“No modo de rastreamento, o programador vê a sequência de execução do comando e os valores das variáveis nesta etapa da execução do programa, o que facilita a detecção de erros”, conta a Wikipedia. Como fãs do Linux, regularmente nos deparamos com a questão de quais ferramentas específicas são melhores para implementá-lo. E queremos compartilhar a tradução de um artigo do programador Hongley Lai, que recomenda o bpftrace. Olhando para o futuro, direi que o artigo termina de forma sucinta: "bpftrace é o futuro". Então, por que ele impressionou tanto o colega de Lai? Uma resposta detalhada sob o corte.
Existem duas ferramentas principais de rastreamento no Linux:
strace permite ver quais chamadas do sistema estão sendo feitas;
O ltrace permite ver quais bibliotecas dinâmicas estão sendo chamadas.
Apesar de sua utilidade, essas ferramentas são limitadas. E se você precisar descobrir o que acontece em uma chamada de sistema ou biblioteca? E se você precisar não apenas compilar uma lista de chamadas, mas também, por exemplo, coletar estatísticas sobre determinado comportamento? E se você precisar rastrear vários processos e comparar dados de várias fontes?
Em 2019, finalmente obtivemos uma resposta decente para essas perguntas no Linux:
bpftrace com base na tecnologia
eBPF . O Bpftrace permite escrever pequenos programas que são executados toda vez que um evento ocorre.
Neste artigo, descreverei como instalar o bpftrace e ensinar sua aplicação básica. Também revisarei como é o ecossistema de rastreamento (por exemplo, “o que é eBPF?”) E como ele evoluiu para o que temos hoje.
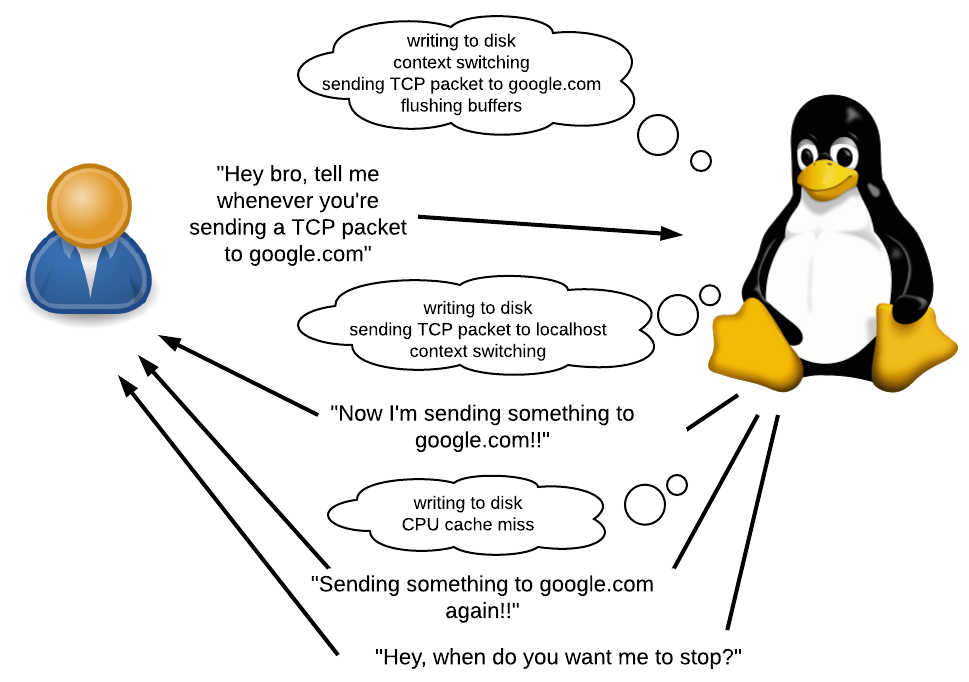
O que é um traço?
Como mencionado anteriormente, o bpftrace permite escrever pequenos programas que são executados toda vez que um evento ocorre.
