Quase todos os sistemas de recomendação têm dificuldades com conteúdo novo ou raro - já que apenas uma pequena parte dos usuários interagiu com ele. Em seu relatório no
Yandex Inside, Daniil Burlakov compartilhou um conjunto de truques que são usados nas recomendações da Music e detalhou o popular modelo Singular Value Decomposition (SVD).
Além disso, temos artistas que são chamados de compositores e geralmente reprimidos por detentores de direitos autorais como um fã. Apenas Mozart havia "gravado" mais de um milhão de composições.
- Olá pessoal! Meu nome é Daniil Burlakov, lidero uma equipe de recomendações nos Serviços de Mídia. Hoje eu quero falar sobre alguns dos problemas que resolvemos quando lidamos com recomendações em Música.
Temos uma equipe maravilhosa que faz recomendações não apenas para o Yandex.Music, mas também para todos os serviços de mídia: o Kinopoisk, pôster. Resolvemos muito mais problemas técnicos do que recomendações.

Hoje, quero falar sobre o produto central Yandex.Music, nosso produto mais importante e favorito são as listas de reprodução inteligentes, que, provavelmente, muitos de vocês conhecem e ouvem.

Analisarei brevemente que tipo de playlists elas são e qual conteúdo as preenchemos.
A lista de reprodução do dia foi concebida como um conjunto de faixas que serão criadas para você todos os dias, para que você possa baixá-las e ouvi-las mesmo onde não há Internet. Mas será ótimo para você, estará com você e deve ser atualizado todos os dias e conter algo novo. O que combina com você.
Deja Vu é uma lista de reprodução mais interessante. Ele é atualizado uma vez por semana e haverá faixas que você nunca ouviu e artistas que você praticamente não conhece ou nem conhece. Premiere - uma seleção de novos produtos de seus artistas que você pode gostar.

O segundo produto é o Yandex.Radio. Em 2015, foi lançado, continuamos a desenvolvê-lo.
A idéia é permitir que o usuário obtenha um fluxo personalizado de músicas em áudio sem fazer nada. Na verdade, pressionei um botão e recebi um fluxo maravilhoso que nunca terminará e irá encantar você por muitas horas. Diferentemente das listas de reprodução, ele já pode ser marcado. Você pode, por exemplo, ligar o rádio por gênero - rock ou música de fundo, se não quiser se distrair durante o trabalho. Ou um fluxo de áudio totalmente personalizado - o que chamamos de rádio "On Your Wave".

Que problemas enfrentamos quando fazemos essas recomendações? Estamos diante de dois problemas principais, bastante comuns na maioria dos sistemas de recomendação. Esses são usuários frios que acabaram de chegar ao nosso serviço e sobre os quais ainda não sabemos nada e conteúdo interessante. Inclui não apenas faixas que apareceram recentemente, mas também um grande número de faixas raras. O catálogo Yandex.Music contém mais de 50 milhões de faixas, muitas delas ainda não foram ouvidas por nenhum usuário. Portanto, surge um problema: mesmo que a faixa tenha saído por tempo suficiente, infelizmente, talvez não saibamos nada sobre essa faixa e não tenhamos estatísticas.
Ambos os problemas foram especialmente agravados e se tornaram especialmente importantes para nós, pois o Yandex.Music se tornou um serviço internacional e começou a ir para muitos países. Ao entrar em cada país, o conteúdo local desse país se torna, antes de tudo, muito importante. É claro que, quando você entra em um novo país, ignorar a música local é bastante desagradável. É necessário recomendar, recomendar adequadamente e entender a estrutura dessa música interna. De fato, na Rússia, ninguém ouve música israelense, e há muito poucas estatísticas sobre ela, mesmo que tenhamos esse conteúdo.
Vamos examinar essas questões. Vamos começar com o problema dos usuários frios. Como pode ser resolvido?

