Nos últimos 7 anos, juntamente com a equipe, tenho apoiado e desenvolvido o núcleo do produto Miro (ex-RealtimeBoard): interação cliente-servidor e cluster, trabalhando com o banco de dados.
Temos Java com diferentes bibliotecas a bordo. Tudo é lançado fora do contêiner, através do plugin Maven. Baseia-se na plataforma de nossos parceiros, que nos permite trabalhar com o banco de dados e fluxos, gerenciar a interação cliente-servidor, etc. DB - Redis e PostgreSQL (meu colega
escreveu sobre como passamos de um banco de dados para outro ).
Em termos de lógica de negócios, o aplicativo contém:
- trabalhar com quadros personalizados e seu conteúdo;
- funcionalidade para registro de usuários, criação e gerenciamento de placas;
- gerador de recursos personalizados. Por exemplo, ele otimiza imagens grandes carregadas no aplicativo para que elas não diminuam a velocidade em nossos clientes;
- muitas integrações com serviços de terceiros.
Em 2011, quando estávamos começando, todo o Miro estava no mesmo servidor. Tudo estava nele: Nginx, no qual o php de um site estava ativado, um aplicativo Java e bancos de dados.
O produto desenvolvido, o número de usuários e o conteúdo que eles adicionaram às placas aumentaram; portanto, a carga no servidor também aumentou. Devido ao grande número de aplicativos em nosso servidor, naquele momento não conseguimos entender o que exatamente carrega a carga e, portanto, não conseguimos otimizá-la.Para corrigir isso, dividimos tudo em diferentes servidores e obtivemos um servidor web, um servidor com nosso aplicativo e servidor de banco de dados.
Infelizmente, após algum tempo, os problemas voltaram a surgir, à medida que a carga no aplicativo continuava aumentando. Depois, pensamos em como dimensionar a infraestrutura.

A seguir, falarei sobre as dificuldades que encontramos no desenvolvimento de clusters e no dimensionamento de aplicativos e infraestrutura Java.
Dimensionar a infraestrutura horizontalmente
Começamos coletando métricas: o uso de memória e CPU, o tempo necessário para executar consultas do usuário, o uso de recursos do sistema e o trabalho com o banco de dados. A partir das métricas, ficou claro que a geração de recursos do usuário era um processo imprevisível. Podemos carregar o processador 100% e esperar dezenas de segundos até que tudo esteja pronto. Às vezes, solicitações de usuários por placas também forneciam uma carga inesperada. Por exemplo, quando um usuário seleciona mil widgets e começa a movê-los espontaneamente.
Começamos a pensar em como dimensionar essas partes do sistema e chegamos a soluções óbvias.
Dimensione o trabalho com quadros e conteúdo . O usuário abre o quadro da seguinte maneira: o usuário abre o cliente → indica qual painel ele deseja abrir → se conecta ao servidor → um fluxo é criado no servidor → todos os usuários deste quadro se conectam a um fluxo → qualquer alteração ou criação do widget ocorre nesse fluxo. Acontece que todo o trabalho com a placa é estritamente limitado pelo fluxo, o que significa que podemos distribuir esses fluxos entre os servidores.
Escale a geração de recursos do usuário . Podemos retirar o servidor para gerar recursos separadamente, e ele receberá mensagens para geração e, em seguida, responde que tudo é gerado.
Tudo parece ser simples. Mas assim que começamos a estudar esse tópico mais profundamente, descobrimos que precisávamos resolver adicionalmente alguns problemas indiretos. Por exemplo, se os usuários expirarem uma assinatura paga, devemos notificá-los sobre isso, independentemente do quadro em que estejam. Ou, se o usuário atualizou a versão do recurso, é necessário garantir que o cache esteja corretamente liberado em todos os servidores e que forneçamos a versão correta.
Identificamos os requisitos do sistema. O próximo passo é entender como colocar isso em prática. De fato, precisávamos de um sistema que permitisse que os servidores do cluster se comuniquem entre si e com base no qual realizaremos todas as nossas idéias.
O primeiro cluster pronto para uso
Não selecionamos a primeira versão do sistema, porque ela já estava parcialmente implementada na plataforma de parceiros que usamos. Nele, todos os servidores estavam conectados um ao outro via TCP e, usando essa conexão, poderíamos enviar mensagens RPC para um ou todos os servidores ao mesmo tempo.
Por exemplo, temos três servidores, eles estão conectados um ao outro via TCP, e no Redis temos uma lista desses servidores. Iniciamos um novo servidor no cluster → ele se adiciona à lista em Redis → lê a lista para descobrir todos os servidores no cluster → se conecta a todos.
