Você já se perguntou como os dados com os quais trabalha aparecem nas entranhas do Python? Sobre como as variáveis são criadas e armazenadas na memória? Como e quando eles são removidos? O material, cuja tradução publicamos, é dedicado à pesquisa nas profundezas do Python, durante as quais tentaremos descobrir os recursos de gerenciamento de memória nessa linguagem. Depois de estudar este artigo, você entenderá como funcionam os mecanismos de baixo nível dos computadores, especialmente aqueles relacionados à memória. Você entenderá como o Python abstrai operações de baixo nível e como ele gerencia a memória.

Saber o que está acontecendo no Python permitirá que você entenda melhor o comportamento dessa linguagem. Espero que isso dê a você a oportunidade de apreciar o enorme trabalho que está sendo feito na implementação da linguagem usada para que seus programas funcionem exatamente da maneira que você precisa.
A memória é um livro vazio
A memória do computador, no início de seu trabalho, pode ser representada na forma de um livro vazio destinado a contos. Embora não haja nada em suas páginas, mas em breve os autores das histórias aparecerão, cada um deles quer escrever sua própria história neste livro.
Como uma história não pode ser escrita em cima de outra, os autores precisam ter cuidado com as páginas do livro em que escrevem. Antes de escrever qualquer coisa, eles consultam o editor-chefe. Ele decide onde exatamente os autores podem gravar histórias.
Como o livro sobre o qual estamos falando já existe há algum tempo, muitas das histórias já estão desatualizadas. Se ninguém lê uma história ou a menciona em seus trabalhos, essa história é removida do livro, abrindo espaço para novas histórias.
Em geral, podemos dizer que a memória do computador é muito semelhante a esse livro. De fato, blocos contínuos de memória de tamanho fixo são chamados de páginas, então acreditamos que comparar a memória com um livro é muito bem-sucedido.
Os autores que escrevem suas histórias em um livro são aplicativos ou processos diferentes que precisam armazenar dados na memória. O editor-chefe, que decide em quais páginas do livro os autores podem escrever, é o mecanismo que lida com o gerenciamento de memória. E quem remove histórias antigas do livro, abrindo espaço para novas, pode ser comparado ao mecanismo de coleta de lixo.
Gerenciamento de memória: o caminho do ferro para os programas
O gerenciamento de memória é um processo durante o qual os programas gravam dados na memória e os lêem a partir deles. Um gerenciador de memória é uma entidade que determina onde exatamente um aplicativo pode colocar seus dados na memória. Como o número de fragmentos de memória que podem ser alocados para aplicativos não é infinito, assim como o número de páginas em qualquer livro não é infinito, o gerenciador de memória, que atende aos aplicativos, precisa encontrar fragmentos de memória livres e fornecê-los aos aplicativos. Esse processo, no qual a memória é alocada para aplicativos, é chamado de alocação de memória.
Por outro lado, quando alguns dados não são mais necessários, eles podem ser excluídos ou, em outras palavras, liberar a memória que ocupam. Mas o que exatamente eles “isolam” e “liberam” quando falam de memória?
Em algum lugar do seu computador, existe um dispositivo físico que armazena dados usados pelos programas Python enquanto eles trabalham. Antes de um objeto Python aparecer na memória física, o código precisa passar por muitas camadas de abstração.
Uma das principais camadas, localizada no topo do hardware (como RAM ou disco rígido), é o sistema operacional (SO). Ele executa (ou se recusa a atender) solicitações para ler dados da memória e gravar dados na memória.
Existe um aplicativo no topo do SO, no nosso caso, uma das implementações do Python (pode ser um pacote de software que faz parte do seu SO ou baixado do
python.org ). É este pacote de software que se dedica ao gerenciamento de memória, garantindo a operação do seu código Python. O foco deste artigo está nos algoritmos e estruturas de dados que o Python usa para gerenciar a memória.
Implementação de referência Python
A implementação de referência do Python é chamada CPython. Está escrito em C. Quando ouvi falar pela primeira vez, isso literalmente me perturbou. Uma linguagem de programação escrita em outra linguagem? Bem, na verdade, isso não é totalmente verdade.
A especificação Python é descrita em inglês simples
neste documento . No entanto, somente essa especificação, código escrito em Python, é claro, não pode ser executado. Para fazer isso, você precisa de algo que, seguindo as regras desta especificação, possa interpretar o código escrito em Python.
