O interesse na análise de imagens para gerar recomendações está aumentando a cada dia. Decidimos descobrir o quão real esse tema de tendência traz. Falamos sobre o teste do uso do aprendizado profundo (Deep Learning) para melhorar as recomendações de produtos relacionados.

Neste artigo, descrevemos a experiência de aplicar a tecnologia de análise de imagem para melhorar o algoritmo de produtos relacionados. Você pode lê-lo de duas maneiras: aqueles que não estão interessados nos detalhes técnicos do uso de redes neurais podem pular os capítulos sobre como criar um conjunto de dados e implementar soluções e ir diretamente para os testes AB e seus resultados. E aqueles que têm um entendimento básico de conceitos como casamentos, uma camada de uma rede neural, etc., estarão interessados em todo o material.
Aprendizado Profundo no Contexto da Análise de Imagem
Em nossa pilha de tecnologias, o Deep Learning é usado com êxito para resolver alguns problemas. Durante algum tempo, não ousamos aplicá-lo no contexto da análise de imagens, mas várias premissas surgiram recentemente que mudaram de idéia:
- maior interesse da comunidade na análise de imagens usando métodos de aprendizado profundo;
- foi definido um círculo de estruturas “maduras” e redes neurais pré-treinadas, a partir das quais se poderia começar de maneira rápida e simples;
- a análise de imagens em sistemas de recomendação tem sido frequentemente usada como um recurso de marketing que garante melhorias "sem precedentes";
- as necessidades alimentares começaram a aparecer nesse tipo de pesquisa.
No contexto da interseção de sistemas de recomendação e análise de imagem, pode haver muitas aplicações de aprendizado profundo; no entanto, na primeira etapa, identificamos para nós três maneiras principais de desenvolver essa área:
- Uma melhoria geral na qualidade das recomendações, por exemplo, produtos relacionados a um vestido, é mais qualitativamente adequada em cores e estilos.
- Encontrar mercadorias na base de produtos de uma loja usando uma fotografia (In Shop Retrieval) é um mecanismo que permite encontrar produtos no banco de dados de uma loja usando uma foto carregada.
- Determinação das propriedades / atributos do produto a partir da foto (marcação de atributo), quando atributos significativos são determinados a partir da foto, por exemplo, o tipo de produto - uma camiseta, jaqueta, calça, etc.
A direção mais prioritária e promissora para nós é a primeira opção, e decidimos explorá-la.
Por que você escolheu um algoritmo para produtos relacionados
Qualquer sistema de recomendação possui dois algoritmos básicos de mercadoria estática: alternativas e produtos relacionados. E se tudo estiver claro com as alternativas - estes são produtos semelhantes ao modelo original (por exemplo, diferentes tipos de camisas), então, com produtos relacionados, tudo fica muito mais complicado. É importante aqui não cometer erros com a correspondência entre os produtos básicos e os recomendados, por exemplo, o carregador deve caber no telefone, a cor do vestido nos sapatos, etc; você precisa considerar o feedback, por exemplo, não recomenda um telefone ao carregador, apesar do fato de que eles são comprados juntos; e pense em várias outras nuances que surgem na prática. Em grande parte devido à presença de várias nuances, nossa escolha recaiu sobre produtos relacionados. Além disso, somente em produtos relacionados é possível formar uma aparência completa, se falarmos sobre o segmento da moda.
Formulamos nosso principal objetivo de pesquisa como "Entendendo se o algoritmo atual para produtos relacionados pode ser significativamente aprimorado usando métodos de aprendizado profundo para análise de imagem"
Observo que, antes disso, não utilizávamos informações de imagem ao calcular recomendações de produtos, e aqui está o porquê:
- Durante a existência da plataforma Retail Rocket, adquirimos grande experiência no campo de recomendações de produtos. E a principal conclusão que recebemos durante esse período é que o uso correto do comportamento do usuário fornece quase 90% do resultado. Sim, há o problema de um começo a frio, quando são coisas de conteúdo, como informações sobre a imagem, que podem esclarecer ou melhorar as recomendações, mas, na prática, esse efeito é muito menor do que o que dizem teoricamente. Portanto, não colocamos muita ênfase nas fontes de informação de conteúdo.
- Para criar recomendações de produtos na forma de informações de conteúdo, usamos elementos como preço, categoria, descrição e outras propriedades que a loja nos transmite. Essas propriedades são independentes da esfera e são validadas qualitativamente ao integrar nosso serviço. O valor da imagem, pelo contrário, surge apenas no segmento de artigos de moda.
