
Vou contar como conseguimos escrever um linter que se mostrou rápido o suficiente para verificar alterações durante cada push do git e fazê-lo em 5 a 10 segundos com uma base de código de 5 milhões de linhas em PHP. Nós o chamamos de NoVerify.
O NoVerify suporta coisas básicas, como a transição para a definição e pesquisa de usos, e é capaz de funcionar no modo
Servidor de Idiomas . Antes de tudo, nossa ferramenta está focada na busca de possíveis erros, mas também pode verificar o estilo. Hoje, seu código fonte apareceu em código aberto no GitHub. Procure o link no final do artigo.
Por que precisamos do nosso linter
Em meados de 2018, decidimos que era hora de implementar um linter para código PHP. Havia dois objetivos: reduzir o número de erros que os usuários veem e monitorar mais rigorosamente a conformidade com o estilo do código. A ênfase principal foi na prevenção de erros típicos: a presença de variáveis não declaradas e não utilizadas no código, código inacessível e outras. Eu também queria que o analisador estático funcionasse o mais rápido possível em nossa base de código (5-6 milhões de linhas de código PHP no momento da redação).
Como você provavelmente sabe, o código fonte da maior parte do site é escrito em PHP e compilado usando o
KPHP ; portanto, seria lógico adicionar essas verificações ao compilador. Mas, na verdade, nem todo o código faz sentido executar o KPHP - por exemplo, o compilador é pouco compatível com bibliotecas de terceiros, portanto, para algumas partes do site, o PHP regular ainda é usado. Eles também são importantes e devem ser verificados pelo linter, portanto, infelizmente, não há como integrá-lo ao KPHP.
Por que NoVerify
Dada a quantidade de código PHP (lembrarei que são de 5 a 6 milhões de linhas), não é possível "corrigi-lo" imediatamente para que seja aprovado nas verificações no linter. No entanto, quero que o código alterado se torne gradualmente mais limpo e siga mais rigorosamente os padrões de codificação, além de conter menos erros. Portanto, decidimos que o linter deveria ser capaz de verificar as alterações que o desenvolvedor lançaria e não juraria o resto.
Para fazer isso, o linter precisa indexar todo o projeto, analisar completamente os arquivos antes e depois das alterações e calcular a diferença entre os avisos gerados. Novos avisos são mostrados ao desenvolvedor, e exigimos que eles sejam corrigidos antes que o push possa ser feito.
Mas há situações em que esse comportamento é indesejável e os desenvolvedores podem enviar sem ganchos locais - usando o
git push --no-verify . Opção
--no-verify e deu um nome a um linter :)
Quais foram as alternativas
A base de código no VK usa pouco OOP e basicamente consiste em funções e classes com métodos estáticos. Se as classes no PHP suportam o carregamento automático, as funções não. Portanto, não podemos usar analisadores estáticos sem modificações significativas, que baseiam seu trabalho no fato de o carregamento automático carregar todo o código ausente. Tais linters incluem, por exemplo, o
salmo do Vimeo .
Examinamos as seguintes ferramentas de análise estática:
- PHPStan - single-threaded, requer carregamento automático; a análise da base de código atingiu 30% em meia hora;
- Phan - mesmo no modo rápido com 20 processos, a análise parou em 5% após 20 minutos;
- Salmo - requer carregamento automático, a análise levou 10 minutos (eu ainda gostaria de ser muito mais rápido);
- PHPCS - verifica o estilo, mas não a lógica;
- phpcf - verifica apenas a formatação.
Como você pode adivinhar no título do artigo, nenhuma dessas ferramentas atende aos nossos requisitos, então escrevemos os nossos.
Como o protótipo foi criado?
Primeiro, decidimos construir um pequeno protótipo para entender se vale a pena tentar fazer um linter completo. Como um dos requisitos importantes para o linter é a sua velocidade, em vez do PHP, escolhemos Go. "Rápido" é fornecer feedback ao desenvolvedor o mais rápido possível, de preferência em não mais que 10 a 20 segundos. Caso contrário, o ciclo "corrija o código, execute o linter novamente" começa a desacelerar significativamente o desenvolvimento e estragar o clima para as pessoas :)
Como Go foi selecionado para o protótipo, você precisa de um analisador PHP. Existem vários deles, mas o projeto
php-parser nos pareceu o mais maduro. Esse analisador não é perfeito e ainda está sendo desenvolvido, mas, para nossos propósitos, é bastante adequado.
