
Compartilharei uma história sobre um pequeno projeto: como encontrar as respostas do autor nos comentários sem saber quem é o autor da postagem.
Comecei meu projeto com um conhecimento mínimo em aprendizado de máquina e acho que não haverá novidades para especialistas aqui. Este material é, em certo sentido, uma compilação de artigos diferentes; nele, mostrarei como ela abordou a tarefa; no código, você pode encontrar pequenas coisas e truques úteis no processamento de linguagem natural.
Meus dados iniciais foram os seguintes: um banco de dados contendo 2,5 milhões de materiais de mídia e 39,5 milhões de comentários sobre eles. Para posts de 1 milhão, de uma forma ou de outra, o autor do material era conhecido (essa informação estava presente no banco de dados ou foi obtida através da análise de dados por motivos indiretos). Nesta base,
um conjunto de dados foi criado a partir de 215K registros marcados.
Inicialmente, usei uma abordagem baseada em heurística emitida pela inteligência natural e traduzida em consultas sql com pesquisa de texto completo ou expressões regulares. Os exemplos mais simples de texto para analisar: "obrigado pelo comentário" ou "obrigado pelas boas classificações", é o autor em 99,99% dos casos e "obrigado pelo trabalho" ou "obrigado!" Envie material por correio. Obrigado! " - revisão ordinária. Com essa abordagem, apenas coincidências óbvias poderiam ser filtradas, exceto em casos de erros banais ou quando o autor estava em diálogo com comentaristas. Por isso, decidiu-se usar redes neurais, essa ideia não veio sem a ajuda de um amigo.
Uma sequência típica de comentários, qual deles é o autor?
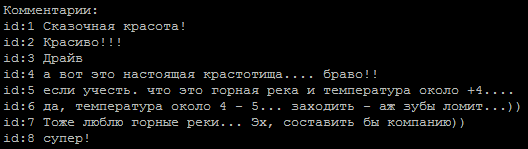
O método para determinar a tonalidade do texto foi tomado como base.A tarefa é simples para nós em duas classes: o autor e não o autor. Para treinar modelos, usei um
serviço do Google que fornece máquinas virtuais com uma interface de notebook GPU e Jupiter.
Exemplos de redes encontradas na Internet:
embed_dim = 128 model = Sequential() model.add(Embedding(max_fatures, embed_dim,input_length = X_train.shape[1])) model.add(SpatialDropout1D(0.2)) model.add(LSTM(196, dropout=0.5, recurrent_dropout=0.2)) model.add(Dense(1,activation='softmax')) model.compile(loss = 'binary_crossentropy', optimizer='adam',metrics = ['accuracy'])
nas linhas limpas de tags html e caracteres especiais, eles deram cerca de 65-74% por cento de precisão, o que não difere muito de jogar uma moeda.
Um ponto interessante é que o alinhamento das seqüências de entrada através das seqüências de
pad_sequences(x_train, maxlen=max_len, padding='pre') deu uma diferença significativa nos resultados. No meu caso, o melhor resultado foi com padding = 'post'.
O próximo passo foi o uso da lematização, que imediatamente deu um aumento na precisão de até 80% e isso poderia ser aprofundado. Agora, o principal problema é a limpeza correta do texto. Por exemplo, erros de digitação na palavra "obrigado" foram convertidos (erros de digitação foram selecionados pela frequência de uso) em uma expressão regular (essas expressões acumularam de meia a duas dúzias).
re16 = re.compile(ur"(?:\b:(?:1|c(?:|)|(?:|)|(?:(?:|(?:(?:(?:|(?:)?|))?|(?:)?))|)|(?:(?:(?:|)|)||||(?:(?:||(?:|)|(?:|(?:(?:(?:||(?:(?:||(?:[]|)|[]))?|[і]))?|||1)||)|)|||[]|(?:|)|(?:(?:(?:[]|)|?|(?:(?:(?:|(?:)?))?|)|(?:|)))?)||)|(?:|x))\b)", re.UNICODE)
Aqui, gostaria de expressar um agradecimento especial a pessoas excessivamente educadas que consideram necessário adicionar esta palavra a cada uma das frases.
Era necessário reduzir a proporção de erros de digitação, porque na saída do lematizador, eles emitem palavras estranhas e perdemos informações úteis.
Mas há um forro de prata, estamos cansados de lidar com erros de digitação, com a limpeza complexa de textos, usei a representação vetorial de palavras - word2vec. O método permitiu traduzir todos os erros de digitação, erros de digitação e sinônimos em vetores bem espaçados.