O que é um evento? Pode ser uma chamada do sistema, uma chamada de função ou mesmo algo acontecendo dentro de tais solicitações. Também pode ser um temporizador ou um evento de hardware, por exemplo, “50 ms passaram desde o último dos mesmos eventos”, “ocorreu falha na página”, “ocorreu mudança de contexto” ou “ocorreu o processador de perda de caso”.
O que pode ser feito em resposta a um evento? Você pode prometer algo, coletar estatísticas e executar comandos arbitrários do shell. Você terá acesso a várias informações contextuais, como o PID atual, rastreamento de pilha, hora, argumentos de chamada, valores de retorno, etc.
Quando usar? Em muitos Você pode descobrir por que o aplicativo é lento compilando uma lista das chamadas mais lentas. Você pode determinar se há vazamentos de memória no aplicativo e, em caso afirmativo, onde. Eu o uso para entender por que Ruby usa tanta memória.
A grande vantagem do bpftrace é que você não precisa recompilar o aplicativo. Não há necessidade de escrever manualmente chamadas de impressão ou qualquer outro código de depuração no código-fonte do aplicativo em estudo. Não é necessário reiniciar aplicativos. E tudo isso com sobrecarga muito baixa. Isso torna o bpftrace especialmente útil para depurar sistemas diretamente no produto ou em outra situação em que há dificuldades com a recompilação.
DTrace: pai do rastreamento
Por um longo tempo, a melhor ferramenta de rastreamento foi o
DTrace , uma estrutura completa de rastreamento dinâmico originalmente desenvolvida pela Sun Microsystems (os fabricantes de Java). Como o bpftrace, o DTrace permite escrever pequenos programas que são executados em resposta a eventos. De fato, muitos dos elementos-chave do ecossistema são amplamente desenvolvidos por
Brendan Gregg , um renomado especialista em DTrace que atualmente trabalha na Netflix. O que explica as semelhanças entre o DTrace e o bpftrace.
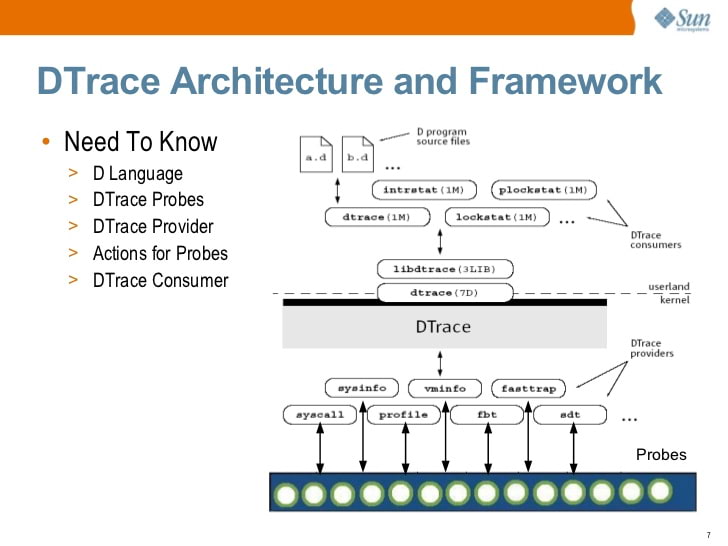 Introdução ao Solaris DTrace (2009) por S. Tripathi, Sun Microsystems
Introdução ao Solaris DTrace (2009) por S. Tripathi, Sun MicrosystemsEm algum momento, a Sun abriu a fonte do DTrace. Hoje, o DTrace está disponível no Solaris, FreeBSD e macOS (embora a versão do macOS seja geralmente inoperante porque o System Integrity Protection, SIP, quebrou muitos dos princípios nos quais o DTrace é executado).
Sim, você percebeu corretamente ... O Linux não está nesta lista. Este não é um problema de engenharia, é um problema de licenciamento. O DTrace foi aberto sob o CDDL em vez da GPL.
A porta Linux DTrace está disponível desde 2011, mas nunca foi suportada pelos principais desenvolvedores de Linux. No início de 2018, a
Oracle reabriu o DTrace sob a GPL , mas já era tarde demais.
