No
último artigo, examinamos as limitações e obstáculos que surgem quando você precisa escalar dados horizontalmente e ter uma garantia das propriedades ACID das transações. Neste artigo, falamos sobre a tecnologia FoundationDB e entendemos como isso ajuda a superar essas limitações ao desenvolver aplicativos de missão crítica.
O FoundationDB é um banco de dados distribuído NoSQL com transações ACID serializáveis que armazena pares de armazenamento de valores-chave classificados. Chaves e valores podem ser seqüências arbitrárias de bytes. Ele não tem um único ponto de incidência - todas as máquinas de cluster são iguais. Ele próprio distribui os dados entre os servidores de cluster e as escalas em tempo real: quando você precisa adicionar recursos ao cluster, basta adicionar o endereço da nova máquina nos servidores de configuração e o banco de dados os seleciona.
No FoundationDB, as transações nunca se bloqueiam. A leitura é implementada através
do controle de versão multiversão (MVCC), e a leitura é implementada através do
controle de concorrência otimista (OCC). Os desenvolvedores afirmam que, quando todas as máquinas do cluster estão no mesmo datacenter, a latência de gravação é de 2 a 3 ms e a latência de leitura é menor que um milissegundo. A documentação contém estimativas de 10 a 15 ms, o que provavelmente está mais próximo dos resultados em condições reais.
 * Não suporta propriedades ACID em vários shards.
* Não suporta propriedades ACID em vários shards.O FoundationDB tem uma vantagem única - o compartilhamento automático novamente. O próprio DBMS garante o carregamento uniforme de máquinas no cluster: quando um servidor está cheio, ele redistribui dados para os vizinhos em segundo plano. Ao mesmo tempo, a garantia do nível de serialização para todas as transações é preservada, e o único efeito perceptível para os clientes é um ligeiro aumento na latência das respostas. O banco de dados garante que a quantidade de dados nos servidores de cluster mais e menos carregados não seja superior a 5%.
Arquitetura
Logicamente, um cluster FoundationDB é um conjunto de processos do mesmo tipo em diferentes máquinas físicas. Os processos não possuem seus próprios arquivos de configuração e, portanto, são intercambiáveis. Vários processos fixos têm uma função dedicada - Coordenadores, e cada processo de cluster na inicialização conhece seus endereços. É importante que as falhas dos coordenadores sejam o mais independentes possível, portanto, é melhor colocá-las em máquinas físicas diferentes ou mesmo em data centers diferentes.
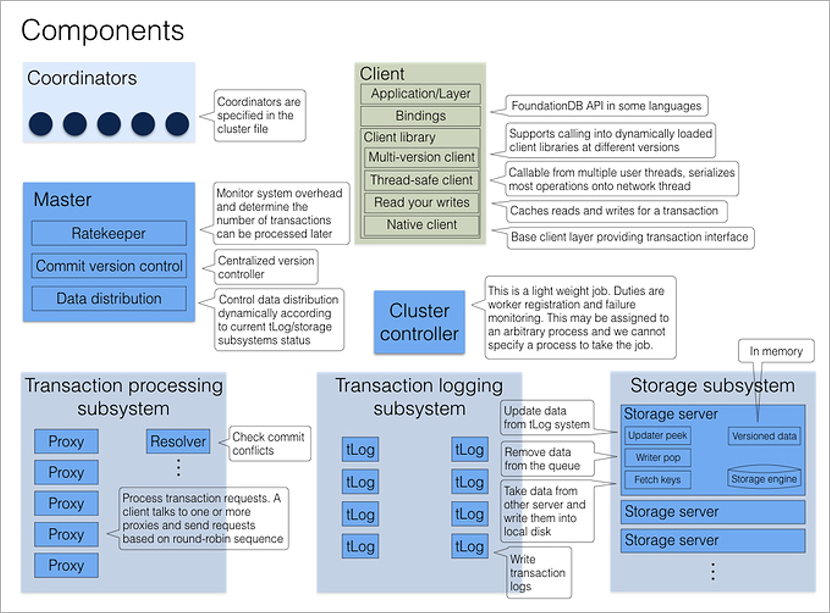
Os coordenadores concordam entre si através do algoritmo de consenso de
Paxos . Eles selecionam o processo do Cluster Controller, que atribui funções ao restante dos processos do cluster. O Controlador de Cluster informa continuamente a todos os Coordenadores que ele está vivo. Se a maioria dos coordenadores pensa que ele está morto, eles apenas escolhem um novo. Nem o Controlador de Cluster nem os Coordenadores estão envolvidos no processamento de transações; sua principal tarefa é eliminar a situação do
cérebro dividido .