Para o protótipo, foi decidido tentar implementar uma das inspeções mais simples, à primeira vista: acesso a uma variável indefinida.
A idéia básica para implementar essa inspeção parece simples: para cada ramificação (por exemplo, se), crie um escopo aninhado separado e combine os tipos de variáveis na saída dele. Um exemplo:
<?php if (rand()) { $a = 42;
Parece simples, certo? No caso de declarações condicionais comuns, tudo funciona bem. Mas devemos lidar, por exemplo, com comutadores sem interrupção;
<?php switch (rand()) { case 1: $a = 1;
Não está claro imediatamente a partir do código que $ c será sempre definido. Especificamente, este exemplo é fictício, mas ilustra bem quais são os momentos difíceis para o linter (e também para a pessoa neste caso).
Considere um exemplo mais complexo:
<?php exec("hostname", $out, $retval); echo $out, $retval;
Sem saber a assinatura da função exec, não se pode dizer se $ out e $ retval serão definidos. Assinaturas de funções
internas podem ser obtidas no repositório
github.com/JetBrains/phpstorm-stubs . Mas os mesmos problemas ocorrerão ao chamar funções definidas pelo usuário, e sua assinatura pode ser encontrada apenas pela indexação de todo o projeto. A função exec usa o segundo e o terceiro argumento por referência, o que significa que as variáveis $ out e $ retval podem ser definidas. Aqui, acessar essas variáveis não é necessariamente um erro, e o linter não deve xingar esse código.
Problemas semelhantes com a passagem implícita de links surgem com métodos, mas ao mesmo tempo, a necessidade de deduzir tipos de variáveis é adicionada:
<?php if (rand()) { $a = some_func(); } else { $a = other_func(); } $a->some_method($b); echo $b;
Precisamos saber quais tipos as funções some_func () e other_func () retornam para encontrar mais tarde um método chamado some_method nessas classes. Somente então podemos dizer se a variável $ b será definida ou não. A situação é complicada pelo fato de muitas vezes funções e métodos simples não possuírem anotações do phpdoc; portanto, você ainda precisa calcular os tipos de funções e métodos com base em sua implementação.
Ao desenvolver o protótipo, tive que implementar cerca de metade de toda a funcionalidade para que a inspeção mais simples funcionasse como deveria.
Trabalhar como servidor de idiomas
Para facilitar a depuração da lógica do linter e ver os avisos que emitem, decidimos adicionar o modo operacional como um
