
Até o momento, qualquer aluno que tenha feito um curso em redes neurais pode reconhecer caracteres coreanos. Dê a ele uma amostra e um computador com uma placa de vídeo e, depois de um tempo, ele oferecerá uma rede que reconhecerá os caracteres coreanos quase sem erros.
Mas essa solução terá várias desvantagens:
Primeiro , um grande número de cálculos necessários, que afetam o tempo de operação ou a energia necessária (o que é muito importante para dispositivos móveis). De fato, se queremos reconhecer pelo menos 3000 caracteres, esse será o tamanho da última camada da rede. E se a entrada dessa camada for pelo menos 512, obteremos multiplicações de 512 * 3000. Demais.
Em segundo lugar , o tamanho. A mesma última camada do exemplo anterior pesará 512 * 3001 * 4 bytes, ou seja, cerca de 6 megabytes. Esta é apenas uma camada, a rede inteira pesará dezenas de megabytes. É claro que esse não é um grande problema para um computador de mesa, mas nem todos estarão prontos para armazenar tantos dados em um smartphone para reconhecer um idioma.
Em terceiro lugar , essa rede fornecerá resultados imprevisíveis em imagens que não são caracteres coreanos, mas são usadas em textos coreanos. Em condições de laboratório, isso não é difícil, mas para a aplicação prática da tecnologia, esse problema deverá ser resolvido de alguma forma.
E em quarto lugar , o problema é o número de caracteres: 3000 é provavelmente o suficiente para, por exemplo, distinguir um bife de um pepino do mar frito no menu do restaurante, mas às vezes existem textos mais complexos. Será difícil treinar a rede para um número maior de caracteres: não apenas será mais lento, como também haverá um problema com a coleta da amostra de treinamento, uma vez que a frequência dos caracteres diminui aproximadamente exponencialmente. Obviamente, você pode obter imagens de fontes e aumentá-las, mas isso não é suficiente para treinar uma boa rede.
E hoje vou lhe contar como conseguimos resolver esses problemas.
Como a escrita coreana funciona?
A escrita coreana, Hangul, é um cruzamento entre a escrita chinesa e a europeia. Externamente, esses são caracteres quadrados que se assemelham a hieróglifos e, em uma página do texto, você pode contar mais de uma centena de caracteres únicos. Por outro lado, é a escrita fonética, ou seja, baseada na gravação de sons. Há um alfabeto contendo 24 letras (além disso, você também pode contar difractos e ditongos). Mas, diferentemente do alfabeto latino ou cirílico, os sons não são escritos em uma linha, mas combinados em blocos. Por exemplo, se escrevermos da mesma maneira, a frase "Olá, Habr" poderá ser escrita em três blocos como este:
Cada bloco pode consistir em duas, três ou quatro letras. Nesse caso, a consoante sempre vem primeiro, depois uma ou duas vogais e, no final, pode haver outra consoante. Existem várias maneiras diferentes de combinar letras em blocos, ou seja, em blocos diferentes, a segunda letra, por exemplo, fica em lugares diferentes.
A figura abaixo mostra dois blocos que juntos formam a palavra "Hangul". A primeira letra de cada bloco é indicada em vermelho, as vogais são destacadas em azul e a consoante final é destacada em verde.
Fonte da imagem: Wikipedia.Modificar bloco Hangul
Ou seja, acontece que um bloco Hangul pode ser descrito pela fórmula: Ci V [V] [Cf], em que Ci é a consoante inicial (possivelmente dupla), V é a vogal e Cf é a consoante final (também pode ser dupla). Essa representação é inconveniente para o reconhecimento, por isso a alteramos.
Primeiro, combine as duas vogais. Temos a fórmula Ci V '[Cf], onde V' - todas as opções possíveis para combinar letras, considerando a ausência da segunda letra. Como existem 10 vogais no idioma, seria de esperar que, como resultado, obtivemos 10 * (10 + 1) opções, mas, na prática, nem todas elas são possíveis, apenas 21 são obtidas.
Além disso, a última letra pode não ser. Acrescente às muitas letras esperadas no final uma letra vazia. Em seguida, obtemos a fórmula Ci V 'Cf *. Assim, verifica-se que agora o símbolo coreano sempre consiste em três "letras". Você pode aprender a grade.