Quando um cliente deseja se conectar ao banco de dados, ele imediatamente entra em contato com todos os coordenadores para o endereço do atual Cluster Controller. Se a maioria das respostas corresponder, ele receberá do Cluster Controller a configuração atual completa do cluster (se não corresponder, chamará novamente os coordenadores).
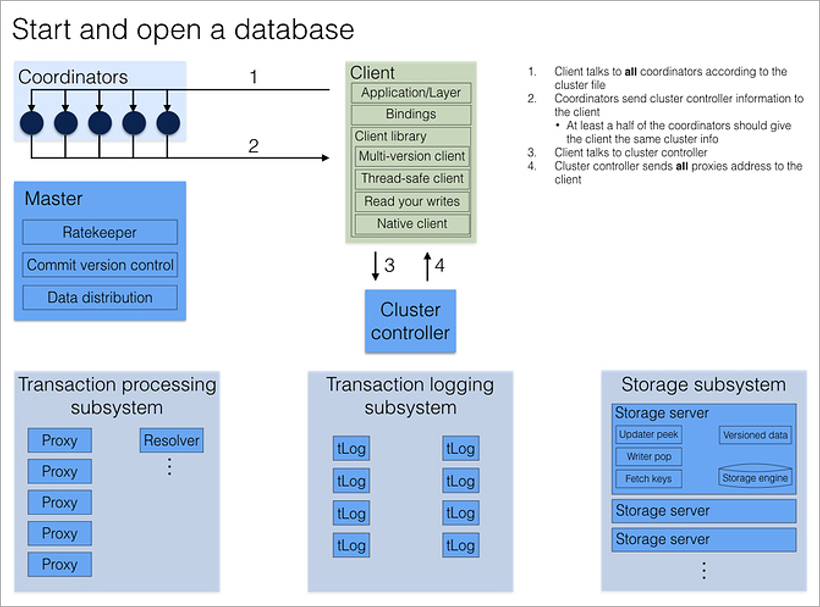
O Cluster Controller conhece o número total de processos disponíveis e distribui funções: esses 5 serão Proxy, esses 2 serão Resolver, este será Master. E se algum deles morrer, ele encontrará imediatamente um substituto para ele, atribuindo a função necessária a um processo livre arbitrário. Isso tudo acontece em segundo plano, invisível para o programador de aplicativos.
O processo Master é responsável pelo número da versão atual do conjunto de dados (aumenta a cada registro no banco de dados), bem como pela distribuição de muitas chaves nos servidores de armazenamento e pela otimização da taxa (desempenho artificialmente mais baixo sob cargas pesadas: se o cluster souber que o cliente fará muitos pedidos pequenos, ele irá esperar, agrupá-los e responder ao pacote inteiro de uma só vez).
O log de transações e o armazenamento são dois subsistemas de armazenamento independentes. O primeiro é o armazenamento temporário para gravar rapidamente dados no disco na ordem de recebimento, o segundo é o armazenamento permanente, onde os dados no disco são classificados em ordem crescente de chaves. Cada transação confirmada, pelo menos três processos tLog devem salvar dados antes que o cluster relate sucesso para o cliente. Paralelamente, os dados em segundo plano passam dos servidores tLog para os servidores de armazenamento (armazenamento no qual também é redundante).
Processamento de solicitação
Todas as solicitações do cliente processam processos de proxy. Ao abrir uma transação, o cliente acessa qualquer Proxy, pesquisa todos os outros Proxies e retorna o número da versão atual dos dados do cluster. Todas as leituras subsequentes ocorrem neste número de versão. Se outro cliente anotou os dados depois que eu abri a transação, simplesmente não vou ver suas alterações.