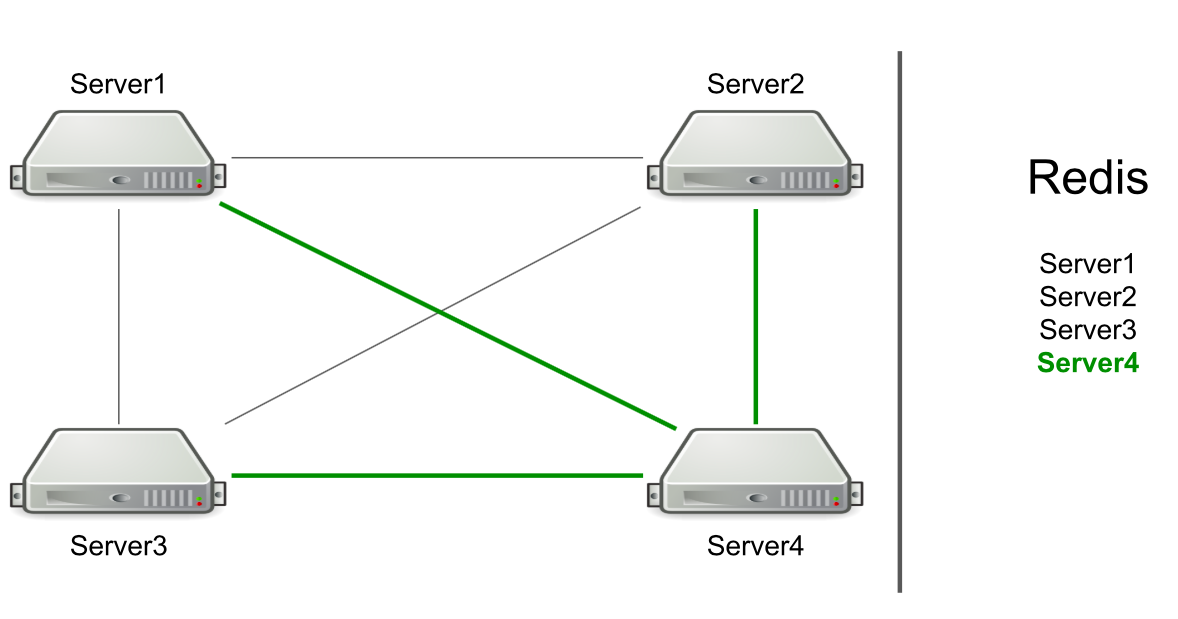
Com base no RPC, o suporte para liberar o cache e redirecionar os usuários para o servidor desejado já foi implementado. Tivemos que gerar uma geração de recursos do usuário e notificar os usuários de que algo havia acontecido (por exemplo, uma conta expirou). Para gerar recursos, escolhemos um servidor arbitrário e enviamos a ele um pedido de geração e, para notificações sobre a expiração de uma assinatura, enviamos um comando a todos os servidores na esperança de que a mensagem atinja a meta.
O próprio servidor determina para quem enviar a mensagem.
Parece um recurso, não um problema. Mas o servidor se concentra apenas na conexão com outro servidor. Se houver conexões, haverá um candidato para enviar uma mensagem.
O problema é que o servidor número 1 não sabe que o servidor número 4 está sob carga alta no momento e não pode respondê-lo com rapidez suficiente. Como resultado, as solicitações do servidor nº 1 são processadas mais lentamente do que podiam.
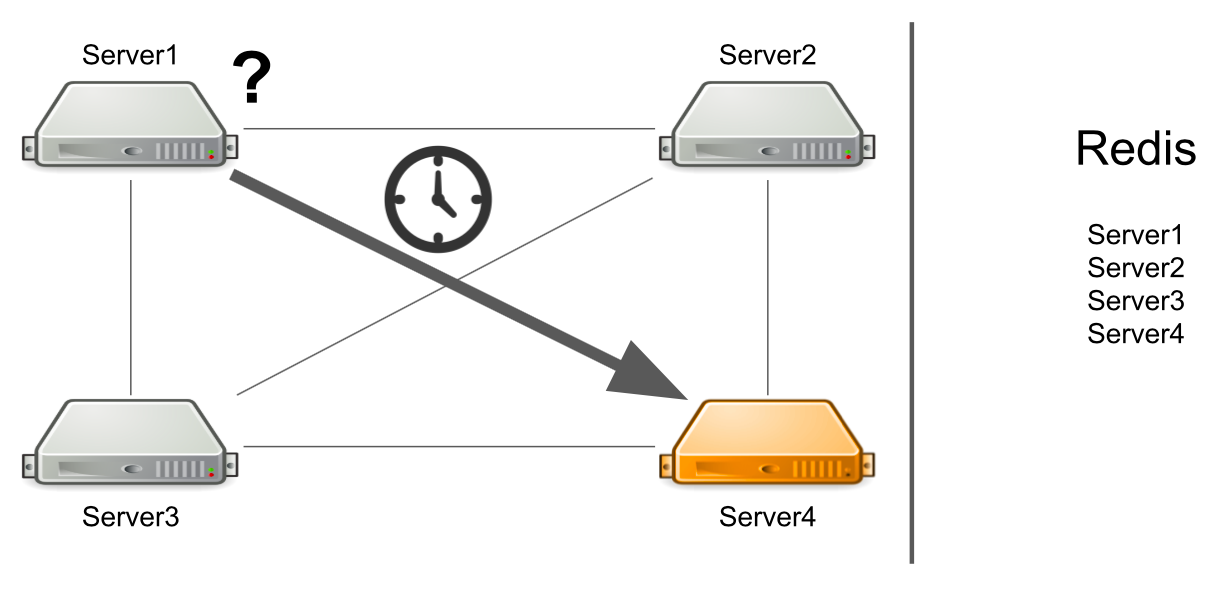
O servidor não sabe que o segundo servidor está congelado
Mas e se o servidor não estiver apenas muito carregado, mas geralmente congela? Além disso, ele trava para que não volte mais à vida. Por exemplo, eu acabei com toda a memória disponível.
