
Ao longo do ano passado, houve tantas publicações sobre microsserviços que seria uma perda de tempo dizer o que é e por que; portanto, o restante da discussão se concentrará na questão de como implementar essa arquitetura e por que ela foi enfrentada exatamente e quais problemas foram encontrados.
Tivemos grandes problemas em um pequeno banco: três monólitos python conectados por uma quantidade monstruosa de interações RPC síncronas com um grande volume de legado. Para resolver pelo menos parcialmente todos os problemas que surgem ao mesmo tempo, foi decidido mudar para uma arquitetura de microsserviço. Mas antes de decidir sobre essa etapa, você precisa responder 3 perguntas principais:
- Como dividir um monólito em microsserviços e quais critérios devem ser seguidos.
- Como os microsserviços interagem?
- Como monitorar?
Respostas realmente breves para essas perguntas serão dedicadas a este artigo.
Como dividir um monólito em microsserviços e quais critérios devem ser seguidos.
Essa questão aparentemente simples acabou determinando toda a arquitetura futura.
Como somos um banco, todo o sistema gira em torno de operações com finanças e várias coisas auxiliares. Certamente é possível transferir transações financeiras do ACID para um sistema distribuído com sagas , mas no caso geral é extremamente difícil. Assim, desenvolvemos as seguintes regras:
- Cumpra o S do SOLID para microsserviços
- A transação deve ser realizada inteiramente no microsserviço - nenhuma transação distribuída sobre os danos do banco de dados
- Para funcionar, o microsserviço precisa de informações de seu próprio banco de dados ou de uma solicitação
- Tente garantir a limpeza (no sentido de linguagens funcionais) para microsserviços
Naturalmente, ao mesmo tempo, era impossível satisfazê-los completamente, mas mesmo a implementação parcial simplifica bastante o desenvolvimento.
Como os microsserviços interagem?
Existem muitas opções, mas no final, todas elas podem ser abstraídas por simples "mensagens de troca de microsserviços", mas se você implementar um protocolo síncrono (por exemplo, RPC via REST), muitas das desvantagens do monólito permanecerão, mas as vantagens dos microsserviços dificilmente aparecerão. Portanto, a solução óbvia foi pegar qualquer intermediário de mensagens e começar. A escolha entre RabbitMQ e Kafka se baseou nesse último e aqui está o porquê:
- Kafka é mais simples e fornece um único modelo de mensagens - Publicar - inscrever-se
- É relativamente fácil obter dados do Kafka pela segunda vez. Isso é extremamente conveniente para depurar ou corrigir erros durante o processamento incorreto, bem como para monitorar e registrar.
- Uma maneira clara e simples de dimensionar o serviço: adicionadas partições ao tópico, lançando mais assinantes - o restante será feito pela kafka.
Além disso, quero chamar a atenção para uma comparação detalhada e de alta qualidade .
As filas no kafka + assincronia nos permitem:
- Desative brevemente qualquer microsserviço para atualizações, sem consequências visíveis para o resto
- Desligue qualquer serviço por um longo tempo e não se preocupe com a recuperação de dados. Por exemplo, o microsserviço de fiscalização caiu recentemente. Foi consertado após 2 horas, ele pegou as contas brutas de Kafka e processou tudo. Não era necessário, como antes, restaurar o que deveria acontecer lá e executar manualmente logs HTTP e uma tabela separada no banco de dados.
- Execute versões de teste de serviços com dados atuais da venda e compare os resultados de seu processamento com a versão do serviço na venda.
Como sistema de serialização de dados, escolhemos o AVRO, por que - descrito em um artigo separado .
Mas, independentemente do método de serialização escolhido, é importante entender como o protocolo será atualizado. Embora o AVRO suporte a resolução de esquema, não usamos isso e decidimos puramente administrativamente:
- Os dados nos tópicos são gravados e lidos apenas pelo AVRO, o nome do tópico corresponde ao nome do esquema (e o Confluent tem uma abordagem diferente - eles escrevem esquemas de ID AVRO do registro nos bytes altos da mensagem, para que possam ter diferentes tipos de mensagens em um tópico
- Se você precisar adicionar ou alterar dados, um novo esquema será criado com um novo tópico no kafka, após o qual todos os produtores mudarão para um novo tópico e serão seguidos pelos assinantes.
