Olá pessoal! A primavera chegou, o que significa que resta menos de um mês antes do início do curso
Python Developer . É a este curso que a publicação de hoje será dedicada.

 Tarefas:
Tarefas:- Aprenda sobre a estrutura interna do Python;
- Compreender os princípios de construção de uma árvore de sintaxe abstrata (AST);
- Escreva código mais eficiente em tempo e memória.
Recomendações preliminares:- Compreensão básica do intérprete (AST, fichas, etc.).
- Conhecimento de Python.
- Conhecimentos básicos de C.
batuhan@arch-pc ~/blogs/cpython/exec_model python --version Python 3.7.0
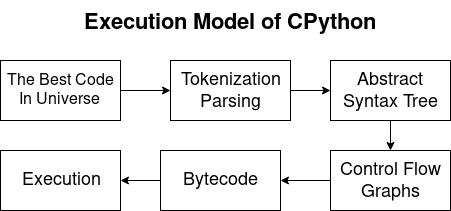
Modelo de Execução do CPythonPython é uma linguagem compilada e interpretada. Assim, o compilador Python gera bytecodes e o intérprete os executa. Durante o artigo, consideraremos os seguintes problemas:
- Análise e tokenização:
- Transformação em AST;
- Gráfico de Fluxo de Controle (CFG);
- Bytecode
- Executando em uma máquina virtual CPython.
Análise e tokenização.
Gramática.A gramática define a semântica da linguagem Python. Também é útil para indicar a maneira como o analisador deve interpretar o idioma. A gramática Python usa sintaxe semelhante à forma estendida de Backus-Naur. Possui gramática própria para um tradutor do idioma de origem. Você pode encontrar o arquivo de gramática no diretório "cpython / Grammar / Grammar".
A seguir, um exemplo de gramática,
batuhan@arch-pc ~/cpython/Grammar master grep "simple_stmt" Grammar | head -n3 | tail -n1 simple_stmt: small_stmt (';' small_stmt)* [';'] NEWLINE
Expressões simples contêm pequenas expressões e colchetes, e o comando termina com uma nova linha. Expressões pequenas parecem uma lista de expressões que importam ...
Algumas outras expressões :)
small_stmt: (expr_stmt | del_stmt | pass_stmt | flow_stmt | import_stmt | global_stmt | nonlocal_stmt | assert_stmt) ... del_stmt: 'del' exprlist pass_stmt: 'pass' flow_stmt: break_stmt | continue_stmt | return_stmt | raise_stmt | yield_stmt break_stmt: 'break' continue_stmt: 'continue'
Tokenização (Lexing)Tokenização é o processo de obter um fluxo de dados de texto e dividir em tokens de palavras significativas (para o intérprete) com metadados adicionais (por exemplo, onde o token começa e termina e qual é o valor da string desse token).
TokensUm token é um arquivo de cabeçalho que contém definições de todos os tokens. Existem 59 tipos de tokens no Python (Include / token.h).
Abaixo está um exemplo de alguns deles,
Você os verá se você dividir algum código Python em tokens.
Tokenização com CLIAqui está o arquivo tests.py
def greetings(name: str): print(f"Hello {name}") greetings("Batuhan")
Em seguida, o tokenizamos usando o comando python -m tokenize e o seguinte é gerado:
batuhan@arch-pc ~/blogs/cpython/exec_model python -m tokenize tests.py 0,0-0,0: ENCODING 'utf-8' ... 2,0-2,4: INDENT ' ' 2,4-2,9: NAME 'print' ... 4,0-4,0: DEDENT '' ... 5,0-5,0: ENDMARKER ''
Aqui, os números (por exemplo, 1.4-1.13) mostram onde o token começou e onde terminou. Um token de codificação é sempre o primeiro token que recebemos. Ele fornece informações sobre a codificação do arquivo de origem e, se houver algum problema, o intérprete gera uma exceção.
Tokenização com tokenize.tokenizeSe você precisar tokenizar o arquivo a partir do seu código, poderá usar o módulo
tokenize no
stdlib .
>>> with open('tests.py', 'rb') as f: ... for token in tokenize.tokenize(f.readline): ... print(token) ... TokenInfo(type=57 (ENCODING), string='utf-8', start=(0, 0), end=(0, 0), line='') ... TokenInfo(type=1 (NAME), string='greetings', start=(1, 4), end=(1, 13), line='def greetings(name: str):\n') ... TokenInfo(type=53 (OP), string=':', start=(1, 24), end=(1, 25), line='def greetings(name: str):\n') ...