Ecossistema de rastreamento do Linux
Sem dúvida, o rastreamento é muito útil, e a comunidade Linux procurou desenvolver suas próprias soluções para este tópico. Porém, diferentemente do Solaris, o Linux não é regulamentado por um fornecedor específico e, portanto, não houve esforço deliberado para desenvolver uma substituição totalmente funcional para o DTrace. O ecossistema de rastreamento do Linux evoluiu lenta e naturalmente, resolvendo problemas à medida que eles surgem. E apenas recentemente esse ecossistema cresceu o suficiente para competir seriamente com o DTrace.
Devido ao crescimento natural, esse ecossistema pode parecer um pouco caótico, consistindo em muitos componentes diferentes. Felizmente, Julia Evans
escreveu uma revisão desse ecossistema (atenção, data de publicação - 2017, antes do advento do bpftrace).
 Ecossistema de rastreamento de Linux descrito por Julia Evans
Ecossistema de rastreamento de Linux descrito por Julia EvansNem todos os elementos são igualmente importantes. Deixe-me resumir brevemente quais elementos considero mais importantes.
Fontes de eventosOs dados do evento podem vir do kernel ou do espaço do usuário (aplicativos e bibliotecas). Alguns deles estão disponíveis automaticamente, sem esforços adicionais do desenvolvedor, enquanto outros requerem anúncio manual.
 Visão geral das fontes mais importantes de eventos rastreados no Linux
Visão geral das fontes mais importantes de eventos rastreados no LinuxNo lado do kernel, existem os kprobes (
de “probes do kernel”, “sensor do kernel”, aprox. Por. ) - um mecanismo que permite rastrear qualquer chamada de função dentro do kernel. Com ele, é possível rastrear não apenas as chamadas do sistema, mas também o que acontece dentro delas (porque os pontos de entrada das chamadas do sistema chamam outras funções internas). Você também pode usar o kprobes para rastrear eventos do kernel que não são chamadas do sistema, por exemplo, “dados em buffer estão sendo gravados no disco”, “pacote TCP é enviado pela rede” ou “troca de contexto em andamento”.
Os pontos de rastreio do kernel permitem rastrear eventos não padrão definidos pelos desenvolvedores do kernel. Esses eventos não estão no nível das chamadas de função. Para criar esses pontos, os desenvolvedores do kernel colocam manualmente a macro TRACE_EVENT no código do kernel.
Ambas as fontes têm prós e contras. O Kprobes funciona "automaticamente" porque não requer que os desenvolvedores do kernel codifiquem manualmente o código. Mas os eventos do kprobe podem mudar arbitrariamente de uma versão do kernel para outra, porque as funções estão mudando constantemente - elas são adicionadas, excluídas e renomeadas.
Os pontos de rastreio do kernel geralmente são mais estáveis ao longo do tempo e podem fornecer informações contextuais úteis que podem não estar disponíveis se o kprobes for usado. Usando o kprobes, você pode acessar argumentos de chamada de função. Mas com a ajuda de pontos de rastreamento, você pode obter qualquer informação que o desenvolvedor do kernel decida descrever manualmente.
No espaço do usuário, há um análogo de kprobes - uprobes. Ele foi projetado para rastrear chamadas de função no espaço do usuário.
Os sensores USDT (“Rastreamentos de espaço do usuário definidos estaticamente”) são um análogo dos pontos de rastreamento do kernel no espaço do usuário. Os desenvolvedores de aplicativos precisam adicionar manualmente os sensores USDT ao código.
Fato interessante: o DTrace há muito tempo fornece a API C para definir seu próprio análogo de sensores USDT (usando a macro DTRACE_PROBE). Os desenvolvedores de ecossistemas de rastreamento no Linux decidiram deixar o código fonte compatível com esta API, para que quaisquer macros DTRACE_PROBE sejam convertidas automaticamente em sensores USDT!
Portanto, em teoria, o strace pode ser implementado usando kprobes, e o ltrace pode ser implementado usando uprobes. Não tenho certeza se isso já é praticado ou não.
InterfacesInterfaces são aplicativos que permitem aos usuários usar facilmente fontes de eventos.
Vamos ver como as fontes de eventos funcionam. O fluxo de trabalho é o seguinte:
- O kernel representa um mecanismo - geralmente um arquivo / proc ou / sys aberto para gravação - que registra a intenção de rastrear o evento e o que deve seguir o evento.