servidor de linguagem para PHP . No modo de integração com o Visual Studio Code, é algo parecido com isto:
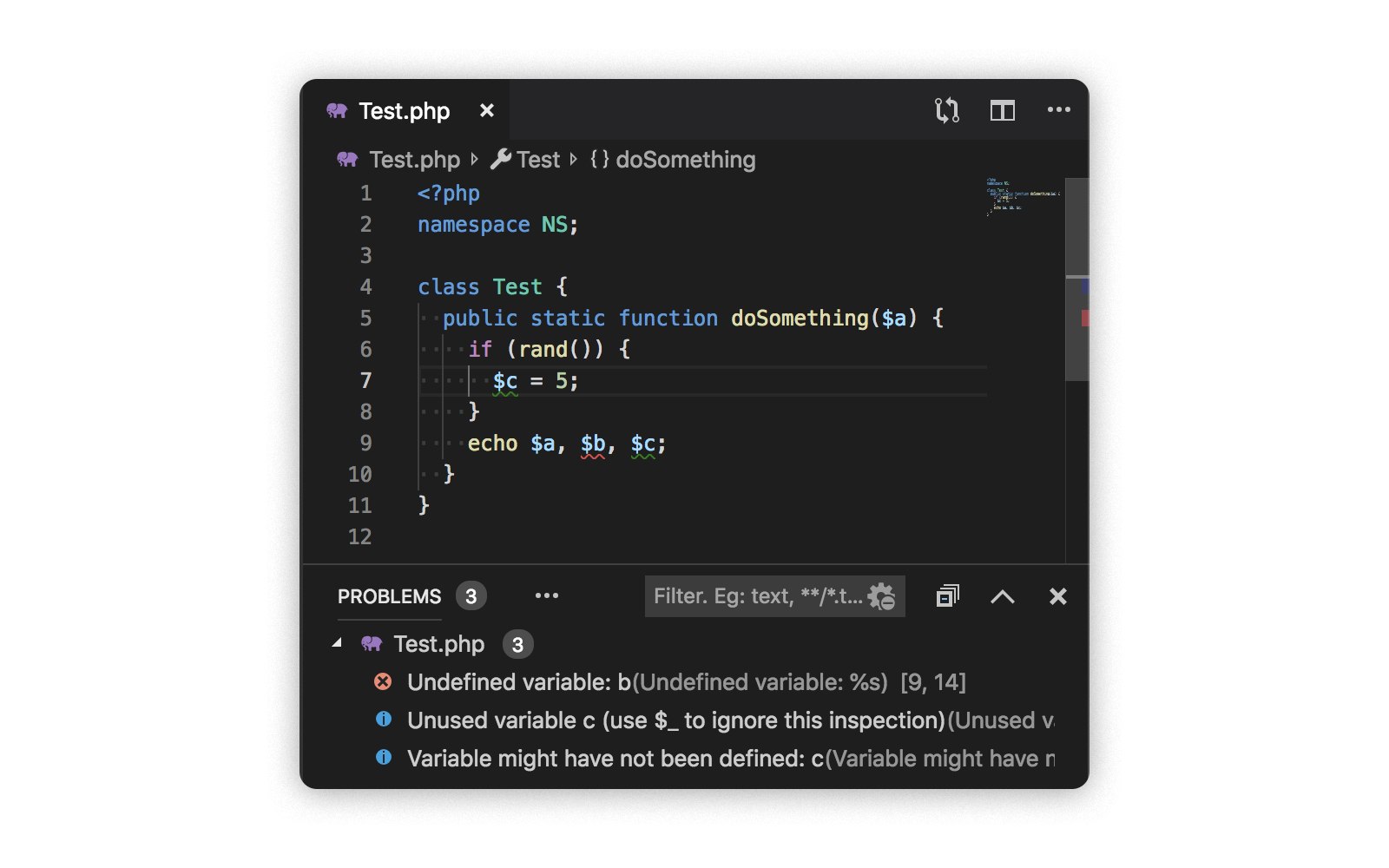
Nesse modo, é conveniente testar hipóteses e casos complexos (depois disso, é claro que você precisa escrever testes). Também é bom testar o desempenho: mesmo em arquivos grandes, o php-parser no Go mostra boa velocidade.
O suporte ao servidor de idiomas está longe de ser o ideal, pois seu principal objetivo é depurar regras de linter. No entanto, neste modo, existem vários recursos adicionais:
- Dicas para nomes de variáveis, constantes, funções, propriedades e métodos.
- Destaque tipos derivados de variáveis.
- Vá para a definição.
- Pesquise usos.
Inferência do tipo "Preguiçoso"
No modo de servidor de idiomas, é necessário o seguinte para funcionar: você altera o código em um arquivo e, ao alternar para outro, deve trabalhar com informações já atualizadas sobre quais tipos são retornados em funções ou métodos. Imagine os arquivos sendo editados na seguinte ordem:
<?php
Como não forçamos os desenvolvedores a sempre escrever PHPDoc (especialmente em casos tão simples), precisamos de uma maneira de armazenar informações sobre que tipo a função B :: something () retorna. Para que, quando o arquivo A.php for alterado, as informações de tipo no arquivo C.php estejam imediatamente atualizadas.
Uma solução possível é armazenar "tipos preguiçosos". Por exemplo, o tipo de retorno do método B :: something () é realmente um tipo de expressão (novo A) -> prop. Nesse formulário, o linter armazena informações sobre o tipo e, graças a isso, você pode armazenar em cache todas as metainformações de cada arquivo e atualizá-las somente quando esse arquivo for alterado. Isso deve ser feito com cuidado para que informações acidentalmente específicas demais sobre os tipos não vazem. Também é necessário alterar a versão do cache quando a lógica de inferência de tipo for alterada. No entanto, esse cache acelera a fase de indexação (que discutirei mais adiante) de 5 a 10 vezes em comparação com a análise repetida de todos os arquivos.
Duas fases do trabalho: indexação e análise
Como lembramos, mesmo para a análise de código mais simples, são necessárias informações pelo menos sobre todas as funções e métodos no projeto. Isso significa que você não pode analisar apenas um arquivo separadamente do projeto. E ainda - isso não pode ser feito de uma só vez: por exemplo, o PHP permite acessar funções que são declaradas mais adiante no arquivo.