Além disso, você precisa de algo que possa executar o código interpretado no computador. A implementação de referência do Python resolve essas duas tarefas. Ele converte o código em instruções que são executadas na máquina virtual.
Máquinas virtuais são semelhantes a computadores comuns feitos de silício, metal e outros materiais, mas são implementadas em software. Eles geralmente estão ocupados processando instruções básicas, semelhantes às instruções escritas no
Assembler .
Python é uma linguagem interpretada. O código escrito em Python é compilado em um conjunto de instruções convenientes para o computador, no chamado
código de bytes . Essas instruções são interpretadas pela máquina virtual quando você executa seu programa.
Você já viu arquivos com a extensão
.pyc ou a pasta
__pycache__ ? Eles contêm o mesmo bytecode que é interpretado pela máquina virtual.
É importante observar que, além do CPython, existem outras implementações em Python. Por exemplo, ao usar o
IronPython, o código Python é compilado em uma instrução Microsoft CLR. No
Jython, o código é compilado no bytecode Java e executado em uma máquina virtual Java. No mundo Python, existe algo como
PyPy , mas é digno de um artigo separado, então aqui apenas mencionamos.
Para os fins deste artigo, focarei em como os mecanismos de gerenciamento de memória funcionam na implementação de referência do Python - CPython.
Deve-se notar que, embora a maior parte do que falaremos aqui seja verdadeira para novas versões do Python, as coisas podem mudar no futuro. Portanto, preste atenção ao fato de que neste artigo eu me concentro na versão mais recente do Python no momento da redação -
Python 3.7 .
Portanto, o pacote de software CPython é escrito em C e interpreta o bytecode do Python. O que isso tem a ver com gerenciamento de memória? O fato é que os algoritmos e as estruturas de dados usadas para o gerenciamento de memória existem no código CPython escrito, como já foi dito em C. Para entender como o gerenciamento de memória funciona no Python, primeiro você precisa entender um pouco sobre o CPython.
A linguagem C na qual o CPython é gravado não possui suporte interno para programação orientada a objetos. Por esse motivo, muitas soluções arquiteturais interessantes são usadas no código CPython.
Você deve ter ouvido falar que tudo no Python é um objeto, mesmo tipos de dados primitivos como
int e
str . E esse é realmente o caso no nível de implementação da linguagem no CPython. Existe uma estrutura chamada
PyObject , usada por objetos criados no CPython.
Uma estrutura é um tipo de dados composto que pode agrupar dados de diferentes tipos. Se você comparar isso com a programação orientada a objetos, a estrutura será semelhante a uma classe que possui atributos, mas não possui métodos.
PyObject é o ancestral de todos os objetos Python. Essa estrutura contém apenas dois campos:
ob_refcnt - contador de referência.ob_type - ponteiro para outro tipo.
O contador de referência é usado para implementar o mecanismo de coleta de lixo. Outro campo
PyObject é um ponteiro para um tipo específico de objeto. Esse tipo é representado por outra estrutura que descreve o objeto Python (por exemplo, pode ser do tipo
dict ou
int ).
Cada objeto possui um mecanismo exclusivo de alocação de memória, único para esse objeto, que sabe como obter a memória necessária para armazenar esse objeto. Além disso, cada objeto possui seu próprio mecanismo para liberar memória, o que "libera" a memória depois que ela não é mais necessária.
No entanto, deve-se notar que em todas essas conversas sobre alocação e liberação de memória, há um fator importante. O fato é que a memória do computador é um recurso compartilhado. Se, ao mesmo tempo, dois processos diferentes tentarem gravar algo na mesma área de memória, algo ruim poderá acontecer.
Bloqueio Global para Intérpretes
O Global Interpreter Lock (GIL) é uma solução para um problema comum que ocorre ao trabalhar com recursos compartilhados do computador, como memória. Quando dois threads tentam modificar simultaneamente o mesmo recurso, eles podem "colidir" entre si. O resultado será uma bagunça e nenhum dos fluxos alcançará o que estava buscando.
Vamos voltar à analogia do livro novamente. Imagine que dois autores decidiram arbitrariamente que agora era sua vez de fazer anotações. Mas eles também decidiram fazer anotações simultaneamente na mesma página.
