O conhecimento de apenas uma abordagem da raspagem da Web resolve o problema no curto prazo, mas todos os métodos têm seus pontos fortes e fracos. A consciência disso economiza tempo e ajuda a resolver o problema com mais eficiência.

Inúmeros recursos falam sobre o único método verdadeiro de recuperar dados de uma página da web. Mas a realidade é que, para isso, você pode usar várias soluções e ferramentas.
- Quais são as opções para extrair programaticamente dados de uma página da web?
- Prós e contras de cada abordagem?
- Como usar os recursos da nuvem para aumentar o grau de automação?
O artigo ajudará a obter respostas para essas perguntas.
Suponho que você já saiba quais são
as solicitações
HTTP ,
DOM (Document Object Model),
HTML ,
seletores CSS e
JavaScript assíncrono .
Caso contrário, aconselho a se aprofundar na teoria e depois retornar ao artigo.
Conteúdo estático
Fontes HTMLVamos começar com a abordagem mais simples.
Se você planeja descartar páginas da web, essa é a primeira coisa a começar. Isso exigirá pouca energia do computador e um tempo mínimo.
No entanto, isso só funciona se o código-fonte HTML contiver os dados que você está direcionando. Para testar isso no Chrome, clique com o botão direito do mouse na página e selecione Exibir código da página. Agora você deve ver o código-fonte HTML.
Depois de encontrar os dados, escreva um
seletor CSS que pertença ao elemento de quebra automática para que você tenha um link posteriormente.
Para implementação, você pode enviar uma solicitação HTTP GET para o URL da página e recuperar o código-fonte HTML.
No
Node, você pode usar a ferramenta
CheerioJS para
analisar o HTML bruto e recuperar dados usando um seletor. O código ficará assim:
const fetch = require('node-fetch'); const cheerio = require('cheerio'); const url = 'https://example.com/'; const selector = '.example'; fetch(url) .then(res => res.text()) .then(html => { const $ = cheerio.load(html); const data = $(selector); console.log(data.text()); });
Conteúdo dinâmico
Em muitos casos, você não pode acessar informações do código HTML bruto porque o DOM foi controlado pelo JavaScript em execução em segundo plano. Um exemplo típico disso é um SPA (aplicativo de página única), em que um documento HTML contém informações mínimas e o JavaScript as preenche em tempo de execução.
Nessa situação, a solução é criar o DOM e executar os scripts localizados no código-fonte HTML, como o navegador faz. Depois disso, os dados podem ser extraídos desse objeto usando seletores.
Navegadores sem cabeçaO navegador sem cabeça é o mesmo que um navegador normal, apenas sem uma interface de usuário. Ele é executado em segundo plano e você pode controlá-lo programaticamente em vez de clicar e digitar no teclado.
O Puppeteer é um dos navegadores sem cabeça mais populares. Essa é uma biblioteca de nós fácil de usar que fornece uma API de alto nível para gerenciar o Chrome offline. Ele pode ser configurado para ser executado sem um cabeçalho, o que é muito conveniente durante o desenvolvimento. O código a seguir faz a mesma coisa que antes, mas funcionará com páginas dinâmicas:
const puppeteer = require('puppeteer'); async function getData(url, selector){ const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto(url); const data = await page.evaluate(selector => { return document.querySelector(selector).innerText; }, selector); await browser.close(); return data; } const url = 'https://example.com'; const selector = '.example'; getData(url,selector) .then(result => console.log(result));
Claro, você pode fazer coisas mais interessantes com o Puppeteer, então confira a
documentação . Aqui está um trecho de código que navega no URL, tira uma captura de tela e a salva:
const puppeteer = require('puppeteer'); async function takeScreenshot(url,path){ const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto(url); await page.screenshot({path: path}); await browser.close(); } const url = 'https://example.com'; const path = 'example.png'; takeScreenshot(url, path);
O navegador requer muito mais poder computacional do que o envio de uma solicitação GET simples e a análise da resposta. Portanto, a execução é relativamente lenta. Não apenas isso, mas também a adição de um navegador como uma dependência torna o pacote enorme.
Por outro lado, esse método é muito flexível. Você pode usá-lo para navegar nas páginas, simular cliques, movimentos do mouse e usar o teclado, preencher formulários, criar capturas de tela ou criar páginas em PDF, executar comandos no console, selecionar itens para extrair o conteúdo do texto. Basicamente, tudo o que pode ser feito manualmente em um navegador.