A primeira solução mais simples é não recomendar nada aos usuários frios. De fato, a solução é muito simples, basta perguntar sobre preferências explícitas. Esses são vários assistentes que podem ser fornecidos ao usuário.
antes que o usuário receba sua primeira lista de reprodução do dia, solicitamos que ele passe por esse assistente, indicando suas preferências, um conjunto de gêneros e artistas que ele gostaria.
Como resultado, a primeira lista de reprodução do usuário se torna bastante significativa, adequada para o usuário e, muito provavelmente, desde a primeira lista de reprodução, o usuário se apaixonará por ele.
Infelizmente, essa abordagem nem sempre pode ser feita.

Nosso segundo produto, Yandex.Radio, foi concebido como um produto que não requer esforço do usuário. Ele só quer vir e ligar a música sem fazer nada. Além disso, o Yandex.Radio está incorporado em muitos outros sistemas, como o Yandex.Drive, onde é bastante estranho e inconveniente simplesmente forçar o usuário a sentar no carro, clique em algum tipo de assistente se ele chegar lá.
Portanto, seguimos o outro caminho. Começamos com recomendações, digamos, para o usuário médio, para que a maioria dos usuários das primeiras faixas tenha o máximo prazer e eles gostem da música. E nós fornecemos personalização muito rápida. Ao contrário da lista de reprodução que você recebeu e ele está com você o dia todo, todas as suas 60 faixas. E se, por exemplo, não adivinhamos o fato de que seu gênero favorito é música popular (o que será um bom palpite para começar), todas as 60 faixas não serão sobre você, e será triste, e provavelmente amanhã você não volte.
No entanto, se colocarmos a primeira faixa de música popular no rádio e você disser que não deseja ouvi-la, personalizaremos instantaneamente a próxima faixa para você e ofereceremos outra coisa, por exemplo, rock ou outro gênero.
Na verdade, essas duas soluções fecham o problema dos usuários frios em um grau ou outro.
Como o problema do conteúdo poderia ser resolvido por analogia? A solução número um, assim como os usuários, não é recomendar conteúdo interessante. Mas aqui, diferentemente dos usuários, o conteúdo em si não é captado e não esquenta. Portanto, o problema é que, se nós mesmos não coletarmos estatísticas sobre ele, o novo produto do artista que acabou de ser lançado não será entregue e os usuários que não viram as notícias do artista provavelmente ficarão chateados.

Uma situação semelhante com conteúdo internacional. Fomos para um novo país, e não o recomendamos, na verdade, ignorar esse conteúdo, obviamente, não nos convém.
A segunda solução, se agirmos completamente por analogia, recomende-a de alguma forma, em média. A analogia mais simples é excluir esse conteúdo para todos em uma fila ou recomendá-lo como música popular. Com a opção de recomendar, em média, geralmente não está muito claro o que é música média. Isso pode ser chamado de música popular pela força, mas dificilmente se pode dizer que toda a música é tão parecida uma com a outra, que parece com a música popular. Portanto, se você encontrar uma composição de Beethoven entre a música popular, é improvável que a maioria das pessoas fique feliz em recebê-la. Portanto, esta solução também não é adequada para nós.

O que mais há sobre as faixas? Junto com a faixa em si, muitos metadados chegam até nós do detentor dos direitos autorais, como o gênero da faixa, artista, álbum e ano de lançamento. Vamos lá. Como eles poderiam ser usados? Por exemplo, um gênero. Um gênero é uma boa informação que nos permite adivinhar mais ou menos. Por exemplo, resolve o problema de Beethoven ou de uma canção que acidentalmente apareceu em alguém no rádio: conhecemos o gênero da faixa e é improvável que o coloquemos naqueles a quem não se encaixa.
Mas, infelizmente, ele não permite construir uma boa recomendação, porque o conceito do gênero em si é bastante subjetivo e não permite a criação de boas recomendações com base nele. Naturalmente, existem muitos subgêneros dentro dos gêneros, e é exatamente isso que os detentores de direitos autorais nos enviam.