Cada um deles não presta atenção ao fato de que o outro está tentando escrever sua história. Juntos, eles começam a escrever texto na página. Como resultado, duas histórias serão gravadas lá, uma em cima da outra, o que tornará a página completamente ilegível.
Uma das soluções para esse problema é um único mecanismo global de intérpretes que bloqueia recursos compartilhados com os quais um determinado encadeamento está trabalhando. No nosso exemplo, esse é um "mecanismo" que "bloqueia" a página de um livro. Esse mecanismo elimina a situação descrita acima, na qual dois autores escrevem simultaneamente texto na mesma página.
O mecanismo GIL no Python realiza isso bloqueando todo o intérprete. Como resultado, nada pode interferir na operação do encadeamento atual. E quando o CPython está trabalhando com memória, ele usa o GIL para garantir que esse trabalho seja realizado com segurança e eficiência.
Existem pontos fortes e fracos nessa abordagem, e o GIL é objeto de intenso debate na comunidade Python. Para saber mais sobre o GIL, você pode dar uma olhada
neste material .
Coleta de lixo
Vamos voltar à analogia do livro e imaginar que algumas das histórias registradas neste livro estão irremediavelmente desatualizadas. Ninguém os lê, ninguém os menciona em lugar nenhum. E se ninguém lê ou se refere a algum material em suas obras, esse material pode ser descartado, abrindo espaço para novos textos.
Esses contos antigos e esquecidos podem ser comparados a objetos Python cujas contagens de referência são zero. Esses são os mesmos contadores sobre os quais falamos ao discutir a estrutura do
PyObject .
O contador de links é incrementado por vários motivos. Por exemplo, o contador é incrementado se o objeto armazenado em uma variável for gravado em outra variável:
numbers = [1, 2, 3]
Aumenta quando o objeto é passado para alguma função como argumento:
total = sum(numbers)
E aqui está outro exemplo de uma situação em que o número no contador de referência aumenta. Isso acontece se o objeto estiver incluído na lista:
matrix = [numbers, numbers, numbers]
O Python permite ao programador descobrir o valor atual da contagem de referência de um determinado objeto usando o módulo
sys . Para isso, é utilizada a seguinte construção:
sys.getrefcount(numbers)
getfefcount() lo, lembre-se de que passar um objeto para o método
getfefcount() aumenta o valor do contador em 1.
De qualquer forma, se o objeto ainda for usado em algum lugar do código, seu contador de referência será maior que 0. Quando o valor do contador cair para 0, uma função especial entrará em jogo, o que "libera" a memória ocupada pelo objeto. Essa memória pode ser usada por outros objetos.
Agora nos perguntamos sobre o que é "liberar memória" e como outros objetos podem usar essa memória. Para responder a essas perguntas, vamos falar sobre os mecanismos de gerenciamento de memória no CPython.
Mecanismos de gerenciamento de memória no CPython
Agora, falaremos sobre como o CPython tem uma arquitetura de memória e como o gerenciamento de memória é feito lá.
Como já mencionado, existem várias camadas de abstração entre o CPython e a memória física. O sistema operacional abstrai a memória física e cria uma camada de memória virtual com a qual os aplicativos podem trabalhar (isso também se aplica ao Python).
O gerenciador de memória virtual de um sistema operacional específico aloca uma parte da memória para o processo Python. As áreas cinza escuras na imagem a seguir são os pedaços de memória que pertencem ao processo Python.