- Manter o serviço de trabalhar com fotos, validar sua qualidade e conformidade com as mercadorias é um processo bastante complicado e um sério dever técnico que eu não queria incorrer sem a confirmação da necessidade.
No entanto, decidimos dar uma chance às fotos e ver como elas afetarão a eficácia das recomendações de construção. Nossa abordagem não é ideal, com certeza alguém resolveria o problema de maneira diferente. O objetivo deste artigo é apresentar nossa abordagem com uma descrição dos argumentos em cada etapa e apresentar os resultados ao leitor.
Formação de conceito
Começamos cruzando os três componentes de qualquer produto: tecnologia acessível, recursos disponíveis e necessidades do cliente. O conceito de "melhorar as recomendações por meio de informações sobre a imagem de produtos relacionados" se desenvolveu por si só. A implementação "ideal" deste produto foi formada como um problema compilado na imagem de uma aparência selecionada. Além disso, essas recomendações não devem apenas parecer ótimas, mas também funcionar do ponto de vista das métricas básicas de comércio eletrônico (Conversão, RPV, AOV), não piores que o nosso algoritmo básico.
Look é uma imagem escolhida pelos estilistas, que inclui um conjunto de coisas diferentes que combinam entre si, por exemplo, um vestido, jaqueta, bolsa, cinto, etc. Do lado de nossos clientes, esse trabalho geralmente é realizado por pessoas especialmente designadas, cujo trabalho é mal automatizado. Afinal, nem toda rede neural pode ter um senso de gosto.
 Uma imagem de exemplo (aparência).
Uma imagem de exemplo (aparência).Imediatamente houve restrições ao uso das informações da imagem - de fato, a aplicação foi encontrada apenas no segmento de moda.
Infraestrutura e conjunto de dados
Primeiro, levantamos uma bancada de testes para experimentos e prototipagem. Tudo é bastante padrão GPU + Python + Keras aqui, por isso não entraremos em detalhes. Encontramos um conjunto de dados de alta qualidade, projetado para solucionar vários problemas ao mesmo tempo, desde a previsão de atributos da imagem até a geração de novas texturas de roupas. O que foi especialmente importante para nós, incluía fotografias que compunham praticamente um único olhar. Além disso, o conjunto de dados incluiu fotografias de modelos de roupas de diferentes ângulos, que tentamos usar no primeiro estágio.
 Exemplo de aparência de um conjunto de dados.
Exemplo de aparência de um conjunto de dados. Exemplos de imagens do mesmo modelo de roupas de diferentes ângulos.
Exemplos de imagens do mesmo modelo de roupas de diferentes ângulos.Primeiros passos
A primeira idéia de implementar o produto final usando o conjunto de dados foi bastante simples: “Vamos reduzir o problema à tarefa de reconhecer roupas por imagem. Assim, ao formular recomendações, "elevaremos" as recomendações semelhantes ao produto básico ". Nesse sentido, deveria encontrar a função de “proximidade” de mercadorias e, ao longo do caminho, resolver o problema de remover alternativas na questão.
Devo dizer imediatamente que esse tipo de problema poderia ser resolvido usando uma rede neural pré-treinada convencional, como o ResNet-50. De fato: removemos a última camada, obtemos casamentos, bem, e depois o cosseno, como uma medida de "proximidade". No entanto, tendo experimentado um pouco essa abordagem, decidimos deixá-la principalmente por três razões.
- Não está muito claro como interpretar corretamente a proximidade resultante. O que se diz cosseno = 0,7 no domínio das camisetas, onde, regra geral, tudo é muito semelhante um ao outro e o que é cosseno = 0,5 no domínio das jaquetas, onde as diferenças são mais significativas. Precisávamos desse tipo de interpretação para remover simultaneamente produtos muito próximos - alternativas.
- Essa abordagem nos limitou um pouco do ponto de vista da educação para nossas tarefas específicas. Por exemplo, os recursos importantes que formam uma imagem holística nem sempre são os mesmos de domínio para domínio. Em algum lugar, cor e forma são mais importantes, mas em algum lugar o material e sua textura. Além disso, queríamos treinar a rede para cometer menos erros de gênero quando as mulheres são recomendadas para roupas masculinas. Tal erro é imediatamente evidente e deve ser encontrado o mais raramente possível. Com o simples uso de redes neurais pré-treinadas, parecia que estávamos um pouco limitados pela incapacidade de fornecer exemplos bem "semelhantes" em termos de imagem.