- Depois de registrado, o kernel localiza o kernel / função na memória no espaço do usuário / pontos de rastreamento / sensores USDT e altera seu código para que algo mais aconteça.
- O resultado dessa "outra coisa" pode ser coletado posteriormente usando algum mecanismo.
Eu não gostaria de fazer tudo isso manualmente! Portanto, as interfaces são úteis: elas fazem tudo isso por você.
Existem interfaces para todos os gostos e cores. No campo das
interfaces baseadas no eBPF, existem as de baixo nível que exigem um entendimento profundo de como interagir com fontes de eventos e como o bytecode do eBPF funciona. E são de alto nível e fáceis de operar, embora durante a sua existência não tenham demonstrado grande flexibilidade.
É por isso que o bpftrace - a interface mais recente - é o meu favorito. É amigável e flexível como o DTrace. Mas é bastante novo e requer polimento.
eBPF
eBPF é a
nova estrela de rastreamento do Linux na qual o bpftrace se baseia. Ao rastrear um evento, você deseja que algo aconteça no kernel. Quão flexível é a maneira de determinar o que é isso "alguma coisa"? Obviamente, usando uma linguagem de programação (ou usando código de máquina).
eBPF (versão aprimorada do Berkeley Packet Filter). Esta é uma máquina virtual de alto desempenho que é executada no kernel e tem as seguintes propriedades / limitações:
- Todas as interações do espaço do usuário ocorrem por meio de "cartões" do eBPF, que são o armazenamento de dados de valor-chave.
- Não há ciclos para que cada programa eBPF termine em um horário específico.
- Espere, dissemos Filtro de lote? Você está certo: eles foram originalmente projetados para filtrar pacotes de rede. Essa é uma tarefa semelhante: ao encaminhar pacotes (a ocorrência de um evento), é necessário executar alguma ação administrativa (aceitar, descartar, registrar em diário ou redirecionar um pacote, etc.) Uma máquina virtual foi inventada para acelerar essas ações (com capacidade JIT) compilação). Uma versão "estendida" é considerada devido ao fato de que, comparado à versão original do Berkeley Packet Filter, o eBPF pode ser usado fora do contexto da rede.
Lá vai você. Com o bpftrace, você pode determinar quais eventos rastrear e o que deve acontecer em resposta. O Bpftrace compila seu programa de alto nível bpftrace no bytecode do eBPF, rastreia eventos e carrega o bytecode no kernel.
Dias sombrios antes do eBPF
Antes do eBPF, as opções de solução eram, para dizer o mínimo, estranhas.
O SystemTap é um dos predecessores "mais sérios" do bpftrace na família Linux. Os scripts do SystemTap são traduzidos para o idioma C e carregados no kernel como módulos. O módulo do kernel resultante é então carregado.
Essa abordagem era muito frágil e mal suportada fora do Red Hat Enterprise Linux. Para mim, nunca funcionou bem no Ubuntu, que tendia a quebrar o SystemTap em todas as atualizações do kernel devido a uma alteração na estrutura de dados do kernel. Também é dito que, nos primeiros dias de sua existência, o SystemTap
facilmente levava ao pânico do kernel .
Instalação do bpftrace
É hora de arregaçar as mangas! Neste guia, veremos a instalação do bpftrace no Ubuntu 18.04. Versões mais recentes da distribuição são indesejáveis, porque durante a instalação, precisaremos de pacotes que ainda não foram compilados para eles.