O tipo de token é seu ID no arquivo de cabeçalho
token.h. String é o valor do token. Início e Fim mostram onde o token começa e termina, respectivamente.
Em outros idiomas, os blocos são indicados entre colchetes ou instruções de início / fim, mas o Python usa recuos e níveis diferentes. Indent e DEDENT tokens e indicam recuo. Esses tokens são necessários para criar árvores de análise relacional e / ou árvores de sintaxe abstrata.
Geração de analisadorGeração de analisador - um processo que gera um analisador de acordo com uma determinada gramática. Os geradores de analisadores são conhecidos como PGen. O Cpython possui dois geradores de analisador. Um é o original (
Parser/pgen ) e um reescrito em python (
/Lib/lib2to3/pgen2 ).
"O gerador original foi o primeiro código que escrevi para Python"
-GuidoA partir da citação acima, fica claro que
pgen é a coisa mais importante em uma linguagem de programação. Quando você chama pgen (no
Analisador / pgen ), ele gera um arquivo de cabeçalho e um arquivo C (o próprio analisador). Se você olhar para o código C gerado, pode parecer inútil, pois sua aparência significativa é opcional. Ele contém muitos dados e estruturas estáticos. A seguir, tentaremos explicar seus principais componentes.
DFA (Máquina de Estado Definido)O analisador define um DFA para cada não-terminal. Cada DFA é definido como uma matriz de estados.
static dfa dfas[87] = { {256, "single_input", 0, 3, states_0, "\004\050\340\000\002\000\000\000\012\076\011\007\262\004\020\002\000\300\220\050\037\202\000"}, ... {342, "yield_arg", 0, 3, states_86, "\000\040\200\000\002\000\000\000\000\040\010\000\000\000\020\002\000\300\220\050\037\000\000"}, };
Para cada DFA, há um kit inicial que mostra com quais tokens um terminal não terminal especial pode começar.
CondiçãoCada estado é definido por uma matriz de transições / arestas (arcos).
static state states_86[3] = { {2, arcs_86_0}, {1, arcs_86_1}, {1, arcs_86_2}, };
Transições (arcos)Cada matriz de transição possui dois números. O primeiro número é o nome da transição (etiqueta do arco), refere-se ao número do símbolo. O segundo número é o destino.
static arc arcs_86_0[2] = { {77, 1}, {47, 2}, }; static arc arcs_86_1[1] = { {26, 2}, }; static arc arcs_86_2[1] = { {0, 2}, };
Nomes (etiquetas)Esta é uma tabela especial que mapeia o ID do caractere para o nome da transição.
static label labels[177] = { {0, "EMPTY"}, {256, 0}, {4, 0}, ... {1, "async"}, {1, "def"}, ... {1, "yield"}, {342, 0}, };
O número 1 corresponde a todos os identificadores. Assim, cada um deles obtém nomes de transição diferentes, mesmo que todos tenham o mesmo ID de caractere.
Um exemplo simples:Suponha que tenhamos um código que emita "Hi" se 1 - true:
if 1: print('Hi')
O analisador considera esse código como single_input.
single_input: NEWLINE | simple_stmt | compound_stmt NEWLINE
Em seguida, nossa árvore de análise começa no nó raiz de uma entrada única.

E o valor do nosso DFA (single_input) é 0.
static dfa dfas[87] = { {256, "single_input", 0, 3, states_0, "\004\050\340\000\002\000\000\000\012\076\011\007\262\004\020\002\000\300\220\050\037\202\000"} ... }
Ficará assim:
static arc arcs_0_0[3] = { {2, 1}, {3, 1}, {4, 2}, }; static arc arcs_0_1[1] = { {0, 1}, }; static arc arcs_0_2[1] = { {2, 1}, }; static state states_0[3] = { {3, arcs_0_0}, {1, arcs_0_1}, {1,
arcs_0_2},
};
Aqui
arc_0_0 consiste em três elementos. O primeiro é
NEWLINE , o segundo é
simple_stmt e o último é
compound_stmt .
