Oi Habr.
Após a publicação do ranking de artigos para
2017 e
2018 , a idéia seguinte foi óbvia - coletar uma classificação generalizada para todos os anos. Mas apenas coletar links seria banal (embora também útil), por isso foi decidido expandir o processamento de dados e coletar algumas informações mais úteis.

Classificações, estatísticas e um pouco de código-fonte em Python sob o gato.
Processamento de dados
Aqueles que estão imediatamente interessados nos resultados podem pular este capítulo. Enquanto isso, descobriremos como isso funciona.
Como dados de origem, há um arquivo csv aproximadamente do seguinte tipo:
datetime,link,title,votes,up,down,bookmarks,views,comments 2006-07-13T14:23Z,https://habr.com/ru/post/1/,"Wiki-FAQ ",votes:1,votesplus:1,votesmin:0,bookmarks:8,views:28300,comments:56 2006-07-13T20:45Z,https://habr.com/ru/post/2/," … !",votes:1,votesplus:1,votesmin:0,bookmarks:1,views:14600,comments:37 ... 2019-01-25T03:47Z,https://habr.com/ru/post/435118/,"Save File Me — ",votes:5,votesplus:5,votesmin:0,bookmarks:26,views:1800,comments:6 2019-01-08T03:09Z,https://habr.com/ru/post/435120/,"Lambda- SQL… ",votes:9,votesplus:13,votesmin:4,bookmarks:63,views:5700,comments:30
O índice de todos os artigos neste formulário ocupa 42 MB e, para coletar, demorou cerca de 10 dias para executar o script no Raspberry Pi (o download ocorreu em um fluxo com pausas para não sobrecarregar o servidor). Agora vamos ver quais dados podem ser extraídos de tudo isso.
Público do site
Vamos começar com um relativamente simples - avaliaremos o público do site durante todos os anos. Para uma estimativa aproximada, você pode usar o número de comentários em artigos. Faça o download dos dados e exiba um gráfico do número de comentários.
import pandas as pd import matplotlib.pyplot as plt df = pd.read_csv(log_path, sep=',', encoding='utf-8', error_bad_lines=True, quotechar='"', comment='#') def to_int(s):
Os dados são mais ou menos assim:

O resultado é interessante - acontece que desde 2009 o público ativo do site (aqueles que deixam comentários nos artigos) praticamente não cresce. Embora talvez todos os funcionários de TI estejam aqui?
Como estamos falando do público, é interessante relembrar a mais recente inovação da Habr - a adição de uma versão em inglês do site. Liste artigos com "/ en /" dentro do link.
df = df[df['link'].str.contains("/en/")]
O resultado também é interessante (a escala vertical fica especialmente igual):

O aumento no número de publicações começou em 15 de janeiro de 2019, quando o anúncio da
Hello world! Ou Habr em inglês , no entanto, vários meses antes da publicação desses 3 artigos:
1 ,
2 e
3 . Provavelmente foi um teste beta?
Identificadores
O próximo ponto interessante que não mencionamos nas partes anteriores é a comparação dos identificadores de artigo e datas de publicação. Cada artigo possui um link do tipo
habr.com/en/post/N , a numeração dos artigos é transversal, o primeiro artigo tem o identificador 1 e o que você está lendo é 441740. Parece que tudo é simples. Mas na verdade não. Verifique a correspondência de datas e identificadores.
Carregue o arquivo no DataFrame do Pandas, selecione as datas e o ID e plote-os:
df = pd.read_csv(log_path, header=None, names=['datetime', 'votes', 'bookmarks', 'views', 'comments']) dates = pd.to_datetime(df['datetime'], format='%Y-%m-%dT%H:%M:%S.%f') dates += datetime.timedelta(hours=3) df['datetime'] = dates def link2id(link):
O resultado é surpreendente - os identificadores nem sempre são capturados em sequência, como originalmente assumido, existem "discrepâncias" visíveis.