Construímos uma rede
A idéia é que, em vez de reconhecermos todo o personagem, reconheceremos as letras individuais neles. Assim, em vez de um softmax enorme no final, temos três pequenos, cada um com algumas dezenas de tamanho. Eles correspondem à primeira, segunda e terceira "letras" da sílaba. Como resultado, obtivemos a seguinte arquitetura:
imagem clicável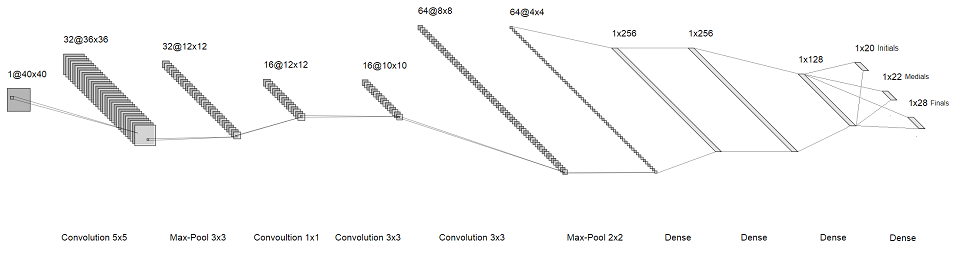
Nós treinamos, corremos em uma amostra separada. A qualidade é boa, a grade é rápida e pesa pouco. Vamos tentar tirá-lo do laboratório para o mundo real.
Resolvemos problemas
Nós vamos encontrar o primeiro problema imediatamente: às vezes imagens que não são caracteres coreanos entram na entrada e a rede nelas se comporta de maneira extremamente imprevisível. É claro que você pode treinar outra rede que distingue os blocos coreanos de todo o resto, mas facilitaremos isso.
Vamos fazer o mesmo que fizemos com o terceiro grupo de letras: adicione uma saída pela ausência de uma letra. Então a fórmula do símbolo ficará assim: Ci * V '* Cf *. E no conjunto de treinamento, adicionaremos todo tipo de lixo - caracteres chineses, caracteres incorretamente cortados, letras européias e ensinaremos a rede a marcar três letras vazias.
Nós treinamos, testamos. Funciona, mas os problemas permanecem. Acontece que, com bastante frequência, por exemplo, essas imagens entram na grade:
Esse é o bloco coreano correto no qual uma aspas simples está presa. E é óbvio que neles a rede encontra perfeitamente todas as três letras das quais o bloco consiste. Isso é apenas a imagem não está correta, e precisamos sinalizar sobre isso. É errado retornar letras vazias aqui, como estão na imagem. Vamos tentar aplicar o que já provou ser bom: adicione mais duas saídas para reconhecer esses pontuadores rígidos. Em cada uma delas, haverá uma saída adicional para uma situação em que não há nada supérfluo na imagem, mas, além disso, é necessário adicionar mais uma saída para a situação "há um pontuador, mas não é reconhecido, provavelmente lixo".
Treinado É ruim nessa grade reconhecer os pontuadores: distingue uma vírgula de um colchete, mas já é difícil de um ponto. Você pode aumentar a complexidade da grade, mas não deseja. Lidaremos com o reconhecimento dos pontuadores mais tarde, mas, por enquanto, simplesmente divulgaremos se há algo lá ou não. Essa grade aprendeu bem.
Descobrimos os pontuadores colados, mas e se, pelo contrário, parte da chave estiver faltando na imagem? Havia uma palavra com dois caracteres, mas a dividimos em caracteres incorretamente:
A rede aqui sem problemas determina a letra central. Seria uma qualidade muito útil se nossa tarefa fosse reconhecer apenas uma seleção de caracteres, mas no mundo real seria prejudicial: quando cortamos incorretamente a string em caracteres, devemos passar essas informações acima, pois, caso contrário, a peça restante será reconhecida como algum tipo de pontuação e no texto resultante haverá um caractere extra.
