Atualmente, a visualização e análise de dados é amplamente utilizada no setor de telecomunicações. Em particular, a análise é altamente dependente do uso de dados geoespaciais. Talvez isso se deva ao fato de as próprias redes de telecomunicações estarem geograficamente dispersas. Consequentemente, a análise de tais dispersões pode ser de tremendo valor.
Dados
Para ilustrar o algoritmo de agrupamento k-means, usaremos o banco de dados geográfico para WiFi público gratuito em Nova York. O conjunto de dados está disponível no NYC Open Data. Em particular, o algoritmo de agrupamento k-means é usado para formar clusters de uso de WiFi com base em dados de latitude e longitude.
Os dados de latitude e longitude são extraídos do próprio conjunto de dados usando a linguagem de programação R:
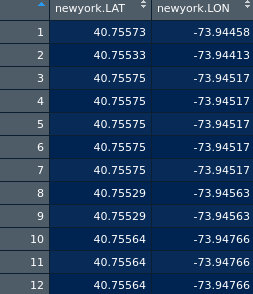
Aqui está um pedaço de dados:
Determinamos o número de clusters
Em seguida, determinamos o número de clusters usando o código abaixo, que mostra o resultado em um gráfico.
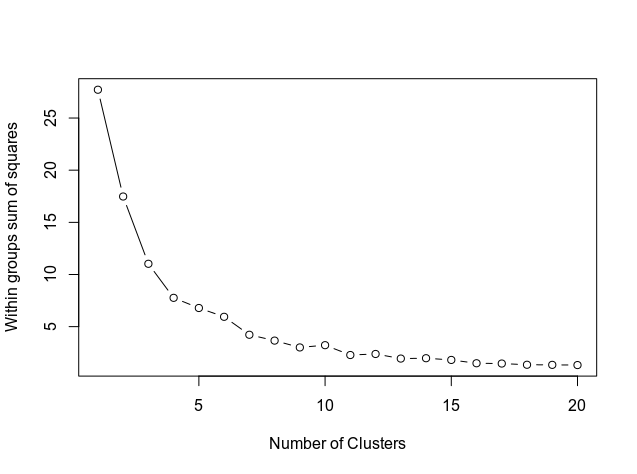
O gráfico mostra como a curva se alinha em torno de 11. Portanto, este é o número de clusters que serão usados no modelo k-means.
Análise K-means
A análise das médias K é realizada:
O conjunto de dados newyorkdf contém informações sobre latitude, longitude e rótulo do cluster:
> newyorkdf
newyork.lat newyork.lon fit.cluster
1 40,75573 -73,94458 1
2 40.75533 -73.94413 1
3 40.75575 -73.94517 1
4 40.75575 -73.94517 1
5 40.75575 -73.94517 1
6 40.75575 -73.94517 1
...
80 40,84832 -73,82075 11
Aqui está uma ilustração clara:
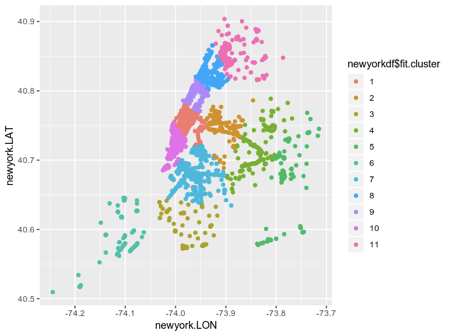
Esta ilustração é útil, mas a visualização será ainda mais valiosa se você a sobrepor em um mapa da própria Nova York.

Esse tipo de cluster fornece uma excelente idéia da estrutura de uma rede WiFi em uma cidade. Isso indica que a região geográfica marcada pelo cluster 1 mostra muito tráfego WiFi. Por outro lado, menos conexões no cluster 6 podem indicar baixo tráfego de WiFi.
O cluster K-Means sozinho não nos diz por que o tráfego de um cluster específico é alto ou baixo. Por exemplo, quando o cluster 6 tem uma alta densidade populacional, mas as velocidades baixas da Internet resultam em menos conexões.
No entanto, esse algoritmo de agrupamento fornece um excelente ponto de partida para análises adicionais e facilita a coleta de informações adicionais. Por exemplo, usando este mapa como exemplo, você pode construir hipóteses sobre clusters geográficos individuais. O artigo original está
aqui .