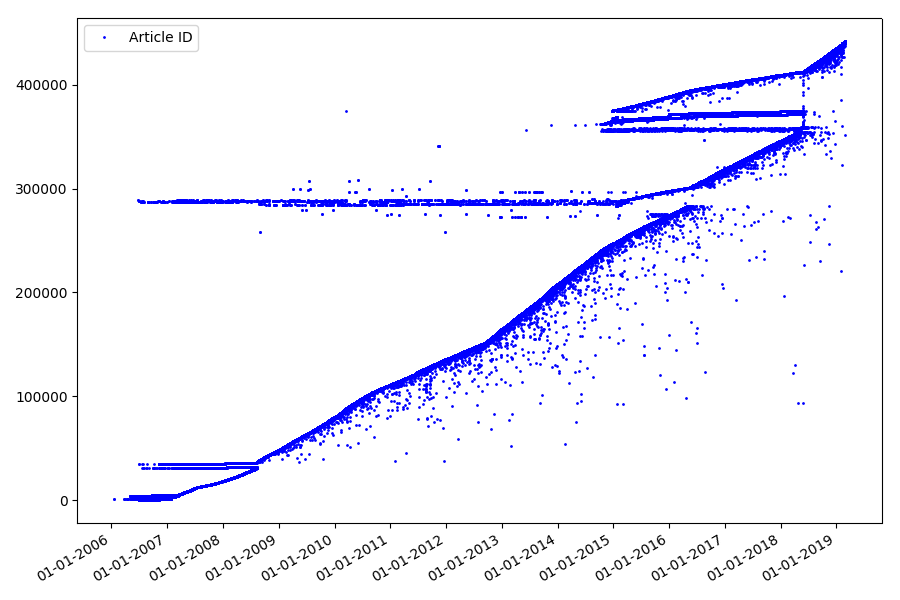
Em parte por causa deles, o público teve perguntas sobre as classificações para 2017 e 2018 - esses artigos com o ID “errado” não foram levados em consideração pelo analisador. Por que é tão difícil dizer, e não tão importante.
O que poderia ser interessante sobre identificadores? Há uma hipótese que não posso provar formalmente, mas que parece óbvia. Um identificador é designado no momento da redação do rascunho do artigo, e a data da publicação obviamente chega mais tarde. Alguém publica o artigo no mesmo dia, alguém publica o material mais tarde. Por que tudo isso? Vamos colocar os identificadores no eixo X e as datas verticalmente e ver um fragmento do gráfico em mais detalhes:
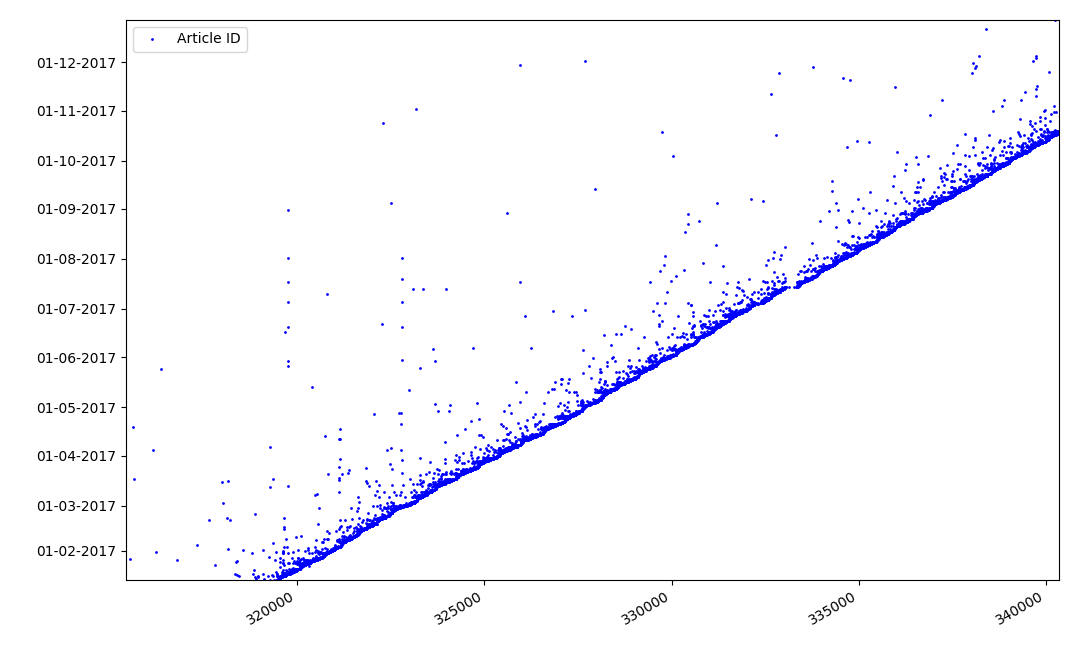
Resultado - vemos uma nuvem de pontos acima da linha sólida, que nos mostra a distribuição do tempo durante
a criação dos artigos . Como você pode ver, o máximo cai no intervalo de até 1-2 semanas. Quase toda a massa de artigos é criada em não mais de um mês, embora alguns sejam publicados poucos meses após a criação do rascunho (é claro, isso não nos garante que o autor trabalhou no artigo por vários meses diariamente, mas o resultado ainda é bastante interessante).