O segundo problema é que uma pessoa comum geralmente pode nomear uma dúzia de gêneros, enquanto os detentores de direitos autorais nos enviam muitos milhares de gêneros, e esse é um problema grande o suficiente para agrupá-los de alguma forma, encontrar outros similares e assim por diante. Infelizmente, esse problema nem sempre é resolvido.
Obviamente, há problemas com o fato de que, infelizmente, os detentores de direitos autorais geralmente ficam confusos e cometem erros. E temos problemas e relatos regulares de que coletamos faixas populares no rádio rock, e o detentor dos direitos autorais colocou o gênero rock nelas. Por analogia, coletamos jazz e outras estações de rádio. E regularmente temos relatórios de usuários que precisam ser corrigidos, porque uma faixa com erro voou para essas estações de rádio.
Quero oferecer a você que adivinhe o gênero da faixa.
Esta não é uma trilha sonora. Isso é metal. E temos um grande problema quando eles nos enviam essa marcação.
Proponho ir para a próxima parte e falar sobre os artistas da faixa. Eu já disse que há um problema, que um novo artista, uma nova faixa ou álbum sai, e isso deve ser recomendado. Em particular, informações sobre o artista sempre nos salvarão. Sabemos que o usuário ouviu esse artista e podemos recomendar a ele de acordo. Então nós fazemos. No entanto, também existem dificuldades. Por exemplo, se não sabíamos nada sobre o próprio artista ou o usuário não o ouvia, as informações que essa faixa possui e esse artista não nos dizem nada. Da mesma forma com faixas raras. Havia uma faixa rara de um artista raro, aprendemos que agora essa faixa rara pertence a ele. Infelizmente, novamente, não há muitas informações que permitirão que ele seja de alguma forma recomendado para outras pessoas que não estão familiarizadas com seu trabalho.

O segundo problema são capas e remixes. Mais uma vez, detestáveis detentores de direitos autorais intervêm aqui e geralmente cometem erros. Em particular, quando temos uma faixa original e sua capa, os detentores de direitos autorais geralmente não se dão ao trabalho de nomeá-las de maneiras diferentes, para assinar que uma delas é um remix ou até mesmo colocar artistas diferentes, quando é.
Quero oferecer a você duas faixas para entender o quão diferente é o som das faixas chamadas exatamente da mesma. Assim, temos duas faixas que podem ser chamadas de semelhantes, elas têm um ritmo relativamente semelhante, um texto relativamente semelhante, mas são diferentes. E para nós é uma e a mesma faixa, porque seu nome, artista e tudo mais são exatamente iguais.
Além disso, temos artistas perversos que são chamados de compositores e geralmente reprimidos por detentores de direitos autorais como um fã. Apenas Mozart havia "gravado" mais de um milhão de composições. É claro que para os amantes da música clássica isso não será possível. Se o usuário disse que gosta de Mozart, temos milhões de faixas, várias re-performances de melodias clássicas padrão. Como resultado, dificilmente podemos fazer algo sobre isso.

