Em 1943, os neuropsicólogos americanos McCallock e Pitts desenvolveram um modelo de computador de uma rede neural e, em 1958, a
primeira rede de camada única em
funcionamento reconheceu algumas letras. Agora, as redes neurais não são usadas apenas para quê: prever a taxa de câmbio, diagnosticar doenças, pilotos automáticos e criar gráficos em jogos de computador. Apenas sobre o último e conversar.
Evgeni Tumanov trabalha como engenheiro de Deep Learning na
NVIDIA . Com base nos resultados de seu discurso na conferência HighLoad ++, preparamos uma história sobre o uso de Machine Learning e Deep Learning em gráficos. O aprendizado de máquina não termina com PNL, Visão por Computador, sistemas de recomendação e tarefas de pesquisa. Mesmo se você não estiver familiarizado com essa área, poderá aplicar as melhores práticas do artigo em seu campo ou setor.
A história consistirá em três partes. Analisaremos as tarefas no gráfico que são resolvidas com a ajuda do aprendizado de máquina, derivaremos a ideia principal e descreveremos o caso de aplicá-la em uma tarefa específica e, especificamente, na
renderização de nuvens .
DL / ML supervisionado em gráficos ou treinamento de professores em gráficos
Vamos analisar dois grupos de tarefas. Para começar, denote-os brevemente.
Mundo real ou mecanismo de renderização :
- Criação de animações credíveis: locomoção, animação facial.
- Pós-processamento de imagens renderizadas: superamostragem, suavização de serrilhado.
- Slow Motion: interpolação de quadros.
- Geração de materiais.
O segundo grupo de tarefas agora é chamado convencionalmente de "
algoritmo pesado ". Incluímos tarefas como renderizar objetos complexos, como nuvens e
simulações físicas : água, fumaça.
Nosso objetivo é entender a diferença fundamental entre os dois grupos. Vamos considerar as tarefas com mais detalhes.
Criação de animações credíveis: locomoção, animação facial
Nos últimos anos, muitos
artigos apareceram , onde os pesquisadores oferecem novas maneiras de gerar belas animações. Usar o trabalho de artistas é caro, e substituí-los por um algoritmo seria muito benéfico para todos. Há um ano, na NVIDIA, estávamos trabalhando em um projeto no qual estávamos envolvidos em animação facial de personagens em jogos: sincronizando o rosto do herói com a trilha sonora do discurso. Tentamos "reviver" o rosto para que todos os pontos se movessem e, acima de tudo, os lábios, porque esse é o momento mais difícil da animação. Manualmente, um artista faz isso caro e por um longo tempo. Quais são as opções para resolver esse problema e criar um
conjunto de
dados para ele?
A primeira opção é
identificar as vogais: a boca se abre e as consoantes se fecham . Este é um algoritmo simples, mas muito simples. Nos jogos, queremos mais qualidade. A segunda opção é
fazer com
que as pessoas leiam textos diferentes e escrevam seus rostos e depois compare as letras que pronunciam com expressões faciais. É uma boa ideia, e fizemos isso em um
projeto conjunto com a Remedy Entertainment. A única diferença é que no jogo não estamos mostrando um vídeo, mas um modelo 3D de pontos. Para montar um conjunto de dados, você precisa entender como os pontos específicos da face se movem. Pegamos atores, pedimos para ler textos com entonações diferentes, filmamos em câmeras muito boas de diferentes ângulos, após o que restauramos o modelo 3D de rostos em cada quadro e previmos a posição dos pontos no rosto pelo som.
Pós-processamento de imagem renderizada: superamostragem, anti-aliasing
Considere um caso de um jogo específico: temos um mecanismo que gera imagens em diferentes resoluções. Queremos renderizar a imagem em uma resolução de 1000 × 500 pixels e mostrar ao player 2000 × 1000 - isso será mais bonito. Como montar um conjunto de dados para esta tarefa?
Primeiro, renderize a imagem em alta resolução, abaixe a qualidade e tente treinar o sistema para converter a imagem de baixa resolução para alta resolução.
Slow Motion: interpolação de quadros
Temos um vídeo e queremos que a rede adicione quadros no meio - para interpolar quadros. A idéia é óbvia - gravar um vídeo real com um grande número de quadros, remover os intermediários e tentar prever o que foi removido pela rede.