- O uso de redes siamesas, que são mais adequadas para essas tarefas, parecia ser uma opção mais natural e bem estudada.
Um pouco sobre a rede neural siamesa
As redes neurais siamesas são amplamente usadas na resolução de tarefas relacionadas ao reconhecimento de faces. Na entrada, uma imagem da pessoa é fornecida, na saída, o nome da pessoa do banco de dados ao qual ela pertence. Esse problema pode ser resolvido diretamente, se você usar o softmax e o número de classes igual ao número de pessoas reconhecíveis na última camada da rede neural. No entanto, essa abordagem tem várias limitações:
- você precisa ter um número suficientemente grande de imagens para cada classe, o que é praticamente impossível.
- essa rede neural precisará ser retreinada toda vez que uma nova pessoa for adicionada ao banco de dados, o que é muito inconveniente.
Uma solução lógica em tal situação seria obter a função de "similaridade" das duas fotos para responder a qualquer momento se as duas fotos - fornecidas à entrada da rede neural e à referência do banco de dados - pertencem à mesma pessoa e, consequentemente, resolvem o problema do reconhecimento de rosto. Isso é mais consistente com o comportamento de uma pessoa. Por exemplo, um guarda olha para o rosto de uma pessoa e uma foto em um crachá e responde à pergunta se essa pessoa é uma ou não. A rede neural siamesa implementa um conceito semelhante.
O principal componente da rede neural siamesa é a rede neural de backbone, que gera uma incorporação de imagem. Essa incorporação pode ser usada para determinar o grau de similaridade entre as duas figuras. Na arquitetura da rede neural siamesa, o componente da espinha dorsal é usado duas vezes, cada vez para receber a incorporação da imagem. O pesquisador precisa mostrar os valores de saída 0 ou 1, dependendo se uma ou várias pessoas são as donas das fotos, e ajustar a rede neural do backbone.
 Um exemplo de uma rede neural siamesa. Os incorporamentos das imagens superior e inferior são obtidos a partir da espinha dorsal da rede neural. Imagem tirada do curso "Redes Neurais Convolucionais" de Andrey Ng.
Um exemplo de uma rede neural siamesa. Os incorporamentos das imagens superior e inferior são obtidos a partir da espinha dorsal da rede neural. Imagem tirada do curso "Redes Neurais Convolucionais" de Andrey Ng.Solução básica
Assim, após algumas experimentações, a primeira versão do algoritmo foi a seguinte:
- Tomamos qualquer rede neural pré-treinada como espinha dorsal. Experimentamos o ResNet-50 e o InceptionV3. Selecionado com base no equilíbrio do tamanho da rede e na precisão das previsões. Focamos nos dados apresentados na documentação oficial da seção Keras "Documentação para modelos individuais".
- Criamos uma rede siamesa e usamos Triplet Loss para treinamento.
- Como exemplos positivos, servimos a mesma imagem, mas de um ângulo diferente. Como exemplo negativo, estamos servindo outro produto.
- Tendo um modelo treinado, obtemos a métrica de proximidade para qualquer par de produtos da mesma maneira que a perda de trigêmeos é considerada.
Código de cálculo de perda tripla.O acordo com a Triplet Loss em um projeto real foi a primeira vez, o que criou várias dificuldades. A princípio, eles lutaram por um longo tempo com o fato de que todos os embeddings recebidos chegaram a um ponto. Havia várias razões: não normalizamos os casamentos antes de calcular a perda; margem, o parâmetro alfa era muito pequeno e os exemplos muito difíceis. Adicionado normalização e casamentos começaram a variar. O segundo problema inesperadamente se tornou Gradient Exploding. Felizmente, o Keras tornou possível resolver esse problema de maneira simples - adicionamos clipnorm = 1.0 ao otimizador, o que não permitia que os gradientes crescessem durante o treinamento.
O trabalho foi iterativo: treinamos o modelo, diminuímos a perda, analisamos o resultado final e decidimos habilmente em que direção estávamos indo. Em algum momento, ficou claro que montamos imediatamente exemplos bastante complexos e a complexidade não muda no processo de aprendizado, o que afeta negativamente o resultado final. Felizmente, o conjunto de dados com o qual trabalhamos tinha uma boa estrutura em árvore, que refletia o produto em si, por exemplo, Homens -> Calças, Homens -> Suéteres etc. Isso nos permitiu refazer o gerador e começamos a dar exemplos "fáceis" para as primeiras épocas, depois para as mais complexas e assim por diante. Os exemplos mais difíceis são produtos da mesma categoria de produto, por exemplo, Calças, como negativos.