Devido a essas limitações, a operação do linter consiste em duas fases: indexação primária e análise subsequente apenas dos arquivos necessários. Agora mais sobre essas duas fases.
Fase de indexação
Nesta fase, todos os arquivos são analisados e é feita uma análise local do código dos métodos e funções, bem como do código no nível superior (por exemplo, para determinar os tipos de variáveis globais). Informações sobre as variáveis globais declaradas, constantes, funções, classes e seus métodos são coletadas e gravadas no cache. Para cada arquivo no projeto, o cache é um arquivo separado no disco.
Um dicionário global de todas as metainformações sobre o projeto, que não muda no futuro *, é compilado a partir de partes individuais.
* Além do modo de operação como servidor de idiomas, quando a indexação e análise do arquivo alterado é executada para cada edição.Fase de análise
Nesta fase, podemos usar metainformações (sobre funções, classes ...) e já analisar diretamente o código. Aqui está uma lista do que o NoVerify pode verificar por padrão:
- código inacessível;
- acesso a objetos como uma matriz;
- número insuficiente de argumentos ao chamar a função;
- chamar um método / função indefinido;
- acesso à propriedade / constante da classe ausente;
- falta de classe;
- PHPDoc inválido
- acesso a uma variável indefinida;
- acesso a uma variável que nem sempre é definida;
- falta de "pausa"; após caso em construções de comutador / caso;
- erro de sintaxe
- variável não utilizada.
A lista é bastante curta, mas você pode adicionar verificações específicas ao seu projeto.
Durante a operação do linter, a inspeção mais útil é apenas a última (variável não utilizada). Isso geralmente acontece quando você refatorar o código (ou escrever um novo) e selá-lo no nome da variável: esse código é válido do ponto de vista do PHP, mas incorreto na lógica.
Velocidade de trabalho
Quanto tempo dura a alteração que queremos enviar? Tudo depende do número de arquivos. Com o NoVerify, o processo pode levar até um minuto (foi quando mudei 1400 arquivos no repositório), mas, se houver poucas edições, geralmente todas as verificações passam em 4-5 segundos. Durante esse período, o projeto é completamente indexado, analisando novos arquivos, bem como suas análises. Conseguimos criar um linter para PHP, que funciona rapidamente, mesmo com nossa grande base de códigos.
Qual é o resultado?
Como a solução está escrita em Go, é necessário usar o repositório
github.com/JetBrains/phpstorm-stubs para ter definições de todas as funções e classes incorporadas ao PHP. Em troca, obtivemos uma alta velocidade de trabalho (indexação de 1 milhão de linhas por segundo, análise de 100 mil linhas por segundo) e pudemos adicionar verificações com um linter como uma das primeiras etapas dos ganchos de pressão git.
Uma base conveniente foi desenvolvida para criar novas inspeções e foi alcançado um nível de entendimento do código próximo ao PHPStorm. Devido ao fato de que fora da caixa o modo com cálculo diff é suportado, é possível melhorar gradualmente o código, evitando novas construções potencialmente problemáticas no novo código.
O diff de contagem não é o ideal: por exemplo, se um arquivo grande foi dividido em vários pequenos, o git e, portanto, o NoVerify, não poderão determinar que o código foi movido e o linter exigirá a correção de todos os problemas encontrados. Nesse sentido, o cálculo do diff impede a refatoração em larga escala; portanto, nesses casos, ele é frequentemente desativado.
Escrever um linter no Go tem mais uma vantagem: não apenas o analisador AST é mais rápido e consome menos memória que no PHP, mas a análise subsequente também é muito rápida em comparação com qualquer coisa que possa ser feita no PHP. Isso significa que nosso linter pode realizar uma análise mais complexa e mais profunda do código, mantendo um alto desempenho (por exemplo, o recurso "tipos preguiçosos" requer um número bastante grande de cálculos no processo).
Código aberto
NoVerify disponível em código aberto no GitHubAproveite o seu uso em seu projeto!
UPD: Eu preparei uma
demonstração que funciona através do WebAssembly . A única limitação desta demonstração é a falta de definições de funções do phpstorm-stubs, portanto o linter jura em funções internas.
Yuri Nasretdinov, desenvolvedor do departamento de infraestrutura da VKontakte