Geração de material
Não vamos nos concentrar muito na geração de materiais. Sua essência é que pegamos, por exemplo, um pedaço de madeira em vários ângulos de iluminação e interpolamos a vista de outros ângulos.
Examinamos o primeiro grupo de problemas. O segundo é fundamentalmente diferente. Falaremos sobre a renderização de objetos complexos, como nuvens, mais tarde, mas agora vamos lidar com simulações físicas.
Simulações físicas de água e fumaça
Imagine uma piscina na qual objetos sólidos em movimento estão localizados. Queremos prever o movimento de partículas fluidas. Existem partículas na piscina no tempo
t , e no tempo
t + Δt queremos obter sua posição. Para cada partícula, chamamos de rede neural e obtemos uma resposta onde ela estará no próximo quadro.
Para resolver o problema, usamos
a equação de Navier-Stokes , que descreve o movimento de um fluido. Para uma simulação plausível e fisicamente correta da água, teremos que resolver a equação ou aproximação a ela. Isso pode ser feito de maneira computacional, da qual muitos foram inventados nos últimos 50 anos: o algoritmo SPH, FLIP ou Fluido Baseado em Posição.
A diferença entre o primeiro grupo de tarefas do segundo
No primeiro grupo, o professor do algoritmo é algo acima: uma gravação da vida real, como no caso de indivíduos, ou algo do mecanismo, por exemplo, renderizando imagens. No segundo grupo de problemas, usamos o método da matemática computacional. A partir dessa divisão temática, uma idéia cresce.
Ideia principal
Temos uma tarefa computacionalmente complexa que é longa, difícil e difícil de resolver pelo método clássico da universidade de computação. Para resolvê-lo e acelerar, talvez até perdendo um pouco de qualidade, precisamos:
- encontre o lugar que consome mais tempo na tarefa em que o código dura mais tempo;
- veja o que essa linha produz;
- tente prever o resultado de uma linha usando uma rede neural ou qualquer outro algoritmo de aprendizado de máquina.
Essa é uma metodologia geral e a idéia principal é uma receita sobre como encontrar aplicativos para aprendizado de máquina. O que você deve fazer para tornar essa ideia útil? Não existe uma resposta exata - use a criatividade, veja seu trabalho e encontre-o. Eu faço gráficos e não estou tão familiarizado com outros campos, mas posso imaginar que no ambiente acadêmico - em física, química, robótica - você pode definitivamente encontrar aplicação. Se você resolver uma equação física complexa em seu local de trabalho, também poderá encontrar um aplicativo para essa ideia. Para maior clareza, considere um caso específico.
Tarefa de renderização em nuvem
Estivemos envolvidos neste projeto na NVIDIA há seis meses: a tarefa é desenhar uma nuvem fisicamente correta, representada como a densidade de gotículas de líquido no espaço.
Uma nuvem é um objeto fisicamente complexo, uma suspensão de gotículas líquidas que não podem ser modeladas como um objeto sólido.
Não será possível impor uma textura e renderizar na nuvem, porque as gotas de água são difíceis geometricamente localizadas no espaço 3D e são complexas em si mesmas: elas praticamente não absorvem a cor, mas a refletem anisotropicamente - em todas as direções de diferentes maneiras.
Se você observar uma gota de água na qual o sol brilha e os vetores do olho e do sol em uma gota forem paralelos, será observado um grande pico de intensidade de luz. Isso explica o fenômeno físico que todos já viram: em dias ensolarados, uma das margens da nuvem é muito brilhante, quase branca. Estamos olhando para a borda da nuvem, e a linha de visão e o vetor dessa borda para o sol são quase paralelos.

A nuvem é um objeto fisicamente complexo e sua renderização pelo algoritmo clássico requer muito tempo. Falaremos sobre o algoritmo clássico um pouco mais tarde. Dependendo dos parâmetros, o processo pode levar horas ou até dias. Imagine que você é um artista e desenhe um filme com efeitos especiais. Você tem uma cena complicada com iluminação diferente com a qual deseja brincar. Desenhamos uma topologia em nuvem - eu não gosto, e você deseja redesenhar e obter uma resposta aqui. É importante obter uma resposta de uma alteração de parâmetro o mais rápido possível. Isso é um problema. Portanto, vamos tentar acelerar esse processo.