Como resultado, obtivemos um modelo que diferia em sua produção da metodologia “ingênua” para usar o ResNet-50. No entanto, a qualidade das recomendações finais não nos convinha completamente. Primeiro, havia um problema com os erros de gênero, mas havia um entendimento de como isso poderia ser resolvido. Como o conjunto de dados dividiu as roupas em masculino e feminino, foi fácil coletar exemplos negativos para treinamento. Em segundo lugar, quando treinamos no conjunto de dados o resultado final, verificamos visualmente nossos clientes - ficou imediatamente claro que era necessário treinar novamente seus exemplos, pois para alguns o algoritmo funcionava muito mal se os produtos não se sobrepusessem bem ao que foi mostrado durante o treinamento . Finalmente, a qualidade era geralmente ruim, porque a imagem do treinamento era frequentemente barulhenta e continha, por exemplo, não apenas jeans, mas também uma camiseta.
 A imagem do jeans na qual de fato também mostra uma camiseta e botas.
A imagem do jeans na qual de fato também mostra uma camiseta e botas.A primeira experiência serviu de base para a solução subsequente, embora não tenhamos começado imediatamente a implementar um modelo aprimorado.
 Um exemplo de recomendações baseadas em uma solução básica. Existem erros de gênero, alternativas também surgem.
Um exemplo de recomendações baseadas em uma solução básica. Existem erros de gênero, alternativas também surgem.Modelo melhorado
Começamos treinando o ResNet-50 nos dados do nosso conjunto de dados. O conjunto de dados contém informações sobre o que é mostrado na figura. É extraído da estrutura do conjunto de dados Men -> Pants, Women -> Cardigans e mais. Esse procedimento foi realizado por dois motivos: primeiro, eles queriam "direcionar" o backbone - uma rede neural para o domínio do vestuário; segundo, como as roupas também são divididas por gênero, eles esperavam se livrar do problema dos erros de gênero encontrados na primeira versão.
No segundo estágio, tentamos remover simultaneamente o ruído das imagens de entrada e obter pares positivos de produtos relacionados para treinamento adicional. O conjunto de dados usado por nós também foi projetado para resolver o problema de detecção de objetos na imagem. Em outras palavras, para cada imagem existem: as coordenadas do retângulo que descrevem o objeto e sua classe. Para resolver esse tipo de problema, usamos um
projeto pronto . Este projeto usa a arquitetura de rede neural RetinaNet usando uma perda focal especial. A essência dessa perda é focar mais não no fundo da imagem, que está em quase todas as imagens, mas no objeto que precisa ser detectado. Como espinha dorsal de uma rede neural para treinamento, usamos nossa rede pré-treinada ResNet-50.
Como resultado, três classes de objetos são detectadas em cada imagem do conjunto de dados: "superior", "inferior" e "visão geral". Depois de definir as classes "superior" e "inferior", simplesmente cortamos a figura em duas figuras separadas, que mais tarde serão usadas como um par de exemplos positivos para o cálculo da perda de trigêmeos. A qualidade de detectar objetos era bastante alta, a única reclamação era que nem sempre era possível encontrar uma classe na imagem. Isso não foi um problema para nós, pois poderíamos aumentar facilmente o número de imagens para previsões.
 Um exemplo de detecção das classes “superior” e “inferior” e corte da imagem.
Um exemplo de detecção das classes “superior” e “inferior” e corte da imagem.Com esse tipo de divisor de imagens, tivemos a oportunidade de analisar qualquer aspecto da Internet e dividi-lo em componentes para uso em treinamento. Para aumentar a amostra de treinamento e derrotar o problema com uma cobertura insuficiente de exemplos que surgiram durante o desenvolvimento da solução básica, expandimos o conjunto de dados devido às imagens "cortadas" de um de nossos clientes. , “”, “ ”, “” . , . .
, , . -, backbone ResNet-50, . -, - , “” . , “” .
 , . — , .
, . — , .: , , . , . “” “”, “”. .
. “” ResNet-50. “” , — . .
 , “” ResNet-50. .
, “” ResNet-50. .ResNet-50 , . — threshold . , , . .
AB-
-. : “ , , — -”. : - — , ( ) . Retail Rocket - ( «
A/- 99% - ? »). - .
-. ,
RecSys 2016 . . , , , , . , - , .
, . , . , . - . , , , , - . : .
- , . -, , , , . -, — , , , , . , . , , , “», .
:
- “” “”, , , , . , , , .