Data e hora da publicação
Um ponto interessante, embora intuitivo, é o momento da publicação dos artigos.
Estatísticas de saída em dias úteis:
print("Group by hour (average, working days):") df_workdays = df[(df['day'] < 5)] g = df_workdays.groupby(['hour']) hour_count = g.size().reset_index(name='counts') grouped = g.median().reset_index() grouped['counts'] = hour_count['counts'] print(grouped[['hour', 'counts', 'views', 'comments', 'votes', 'votesperview']]) print() view_hours = grouped['hour'].values view_hours_avg = grouped['counts'].values fig, ax = plt.subplots() plt.bar(view_hours, view_hours_avg, align='edge', label='Publication Time (Mo-Fr)') ax.set_xticks(range(24)) ax.xaxis.set_major_formatter(FormatStrFormatter('%d:00')) plt.legend(loc='best') fig.autofmt_xdate() plt.tight_layout() plt.show()
A dependência do número de artigos no horário da publicação em dias da semana:
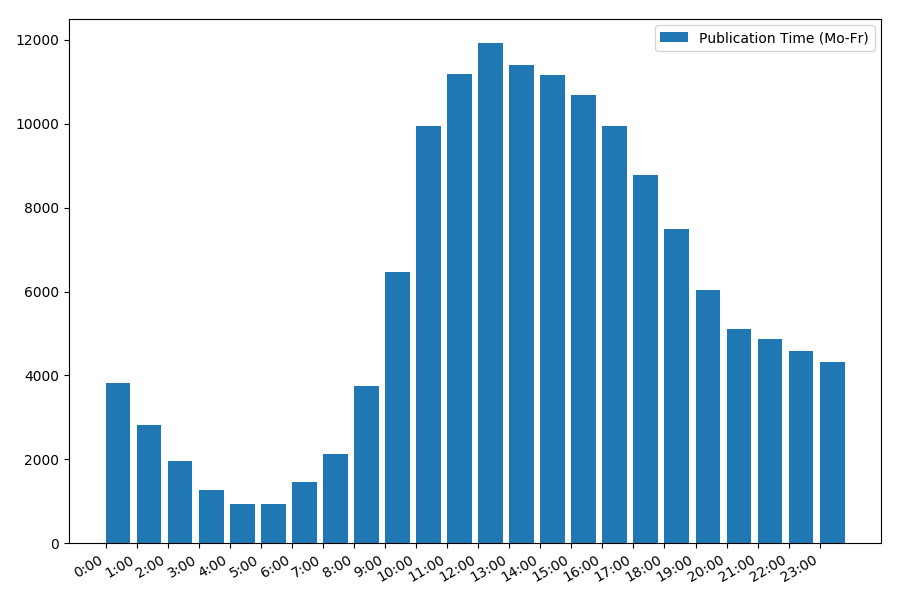
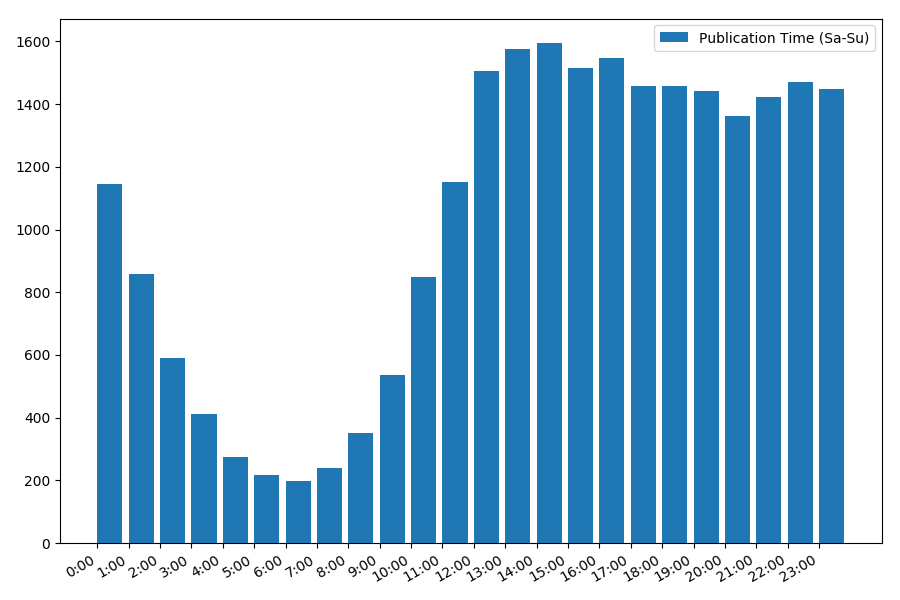
A imagem é interessante, a maioria das publicações recai sobre o horário de trabalho. Ainda interessante: para a maioria dos autores, escrever artigos é o trabalho principal, ou eles apenas o fazem durante o horário de trabalho? ;) Mas a programação de distribuição no fim de semana dá uma imagem diferente:
Como estamos falando de data e hora, vamos ver o valor médio das visualizações e o número de artigos por dia da semana.
g = df.groupby(['day', 'dayofweek']) dayofweek_count = g.size().reset_index(name='counts') grouped = g.median().reset_index() grouped['counts'] = dayofweek_count['counts'] grouped.sort_values('day', ascending=False) print(grouped[['day', 'dayofweek', 'counts', 'views', 'comments', 'votes', 'votesperview']]) print() view_days = grouped['day'].values view_per_day = grouped['views'].values counts_per_day = grouped['counts'].values days_of_week = grouped['dayofweek'].values plt.bar(view_days, view_per_day, align='edge', label='Avg.Views/day') plt.bar(view_days, counts_per_day, align='edge', label='Amount/day') plt.xticks(view_days, days_of_week) plt.ylim(bottom=0, top=10000) plt.show()
O resultado é interessante:
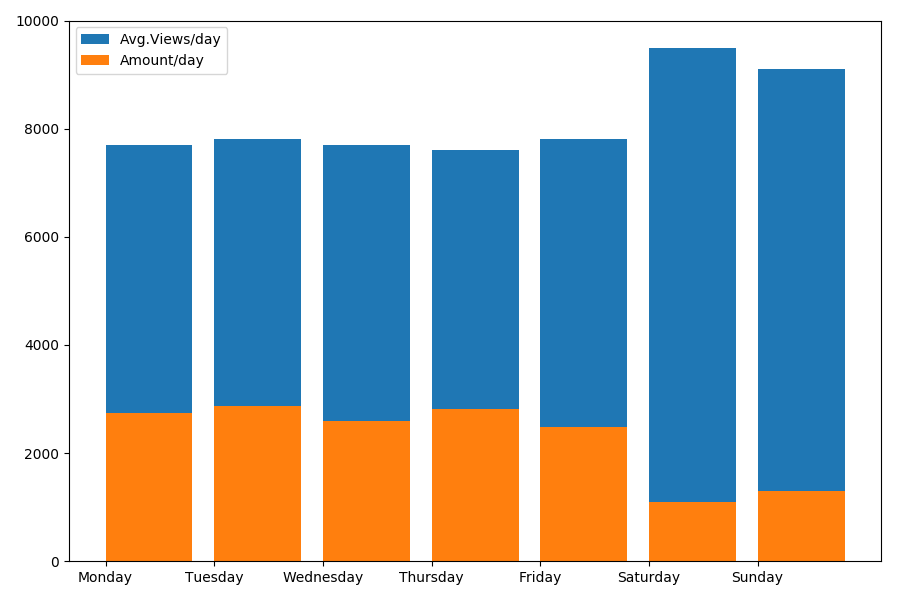
Como você pode ver, notavelmente menos artigos são publicados nos finais de semana. Porém, como cada artigo ganha mais visualizações, a publicação de artigos no fim de semana parece bastante recomendável (como foi encontrado na
primeira parte , a vida ativa do artigo não passa de 3-4 dias, portanto, os primeiros dois dias são bastante críticos).
O artigo talvez esteja ficando muito longo. O final na
segunda parte .