Gravar uma transação é um pouco mais complicado, pois você precisa resolver conflitos. Isso inclui o processo do Resolver, que armazena na memória todas as chaves modificadas por um determinado período de tempo. Quando o cliente conclui a transação de confirmação, o Resolver verifica se os dados que estavam lendo estão desatualizados. (Ou seja, se a transação que foi aberta depois da minha foi concluída e alterou as chaves que eu li.) Se isso acontecer, a transação será revertida e a própria biblioteca do cliente (!) Fará uma segunda tentativa de confirmação. A única coisa em que o desenvolvedor deve pensar é que as transações são idempotentes, ou seja, o uso repetido deve fornecer um resultado idêntico. Uma maneira de conseguir isso é salvar algum valor exclusivo dentro da transação e, no início da transação, verificar sua presença no banco de dados.
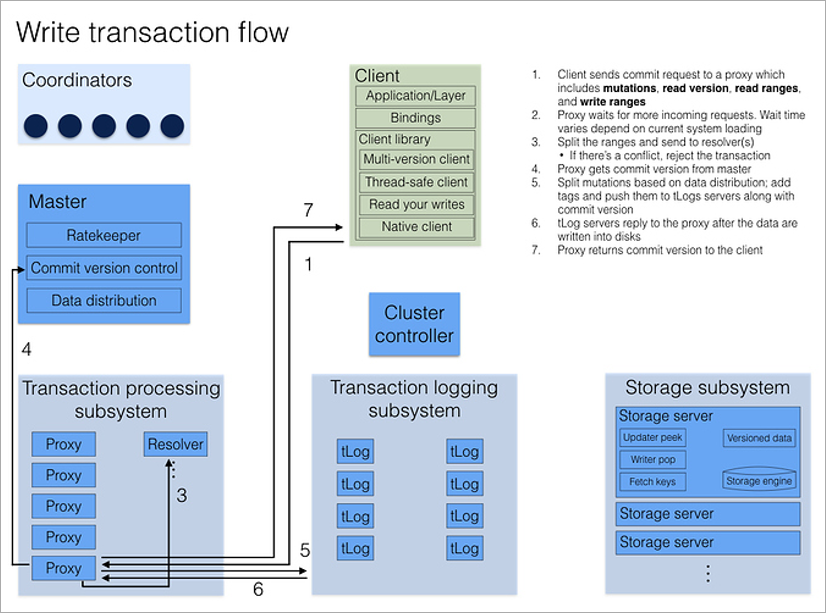
Como em qualquer sistema cliente-servidor, há situações em que a transação é concluída com êxito, mas o cliente não recebeu confirmação devido a uma desconexão. A biblioteca cliente os trata como qualquer outro erro - simplesmente tenta novamente. Isso pode levar à reexecução de toda a transação. No entanto, se a transação for idempotente, não há problema com isso - ela não afetará o resultado final.
Dimensionamento
Pode haver milhares de servidores em um subsistema de armazenamento. Qual deles um cliente deve entrar em contato quando precisar de dados em uma determinada chave? No Cluster Controller, o cliente conhece a configuração completa de todo o cluster e inclui intervalos de chaves em cada servidor de Armazenamento. Portanto, ele simplesmente acessa os servidores de armazenamento desejados diretamente, sem solicitações intermediárias.
Se o servidor de armazenamento desejado não estiver disponível, a biblioteca do cliente obterá uma nova configuração do Cluster Controller. Se, como resultado de uma falha no servidor, o cluster entender que a redundância é insuficiente, ele imediatamente começará a coletar um novo nó de partes de outro armazenamento.
Suponha que você salve um gigabyte de dados em uma transação. Como você pode fornecer uma resposta rápida? De maneira alguma e, portanto, o FoundationDB simplesmente limitou o tamanho de uma transação a 10 megabytes. Além disso, essa é uma restrição a todos os dados que a transação
diz respeito - lê ou grava. Cada entrada no banco de dados também é limitada - a chave não pode exceder 10 kilobytes, o valor é 100 kilobytes. (Ao mesmo tempo, para um desempenho ideal, os desenvolvedores recomendam chaves de 32 bytes e 10 kilobytes.)