Dado o conjunto inicial de
simple_stmt podemos concluir que
simple_stmt não pode começar com
if . No entanto, mesmo se não for uma nova linha, o
compound_stmt ainda poderá começar com
if . Portanto, passamos para o último
arc ({4;2}) e adicionamos o nó composite_stmt à árvore de análise e mudamos para o novo DFA antes de prosseguir para o número 2. Temos uma árvore de análise atualizada:

O novo DFA analisa instruções compostas.
compound_stmt: if_stmt | while_stmt | for_stmt | try_stmt | with_stmt | funcdef | classdef | decorated | async_stmt
E temos o seguinte:
static arc arcs_39_0[9] = { {91, 1}, {92, 1}, {93, 1}, {94, 1}, {95, 1}, {19, 1}, {18, 1}, {17, 1}, {96, 1}, }; static arc arcs_39_1[1] = { {0, 1}, }; static state states_39[2] = { {9, arcs_39_0}, {1, arcs_39_1}, };
Somente o primeiro salto pode começar com
if . Temos uma árvore de análise atualizada.
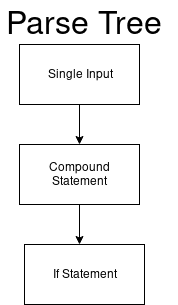
Em seguida, alteramos novamente o DFA e os próximos ifs do DFA.
if_stmt: 'if' test ':' suite ('elif' test ':' suite)* ['else' ':' suite]
Como resultado, obtemos a única transição com a designação 97. Ela coincide com o token
if .
static arc arcs_41_0[1] = { {97, 1}, }; static arc arcs_41_1[1] = { {26, 2}, }; static arc arcs_41_2[1] = { {27, 3}, }; static arc arcs_41_3[1] = { {28, 4}, }; static arc arcs_41_4[3] = { {98, 1}, {99, 5}, {0, 4}, }; static arc arcs_41_5[1] = { {27, 6}, }; static arc arcs_41_6[1] = { {28, 7}, }; ...
Quando passamos para o próximo estado, permanecendo no mesmo DFA, o próximo arcs_41_1 também possui apenas uma transição. Isso é verdade para o terminal de teste. Ele deve começar com um número (por exemplo, 1).
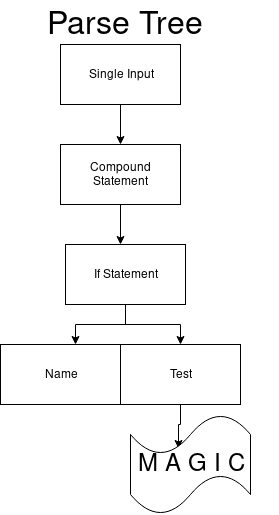
Existe apenas uma transição no arc_41_2 que obtém o token de dois pontos (:).

Portanto, temos um conjunto que pode começar com um valor de impressão. Por fim, vá para arcs_41_4. A primeira transição no conjunto é uma expressão elif, a segunda é outra, e a terceira é para o último estado. E temos a visão final da árvore de análise.
 Interface Python para analisador.
Interface Python para analisador.
O Python permite editar a árvore de análise de expressões usando um módulo chamado analisador.
>>> import parser >>> code = "if 1: print('Hi')"
Você pode gerar uma árvore de sintaxe específica (Árvore de sintaxe concreta, CST) usando o parser.suite.
>>> parser.suite(code).tolist() [257, [269, [295, [297, [1, 'if'], [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [2, '1']]]]]]]]]]]]]]]], [11, ':'], [304, [270, [271, [272, [274, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [1, 'print']], [326, [7, '('], [334, [335, [305, [309, [310, [311, [312, [315, [316, [317, [318, [319, [320, [321, [322, [323, [324, [3, "'Hi'"]]]]]]]]]]]]]]]]]], [8, ')']]]]]]]]]]]]]]]]]]], [4, '']]]]]], [4, ''], [0, '']]
O valor de saída será uma lista aninhada. Cada lista na estrutura possui 2 elementos. O primeiro é o ID do caractere (0-256 - terminais, 256+ - não terminais) e o segundo é a sequência de tokens para o terminal.
Árvore de sintaxe abstrataDe fato, uma árvore de sintaxe abstrata (AST) é uma representação estrutural do código-fonte na forma de uma árvore, em que cada vértice denota tipos diferentes de construções de linguagem (expressão, variável, operador, etc.)
O que é uma árvore?Uma árvore é uma estrutura de dados que possui um vértice raiz como ponto de partida. O vértice raiz é abaixado por ramos (transições) até outros vértices. Cada vértice, exceto a raiz, possui um vértice pai exclusivo.
Há uma certa diferença entre a árvore de sintaxe abstrata e a árvore de análise.
