.
O programa de treinamento incluirá números. Ele consistirá em um grande gerador de números, um processador de números, uma fila, armazenamento de colunas e um servidor da web.
Durante o desenvolvimento, os seguintes padrões de design serão aplicados:
A arquitetura do sistema ficará assim:
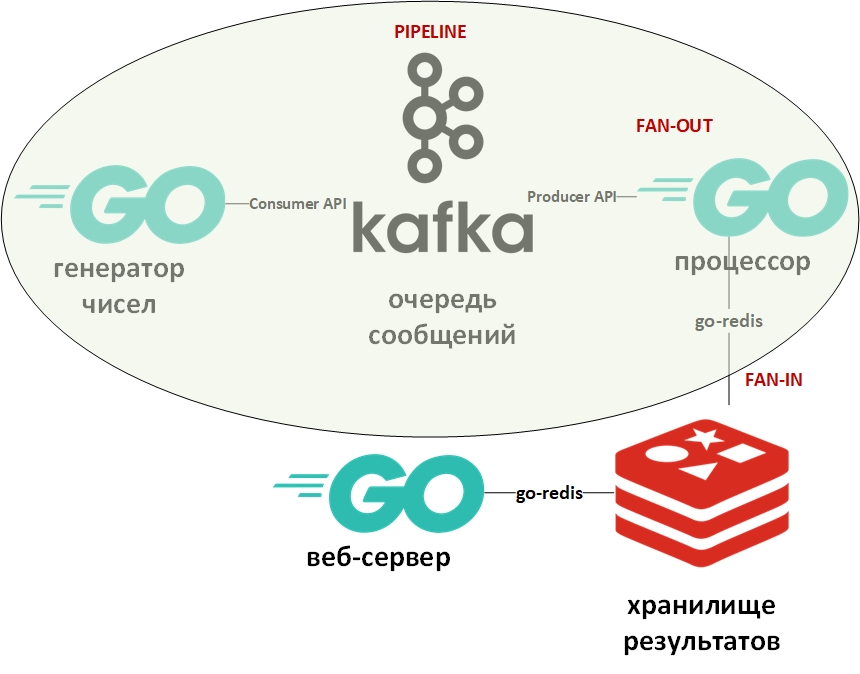
Na figura, o oval indica o padrão de design do transportador. Vou me debruçar sobre isso em mais detalhes.
O modelo "transportador" pressupõe que as informações venham na forma de um fluxo e sejam processadas em etapas. Geralmente, há algum gerador (fonte de informação) e um ou mais processadores (processadores de informação). Nesse caso, o gerador será um programa no Go que enfileira números grandes aleatórios. E o processador (o único) será um programa que coleta dados da fila e realiza a fatoração. No Go puro, esse padrão é muito fácil de implementar usando canais (chan). Acima, há um link para o meu github com um exemplo. Aqui, a fila de mensagens desempenhará o papel de canais.
Os modelos Fan-In - Fan-Out geralmente são usados juntos e, conforme aplicado ao Go, significam paralelização de cálculos usando goroutines, seguidos de um resumo dos resultados e da transferência deles, por exemplo, no pipeline. Um link para um exemplo também é fornecido acima. Novamente, o canal foi substituído pela fila, as goroutines permaneceram no local.
Agora, algumas palavras sobre o Apache Kafka. O Kafka é um sistema de gerenciamento de mensagens que possui excelentes ferramentas de clustering, usa um log de transações (exatamente como em um RDBMS) para armazenar mensagens e suporta o modelo de fila e o modelo de editor / assinante. O último é alcançado através de grupos de destinatários da mensagem. Cada mensagem recebe apenas um membro do grupo (processamento paralelo), mas a mensagem será entregue uma vez para cada grupo. Pode haver muitos desses grupos, bem como destinatários dentro de cada grupo.
Para trabalhar com o Kafka, usarei o pacote "github.com/segmentio/kafka-go".
O Redis, por outro lado, é um banco de dados da coluna de valor-chave na memória que suporta a capacidade de armazenar dados permanentemente. O principal tipo de dados para chaves e valores são cadeias de caracteres, mas existem outras. O Redis é considerado um dos bancos de dados mais rápidos (ou mais) de sua classe. É bom armazenar todos os tipos de estatísticas, métricas, fluxos de mensagens etc.
Para trabalhar com o Redis, usarei o pacote “github.com/go-redis/redis”.
Como este artigo é um início rápido, implantaremos os dois sistemas usando o Docker usando imagens prontas do DockerHub. Eu uso o docker-compose no Windows 10 no modo de contêiner em uma VM do Linux (criada automaticamente pela VM do Docker) com este arquivo docker-compose.yml como este:
version: '2' services: zookeeper: image: wurstmeister/zookeeper ports: - "2181:2181" kafka: image: wurstmeister/kafka:latest ports: - "9092:9092" environment: KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1 KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 KAFKA_CREATE_TOPICS: "Generated:1:1,Solved:1:1,Unsolved:1:1" KAFKA_DELETE_TOPIC_ENABLE: "true" volumes: - /var/run/docker.sock:/var/run/docker.sock redis: image: redis ports: - "6379:6379"
Salve este arquivo, vá para o diretório com o mesmo e execute:
docker-compose up -d
Três contêineres devem ser baixados e iniciados: Kafka (fila), Zookeeper (servidor de configuração para Kafka) e (Redis).