Qualquer transação pode potencialmente se tornar uma fonte de conflito e, em seguida, terá que ser revertida. Portanto, por uma questão de velocidade, até que o comando commit chegue, faz sentido manter as alterações atuais na RAM e não no disco. Suponha que você esteja gravando dados em um banco de dados com uma carga de 1 GB / segundo. Em um caso extremo, seu cluster alocará 3 GB de RAM a cada segundo (gravamos transações em 3 máquinas). Como limitar um crescimento tão semelhante a uma avalanche de memória usada? É muito simples limitar o tempo máximo de transação. No FoundationDB, uma transação não pode durar mais de 5 segundos. Se o cliente tentar acessar o banco de dados 5 segundos após a transação ser aberta, o cluster ignorará todos os seus comandos até abrir um novo.
Índices
Suponha que você mantenha uma lista de pessoas, cada pessoa tenha um identificador exclusivo, que seja usado como chave e, no valor, escreva todos os outros atributos - nome, sexo, idade etc.
| Key | Valor |
| 12345 | (Ivanov Ivan Ivanovich, M, 35 anos) |
Como obter uma lista de todas as pessoas com 30 anos de idade sem pesquisa exaustiva? Geralmente, um índice é criado no banco de dados para isso. Um índice é outra visualização de dados projetada para procurar rapidamente atributos adicionais. Podemos simplesmente adicionar entradas do formulário:
Agora, para obter a lista que você precisa, basta pesquisar o intervalo de teclas (30, *). Como o FoundationDB armazena dados classificados por chave, essa consulta será executada muito rapidamente. Obviamente, o índice ocupa espaço em disco adicional, mas muito pouco. Observe que nem todos os atributos são duplicados, mas apenas a idade e o identificador.
É importante que as operações de adição do próprio registro e do índice sejam executadas em uma transação.
Confiabilidade
O FoundationDB é escrito em C ++. Os autores começaram a trabalhar nele em 2009, a primeira versão foi lançada em 2013 e, em março de 2015, a Apple os comprou. Três anos depois, a Apple abriu inesperadamente o código fonte.
Há rumores de que a Apple o usa, entre outras coisas, para armazenar dados de serviço do iCloud.
Desenvolvedores experientes geralmente não confiam imediatamente em novas soluções. Pode levar anos até que a tecnologia se estabeleça de forma confiável e comece a ser usada maciçamente em prod. Para reduzir esse tempo, os autores fizeram uma extensão interessante da linguagem C ++:
Flow . Ele permite emular normalmente o trabalho com componentes externos não confiáveis, com a possibilidade de uma repetição previsível completa da execução do programa. Cada chamada para uma rede ou disco é agrupada em algum wrapper (Actor) e cada ator possui várias implementações. A implementação padrão grava dados no disco ou na rede, conforme pretendido. E o outro grava no disco 999 vezes em 1000 e perde 1 vez em 1000. Uma implementação de rede alternativa pode, por exemplo, trocar bytes em pacotes de rede. Existem até atores que imitam o trabalho de um administrador de sistema descuidado. Isso pode excluir a pasta de dados ou trocar duas pastas. Os desenvolvedores
conduzem milhares de simulações , substituindo diferentes atores e usando o Flow atingem 100% de reprodutibilidade: se algum teste falhar, eles podem reiniciar a simulação e sofrer uma falha no mesmo local. Em particular, para eliminar a incerteza introduzida pelos threads de alternância do agendador do SO, cada processo do FoundationDB é estritamente de thread único.
Quando o
pesquisador , que descobriu
cenários de perda de dados em quase todas as soluções NoSQL populares , foi convidado a testar o FoundationDB, ele se recusou, observando que não entendia o motivo, porque os autores
fizeram um trabalho gigantesco e os
testaram muito mais profundamente e mais profundamente que o seu.
É habitual pensar que as falhas do cluster são aleatórias, mas os devops experientes sabem que isso está longe de ser o caso. Se você tiver 10 mil discos do mesmo fabricante e o mesmo número de outros, a taxa de falhas será diferente. No FoundationDB, é possível uma configuração chamada de reconhecimento de máquina, na qual é possível informar ao cluster quais máquinas estão no mesmo datacenter e quais processos estão na mesma máquina. O banco de dados levará isso em consideração ao distribuir a carga entre as máquinas. E máquinas em um cluster geralmente têm características diferentes. O FoundationDB também leva isso em consideração, analisa a duração das filas de solicitações e redistribui a carga de maneira equilibrada: máquinas mais fracas recebem menos solicitações.