Nesse caso, o servidor nº 1 não sabe qual é o problema e continua aguardando uma resposta. Os servidores restantes no cluster também não sabem sobre a situação com o servidor número 4, portanto, eles enviarão muitas mensagens para o servidor número 4 e aguardarão uma resposta. Portanto, será até que o servidor número 4 morra.
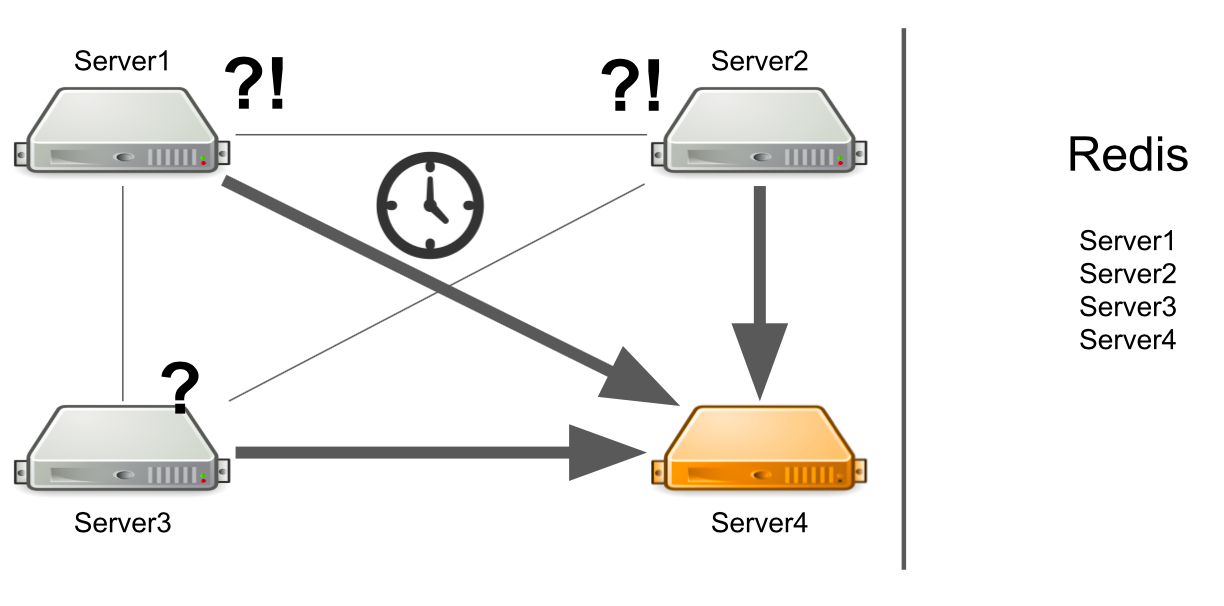
O que fazer Podemos adicionar independentemente uma verificação de status do servidor ao sistema. Ou podemos redirecionar mensagens de servidores "doentes" para servidores "saudáveis". Tudo isso levará muito tempo para os desenvolvedores. Em 2012, como tínhamos pouca experiência nessa área, começamos a procurar soluções prontas para todos os nossos problemas de uma só vez.
Agente de mensagens. Activemq
Decidimos ir na direção do Message broker para configurar corretamente a comunicação entre os servidores. Eles escolheram o ActiveMQ devido à capacidade de configurar o recebimento de mensagens no consumidor em um determinado momento. É verdade que nunca aproveitamos essa oportunidade para poder escolher o RabbitMQ, por exemplo.
Como resultado, transferimos todo o sistema de cluster para o ActiveMQ. O que deu:
- O servidor não determina mais para quem a mensagem é enviada, porque todas as mensagens passam pela fila.
- Tolerância de falha configurada. Para ler a fila, você pode executar não um, mas vários servidores. Mesmo se um deles cair, o sistema continuará funcionando.