Palavras e seus relacionamentos no espaço vetorial.
As regras de limpeza foram significativamente simplificadas (aha, contador de histórias), todas as mensagens e nomes de usuários foram divididos em frases e enviados para um arquivo. Um ponto importante: devido à brevidade de nossos comentaristas, para criar vetores de alta qualidade, as palavras precisam de informações contextuais adicionais, por exemplo, do fórum e da Wikipedia. Três modelos foram treinados no arquivo resultante: classic word2vec, Glove e FastText. Depois de muitas experiências, ele finalmente decidiu usar o FastText, como o agrupamento de palavras com maior distinção qualitativa no meu caso.
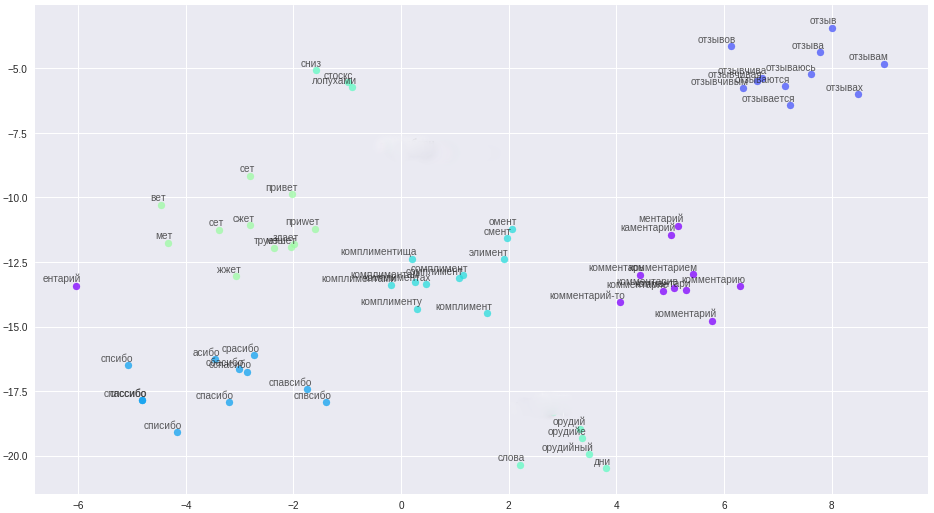
Todas essas mudanças trouxeram uma precisão estável de 84 a 85%.
Exemplos de modelo def model_conv_core(model_input, embd_size = 128): num_filters = 128 X = Embedding(total_unique_words, DIM, input_length=max_words, weights=[embedding_matrix], trainable=False, name='Word2Vec')(model_input) X = Conv1D(num_filters, 3, activation='relu', padding='same')(X) X = Dropout(0.3)(X) X = MaxPooling1D(2)(X) X = Conv1D(num_filters, 5, activation='relu', padding='same')(X) return X def model_conv1d(model_input, embd_size = 128, num_filters = 64, kernel_size=3): X = Embedding(total_unique_words, DIM, input_length=max_words, weights=[embedding_matrix], trainable=False, name='Word2Vec')(model_input) X = Conv1D(num_filters, kernel_size, padding='same', activation='relu', strides=1)(X)
e mais 6 modelos em
código . Alguns dos modelos são retirados da rede, outros são inventados de forma independente.
Percebeu-se que comentários diferentes se destacavam em diferentes modelos, o que levou à ideia de usar conjuntos de modelos. Primeiro, montei o conjunto manualmente, escolhendo os melhores pares de modelos, depois criei um gerador. Para otimizar a pesquisa exaustiva, tomei o código cinza como base.
def gray_code(n): def gray_code_recurse (g,n): k = len(g) if n <= 0: return else: for i in range (k-1, -1, -1): char='1' + g[i] g.append(char) for i in range (k-1, -1, -1): g[i]='0' + g[i] gray_code_recurse (g, n-1) g = ['0','1'] gray_code_recurse(g, n-1) return g def gen_list(m): out = [] g = gray_code(len(m)) for i in range (len(g)): mask_str = g[i] idx = 0 v = [] for c in list(mask_str): if c == '1': v.append(m[idx]) idx += 1 if len(v) > 1: out.append(v) return out
Com o conjunto, “a vida se tornou mais divertida” e a porcentagem atual de precisão do modelo está no nível de 86 a 87%, o que está associado principalmente à classificação de baixa qualidade de alguns autores no conjunto de dados.

Os problemas que encontrei:
- Conjunto de dados desequilibrado. O número de comentários dos autores foi significativamente menor do que outros comentadores.
- As classes da amostra seguem em ordem estrita. A linha inferior é que o começo, meio e fim diferem significativamente na qualidade da classificação. Isso é claramente visível no processo de aprendizado no cronograma da medida f1.
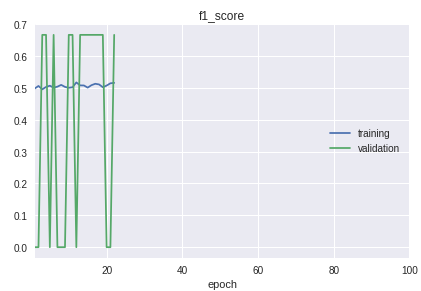
Para a solução, foi feita uma bicicleta para separação em amostras de treinamento e validação. Embora na prática, na maioria dos casos, o procedimento train_test_split da biblioteca sklearn seja suficiente.
Gráfico do modelo de trabalho atual:

Como resultado, consegui um modelo com uma definição confiável de autores a partir de breves comentários. Melhorias adicionais serão associadas à limpeza e transferência dos resultados da classificação de dados reais para o conjunto de dados de treinamento.
Todo o código com explicações adicionais está no
repositório .
Como um pós-escrito: se você precisar classificar grandes quantidades de texto, dê uma olhada no
modelo “Rede Neural Convolucional Muito Profunda” do
VDCNN (
implementação em keras), este é um análogo do ResNet para textos.
Materiais utilizados:
•
Visão geral dos cursos de aprendizado de máquina•
Análise de convolução usando convolução•
Redes convolucionais em PNL•
Métricas no aprendizado de máquinahttps://ld86.imtqy.com/ml-slides/unbalanced.html•
Um olhar dentro do modelo