Você pode verificar se os contêineres funcionam usando o comando:
docker-compose ps
Deve ser algo como:
Name State Ports -------------------------------------------------------------------------------------- docker-compose_kafka_1 Up 0.0.0.0:9092->9092/tcp docker-compose_redis_1 Up 0.0.0.0:6379->6379/tcp docker-compose_zookeeper_1 Up 0.0.0.0:2181->2181/tcp, 22/tcp, 2888/tcp, 3888/tcp
De acordo com o arquivo yml, três filas devem ser criadas automaticamente, você pode vê-las com o comando:
docker exec kafka-container_kafka_1 /opt/kafka_2.12-2.1.0/bin/kafka-topics.sh --list --zookeeper zookeeper:2181
Deve haver filas (tópicos - tópicos em termos de Kafka) gerados, resolvidos e não resolvidos.
O gerador de dados enfileira infinitamente os números com um atraso aleatório. Seu código é extremamente simples. Você pode verificar a presença de mensagens na fila Gerada usando o comando:
docker exec kafka-container_kafka_1 /opt/kafka_2.12-2.1.0/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic Generated --from-beginning
Em seguida, está o
processador - aqui você deve prestar atenção à paralelização do processamento de valores da fila no seguinte bloco de código:
var wg sync.WaitGroup c := 0
Como a leitura da fila de mensagens bloqueia o programa, criei um objeto context.Context com um tempo limite de 15 segundos. Esse tempo limite encerrará o programa se a fila estiver vazia por um longo tempo.
Além disso, para cada gorutina que fatorar o número, também é definido o tempo máximo de operação. Eu queria que os números que pudessem fatorar fossem escritos em um banco de dados. E os números que não puderam ser fatorados no tempo alocado foram transferidos para outro banco de dados.
Para determinar o tempo aproximado, o benchmark foi usado:
func BenchmarkFactorize(b *testing.B) { ch := make(chan []int) var factors []int for i := 1; i < bN; i++ { num := 2345678901234 go factorize(num, ch) factors = <-ch b.Logf("\n%d %+v\n\n", num, factors) } }
Os benchmarks no Go são variedades de testes e são colocados em um arquivo com testes. Com base nessa medida, o número máximo para o gerador de números aleatórios foi selecionado. No meu computador, parte dos números teve tempo de fatorar e parte - não.
Os números que poderiam ser decompostos foram escritos no DB No. 0, e os números não compostos no DB No. 1.
Aqui devo dizer que em Redis não há tabelas e tabelas no sentido clássico. Por padrão, o DBMS contém 16 bancos de dados disponíveis para o programador. Essas bases diferem em seus números - de 0 a 15.
O limite de tempo para goroutines no processador foi fornecido usando o contexto e a instrução select:
Este é outro dos truques típicos de desenvolvimento no Go. Seu significado é que a instrução select itera sobre os canais e executa o código correspondente ao primeiro canal ativo. Nesse caso, a goroutine exibirá o resultado em seu canal ou o canal de contexto com um tempo limite será fechado. Em vez do contexto, você pode usar um canal arbitrário que atuará como gerente e fornecerá o encerramento forçado de goroutines.
As sub-rotinas para gravar no banco de dados executam o comando para selecionar o banco de dados desejado (0 ou 1) e escrever pares do formulário (número-fatores) para números analisados ou (número-número) para números não compostos.
func storeSolved(item data) (err error) {
A última parte será um
servidor da web , que exibirá uma lista de números decompostos e não compostos na forma de json. Ele terá dois pontos finais:
http.HandleFunc("/solved", solvedHandler) http.HandleFunc("/unsolved", unsolvedHandler)
O manipulador de solicitação http com o recebimento de dados do Redis e o retorno como json se parece com o seguinte:
func solvedHandler(w http.ResponseWriter, r *http.Request) { w.Header().Set("Content-Type", "application/json") w.Header().Set("Access-Control-Allow-Origin", "*") w.Header().Set("Access-Control-Allow-Methods", "GET") w.Header().Set("Access-Control-Allow-Headers", "Accept, Content-Type, Content-Length, Accept-Encoding, X-CSRF-Token, Authorization")
O resultado da solicitação em:
localhost / resolvido [{ "Key": "1604388558816", "Val": "[1,2,3,227]" }, { "Key": "545232916387", "Val": "[1,545232916387]" }, { "Key": "1786301239076", "Val": "[1,2]" }, { "Key": "698495534061", "Val": "[1,3,13,641,165331]" }]
Agora você pode se aprofundar na documentação e na literatura especializada. Espero que o artigo tenha sido útil.
Peço aos especialistas que não sejam preguiçosos e aponto meus erros.