Armazenamos os circuitos AVRO em sub-módulos git e nos conectamos a todos os projetos kafka. Eles decidiram ainda não implementar um registro centralizado de esquemas.
PS: Os colegas fizeram a opção de código-fonte aberto, mas apenas com o esquema JSON, em vez do AVRO .
Algumas sutilezas
Cada assinante recebe todas as mensagens do tópico
Essa é a especificidade do modelo de interação Publicar - assinar - quando inscrito em um tópico, o assinante receberá todos eles. Como resultado, se o serviço precisar apenas de algumas das mensagens, ele precisará filtrá-las. Se isso se tornar um problema, será possível criar um roteador de serviço separado que distribuirá as mensagens em vários tópicos diferentes, implementando parte da funcionalidade RabbitMQ que não está no kafka. Agora, temos um assinante no python em um thread processando cerca de 7 a 5 mil mensagens por segundo, mas se você executar o PyPy, a velocidade aumentará para 11 a 15 mil / s.
Limitar a vida útil de um ponteiro em um tópico
Nas configurações do kafka, há um parâmetro que limita o tempo em que o kafka "lembra" onde o leitor parou - o padrão é 2 dias. Seria bom aumentá-lo para uma semana, para que, se o problema surgir durante as férias e 2 dias não forem resolvidos, isso não levaria a uma perda de posição no tópico.