Solução clássica
Para resolver o problema, você precisa resolver esta equação complicada.

A equação é dura, mas vamos entender seu significado físico. Considere um raio perfurado por uma nuvem perfurando uma nuvem. Como a luz entra na câmera nessa direção? Primeiro, a luz pode chegar ao ponto de saída do raio da nuvem e depois se propagar ao longo desse raio dentro da nuvem.
Para o segundo método de "propagação da luz ao longo da direção" é o termo integral da equação. Seu significado físico é o seguinte.
Considere o segmento dentro da nuvem no raio - do ponto de entrada ao ponto de saída. A integração é realizada precisamente sobre esse segmento e, para cada ponto, consideramos a chamada
energia luminosa indireta L (x, ω) - o significado da integral I
1 - iluminação indireta no ponto. Parece que as gotas de maneiras diferentes refletem a luz do sol. Consequentemente, uma enorme quantidade de raios mediados das gotículas ao redor chega ao ponto. I
1 é a integral sobre a esfera que circunda um ponto no raio. No algoritmo clássico, é contado usando o método de
Monte Carlo .
O algoritmo clássico.
- Renderize uma imagem a partir de pixels e produza um raio que vai do centro da câmera para um pixel e depois para mais longe.
- Atravessamos a viga com a nuvem, encontramos os pontos de entrada e saída.
- Consideramos o último termo da equação: cruzar, conectar-se ao sol.
- Amostragem de importância de introdução
Como considerar a estimativa de Monte Carlo I
1 não analisaremos, porque é difícil e não é tão importante. Basta dizer que esta é a parte mais longa e mais difícil de todo o algoritmo.
Conectamos redes neurais
A partir da idéia principal e da descrição do algoritmo clássico, segue-se uma receita sobre como aplicar redes neurais a esta tarefa. O mais difícil é calcular a pontuação de Monte Carlo. Ele fornece um número que significa iluminação indireta em um ponto, e é exatamente isso que queremos prever.

Decidimos a saída, agora entenderemos a entrada - a partir de quais informações ficará claro qual é a magnitude da luz indireta no ponto. Essa é a luz refletida pelas muitas gotas de água que cercam o ponto. A topologia da luz é fortemente influenciada pela topologia da densidade em torno do ponto, a direção da fonte e a direção da câmera.
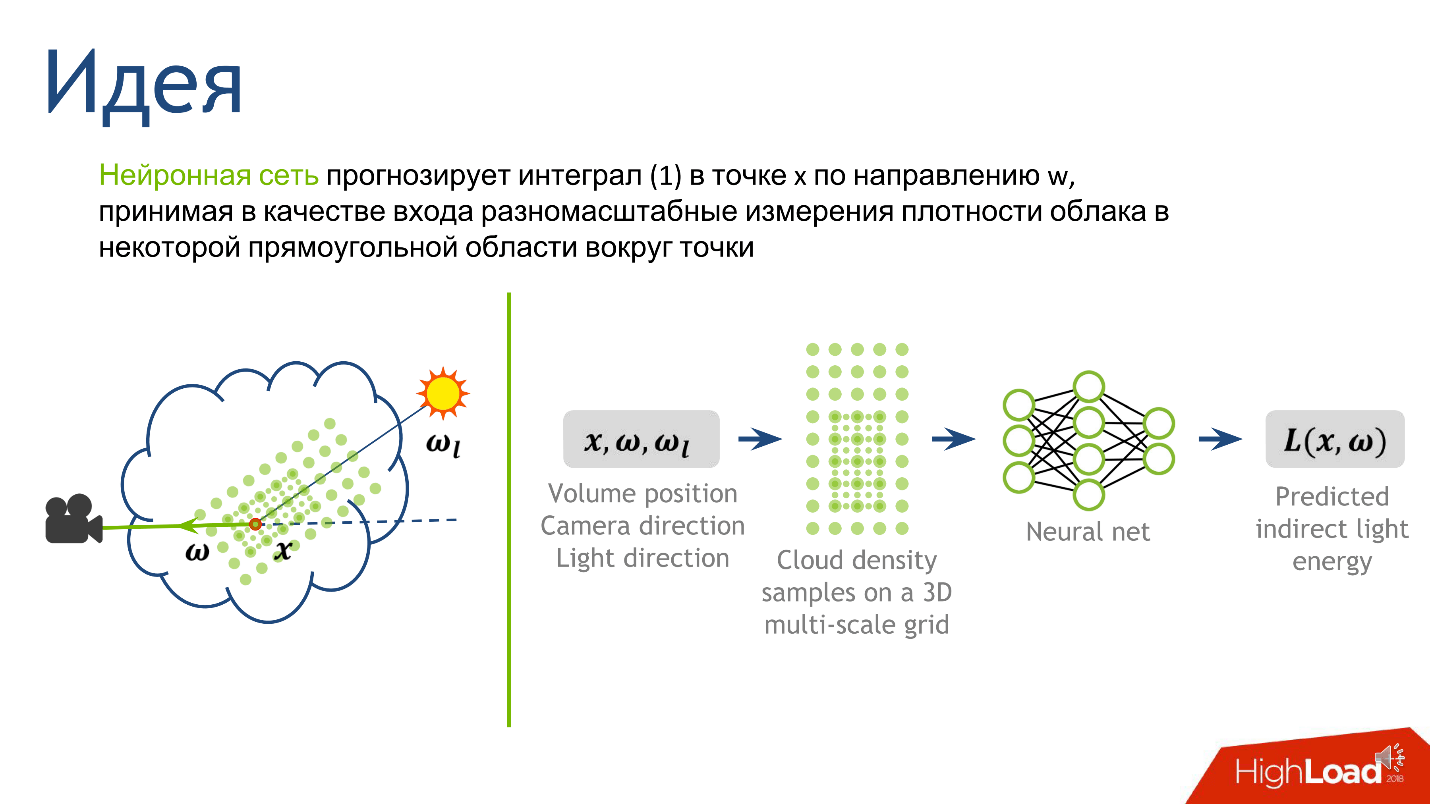