Instalação de DependênciasPrimeiro, instale o Clang 5.0, lbclang 5.0 e LLVM 5.0, incluindo todos os arquivos de cabeçalho. Usaremos os pacotes fornecidos pelo llvm.org, porque os repositórios do Ubuntu são
problemáticos .
wget -O - https://apt.llvm.org/llvm-snapshot.gpg.key | sudo apt-key add - cat <<EOF | sudo tee -a /etc/apt/sources.list deb http://apt.llvm.org/xenial/ llvm-toolchain-xenial main deb-src http://apt.llvm.org/xenial/ llvm-toolchain-xenial main deb http://apt.llvm.org/xenial/ llvm-toolchain-xenial-5.0 main deb-src http://apt.llvm.org/xenial/ llvm-toolchain-xenial-5.0 main EOF sudo apt update sudo apt install clang-5.0 libclang-5.0-dev llvm-5.0 llvm-5.0-dev
Seguinte:
sudo apt install bison cmake flex g++ git libelf-dev zlib1g-dev libfl-dev
E, finalmente, instale o libbfcc-dev a partir do upstream, não do repositório Ubuntu. Não
há arquivos de cabeçalho no pacote que está no Ubuntu. E esse problema não foi resolvido mesmo às 18h10.
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4052245BD4284CDD echo "deb https://repo.iovisor.org/apt/$(lsb_release -cs) $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/iovisor.list sudo apt update sudo apt install bcc-tools libbcc-examples linux-headers-$(uname -r)
Instalação principal do BpftraceÉ hora de instalar o bpftrace a partir da fonte! Vamos cloná-lo, montá-lo e instalá-lo em / usr / local:
git clone https://github.com/iovisor/bpftrace cd bpftrace mkdir build && cd build cmake -DCMAKE_BUILD_TYPE=DEBUG .. make -j4 sudo make install
E pronto! O executável será instalado em / usr / local / bin / bpftrace. Você pode alterar o destino usando o argumento cmake, que se parece com isso por padrão:
DCMAKE_INSTALL_PREFIX=/usr/local.
Exemplos de uma linhaVamos executar alguns liners únicos do bpftrace para entender nossos recursos. Eu os peguei no
guia de
Brendan Gregg , que tem uma descrição detalhada de cada um deles.
# 1. Exiba uma lista de sensores
bpftrace -l 'tracepoint:syscalls:sys_enter_*'
# 2. Saudações
bpftrace -e 'BEGIN { printf("hello world\n"); }'
# 3. Abrindo um arquivo
bpftrace -e 'tracepoint:syscalls:sys_enter_open { printf("%s %s\n", comm, str(args->filename)); }'
# 4. O número de chamadas do sistema por processo
bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] = count(); }'
# 5. Distribuição de chamadas read () por número de bytes
bpftrace -e 'tracepoint:syscalls:sys_exit_read /pid == 18644/ { @bytes = hist(args->retval); }'
# 6. Rastreio dinâmico de conteúdo read ()
bpftrace -e 'kretprobe:vfs_read { @bytes = lhist(retval, 0, 2000, 200); }'
# 7. Tempo gasto em chamadas read ()
bpftrace -e 'kprobe:vfs_read { @start[tid] = nsecs; } kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); }'
# 8. Contando eventos no nível do processo
bpftrace -e 'tracepoint:sched:sched* { @[name] = count(); } interval:s:5 { exit(); }'
# 9. Criando perfil de pilhas de trabalho do kernel
bpftrace -e 'profile:hz:99 { @[stack] = count(); }'
# 10. Planejador de rastreamento
bpftrace -e 'tracepoint:sched:sched_switch { @[stack] = count(); }'
# 11. Rastreio de E / S de bloqueio
bpftrace -e 'tracepoint:block:block_rq_complete { @ = hist(args->nr_sector * 512); }'
Confira o site de Brendan Gregg para descobrir
que tipo de saída as equipes acima podem gerar .
Sintaxe de script e exemplo de tempo de E / SA sequência passada pela opção '-e' é o conteúdo do script bpftrace. A sintaxe nesse caso é, condicionalmente, um conjunto de construções:
<event source> /<optional filter>/ { <program body> }
Vejamos o sétimo exemplo, sobre o tempo das operações de leitura do sistema de arquivos:
kprobe:vfs_read { @start[tid] = nsecs; } <- 1 -><-- 2 -> <---------- 3 --------->
Rastreamos o evento a partir do mecanismo
kprobe , ou seja, rastreamos o início da função do kernel.
A função do kernel para rastreamento é
vfs_read , essa função é chamada quando o kernel executa uma operação de leitura do sistema de arquivos (VFS do “Virtual FileSystem”, abstração do sistema de arquivos dentro do kernel).