Limite de tempo de confirmação de leitura
Se o leitor Kafka não confirmar a leitura em 30 segundos (um parâmetro configurável), o broker acreditará que algo deu errado e ocorre um erro ao tentar confirmar a leitura. Para evitar isso, ao processar uma mensagem por um longo tempo, enviamos confirmações de leitura sem mover o ponteiro.
O gráfico de conexões é difícil de entender.
Se você honestamente desenhar todos os relacionamentos no graphviz, existe um ouriço do apocalipse tradicional para microsserviços com dezenas de conexões em um nó. Para pelo menos, de alguma forma, tornar (o gráfico de conexões) legível, concordamos com a seguinte notação: microsserviços - ovais, tópicos de kafka - retângulos. Assim, em um gráfico, é possível exibir o fato da interação e seu tipo. Mas, infelizmente, não está ficando muito melhor. Portanto, esta questão ainda está em aberto.
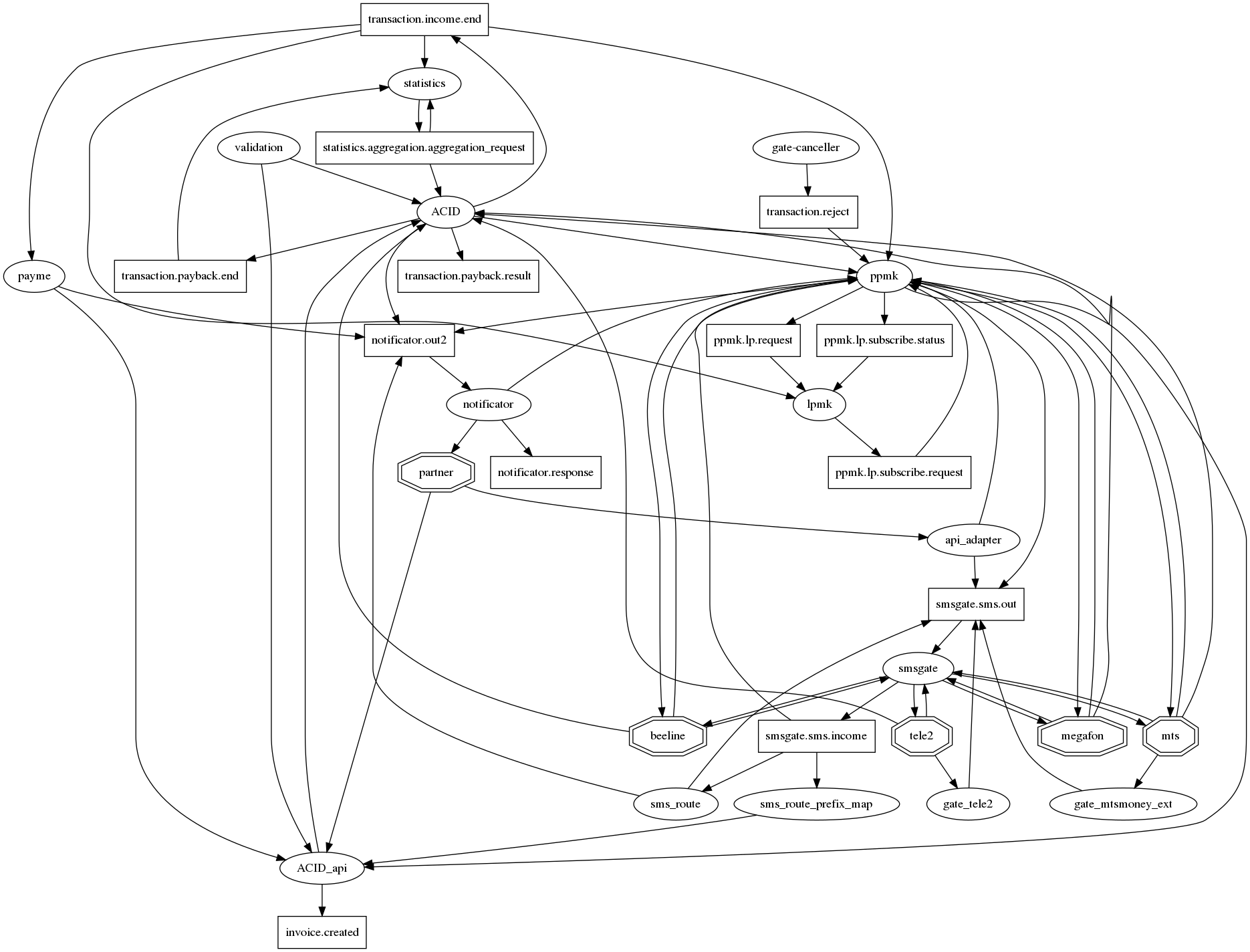
Como monitorar?
Mesmo como parte do monólito, tínhamos logs nos arquivos e no Sentry. Porém, quando mudamos para a interação através do Kafka e implantados nos k8s, os logs foram movidos para o ElasticSearch e, consequentemente, foram monitorados primeiro pela leitura dos logs do assinante no Elastic. Sem registros - sem trabalho.