- Os servidores apareceram funções, o que permitiu dividir o servidor por tipo de carga. Por exemplo, um gerador de recursos pode se conectar apenas a uma fila para ler mensagens para gerar recursos, e um servidor com placas pode se conectar a uma fila para abrir placas.
- A comunicação RPC, ou seja, cada servidor tem sua própria fila privada, onde outros servidores enviam eventos para ele.
- Você pode enviar mensagens para todos os servidores através do Tópico, que usamos para redefinir as assinaturas.
O esquema parece simples: todos os servidores estão conectados ao broker e gerencia a comunicação entre eles. Tudo funciona, as mensagens são enviadas e recebidas, os recursos são criados. Mas há novos problemas.
O que fazer quando todos os servidores necessários estiverem mentindo?
Digamos que o servidor nº 3 queira enviar uma mensagem para gerar recursos em uma fila. Ele espera que sua mensagem seja processada. Mas ele não sabe que, por algum motivo, não há um único destinatário da mensagem. Por exemplo, os destinatários falharam devido a um erro.
Durante todo o tempo de espera, o servidor envia muitas mensagens com uma solicitação, e é por isso que uma fila de mensagens aparece. Portanto, quando os servidores em funcionamento aparecem, eles são forçados a processar primeiro a fila acumulada, o que leva tempo. No lado do usuário, isso leva ao fato de que a imagem carregada por ele não aparece imediatamente. Ele não está pronto para esperar, então deixa o conselho.
Como resultado, gastamos a capacidade do servidor na geração de recursos e ninguém precisa do resultado.
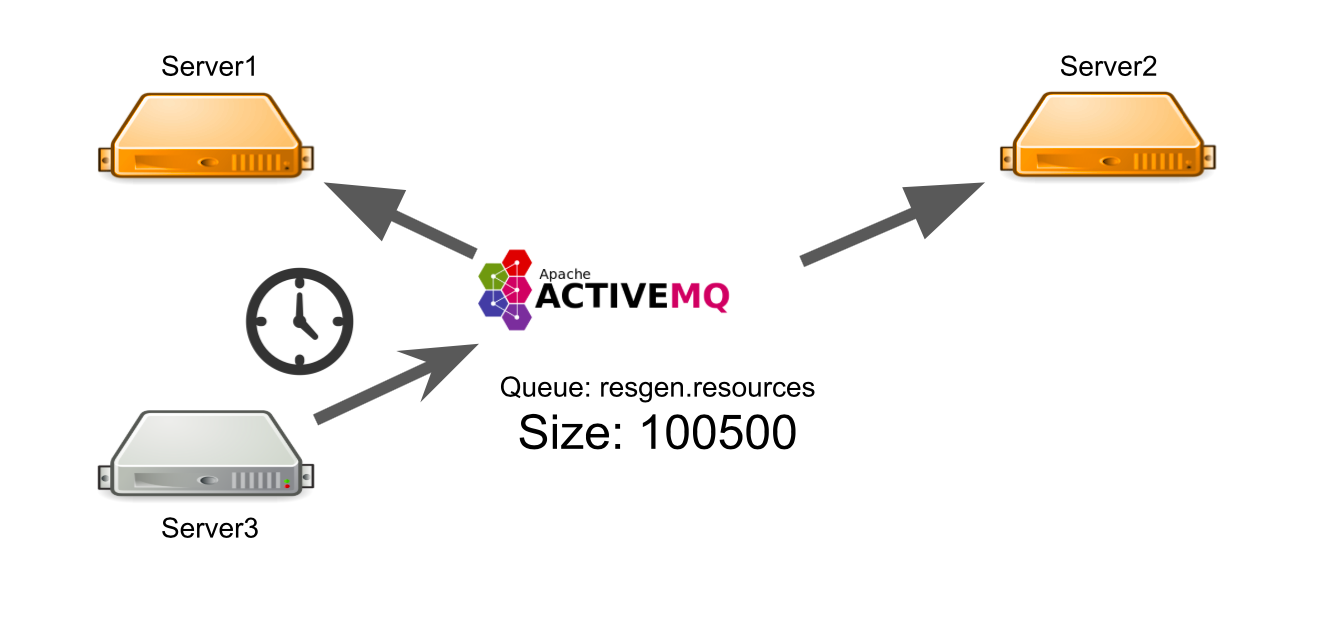
Como posso resolver o problema? Podemos configurar o monitoramento, que notificará você sobre o que está acontecendo. Mas a partir do momento em que o monitoramento relata algo, até o momento em que entendemos que nossos servidores estão ruins, o tempo passa. Isso não nos convém.
Outra opção é executar o Service Discovery, ou um registro de serviços que saberá quais servidores com quais funções estão em execução. Nesse caso, receberemos imediatamente uma mensagem de erro se não houver servidores livres.