Para construir a entrada para a rede neural, descrevemos a densidade local. Existem várias maneiras de fazer isso, mas nos concentramos no artigo
Dispersão Profunda: Renderização de Nuvens Atmosféricas com Redes Neurais Preditivas de Radiância, Kallwcit et al. 2017 e muitas idéias vieram de lá.
Resumidamente, o método de representação local da densidade em torno de um ponto se parece com isso.
- Corrija uma constante relativamente pequena . Que seja o caminho livre médio na nuvem.
- Desenhe em torno de um ponto em nosso segmento uma grade retangular volumétrica de tamanho fixo , digamos 5 * 5 * 9. No centro deste cubo será o nosso ponto. O espaçamento da grade é uma pequena constante fixa. Nos nós da grade, mediremos a densidade da nuvem.
- Vamos aumentar a constante em 2 vezes , desenhar uma grade maior e fazer o mesmo - meça a densidade nos nós da grade.
- Repita a etapa anterior várias vezes . Fizemos isso 10 vezes e, após o procedimento, obtivemos 10 grades - 10 tensores, cada um dos quais armazena a densidade das nuvens e cada um dos tensores cobre uma vizinhança cada vez maior ao redor do ponto.
Essa abordagem nos fornece a descrição mais detalhada de uma pequena área - quanto mais próxima ao ponto, mais detalhada é a descrição. Decidido sobre a saída e entrada da rede, resta entender como treiná-la.
Treinamento
Geraremos 100 nuvens diferentes com diferentes topologias. Nós simplesmente os renderizamos usando o algoritmo clássico, anote o que o algoritmo recebe na mesma linha em que ele executa a integração de Monte Carlo e anote as propriedades que correspondem ao ponto. Então, temos um conjunto de dados para aprender.

O que ensinar, ou arquitetura de rede
A arquitetura de rede para esta tarefa não é o momento mais crucial e, se você não entende nada - não se preocupe -, essa não é a coisa mais importante que eu queria transmitir. Usamos a seguinte arquitetura: para cada ponto, existem 10 tensores, cada um dos quais é calculado em uma grade de escala cada vez maior. Cada um desses tensores cai no bloco correspondente.
- Primeiro na primeira camada totalmente conectada regular.
- Depois de sair da primeira camada totalmente conectada, na segunda camada totalmente conectada, que não possui ativação.
Uma camada totalmente conectada sem ativação é apenas a multiplicação por uma matriz. Ao resultado da multiplicação pela matriz, adicionamos a saída do
bloco residual anterior e só então aplicamos a ativação.