- , . proof-of-concept , .
, , . , , .
AB-
, , - . — fashion. . , , . , , .
. 3 . , 95%.
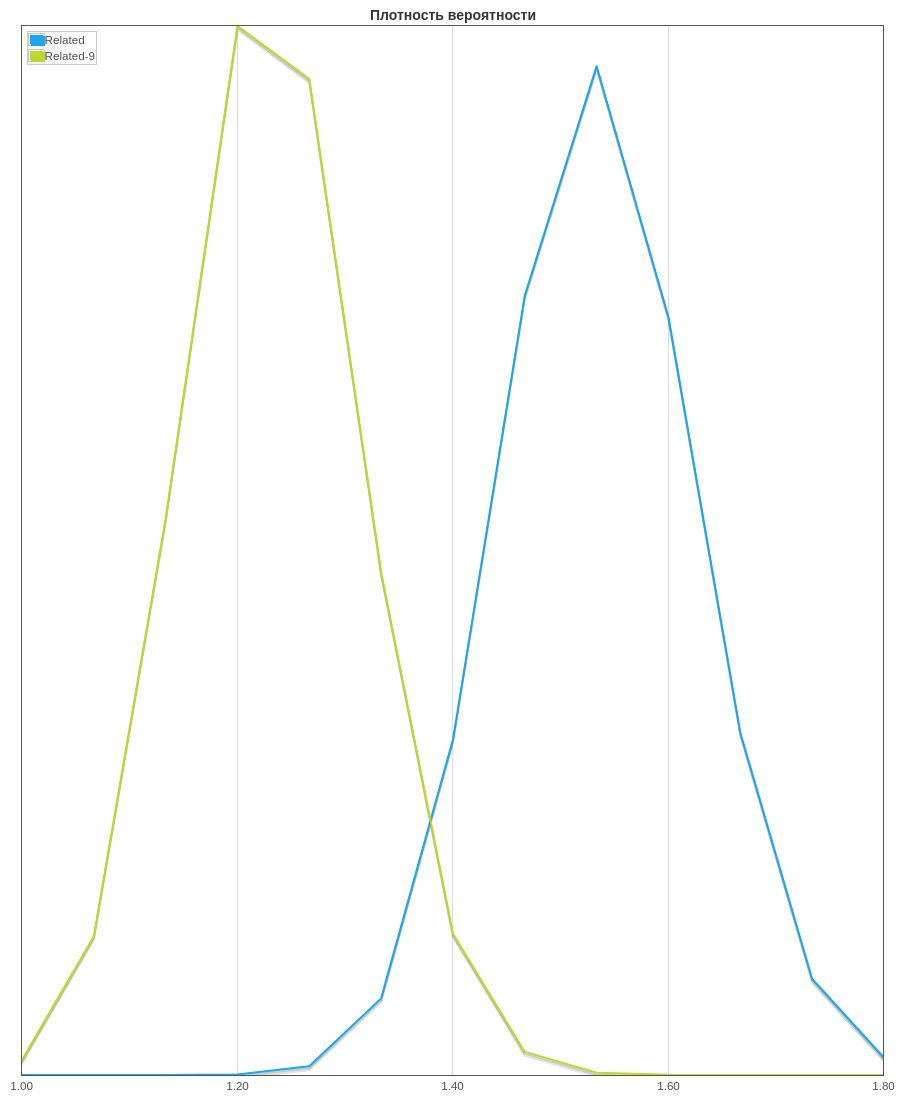
 . Related-9 — “” , Related — .
. Related-9 — “” , Related — . . Related-9 “” . : Mann-Whitney Test Bootstrap. 97%.
. Related-9 “” . : Mann-Whitney Test Bootstrap. 97%.: . , , , “” CTR. , , CTR , . - , - - , -. , .
 CTR. . CTR Related-9, “” , () Related — (). CTR ( ) — 95%.
CTR. . CTR Related-9, “” , () Related — (). CTR ( ) — 95%., , , , . , , . , , . .
Conclusões
, , . , , . - . , — — , . , . , , , Retail Rocket.
Como regra geral, ceteris paribus, lançamos algo que é mais simples e requer menos esforço de implementação, mesmo que "não esteja na moda". O mecanismo para extrair informações de imagens no nível do produto é um processo bastante complicado, por isso decidimos deixar a pesquisa nessa direção por um tempo até que haja novas informações. Por exemplo, a parte do início a frio mudará significativamente ou outras informações importantes aparecerão.Alexander Anokhin, analista, foguete de varejo