Alguns serviços não podem ser dimensionados horizontalmente
Este é um problema do nosso código inicial, não do ActiveMQ. Deixe-me mostrar um exemplo:
Permission ownerPermission = service.getOwnerPermission(board); Permission permission = service.getPermission(board,user); ownerPermission.setRole(EDITOR); permission.setRole(OWNER);
Temos um serviço para trabalhar com direitos de usuário no quadro: o usuário pode ser o proprietário do quadro ou seu editor. Só pode haver um proprietário no quadro. Suponha que tenhamos um cenário em que queremos transferir a propriedade de uma placa de um usuário para outro. Na primeira linha, obtemos o atual proprietário do quadro, na segunda - pegamos o usuário que era o editor e agora se torna o proprietário. Além disso, o proprietário atual colocamos o papel de EDITOR e o ex-editor - o papel de OWNER.
Vamos ver como isso funcionará em um ambiente multithread. Quando o primeiro thread estabelece a função EDITOR e o segundo thread tenta assumir o PROPRIETÁRIO atual, pode acontecer que OWNER não exista, mas existem dois EDITORES.
O motivo é a falta de sincronização. Podemos resolver o problema adicionando um bloco de sincronização no quadro.
synchronized (board) { Permission ownerPermission = service.getOwnerPermission(board); Permission permission = service.getPermission(board,user); ownerPermission.setRole(EDITOR); permission.setRole(OWNER); }
Esta solução não funcionará no cluster. O banco de dados SQL pode nos ajudar com isso, com a ajuda de transações. Mas nós temos Redis.
Outra solução é adicionar bloqueios distribuídos ao cluster para que a sincronização fique dentro de todo o cluster, e não apenas em um servidor.
Um único ponto de falha ao entrar no quadro
O modelo de interação entre o cliente e o servidor é estável. Portanto, devemos armazenar o estado do quadro no servidor. Portanto, criamos uma função separada para servidores - BoardServer, que lida com solicitações de usuários relacionadas a placas.
Imagine que temos três BoardServer, um dos quais é o principal. O usuário envia a ele uma solicitação "Abra-me o quadro com id = 123" → o servidor verifica em seu banco de dados se o quadro está aberto e em qual servidor está. Neste exemplo, o quadro está aberto.
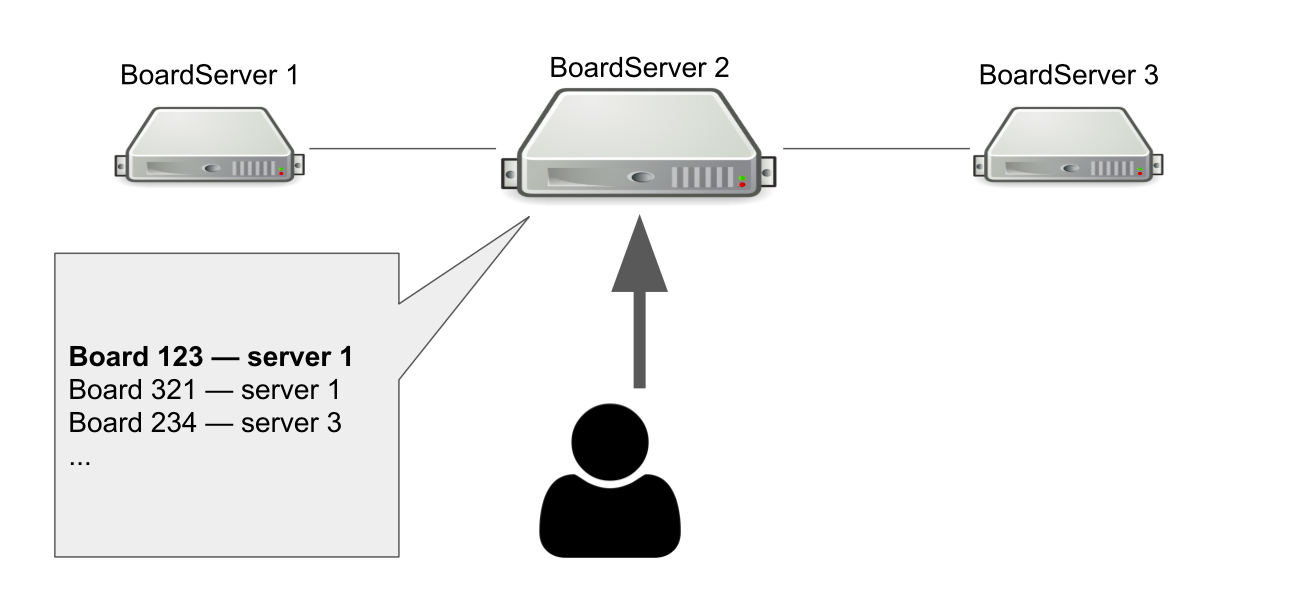
O servidor principal responde que você precisa se conectar ao servidor nº 1 → o usuário está se conectando. Obviamente, se o servidor principal morrer, o usuário não poderá mais acessar novas placas.