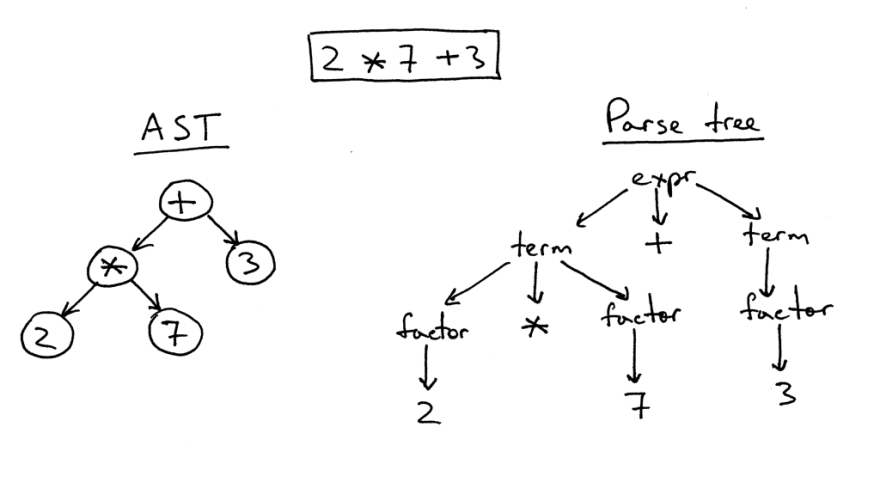
À direita, há uma árvore de análise para a expressão 2 * 7 + 3. Esta é literalmente uma imagem de origem individual sob a forma de uma árvore. Todas as expressões, termos e valores são visíveis nele. No entanto, essa imagem é muito complicada para um simples trecho de código; portanto, podemos simplesmente remover todas as expressões sintáticas que tivemos que definir no código para os cálculos.
Essa árvore simplificada é chamada de árvore de sintaxe abstrata (AST). À esquerda na figura, é mostrado exatamente para o mesmo código. Todas as expressões de sintaxe foram descartadas para facilitar o entendimento, mas lembre-se de que determinadas informações foram perdidas.
Exemplo
O Python oferece um módulo AST embutido para trabalhar com o AST. Para gerar código a partir de árvores AST, você pode usar módulos de terceiros, por exemplo,
Astor .
Por exemplo, considere o mesmo código de antes.
>>> import ast >>> code = "if 1: print('Hi')"
Para obter o AST, usamos o método ast.parse.
>>> tree = ast.parse(code) >>> tree <_ast.Module object at 0x7f37651d76d8>
Tente usar o método
ast.dump para obter uma árvore de sintaxe abstrata mais legível.
>>> ast.dump(tree) "Module(body=[If(test=Num(n=1), body=[Expr(value=Call(func=Name(id='print', ctx=Load()), args=[Str(s='Hi')], keywords=[]))], orelse=[])])"
O AST é geralmente considerado mais visual e fácil de entender do que a árvore de análise.
Graf de fluxo de controle (CFG)Os gráficos de fluxo de controle são gráficos direcionais que modelam o fluxo de um programa usando blocos base que contêm uma representação intermediária.
Normalmente, CFG é a etapa anterior antes de obter os valores do código de saída. O código é gerado diretamente a partir dos blocos de base usando uma pesquisa de profundidade para trás no CFG, começando pelos topos.
BytecodeO bytecode do Python é um conjunto intermediário de instruções que funcionam em uma máquina virtual Python. Quando você executa o código-fonte, o Python cria um diretório chamado __pycache__. Ele armazena o código compilado para economizar tempo em caso de reiniciar a compilação.
Considere uma função Python simples em func.py.
def say_hello(name: str): print("Hello", name) print(f"How are you {name}?")
>>> from func import say_hello >>> say_hello("Batuhan") Hello Batuhan How are you Batuhan?
O
say_hello objeto
say_hello é uma função.
>>> type(say_hello) <class 'function'>
Possui o atributo
__code__ .
>>> say_hello.__code__ <code object say_hello at 0x7f13777d9150, file "/home/batuhan/blogs/cpython/exec_model/func.py", line 1>
Objetos de códigoObjetos de código são estruturas de dados imutáveis que contêm as instruções ou metadados necessários para executar o código. Simplificando, essas são representações do código Python. Você também pode obter objetos de código compilando árvores de sintaxe abstrata usando o método
compile .