Depois disso, eles começaram a usar o Prometheus e o kafka-exportador modificou levemente seu painel: https://github.com/kkirsanov/articles/blob/master/2019-habr-kafka/dashboard.json
Como resultado, obtemos essas imagens:
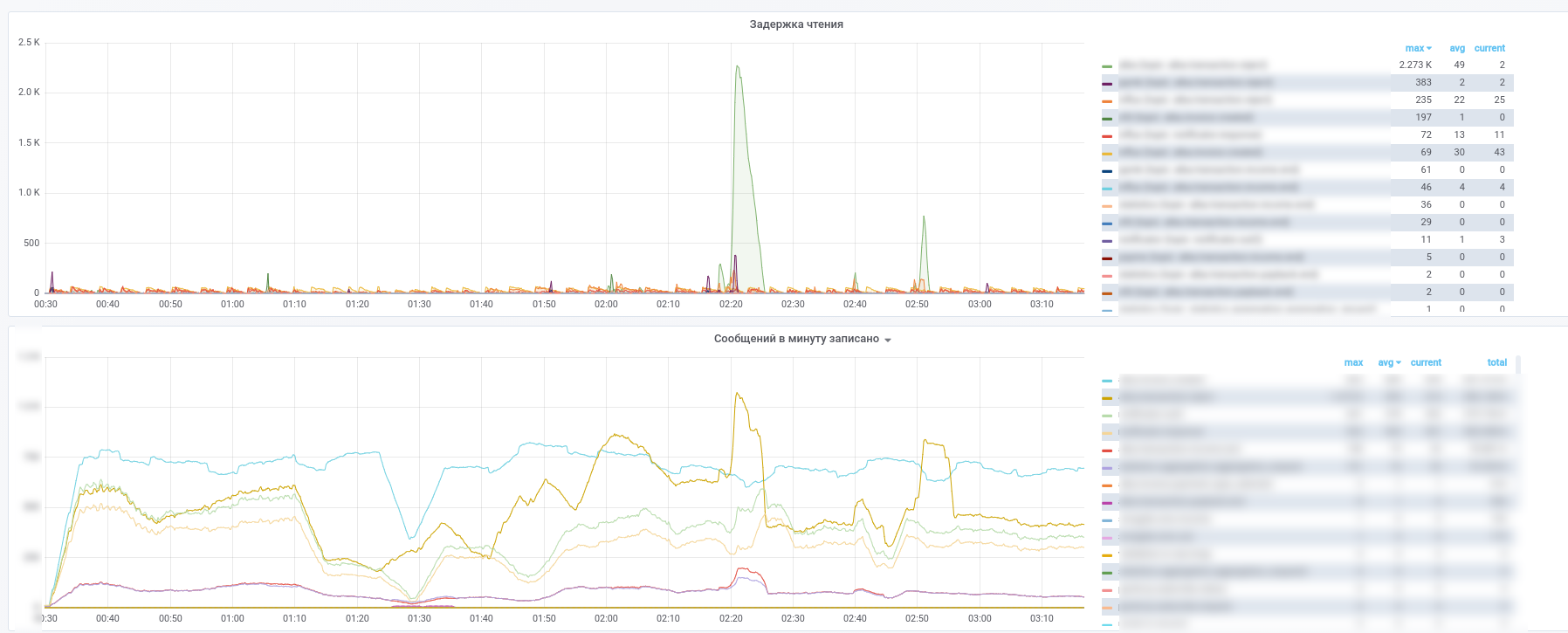
Você pode ver qual serviço parou de processar quais mensagens.
Além disso, todas as mensagens dos principais tópicos (transações de pagamento, notificações de parceiros etc.) são copiadas para o InfluxDB, configurado na mesma grafana. Portanto, não podemos apenas registrar o fato da passagem de mensagens, mas também fazer várias amostras de acordo com o conteúdo. Portanto, respostas para perguntas como "qual é o tempo médio de atraso para uma resposta de um serviço" ou "O fluxo de transações é muito diferente hoje de ontem nesta loja" estão sempre à mão.
Além disso, para simplificar a análise de incidentes, usamos a seguinte abordagem: cada serviço, ao processar uma mensagem, a complementa com meta-informações contendo o UUID emitido quando o sistema exibe uma matriz de registros do tipo
- nome do serviço
- UUID do processo de processamento neste microsserviço
- registro de data e hora de início do processo
- tempo de processo
- conjunto de tags
Como resultado, conforme a mensagem passa pelo gráfico computacional, a mensagem é enriquecida com informações sobre o caminho percorrido no gráfico. Acontece um análogo do zipkin / opentracing para MQ, que permite receber uma mensagem para restaurar facilmente seu caminho no gráfico. Isso adquire um valor especial nos casos em que os ciclos aparecem no gráfico. Lembre-se do exemplo de um serviço pequeno, cuja parcela de pagamentos é de apenas 0,0001% Ao analisar as metainformações da mensagem, ele pode determinar se foram o iniciador do pagamento, sem entrar em contato com o banco de dados para verificação.