Então, por que precisamos de um servidor que saiba onde as placas estão abertas? Para que tenhamos um único ponto de decisão. Se algo acontecer com os servidores, precisamos entender se a placa está realmente disponível para remover a placa do registro ou reabrir em outro lugar. Seria possível organizar isso com a ajuda de um quorum, quando vários servidores resolverem um problema semelhante, mas naquela época não tínhamos o conhecimento necessário para implementar o quorum independentemente.
Mudar para Hazelcast
De um jeito ou de outro, lidamos com os problemas que surgiram, mas pode não ser o caminho mais bonito. Agora, precisávamos entender como resolvê-los corretamente, e formulamos uma lista de requisitos para uma nova solução de cluster:
- Precisamos de algo que monitore o status de todos os servidores e suas funções. Chame isso de descoberta de serviço.
- Precisamos de bloqueios de cluster que ajudem a garantir consistência ao executar consultas perigosas.
- Precisamos de uma estrutura de dados distribuídos que garanta que as placas estejam em determinados servidores e informe se algo deu errado.
Foi o ano de 2015. Optamos pelo Hazelcast - In-Memory Data Grid, um sistema de cluster para armazenar informações na RAM. Então pensamos que tínhamos encontrado uma solução milagrosa, o santo graal do mundo da interação de cluster, uma estrutura milagrosa que pode fazer tudo e combina estruturas de dados distribuídos, bloqueios, mensagens e filas RPC.
Como no ActiveMQ, transferimos quase tudo para o Hazelcast:
- geração de recursos do usuário através do ExecutorService;
- bloqueio distribuído quando os direitos são alterados;
- funções e atributos de servidores (Service Discovery);
- um único registro de placas abertas, etc.
Topologias Hazelcast
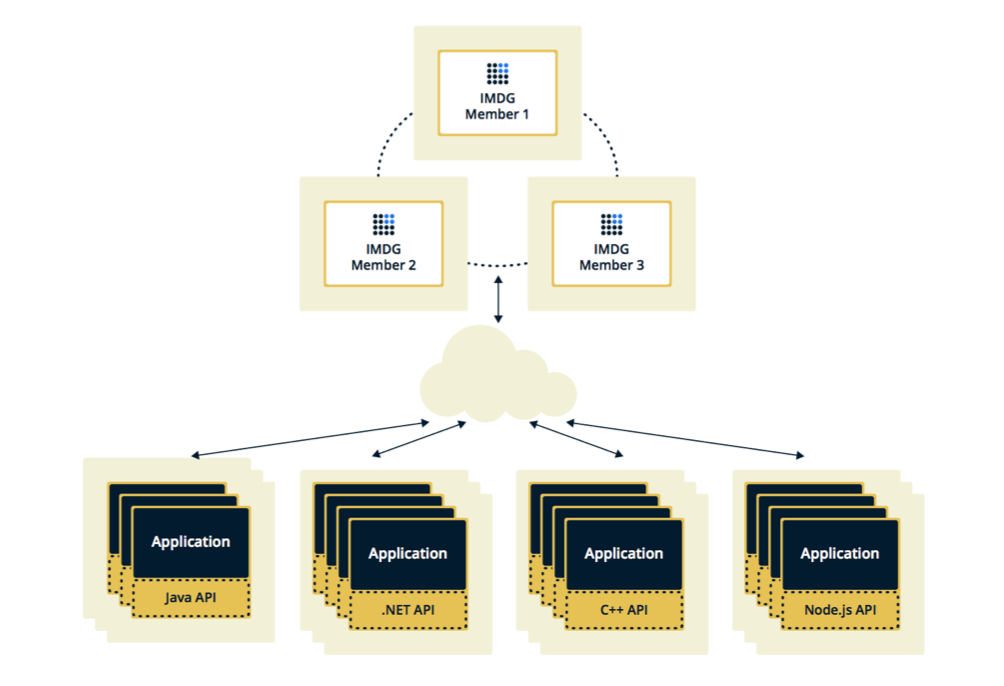
Hazelcast pode ser configurado em duas topologias. A primeira opção é Cliente-Servidor, quando os membros estão localizados separadamente do aplicativo principal, eles próprios formam um cluster e todos os aplicativos se conectam a eles como um banco de dados.
A segunda topologia é Incorporada, quando os membros Hazelcast são incorporados no próprio aplicativo. Nesse caso, podemos usar menos instâncias, o acesso aos dados é mais rápido, porque os dados e a própria lógica de negócios estão no mesmo local.