>>> import ast >>> code = """ ... def say_hello(name: str): ... print("Hello", name) ... print(f"How are you {name}?") ... say_hello("Batuhan") ... """ >>> tree = ast.parse(code, mode='exec') >>> code = compile(tree, '<string>', mode='exec') >>> type(code) <class 'code'>
Cada objeto de código possui atributos que contêm determinadas informações (prefixadas com co_). Aqui mencionamos apenas alguns deles.
co_namePara começar - um nome. Se uma função existe, ela deve ter um nome, respectivamente, esse nome será o nome da função, uma situação semelhante à da classe. No exemplo AST, usamos módulos e podemos dizer exatamente ao compilador como queremos chamá-los. Deixe que sejam apenas um
module .
>>> code.co_name '<module>' >>> say_hello.__code__.co_name 'say_hello'
co_varnamesEsta é uma tupla que contém todas as variáveis locais, incluindo argumentos.
>>> say_hello.__code__.co_varnames ('name',)
co_contsUma tupla contendo todos os literais e valores constantes que acessamos no corpo da função. Aqui vale a pena notar o valor de Nenhum. Não incluímos None no corpo da função, no entanto, o Python indicou, porque se a função começar a executar e terminar sem receber nenhum valor de retorno, ela retornará None.
>>> say_hello.__code__.co_consts (None, 'Hello', 'How are you ', '?')
Código de bytes (co_code)A seguir, é apresentado o bytecode de nossa função.
>>> bytecode = say_hello.__code__.co_code >>> bytecode b't\x00d\x01|\x00\x83\x02\x01\x00t\x00d\x02|\x00\x9b\x00d\x03\x9d\x03\x83\x01\x01\x00d\x00S\x00'
Isso não é uma string, é um objeto de byte, ou seja, uma sequência de bytes.
>>> type(bytecode) <class 'bytes'>
O primeiro caractere impresso é "t". Se pedirmos seu valor numérico, obteremos o seguinte.
>>> ord('t') 116
116 é o mesmo que bytecode [0].
>>> assert bytecode[0] == ord('t')
Para nós, um valor de 116 não significa nada. Felizmente, o Python fornece uma biblioteca padrão chamada dis (da desmontagem). É útil ao trabalhar com a lista opname. Esta é uma lista de todas as instruções de bytecode, em que cada índice é o nome da instrução.
>>> dis.opname[ord('t')] 'LOAD_GLOBAL'
Vamos criar outra função mais complexa.
>>> def multiple_it(a: int): ... if a % 2 == 0: ... return 0 ... return a * 2 ... >>> multiple_it(6) 0 >>> multiple_it(7) 14 >>> bytecode = multiple_it.__code__.co_code
E descobrimos a primeira instrução em bytecode.
>>> dis.opname[bytecode[0]] 'LOAD_FAST
A instrução LOAD_FAST consiste em dois elementos.
>>> dis.opname[bytecode[0]] + ' ' + dis.opname[bytecode[1]] 'LOAD_FAST <0>'
A instrução Loadfast 0 procura por nomes de variáveis em uma tupla e envia um elemento com um índice zero para uma tupla na pilha de execução.
>>> multiple_it.__code__.co_varnames[bytecode[1]] 'a'
Nosso código pode ser desmontado usando dis.dis e converter o bytecode em uma visualização familiar. Aqui os números (2,3,4) são os números de linha. Cada linha de código no Python é expandida como um conjunto de instruções.
>>> dis.dis(multiple_it) 2 0 LOAD_FAST 0 (a) 2 LOAD_CONST 1 (2) 4 BINARY_MODULO 6 LOAD_CONST 2 (0) 8 COMPARE_OP 2 (==) 10 POP_JUMP_IF_FALSE 16 3 12 LOAD_CONST 2 (0) 14 RETURN_VALUE 4 >> 16 LOAD_FAST 0 (a) 18 LOAD_CONST 1 (2) 20 BINARY_MULTIPLY 22 RETURN_VALUE
Prazo de execuçãoCPython é uma máquina virtual orientada a pilha, não uma coleção de registros. Isso significa que o código Python é compilado para uma máquina virtual com uma arquitetura de pilha.
Ao chamar uma função, o Python usa duas pilhas juntas. O primeiro é a pilha de execução e o segundo é a pilha de blocos. A maioria das chamadas ocorre na pilha de execução; a pilha de blocos controla quantos blocos estão ativos no momento, bem como outros parâmetros relacionados a blocos e escopos.
Aguardamos seus comentários sobre o material e convidamos você para
um seminário on-
line aberto sobre o tema: “Solte-o: aspectos práticos da liberação de software confiável”, que será conduzido por nosso professor, programador do sistema de publicidade no Mail.Ru,
Stanislav Stupnikov .