Portanto, o FoundationDB fornece transações ACID e o mais alto nível de isolamento, serializável, em um cluster de milhares de máquinas. Juntamente com incrível flexibilidade e alto desempenho, parece mágica. Mas você tem que pagar por tudo, então existem algumas limitações tecnológicas.
Limitações
Além dos limites já mencionados sobre o tamanho e a duração da transação, é importante observar os seguintes recursos:
- A linguagem de consulta não é SQL, ou seja, os desenvolvedores com experiência em SQL terão que reaprender.
- A biblioteca do cliente suporta apenas 5 linguagens de alto nível (Phyton, Ruby, Java, Golang e C). Ainda não há um cliente oficial para C #. Como não há API REST, a única maneira de oferecer suporte a outro idioma é escrever um wrapper sobre ele na parte superior da biblioteca C padrão.
- Não há mecanismos de compartilhamento, toda essa lógica deve ser fornecida pelo seu aplicativo.
- O formato de armazenamento de dados não está documentado (embora geralmente também não esteja documentado em bancos de dados comerciais). Isso é um risco, porque, de repente, o cluster não é montado, então não está claro o que fazer e será necessário investigar os arquivos de origem.
- Um modelo de programação estritamente assíncrono pode parecer complicado para desenvolvedores iniciantes.
- Você precisa pensar constantemente na idempotência das transações.
- Se você precisar dividir transações longas em pequenas, precisará cuidar da integridade em nível global.
Traduzido do inglês, "Foundation" significa "Foundation" e os autores deste DBMS veem seu papel desta maneira: fornecer um alto nível de confiabilidade no nível de registros simples, e qualquer outro banco de dados pode ser implementado como um complemento da funcionalidade básica. Assim, no topo do FoundationDB, você pode criar diferentes outras camadas - documentos, gráficos etc. A questão permanece como essas camadas serão dimensionadas sem perder o desempenho. Por exemplo, os autores do CockroachDB já adotaram esse caminho - construindo uma camada SQL no topo do RocksDB (armazenamento de valor da chave local) e eles têm problemas de desempenho inerentes às junções relacionais.
Até o momento, a Apple desenvolveu e publicou duas camadas sobre o FoundationDB: a
Camada de documentos (suporta API MongoDB) e a
Camada de registros (armazena registros como conjuntos de campos no formato
Protocol Buffers , suporta índices, está disponível apenas em Java). É agradável e surpreendentemente surpreendente que a empresa historicamente fechada da Apple hoje siga os passos do Google e da Microsoft e publique o código fonte das tecnologias usadas no interior.
Perspectivas
Existe um conflito existencial no desenvolvimento de software: a empresa constantemente quer mudanças, melhorias do produto. Mas, ao mesmo tempo, ele quer um software confiável. E esses dois requisitos se contradizem, porque quando o software muda, os bugs aparecem e os negócios sofrem com isso. Portanto, se você puder confiar em alguma tecnologia comprovada e confiável e escrever menos código por conta própria, sempre vale a pena fazer isso. Nesse sentido, apesar de certas limitações, é legal poder não esculpir muletas em diferentes bancos de dados NoSQL, mas usar uma solução comprovada em produção com propriedades ACID.
Há um ano, estávamos
otimistas com outra tecnologia - o CockroachDB, mas ela não atendeu às nossas expectativas de desempenho. Desde então, perdemos o apetite pela idéia de uma camada SQL em relação a um armazenamento de valor-chave distribuído e, portanto, não examinamos cuidadosamente, por exemplo, o
TiDB . Planejamos experimentar cuidadosamente o FoundationDB como um banco de dados secundário para os maiores conjuntos de dados em nosso projeto. Se você já tem experiência no uso real do FoundationDB ou TiDB na produção, teremos o maior prazer em ouvir sua opinião nos comentários.