Quando o
vfs_read começa a ser
executado (ou seja, antes da função
executar qualquer trabalho útil), o programa bpftrace é iniciado. Ele salva o registro de data e hora atual (em nanossegundos) em um array associativo global chamado
st art . A chave é
tid , uma referência ao ID do encadeamento atual.
kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); } <-- 1 --> <-- 2 -> <---- 3 ----> <----------------------------- 4 ----------------------------->
1. Rastreamos o evento a partir do mecanismo
kretprobe , que é semelhante ao
kprobe , exceto que ele é chamado quando a função retorna o resultado de sua execução.
2. A função do kernel para rastreamento é
vfs_read .
3. Este é um filtro opcional. Ele verifica se a hora de início foi gravada anteriormente. Sem esse filtro, o programa pode ser iniciado durante a leitura e capturar apenas o final, resultando em um tempo
estimado de
nsecs - 0 , em vez de
nsecs - iniciar .
4. O corpo do programa.
nsecs - st art [tid] calcula quanto tempo se passou desde o início da função vfs_read.
@ns [comm] = hist (...) adiciona os dados especificados ao histograma bidimensional armazenado em
@ns . A chave de
comunicação refere-se ao nome do aplicativo atual. Portanto, teremos um histograma comando por comando.
delete (...) exclui o horário de início da matriz associativa, porque não precisamos mais dele.
Esta é a conclusão final. Observe que todos os histogramas são exibidos automaticamente. O uso explícito do comando imprimir histograma não é necessário.
@ns não é uma variável especial; portanto, o histograma não é exibido por causa disso.
@ns[snmp-pass]: [0, 1] 0 | | [2, 4) 0 | | [4, 8) 0 | | [8, 16) 0 | | [16, 32) 0 | | [32, 64) 0 | | [64, 128) 0 | | [128, 256) 0 | | [256, 512) 27 |@@@@@@@@@ | [512, 1k) 125 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ | [1k, 2k) 22 |@@@@@@@ | [2k, 4k) 1 | | [4k, 8k) 10 |@@@ | [8k, 16k) 1 | | [16k, 32k) 3 |@ | [32k, 64k) 144 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@| [64k, 128k) 7 |@@ | [128k, 256k) 28 |@@@@@@@@@@ | [256k, 512k) 2 | | [512k, 1M) 3 |@ | [1M, 2M) 1 | |
Exemplo de sensor USDTVamos pegar esse código C e salvá-lo no arquivo
tracetest.c :
#include <sys/sdt.h> #include <sys/time.h> #include <unistd.h> #include <stdio.h> static long myclock() { struct timeval tv; gettimeofday(&tv, NULL); DTRACE_PROBE1(tracetest, testprobe, tv.tv_sec); return tv.tv_sec; } int main(int argc, char **argv) { while (1) { myclock(); sleep(1); } return 0; }
Este programa é executado infinitamente chamando
myclock () uma vez por segundo.
myclock () consulta a hora atual e retorna o número de segundos desde o início da era.
A chamada para
DTRACE_PROBE1 aqui define um ponto de rastreamento USDT estático.
- A macro DTRACE_PROBE1 é obtida em sys / sdt.h. A macro oficial do USDT, que faz o mesmo, é chamada STAP_PROBE1 (STAP do SystemTap, que foi o primeiro mecanismo Linux suportado no USDT). Mas como o USDT é compatível com os sensores de espaço do usuário do DTrace, o DTRACE_PROBE1 é apenas uma referência ao STAP_PROBE1 .
- O primeiro parâmetro é o nome do provedor. Acredito que este é um vestígio que resta do DTrace, porque o bpftrace não parece estar fazendo nada útil com ele. No entanto, há uma nuance ( que eu descobri ao depurar o problema na solicitação 328 ): o nome do provedor deve ser idêntico ao nome do arquivo binário do aplicativo, caso contrário, o bpftrace não conseguirá encontrar o ponto de rastreamento.
- O segundo parâmetro é o nome do ponto de rastreamento.
- Quaisquer parâmetros adicionais são o contexto fornecido pelos desenvolvedores. O número 1 em DTRACE_PROBE1 significa que queremos passar um parâmetro adicional.