Construindo um DOMVocê pensará que é desnecessário simular um navegador inteiro apenas para criar um DOM. De fato, isso é verdade, pelo menos em certas circunstâncias.
Jsdom é uma biblioteca de
nós que analisa o HTML sendo transmitido, assim como um navegador. No entanto, este não é um navegador, mas uma
ferramenta para criar o DOM a partir de um determinado código-fonte HTML , bem como para executar o código JavaScript neste HTML.
Graças a essa abstração, o Jsdom pode executar mais rápido que um navegador sem cabeça. Se for mais rápido, por que não usá-lo em vez de navegadores sem cabeça o tempo todo?
Cite a documentação :
As pessoas geralmente têm problemas ao carregar scripts de forma assíncrona ao usar o jsdom. Muitas páginas carregam scripts de forma assíncrona, mas é impossível determinar quando isso aconteceu e, portanto, quando executar o código e verificar a estrutura DOM resultante. Essa é uma limitação fundamental.
Esta solução é mostrada no exemplo. A cada 100 ms, é verificado se um elemento apareceu ou ocorreu um tempo limite (após 2 segundos).
Também costuma enviar mensagens de erro quando o Jsdom não implementa alguns recursos do navegador na página, como: “
Erro: Não implementado: window.alert ...” ou “Erro: Não implementado: window.scrollTo ... ”. Esse problema também pode ser resolvido com algumas soluções alternativas (
consoles virtuais ).
Normalmente, essa é uma API de nível inferior ao Puppeteer; portanto, você mesmo precisa implementar algumas coisas.
Isso complica um pouco o uso, como pode ser visto no exemplo.
Jsdom oferece uma solução rápida para o mesmo trabalho.
Vejamos o mesmo exemplo, mas usando
Jsdom :
const jsdom = require("jsdom"); const { JSDOM } = jsdom; async function getData(url,selector,timeout) { const virtualConsole = new jsdom.VirtualConsole(); virtualConsole.sendTo(console, { omitJSDOMErrors: true }); const dom = await JSDOM.fromURL(url, { runScripts: "dangerously", resources: "usable", virtualConsole }); const data = await new Promise((res,rej)=>{ const started = Date.now(); const timer = setInterval(() => { const element = dom.window.document.querySelector(selector) if (element) { res(element.textContent); clearInterval(timer); } else if(Date.now()-started > timeout){ rej("Timed out"); clearInterval(timer); } }, 100); }); dom.window.close(); return data; } const url = "https://example.com/"; const selector = ".example"; getData(url,selector,2000).then(result => console.log(result));
Engenharia reversaO Jsdom é uma solução rápida e fácil, mas você pode torná-lo ainda mais simples.
Precisamos modelar o DOM?
A página da web que você deseja descartar consiste no mesmo HTML e JavaScript, nas mesmas tecnologias que você já conhece. Portanto,
se você encontrar um pedaço de código do qual os dados de destino foram obtidos, poderá repetir a mesma operação para obter o mesmo resultado .
Para simplificar, os dados que você está procurando podem ser:
- parte do código-fonte HTML (como pode ser visto na primeira parte do artigo),
- parte de um arquivo estático referenciado em um documento HTML (por exemplo, uma linha em um arquivo javascript),
- resposta a uma solicitação de rede (por exemplo, algum código JavaScript enviou uma solicitação AJAX para um servidor que respondeu com uma sequência JSON).
Essas fontes de dados podem ser acessadas usando consultas de rede . Não importa se a página da Web usa HTTP, WebSockets ou qualquer outro protocolo de comunicação, porque eles são todos reproduzíveis em teoria.
Depois de encontrar um recurso que contém dados, você pode enviar uma solicitação de rede semelhante para o mesmo servidor que a página original. Como resultado, você obterá uma resposta contendo os dados de destino, que podem ser facilmente extraídos usando expressões regulares, métodos de string, JSON.parse etc.
Em palavras simples, você pode usar o recurso no qual os dados estão localizados, em vez de processar e carregar todo o material. Portanto, o problema mostrado nos exemplos anteriores pode ser resolvido com uma única solicitação HTTP em vez de controlar um navegador ou objeto JavaScript complexo.
Essa solução parece simples em teoria, mas na maioria dos casos pode consumir muito tempo e requer experiência com páginas da web e servidores.
Comece monitorando o tráfego da rede. Uma ótima ferramenta para isso é a guia
Rede no Chrome DevTools . Você verá todas as solicitações enviadas com respostas (incluindo arquivos estáticos, solicitações AJAX etc.) para iterá-las e procurar dados.