Quero contar mais a você como esse problema pode ser resolvido, mas, para começar, vamos relaxar nossos requisitos. Queríamos recomendar faixas que ninguém ouvia, e agora vamos pensar em como recomendar apenas faixas que seriam raras. A filtragem colaborativa vem em nosso auxílio aqui. Como funciona e o que obtemos no final?
Para começar, precisamos criar uma matriz de classificações de usuários, onde haverá usuários nas linhas, haverá faixas nas colunas, na interseção da coluna e na linha onde haverá sua classificação. É claro que para a maioria da matriz não sabemos o feedback do usuário, os usuários não puderam ouvir todo o nosso catálogo nem de perto.
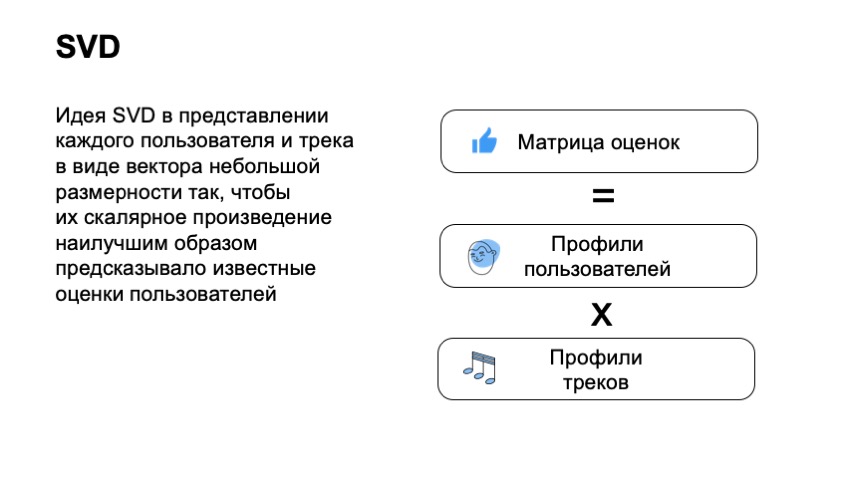
Com essa matriz, queremos que o usuário e a faixa associem vetores pequenos e curtos o suficiente para que o produto escalar do vetor do usuário e do vetor do item preveja bem a classificação do usuário. Assim, obtemos que para cada item e para cada usuário, precisamos encontrar dois vetores para que seu produto final preveja melhor nossa estimativa. Por exemplo, se neste caso dissermos que o usuário gostou da faixa - é 1, se não gostou - 0. E, neste caso, podemos realmente aplicar a técnica padrão, decomposição SVD e obter vetores ideais para os usuários e para as faixas.