Vamos garantir que sys / sdt.h esteja disponível para nós e montar o programa:
sudo apt install systemtap-sdt-dev gcc tracetest.c -o tracetest -Wall -g
Instruímos o bpftrace a emitir o PID e "time is [number]" sempre que a
testprobe for atingida:
sudo bpftrace -e 'usdt:/full-path-to/tracetest:testprobe { printf("%d: time is %d\n", pid, arg0); }'
O Bpftrace continua funcionando enquanto pressionamos Ctrl-C. Portanto, abra um novo terminal e execute o teste mais
rápido lá:
# No novo terminal
./tracetest
Volte para o primeiro terminal com bpftrace, lá você deve ver algo como:
Attaching 1 probe... 30909: time is 1549023215 30909: time is 1549023216 30909: time is 1549023217 ... ^C
Exemplo de alocação de memória usando glibc ptmallocEu uso o bpftrace para entender por que o Ruby usa tanta memória. E como parte de minha pesquisa, preciso entender como o alocador de memória da glibc usa
regiões de memória .
Para otimizar o desempenho de vários núcleos, o alocador de memória glibc destaca várias "áreas" do sistema operacional. Quando o aplicativo solicita alocação de memória, o alocador seleciona uma área que não está em uso e marca parte dessa área como "usada". Como os encadeamentos usam áreas diferentes, o número de bloqueios é reduzido, o que leva a um melhor desempenho multithread.
Mas essa abordagem gera muito lixo e parece que um consumo de memória tão alto no Ruby é justamente por isso. Para entender melhor a natureza desse lixo, pensei: o que significa “escolher uma área que não é usada”? Isso pode significar um dos seguintes:
- Cada vez que malloc () é chamado, o alocador itera sobre todas as áreas e localiza aquela que não está bloqueada no momento. E somente se todos estiverem bloqueados, ele tentará criar um novo.
- A primeira vez que malloc () é chamado em um encadeamento específico (ou quando o encadeamento é iniciado), o alocador seleciona aquele que não está bloqueado no momento. E se todos estiverem bloqueados, ele tentará criar um novo.
- Na primeira vez em que malloc () é chamado em um encadeamento específico (ou quando o encadeamento é iniciado), o alocador tenta criar uma nova região, independentemente de haver regiões desbloqueadas. Somente se uma nova área não puder ser criada (por exemplo, quando o limite estiver esgotado), ela reutilizará a existente.
- Provavelmente existem mais opções que eu não considerei.
Não há resposta específica na documentação, qual desses recursos permite selecionar uma área que não é usada. Estudei o código fonte da glibc, que sugeriu a opção 3. Mas eu queria verificar experimentalmente que interpretei o código fonte corretamente, sem a necessidade de depurar o código no glibc.
Aqui está a função de alocador de memória glibc que cria uma nova área. Mas você pode chamá-lo somente depois de verificar o limite.
static mstate _int_new_arena(size_t size) { mstate arena; size = calculate_how_much_memory_to_ask_from_os(size); arena = do_some_stuff_to_allocate_memory_from_os(); LIBC_PROBE(memory_arena_new, 2, arena, size); do_more_stuff(); return arena; }
Posso usar
uprobes para rastrear a função
_int_new_arena ? Infelizmente não. Por alguma razão, este símbolo não está disponível no glibc Ubuntu 18.04. Mesmo após a instalação dos símbolos de depuração.
Felizmente, existe um sensor USDT nesta função.
LIBC_PROBE é um alias de macro para
STAP_PROBE .
O nome do provedor é libc.
O nome do sensor é memory_arena_new.
O número 2 significa que existem 2 argumentos adicionais especificados pelo desenvolvedor.
arena é o endereço da área que foi extraída do sistema operacional e tamanho é o seu tamanho.