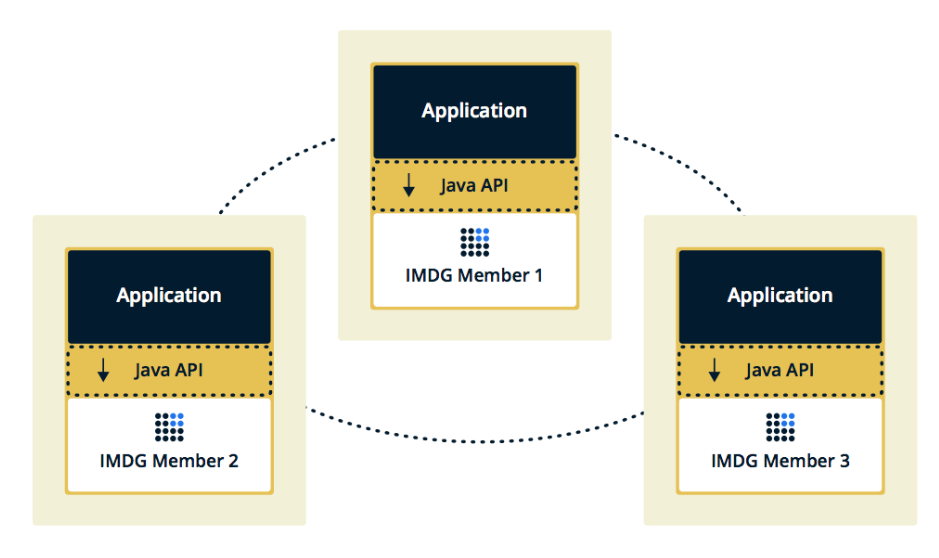
Escolhemos a segunda solução porque consideramos mais eficaz e econômica de implementar. Eficaz, porque a velocidade de acesso aos dados Hazelcast será menor, porque talvez esses dados estejam no servidor atual. Econômico, porque não precisamos gastar dinheiro em instâncias adicionais.
O cluster trava quando o membro trava
Algumas semanas depois de ativar o Hazelcast, surgiram problemas no produto.
Inicialmente, nosso monitoramento mostrou que um dos servidores começou a sobrecarregar gradualmente a memória. Enquanto assistia esse servidor, o restante dos servidores também começou a carregar: a CPU cresceu, depois a RAM e, após cinco minutos, todos os servidores usaram toda a memória disponível.
Neste ponto nos consoles, vimos estas mensagens:
2015-07-15 15:35:51,466 [WARN] (cached18) com.hazelcast.spi.impl.operationservice.impl.Invocation: [my.host.address.com]:5701 [dev] [3.5] Asking ifoperation execution has been started: com.hazelcast.spi.impl.operationservice.impl.IsStillRunningService$InvokeIsStillRunningOperationRunnable@6d4274d7 2015-07-15 15:35:51,467 [WARN] (hz._hzInstance_1_dev.async.thread-3) com.hazelcast.spi.impl.operationservice.impl.Invocation:[my.host.address.com]:5701 [dev] [3.5] 'is-executing': true -> Invocation{ serviceName='hz:impl:executorService', op=com.hazelcast.executor.impl.operations.MemberCallableTaskOperation{serviceName='null', partitionId=-1, callId=18062, invocationTime=1436974430783, waitTimeout=-1,callTimeout=60000}, partitionId=-1, replicaIndex=0, tryCount=250, tryPauseMillis=500, invokeCount=1, callTimeout=60000,target=Address[my.host2.address.com]:5701, backupsExpected=0, backupsCompleted=0}
Aqui, o Hazelcast verifica se a operação que foi enviada para o primeiro servidor "moribundo" está em andamento. O Hazelcast tentou se manter a par e verificou o status da operação várias vezes por segundo. Como resultado, ele enviou spam a todos os outros servidores com esta operação e, após alguns minutos, eles ficaram sem memória e coletamos vários GB de logs de cada um deles.
A situação foi repetida várias vezes. Aconteceu que este é um erro na versão 3.5 do Hazelcast, na qual o mecanismo de pulsação foi implementado, que verifica o status das solicitações. Não verificou alguns dos casos de fronteira que encontramos. Eu tive que otimizar o aplicativo para não cair nesses casos e, depois de algumas semanas, o Hazelcast corrigiu o erro em casa.
Adicionando e removendo membros frequentemente do Hazelcast
A próxima edição que descobrimos é adicionar e remover membros do Hazelcast.
Primeiro, descreverei brevemente como o Hazelcast funciona com partições. Por exemplo, existem quatro servidores, e cada um armazena parte dos dados (na figura, eles são de cores diferentes). A unidade é a partição primária, o empate é a partição secundária, ou seja, backup da partição principal.

Quando um servidor está desligado, as partições são enviadas para outros servidores. Caso o servidor morra, as partições são transferidas não dele, mas daqueles servidores que ainda estão ativos e mantendo um backup dessas partições.