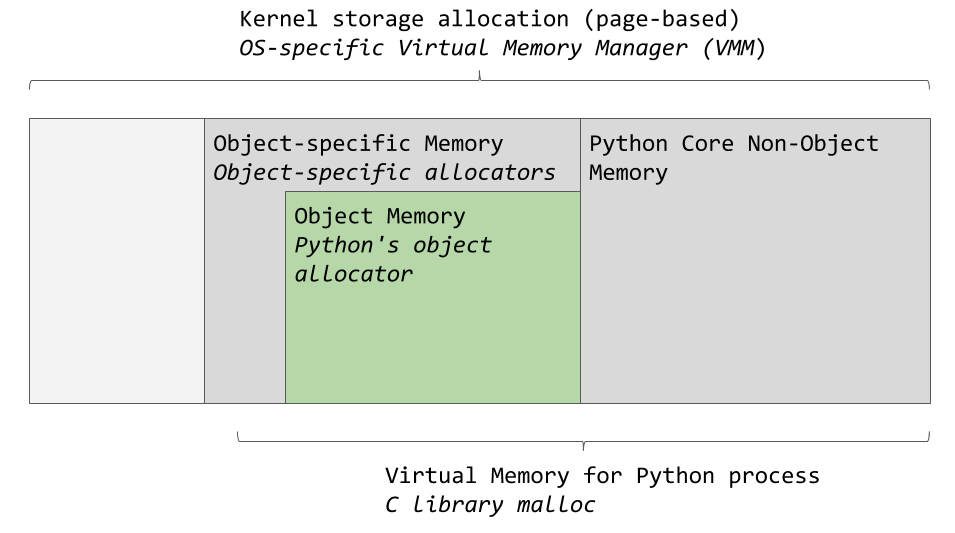 Áreas de memória usadas pelo CPython
Áreas de memória usadas pelo CPythonO Python usa uma certa quantidade de memória para uso interno e para necessidades não relacionadas à alocação de memória para objetos. Outra parte da memória é usada para armazenar objetos (esses são valores dos tipos
int ,
dict e outros assim). Observe que este é um diagrama simplificado. Se você quiser ver a imagem completa, dê uma olhada no código fonte do
CPython , onde tudo o que estamos falando está acontecendo.
O CPython possui um recurso para alocar memória para objetos, responsável por alocar memória na área destinada ao armazenamento de objetos. A coisa mais interessante acontece quando esse mecanismo funciona. É chamado quando o objeto precisa de memória ou nos casos em que a memória precisa ser liberada.
Normalmente, adicionar ou excluir dados de objetos Python como
list e
int não envolve o processamento simultâneo de grandes quantidades de informações. Portanto, a arquitetura da ferramenta de alocação de memória é criada com o olho no processamento de pequenas quantidades de dados. Além disso, essa ferramenta procura não alocar memória até que fique claro que é absolutamente necessário.
Os comentários no
código-fonte descrevem a ferramenta de alocação de memória como "uma ferramenta rápida e especializada de alocação de memória para pequenos blocos projetados para serem usados no topo do malloc universal". Nesse caso,
malloc é uma função da biblioteca C projetada para alocar memória.
Vamos discutir a estratégia de alocação de memória usada pelo CPython. Primeiro, falaremos sobre três entidades - os chamados blocos (blocos), piscinas (piscinas) e arenas (arena), e como elas se relacionam.
As arenas são os maiores fragmentos de memória. Eles estão alinhados nas bordas das páginas da memória. O limite da página é onde o bloco contínuo de memória de tamanho fixo termina em uso pelo sistema operacional. O Python, enquanto trabalha com memória, assume que o tamanho da página de memória do sistema é de 256 KB.
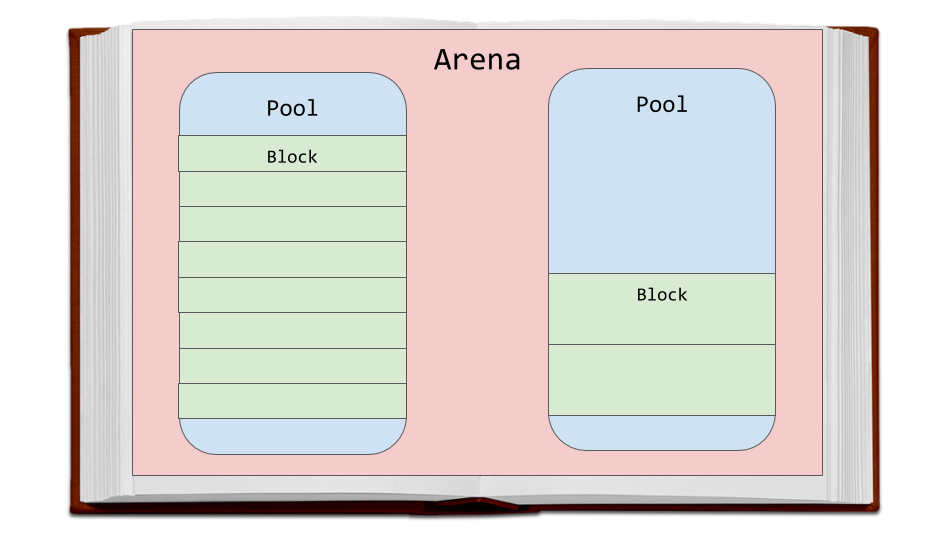 Arenas, Piscinas e Blocos
Arenas, Piscinas e BlocosOs pools estão localizados nas arenas, que são páginas de memória virtual de 4 KB. Eles se assemelham às páginas do livro do nosso exemplo. Os pools são divididos em pequenos blocos de memória.