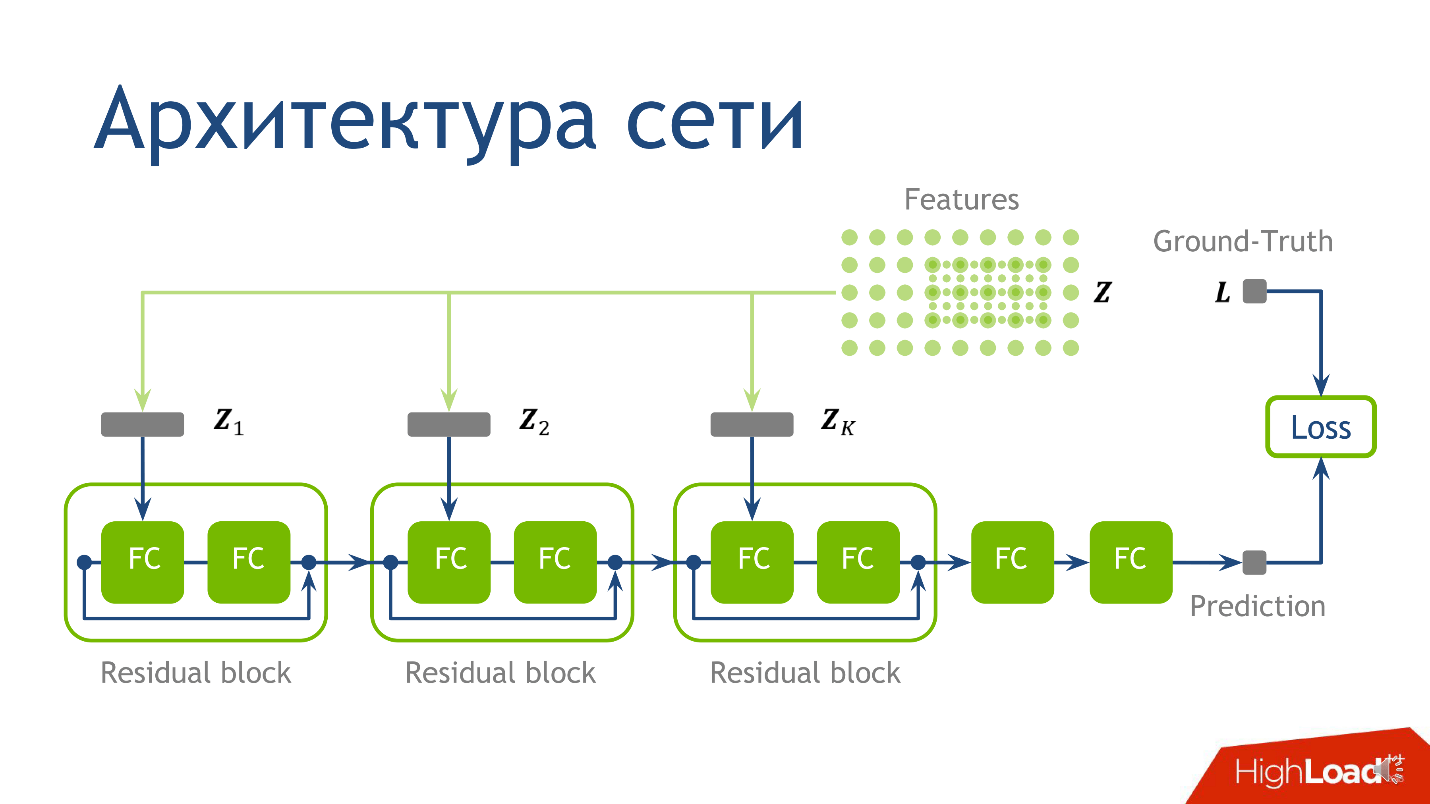
Tomamos um ponto, contamos os valores em cada uma das grades, colocamos os tensores obtidos no bloco residual correspondente - e você pode realizar
inferência da rede neural - modo de produção da rede. Fizemos isso e nos certificamos de tirar fotos de nuvens.
Resultados
A primeira observação - conseguimos o que queríamos: uma chamada de rede neural, comparada à estimativa de Monte Carlo, funciona mais rápido, o que já é bom.