O que isso nos dá? isso nos dá a próxima grande vantagem. Para a maioria das abordagens, não podemos dizer que as duas faixas são semelhantes se ninguém escutou juntas. Geralmente, uma parte significativa das abordagens se baseia no fato de termos alguns usuários que interagiram com os itens A e B, e vemos que eles são semelhantes como resultado disso. A filtragem colaborativa na forma de SVD nos permite fazer isso, mesmo que nenhum usuário tenha ouvido duas faixas juntas. Eles nos permitem avaliar muito bem. Esta é a primeira vantagem.
O que isso nos dá? Tendo um vetor de faixa, podemos recomendá-lo a um círculo muito maior de pessoas e recomendar faixas muito menos populares. E a vantagem principal, ainda temos uma representação vetorial das faixas, o que é muito conveniente para trabalhar, com o qual você pode procurar rapidamente por trilhas semelhantes.
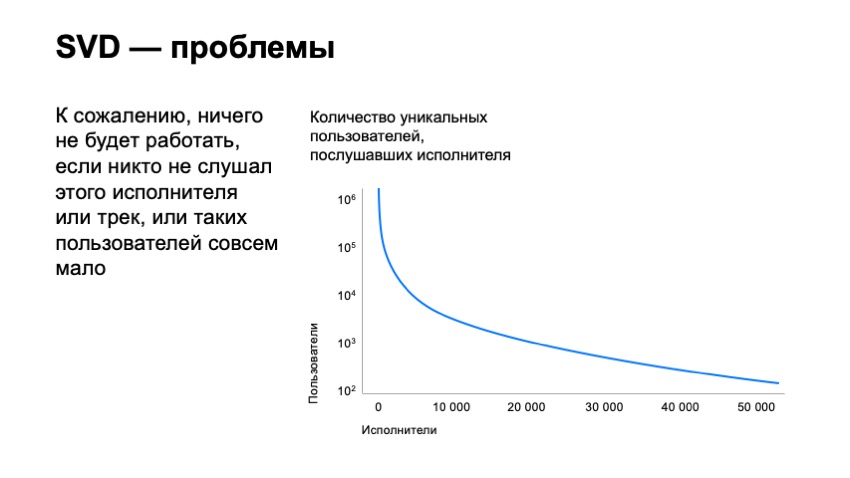
No entanto, isso não resolve todos os nossos problemas. apenas movemos a barra levemente para o número de faixas que podemos recomendar. Se criarmos um gráfico do número de usuários que ouviram os artistas, e classificarmos os artistas de acordo com sua popularidade, veremos que milhões de usuários estão ouvindo os artistas de melhor desempenho em nosso serviço. Se já olharmos para a décima milésima posição desses artistas, haverá apenas mil usuários. Se olharmos para o 50.000º artista, haverá apenas uma centena de usuários. É claro que suas faixas terão apenas dezenas de usuários que o ouviram, o que de fato torna impossível recomendá-las, já que o vetor SVD para essas faixas será extremamente instável e não funcionará.
Como podemos tentar resolver isso? O que nós queremos?
Queremos pegar uma trilha nova e rara que não sabemos nada sobre, por exemplo, uma trilha rara de Israel, e queremos obter algum tipo de representação vetorial para ela, que seria muito semelhante ao nosso vetor SVD, o que é muito conveniente para trabalhar. e faça recomendações.
A única coisa que não consideramos é o áudio dessa faixa. Graças ao áudio, podemos recomendar as faixas. Como poderíamos, usando uma faixa de áudio, obter um vetor SVD. a primeira coisa que queremos fazer é uma pequena conversão.
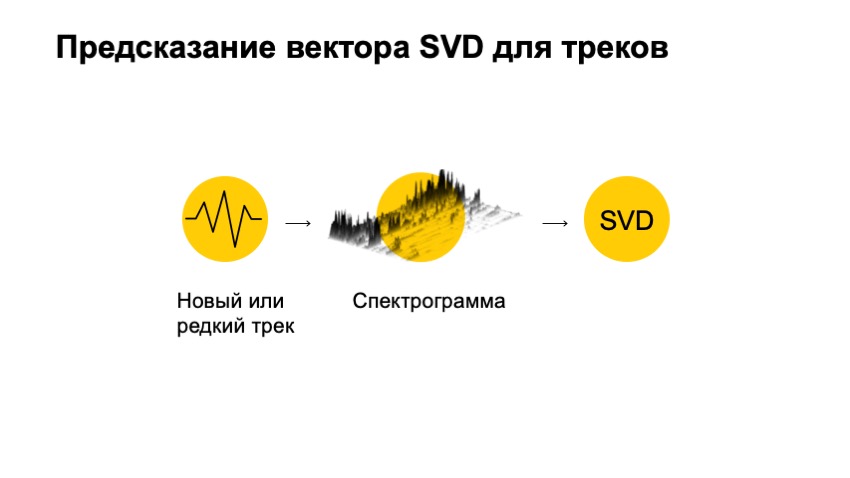
O que é essencialmente áudio? Você pode imaginar um gráfico de tensão. De qualquer forma, esse é um conjunto unidimensional de números, que é bastante inconveniente para se trabalhar, é muito grande e longo, faz pouco sentido por si só. Mas podemos verificar seu espectro, fazer Fourier se transformar nele, muito brevemente, para ver o quanto ele se parece com um tipo específico de sinusóide. O quanto ele se parece com algum tipo de sinusóide. E veja quantos sinusóides existem neste gráfico e faça o mesmo para cada uma das frequências.