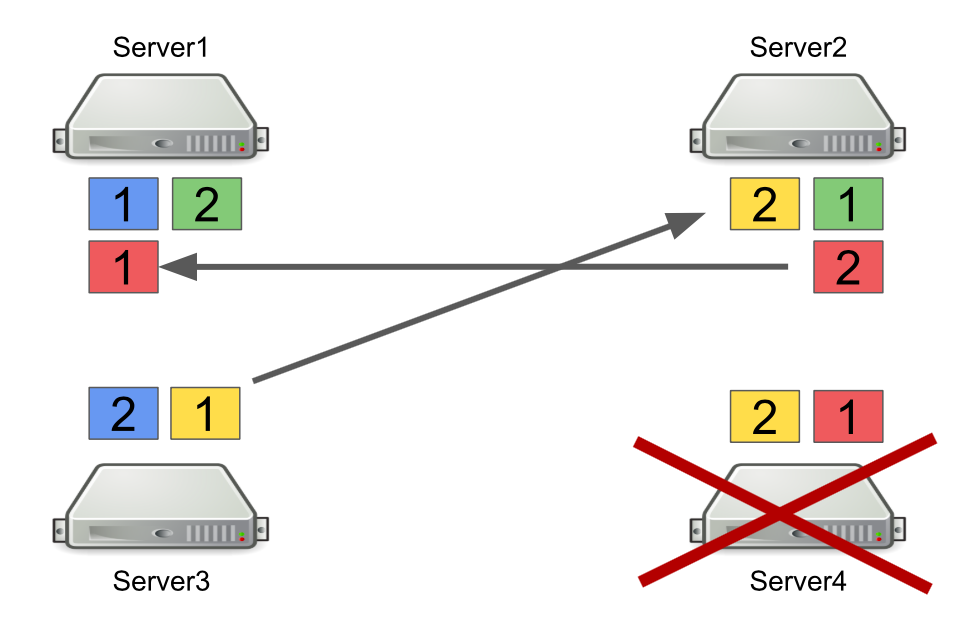
Este é um mecanismo confiável. O problema é que geralmente ligamos e desligamos os servidores para equilibrar a carga, e o reequilíbrio das partições também leva tempo. E quanto mais servidores estiverem em execução e mais dados armazenarmos no Hazelcast, mais tempo será necessário para reequilibrar as partições.
Obviamente, podemos reduzir o número de backups, ou seja, partições secundárias. Mas isso não é seguro, pois algo definitivamente vai dar errado.
Outra solução é alternar para a topologia Cliente-Servidor para que ligar e desligar os servidores não afete o cluster principal do Hazelcast. Tentamos fazer isso, e as solicitações de RPC não podem ser executadas nos clientes. Vamos ver o porquê.
Para fazer isso, considere o exemplo do envio de uma solicitação RPC para outro servidor. Tomamos o ExecutorService, que permite enviar mensagens RPC, e enviamos com uma nova tarefa.
hazelcastInstance .getExecutorService(...) .submit(new Task(), ...);
A tarefa em si parece uma classe Java regular que implementa o Callable.
public class Task implements Callable<Long> { @Override public Long call() { return 42; } }
O problema é que os clientes Hazelcast podem ser não apenas aplicativos Java, mas também aplicativos C ++, .NET e outros. Naturalmente, não podemos gerar e converter nossa classe Java para outra plataforma.
Uma opção é mudar para o uso de solicitações http, caso desejemos enviar algo de um servidor para outro e obter uma resposta. Mas então teremos que abandonar parcialmente o Hazelcast.
Portanto, como solução, optamos por usar filas em vez de ExecutorService. Para fazer isso, implementamos independentemente um mecanismo para aguardar a execução de um elemento na fila, que processa casos de limite e retorna o resultado ao servidor solicitante.
O que aprendemos
Coloque flexibilidade no sistema. O futuro está mudando constantemente, então não há soluções perfeitas. Fazer o certo "certo" não funciona, mas você pode tentar ser flexível e colocá-lo no sistema. Isso nos permitiu adiar decisões arquiteturais importantes até o momento em que não é mais impossível aceitá-las.
Robert Martin, em Arquitetura Limpa, escreve sobre esse princípio:
“O objetivo do arquiteto é criar um formulário para o sistema que tornará a política o elemento mais importante e os detalhes não relacionados à política. Isso atrasará e atrasará as decisões sobre detalhes. ”
Ferramentas e soluções universais não existem. Se lhe parece que alguma estrutura resolve todos os seus problemas, provavelmente isso não é verdade. Portanto, ao implementar qualquer estrutura, é importante entender não apenas quais problemas ela resolverá, mas quais ela trará.
Não reescreva tudo imediatamente. Se você se deparar com um problema na arquitetura e parece que a única solução certa é escrever tudo do zero, aguarde. Se o problema for realmente sério, encontre uma solução rápida e observe como o sistema funcionará no futuro. Provavelmente, esse não será o único problema na arquitetura, com o tempo você encontrará mais. E somente quando você seleciona um número suficiente de áreas problemáticas você pode começar a refatorar. Somente neste caso, haverá mais vantagens do que seu valor.