Mas há outra observação sobre os resultados do treinamento - é a convergência no número de amostras. Do que você está falando?

Ao renderizar uma imagem, vamos cortá-la em pequenos blocos - quadrados de pixels, digamos 16 * 16. Considere um bloco de imagem sem perda de generalidade. Quando renderizamos esse bloco, para cada pixel da câmera, liberamos muitos raios correspondentes a um pixel e adicionamos um pouco de ruído aos raios para que eles sejam ligeiramente diferentes. Esses raios são chamados
anti-aliasing e são inventados para reduzir o ruído na imagem final.
- Liberamos vários raios anti-aliasing para cada pixel.
- Na parte interna do feixe da câmera, na nuvem, em um segmento, calculamos n amostras de pontos nos quais queremos realizar uma avaliação de Monte Carlo ou chamar uma rede para eles.
Ainda existem amostras que correspondem à conexão com as fontes de luz. Eles aparecem quando conectamos um ponto a uma fonte de luz, por exemplo, ao sol. Isso é fácil, porque o sol são os raios que caem na terra paralelos um ao outro. Por exemplo, o céu, como fonte de luz, é muito mais complicado, porque aparece como uma esfera infinitamente distante, que tem uma função de cor na direção. Se o vetor olhar diretamente para o céu, a cor é azul. Quanto mais baixo, mais brilhante. No fundo da esfera geralmente existe uma cor neutra que imita a terra: verde, marrom.
Quando conectamos um ponto ao céu para entender quanta luz entra nele, sempre liberamos alguns raios para obter uma resposta que converge para a verdade. Lançamos mais de um raio para obter uma nota melhor. Portanto, toda a
renderização do pipeline precisa de tantas amostras.
Quando treinamos a rede neural, percebemos que ela aprende uma solução muito mais média. Se fixarmos o número de amostras, veremos que o algoritmo clássico converge para a linha esquerda da coluna da imagem e a rede aprende à direita. Isso não significa que o método original seja ruim - apenas convergimos mais rapidamente. Quando aumentarmos o número de amostras, o método original estará cada vez mais próximo do que obtemos.
Nosso principal resultado que queríamos obter é um aumento na velocidade de renderização. Para uma nuvem específica em uma resolução específica com parâmetros de amostra, vemos que as imagens obtidas pela rede e pelo método clássico são quase idênticas, mas obtemos a imagem certa 800 vezes mais rápido.

Implementação
Existe um programa de código aberto para modelagem 3D -
Blender , que implementa o algoritmo clássico. Nós mesmos não escrevemos um algoritmo, mas usamos este programa: treinamos no Blender, anotando tudo o que precisávamos para o algoritmo. A produção também foi realizada no programa: treinamos a rede no
TensorFlow , transferimos para C ++ usando o TensorRT e já integramos a rede do TensorRT ao Blender, porque seu código é aberto.
Como fizemos tudo para o Blender, nossa solução possui todos os recursos do programa: podemos renderizar qualquer tipo de cena e muitas nuvens. As nuvens em nossa solução são definidas criando um cubo, dentro do qual determinamos a função de densidade de uma maneira específica para programas 3D. Otimizamos esse processo - densidade de cache. Se um usuário deseja desenhar a mesma nuvem em uma pilha de configurações diferentes de uma cena: sob diferentes condições de iluminação, com diferentes objetos no palco, ele não precisa recalcular constantemente a densidade da nuvem. O que aconteceu, você pode assistir ao
vídeo .
Concluindo, repito mais uma vez a idéia principal que eu queria transmitir:
se, durante muito tempo, no seu trabalho, você considera algo como um algoritmo computacional específico, e isso não combina com você - encontre o lugar mais difícil do código, substitua-o por uma rede neural e talvez isso ajude você.Redes neurais e inteligência artificial são um dos novos tópicos que discutiremos no Saint HighLoad ++ 2019 em abril. Já recebemos vários aplicativos sobre esse tópico e, se você tiver uma experiência interessante, não necessariamente em redes neurais, envie um aplicativo antes de 1º de março . Teremos o maior prazer em vê-lo entre os nossos oradores.
Para acompanhar como o programa é formado e quais relatórios são aceitos, assine o boletim . Nele, publicamos apenas coleções temáticas de relatórios, resumos de artigos e novos vídeos.