Se fizermos isso para toda a faixa como um todo, é claro, obteremos algumas informações, mas muito pouco, dirá muito pouco, porque, por exemplo, as transições entre partes da faixa são muito importantes para a música, enquanto no espectro obteremos ter na forma indireta uma mudança nas frequências muito grandes, que devem estar relacionadas a segundos, a minutos, e isso é bastante inconveniente e mal apresentado na forma de espectro.
Portanto, vamos mais longe e cortamos a pista em pedaços pequenos. Em cada peça, fazemos essa transformação. Como resultado, obtemos uma imagem dessas, desenhei-a na forma tridimensional, para que fique mais visível que desenvolvemos frequências em um plano no tempo e na altura - a energia que estava naquele momento no tempo. E eles receberam o chamado espectrograma.
Como, usando esse espectrograma, obteríamos o vetor SVD? A resposta em nosso tempo é bastante banal: vamos pegar uma rede neural e treiná-la para prever o vetor SVD.
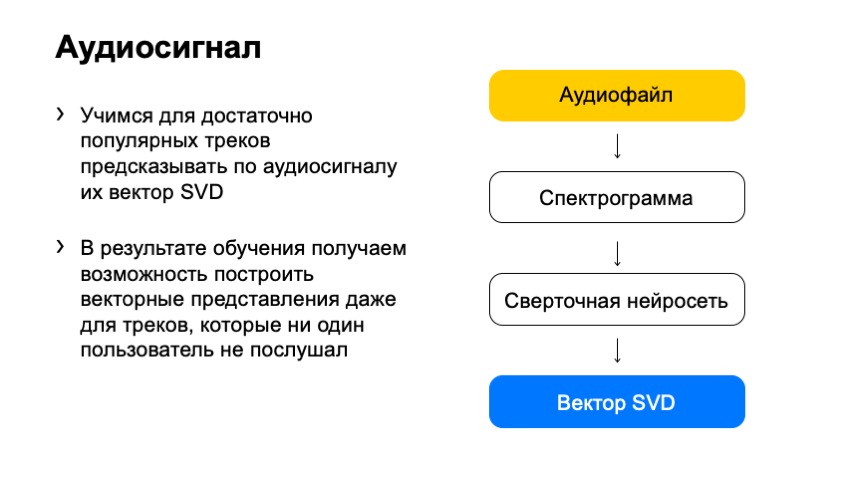
Então nós fizemos. O que escolhemos como treinamento? Aquelas trilhas SVD cujo vetor sabemos com certeza. Selecionamos especialmente faixas populares cujo feedback era grande o suficiente para que o vetor SVD já estivesse completamente silencioso e pudéssemos calculá-lo claramente. E - eles treinaram a rede neural para prever esses vetores.
O que conseguimos no final? Uma rede que pode acompanhar qualquer pista e prever seu vetor SVD. Temos uma solução muito simples que funciona muito bem.
Quero mostrar um exemplo de um par de faixas que escolhemos. Uma dessas faixas é bastante popular, e seu vetor SVD pode ser reconhecido com bastante precisão, e a segunda é muito impopular. Quero sugerir que adivinhe qual dessas faixas é menos popular e qual é mais popular.
Primeira faixa:
Segunda faixa:
A resposta
A primeira faixa é mais popular. Se você observar o número de ouvintes que conheciam essa faixa e pudessem encontrá-la, sem a ajuda de recomendações, a primeira faixa poderia ser encontrada por mais de 1000 usuários e a segunda - apenas 10. E como aplicamos nossa tecnologia, não conseguimos tente até recomendar essa faixa, porque não havia nada a que se apegar para obter recomendações. Só poderíamos oferecer a esses 10 usuários.
Quando aplicamos isso na produção, recebemos muitos ótimos comentários. Uma das listas de reprodução, "Deja Vu", na qual temos que incorporar faixas que o usuário não escutou, organizar a descoberta para o usuário, melhorou significativamente depois que conseguimos aplicar essa tecnologia.
Obviamente, aplicamos isso ao entrar em novos países e também recebemos muitas críticas positivas. Eles observaram que as listas de reprodução sabem como personalizar bem. Além disso, os editores em Israel ficaram bastante surpresos que o serviço russo em Israel não recomenda artistas russos em grandes quantidades, mas música local e internacional.

Sobre os números que conseguimos alcançar. Mais importante, queríamos alcançar o número de novos produtos para os usuários no fluxo de áudio, para que ele se tornasse mais diversificado. , . , : . . . 1,5% . , . , - , , . , , .
: . , , , . . Obrigado pela atenção.