Todos os blocos no mesmo pool pertencem à mesma classe de tamanho. A classe de tamanho à qual o bloco pertence determina o tamanho desse bloco, que é selecionado levando em consideração o tamanho da memória solicitada. Aqui está uma tabela tirada do código-fonte que demonstra a quantidade de dados que o sistema solicita para armazenar na memória, os tamanhos dos blocos alocados e os identificadores das classes de tamanho.
A quantidade de dados em bytes
| Tamanho do bloco
| tamanho da classe idx
|
1-8
| 8
| 0 0
|
9-16
| 16
| 1
|
17-24
| 24
| 2
|
25-32
| 32.
| 3
|
33-40
| 40.
| 4
|
41-48
| 48.
| 5
|
49-56
| 56.
| 6
|
57-64
| 64
| 7
|
65-72
| 72
| 8
|
...
| ...
| ...
|
497-504
| 504
| 62
|
505-512
| 512
| 63.
|
Por exemplo, se for solicitado que 42 bytes sejam armazenados, os dados serão colocados em um bloco de 48 bytes.
Piscinas
Pools consistem em blocos pertencentes à mesma classe de tamanho. Cada conjunto é associado a outros conjuntos que contêm blocos da mesma classe de tamanho usando o mecanismo de lista duplamente vinculado. Com essa abordagem, o algoritmo de alocação de memória pode encontrar facilmente espaço livre para um bloco de um determinado tamanho, mesmo que seja para encontrar espaço livre em conjuntos diferentes.
A lista
usedpools permite acompanhar todos os conjuntos nos quais há espaço para dados pertencentes a uma classe de tamanho específica. Quando é solicitado que você salve um bloco de um determinado tamanho, o algoritmo verifica essa lista em busca de uma lista de conjuntos que armazenam blocos do tamanho necessário.
As piscinas em si devem estar em um dos três estados. Ou seja, eles podem ser usados (estado
used ), podem ser preenchidos (
full ) ou vazios (
empty ). O pool usado possui blocos livres nos quais é possível salvar dados de tamanho adequado. Todos os blocos do pool preenchido são alocados para dados. Um conjunto vazio não contém dados e, se necessário, pode ser atribuído para armazenar blocos pertencentes a qualquer classe de tamanho.
A lista
freepools armazena informações sobre todos os conjuntos que estão no estado
empty . Por exemplo, se não houver entradas na lista
usedpools sobre pools que armazenam blocos de 8 bytes (classe com idx 0), um novo pool será inicializado, no estado
empty , projetado para armazenar esses blocos. Este novo pool é adicionado à lista de
usedpools usados e pode ser usado para atender a solicitações de salvamento de dados recebidos após sua criação.
Suponha que em um pool que esteja no estado
full , alguns blocos sejam liberados. Isso se deve ao fato de os dados armazenados neles não serem mais necessários. Esse pool estará novamente na lista
usedpools e pode ser usado para dados da classe de tamanho correspondente.
O conhecimento desse algoritmo nos permite entender como o estado dos conjuntos muda durante a operação (e como as classes de tamanho são alteradas, os blocos pertencentes aos quais podem ser armazenados neles).