Se a resposta for alterada por qualquer código antes de ser exibida na tela, o processo será mais lento. Nesse caso, você deve encontrar essa parte do código e entender o que está acontecendo.
Como você pode ver, esse método pode exigir muito mais trabalho do que os métodos descritos acima. Por outro lado, fornece o melhor desempenho.
O diagrama mostra o tempo de execução e o tamanho do pacote necessários em comparação com Jsdom e Puppeteer:
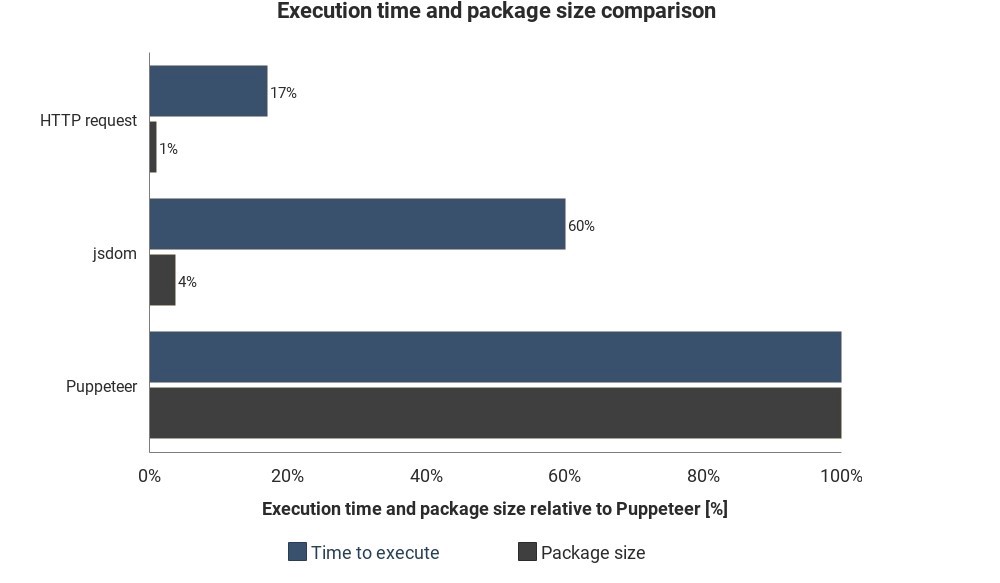
Os resultados não são baseados em medições precisas e podem variar, mas mostram boas diferenças aproximadas entre esses métodos.
Integração de serviços em nuvem
Suponha que você tenha implementado uma dessas soluções. Uma maneira de executar o script é ligar o computador, abrir o terminal e iniciá-lo manualmente.
Mas isso se tornará irritante e ineficiente, por isso seria melhor se você pudesse simplesmente carregar o script no servidor e ele executasse o código regularmente, dependendo das configurações.
Isso pode ser feito iniciando o servidor real e definindo as regras quando executar o script. Em outros casos, a função de nuvem é uma maneira mais fácil.
As funções de nuvem são armazenamentos projetados para executar o código baixado quando um evento ocorre. Isso significa que você não precisa gerenciar os servidores, isso é feito automaticamente pelo seu provedor de nuvem.
Um gatilho pode ser um agendamento, uma solicitação de rede e muitos outros eventos. Você pode salvar os dados coletados em um banco de dados, gravá-los em uma
planilha do Google ou enviá-los por
e-mail . Tudo depende da sua imaginação.
Fornecedores de nuvem populares -
Amazon Web Services (AWS),
Google Cloud Platform (GCP) e
Microsoft Azure :
Você pode usar esses serviços de graça, mas não por muito tempo.
Se você usa o Puppeteer, os
recursos do Google Cloud são a solução mais fácil. O tamanho do pacote no formato Chrome sem cabeçalho (~ 130 MB) excede o tamanho máximo permitido de arquivamento no AWS Lambda (50 MB). Existem vários métodos para fazê-lo funcionar com o Lambda, mas o GCP, por padrão,
suporta o Chrome sem cabeçalho , você só precisa incluir o Puppeteer como uma dependência no
package.json .
Se você deseja aprender mais sobre os recursos da nuvem em geral, consulte as informações da arquitetura sem servidor. Muitos bons tutoriais já foram escritos sobre esse tópico, e a maioria dos provedores possui documentação fácil de entender.