Para resolver esse problema, usaremos o que resta de alguns experimentos antigos de muitos anos atrás. A idéia de reconhecer caracteres coreanos por letras apareceu há muito tempo, e as primeiras tentativas foram feitas mesmo antes da era das redes neurais, mas elas não encontraram aplicação prática. Mas desde então, coisas interessantes permaneceram:
- Marcar onde cada bloco tem uma letra.
- Alta qualidade, embora rápida, cortando essas letras dos símbolos.
Depois de limpar a poeira, com a ajuda dessas coisas, geraremos um número suficiente de imagens problemáticas sem uma das letras e ensinaremos especialmente a rede a responder que elas são uma carta vazia.
Isso é tudo, não há mais problemas em reconhecer caracteres coreanos, mas a vida coloca as varas nas rodas novamente.
O fato é que, além dos caracteres Hangeul, os textos coreanos também consistem em um grande número de outros caracteres: pontuadores, caracteres europeus (pelo menos números) e caracteres chineses. Mas eles ocorrem naturalmente com muito menos frequência. Vamos dividi-los em dois grupos: hieróglifos e tudo mais, e treinaremos nossa grade para cada um deles. E faremos um classificador simples, que, de acordo com os resultados da rede para o reconhecimento de caracteres coreanos e para alguns outros sinais (geométricos, em primeiro lugar), responderá se pelo menos um deles precisa ser lançado e, em caso afirmativo, qual. Você precisa reconhecer um pouco de caracteres europeus, para que a grade seja pequena, mas para hieróglifos ... Isso poupa que eles raramente sejam encontrados em textos, então vamos torcer nosso classificador para sugerir muito raramente reconhecê-los.
Em geral, com essas duas grades, o problema de uma resposta adequada surge em imagens que não são símbolos sobre as quais ela foi treinada, mas falaremos sobre como resolver esse problema outra vez.
Realizar experiências
Primeiro . Existem duas bases de imagem, vamos chamá-las de Real e Sintética. Real consiste em imagens reais obtidas de documentos digitalizados e Imagens sintéticas obtidas de fontes. Na primeira base, existem imagens para 2374 blocos (o restante é muito raro) e, a partir das fontes, obtivemos todos os 11172 caracteres possíveis. Vamos tentar treinar a rede nos blocos que estão no Real (vamos tirar as imagens das duas bases) e testar nos que estão apenas no Synthetic. Resultados:

Ou seja, em cerca de 60% dos casos, a rede é capaz de reconhecer esses blocos, exemplos dos quais não viu durante o treinamento. A qualidade poderia ter sido maior, se não fosse por um problema: entre as cartas finais, há muito raras e, durante o treinamento, a rede viu muito poucas imagens de blocos nelas. Isso explica a baixa qualidade na última coluna. Se fosse possível escolher os 2374 blocos em que estudamos, de uma maneira diferente, a qualidade provavelmente seria notavelmente mais alta.
Segundo . Compare nossa rede com uma rede "normal", que possui o softmax no final. Gostaria de fazer 11172 em tamanho, mas não conseguimos encontrar um número suficiente de imagens reais para blocos raros, por isso nos restringimos a 2374. A qualidade e a velocidade dessa rede dependem do tamanho das camadas ocultas. Apenas ensinaremos no Real, testá-lo (por outro lado, é claro).

Ou seja, mesmo que nos limitemos a reconhecer apenas 2374 blocos, nossa rede é mais rápida e com o mesmo nível de qualidade.
Terceiro . Suponha que fomos capazes de chegar a algum lugar com uma base enorme de todos os 11172 blocos coreanos. Se treinarmos uma rede com softmax, por quanto tempo ela funcionará no prazo? É caro realizar todas as experiências, portanto, consideraremos apenas uma rede com 256 tamanhos de camada oculta:

Nós obtemos os resultados
Sem eles, nada teria acontecido
Expresso minha gratidão à minha colega Jura Chulinin, a autora original da idéia. É
patenteado na Rússia e, além disso, um pedido semelhante foi
registrado no American Patent Office (USPTO). Muito obrigado à desenvolvedora Misha Zatsepin, que implementou tudo isso e conduziu todos os experimentos.
Yuri Vatlin,
Chefe do grupo de scripts complexos