Blocos
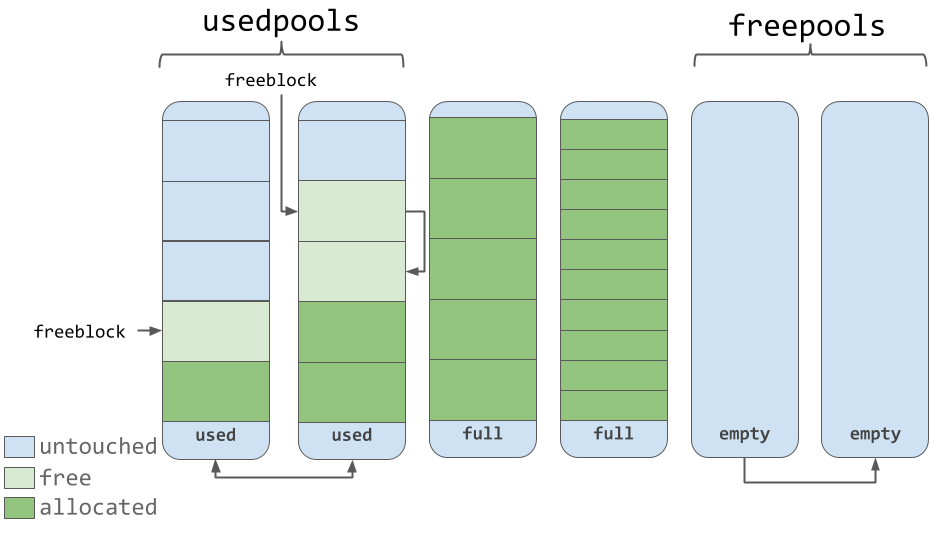 Piscinas usadas, cheias e vazias
Piscinas usadas, cheias e vaziasComo você pode ver na ilustração anterior, os pools contêm ponteiros para os blocos de memória "livres" que eles contêm. No que diz respeito ao trabalho com blocos, um pequeno recurso deve ser observado, indicado no código fonte. O sistema de gerenciamento de memória usado no CPython, em todos os níveis (arenas, conjuntos, blocos), esforça-se para alocar memória somente quando é absolutamente necessário.
Isso significa que os conjuntos podem conter blocos que estão em um dos três estados:
untouched é a parte da memória que ainda não foi alocada.free - a parte da memória que já foi alocada, mas depois foi liberada pelo CPython e não contém mais dados valiosos.allocated é a parte da memória que contém dados valiosos.
O ponteiro de
freeblock aponta para uma lista isolada de blocos de memória livre. Em outras palavras, esta é uma lista de lugares onde você pode colocar dados. Se mais de um bloco livre for necessário para colocar os dados, a ferramenta de alocação de memória retirará vários blocos do pool que estão no estado
untouched .
Como a ferramenta de gerenciamento de memória torna os blocos "livres", eles, quando adquirem o estado
free , chegam ao topo da lista de
freeblock . Os blocos contidos nesta lista não representam necessariamente uma região de memória contígua semelhante à mostrada na figura anterior. Eles podem realmente parecer com o abaixo.
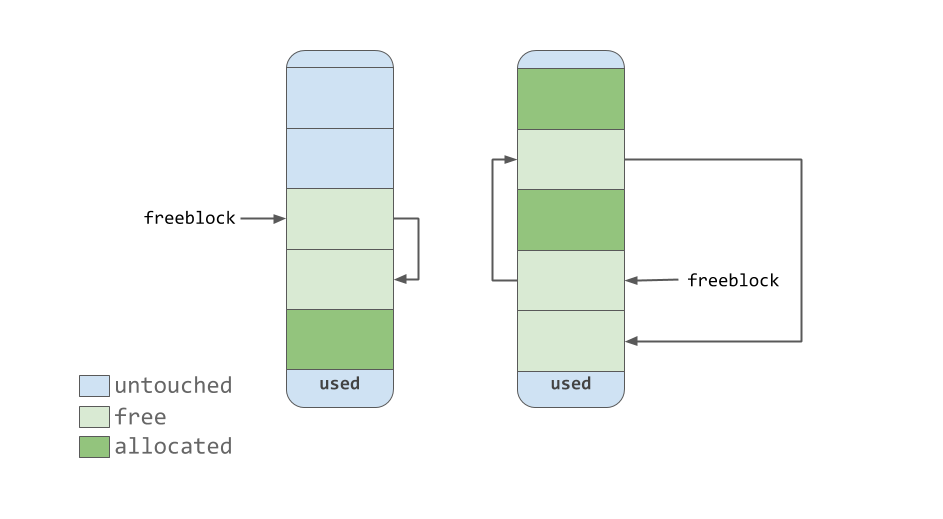 Lista de bloqueio gratuito vinculada única
Lista de bloqueio gratuito vinculada únicaArenas
Arenas contêm piscinas. Esses conjuntos, como já mencionado, podem residir nos estados
used ,
full ou
empty . Deve-se notar que as arenas não têm estados semelhantes aos das piscinas.