Antes de podermos usar esse sensor, precisamos
contornar o problema 328 . Precisamos criar um link simbólico com glibc em algum lugar com o nome
libc , porque o bpftrace espera que o nome da biblioteca (que de outra forma seria
libc-2.27.so ) seja idêntico ao nome do provedor
(libc) .
ln -s /lib/x86_64-linux-gnu/libc-2.27.so /tmp/libc
Agora instruímos o bpftrace a conectar o sensor USDT memory_arena_new, cujo nome do fornecedor é
libc :
sudo bpftrace -e 'usdt:/tmp/libc:memory_arena_new { printf("PID %d: created new arena at %p, size %d\n", pid, arg0, arg1); }'
Em outro terminal, rodaremos o Ruby, que criará três threads que não fazem nada e terminam em um segundo. Devido ao bloqueio global do intérprete, Ruby
malloc () não deve ser chamado em paralelo por threads diferentes.
ruby -e '3.times { Thread.new { } }; sleep 1'
Voltando ao terminal com bpftrace, veremos:
Attaching 1 probe... PID 431: created new arena at 0x7f40e8000020, size 576 PID 431: created new arena at 0x7f40e0000020, size 576 PID 431: created new arena at 0x7f40e4000020, size 576
Aqui está a resposta para a nossa pergunta! Cada vez que você cria um novo thread no Ruby, a glibc destaca uma nova área, independentemente da competitividade.
Quais pontos de rastreio estão disponíveis? O que devo rastrear?Você pode listar todos os pontos de rastreio de hardware, timers, kprobe e estático do kernel executando o comando:
sudo bpftrace -l
Você pode listar todos os pontos de rastreio da verificação vertical (caracteres de função) de um aplicativo ou biblioteca fazendo:
nm /path-to-binary
Você pode listar todos os pontos de rastreio do aplicativo ou biblioteca USDT executando o seguinte comando:
/usr/share/bcc/tools/tplist -l /path-to/binary
Com relação a quais pontos de rastreamento usar: não faria mal entender o código fonte do que você vai rastrear. Eu recomendo que você estude o código fonte.
Dica: um formato estrutural para pontos de rastreio no kernelAqui está uma dica útil sobre os pontos de rastreamento do kernel. Você pode verificar quais campos de argumento estão disponíveis lendo o arquivo / sys / kernel / debug / tracing / events!
Por exemplo, suponha que você deseja rastrear chamadas para
madvise (..., MADV_DONTNEED) :
sudo bpftrace -l | grep madvise
- nos dirá que podemos usar o tracepoint: syscalls: sys_enter_madvise.
sudo cat /sys/kernel/debug/tracing/events/syscalls/sys_enter_madvise/format
- nos fornecerá as seguintes informações:
name: sys_enter_madvise ID: 569 format: field:unsigned short common_type; offset:0; size:2; signed:0; field:unsigned char common_flags; offset:2; size:1; signed:0; field:unsigned char common_preempt_count; offset:3; size:1; signed:0; field:int common_pid; offset:4; size:4; signed:1; field:int __syscall_nr; offset:8; size:4; signed:1; field:unsigned long start; offset:16; size:8; signed:0; field:size_t len_in; offset:24; size:8; signed:0; field:int behavior; offset:32; size:8; signed:0; print fmt: "start: 0x%08lx, len_in: 0x%08lx, behavior: 0x%08lx", ((unsigned long)(REC->start)), ((unsigned long)(REC->len_in)), ((unsigned long)(REC->behavior))
Assinatura Madvise de acordo com o manual:
(void * addr, size_t length, int conselho) . Os últimos três campos dessa estrutura correspondem a esses parâmetros!
Qual é o significado de MADV_DONTNEED? A julgar pelo grep MADV_DONTNEED / usr / include, é igual a 4:
/usr/include/x86_64-linux-gnu/bits/mman-linux.h:80:# define MADV_DONTNEED 4 /* Don't need these pages. */
Portanto, nossa equipe bpftrace se torna:
sudo bpftrace -e 'tracepoint:syscalls:sys_enter_madvise /args->behavior == 4/ { printf("madvise DONTNEED called\n"); }'
Conclusão
Bpftrace é maravilhoso! Bpftrace é o futuro!
Se você quiser saber mais sobre ele, recomendo que você se familiarize com
a liderança dele , bem como com o
primeiro post de 2019 no blog de Brendan Gregg.
Boa depuração!