As arenas são organizadas em uma lista duplamente vinculada chamada
usable_arenas . Essa lista é classificada pelo número de pools gratuitos disponíveis. Quanto menos piscinas gratuitas na arena, mais próxima a arena fica do topo da lista.
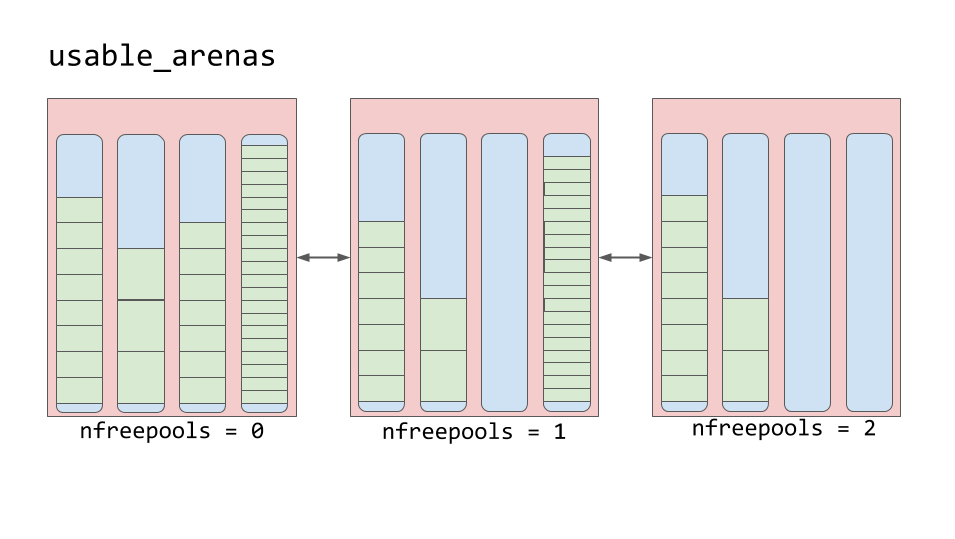 Lista de arenas utilizáveis
Lista de arenas utilizáveisIsso significa que a arena, mais forte que outras preenchidas com dados, será selecionada para colocar novos dados nela. E por que não vice-versa? Por que não postar novos dados na arena com mais espaço livre?
De fato, esse recurso nos leva à idéia de realmente liberar memória. Você deve ter notado que frequentemente usamos o conceito de "liberar memória" aqui, colocando-o entre aspas. A razão pela qual isso foi feito é que, embora o bloco possa ser considerado "livre", a parte da memória que ele representa não é realmente devolvida ao sistema operacional. O processo Python mantém esse pedaço de memória e depois o usa para armazenar novos dados. A verdadeira liberação da memória é o retorno do seu sistema operacional, que pode tirar vantagem disso.
As arenas são a única entidade no esquema considerado aqui, cuja memória representada pode ser verdadeiramente liberada. O senso comum determina que o esquema acima descrito de trabalhar com arenas visa permitir que as arenas quase vazias esvaziem completamente. Com essa abordagem, a parte da memória representada por uma arena completamente vazia pode ser realmente liberada, o que reduzirá a quantidade de memória consumida pelo Python.
Sumário
Aqui está o que você aprendeu lendo este material:
- O que é gerenciamento de memória e por que é importante.
- Como é organizada a implementação de referência do Python, Cpython, escrita na linguagem de programação C.
- Quais estruturas e algoritmos de dados são usados no CPython para gerenciamento de memória.
O gerenciamento de memória é parte integrante do trabalho dos programas de computador. O Python resolve quase todas as tarefas de gerenciamento de memória despercebidas pelo programador. O Python permite que qualquer pessoa que escreva nesta linguagem ignore os muitos pequenos detalhes relacionados ao trabalho com computadores. Isso dá ao programador a oportunidade de trabalhar em um nível superior, criar seu próprio código, sem se preocupar com o local onde seus dados estão armazenados.
Caros leitores! Se você tem experiência no desenvolvimento de Python, conte-nos como você aborda o uso de memória em seus programas. Por exemplo, você procura salvá-lo?
