
O que mais o incomoda quando pensa em efetuar login no NodeJS? Se você me perguntar, vou dizer falta de padrões da indústria para criar IDs de rastreamento. Neste artigo, mostraremos como podemos criar esses IDs de rastreamento (o que significa que examinaremos brevemente como o armazenamento local de continuação, conhecido como CLS, funciona) e nos aprofundaremos em como podemos utilizar o Proxy para fazê-lo funcionar com QUALQUER criador de logs.
Por que é um problema ter um ID de rastreamento para cada solicitação no NodeJS?
Bem, em plataformas que usam multiencadeamento e geram um novo encadeamento para cada solicitação. Existe uma coisa chamada armazenamento local de encadeamento, também conhecido como TLS , que permite manter todos os dados arbitrários disponíveis para qualquer coisa dentro de um encadeamento. Se você tiver uma API nativa para fazer isso, é bastante trivial gerar um ID aleatório para cada solicitação, coloque-o no TLS e use-o em seu controlador ou serviço posteriormente. Então, qual é o problema com o NodeJS?
Como você sabe, o NodeJS é uma plataforma de thread único (que não é mais verdadeira como agora temos trabalhadores, mas isso não muda o cenário geral), o que torna o TLS obsoleto. Em vez de operar segmentos diferentes, o NodeJS executa retornos de chamada diferentes no mesmo segmento (há uma grande série de artigos sobre loop de eventos no NodeJS, se você estiver interessado) e o NodeJS nos fornece uma maneira de identificar exclusivamente esses retornos de chamada e rastrear suas relações entre si. .
Antigamente (v0.11.11), tínhamos addAsyncListener que nos permitia rastrear eventos assíncronos. Com base nisso, a Forrest Norvell criou a primeira implementação do armazenamento local de continuação, também conhecido como CLS . Não abordaremos essa implementação do CLS devido ao fato de que nós, como desenvolvedores, já não temos essa API na v0.12.
Até o NodeJS 8, não tínhamos maneira oficial de conectar o processamento assíncrono de eventos do NodeJS. E, finalmente, o NodeJS 8 nos concedeu o poder que perdemos via async_hooks (se você quiser entender melhor o async_hooks, dê uma olhada neste artigo ). Isso nos leva à moderna implementação baseada em async_hooks do CLS - cls-hooked .
Visão geral do CLS
Aqui está um fluxo simplificado de como o CLS funciona:
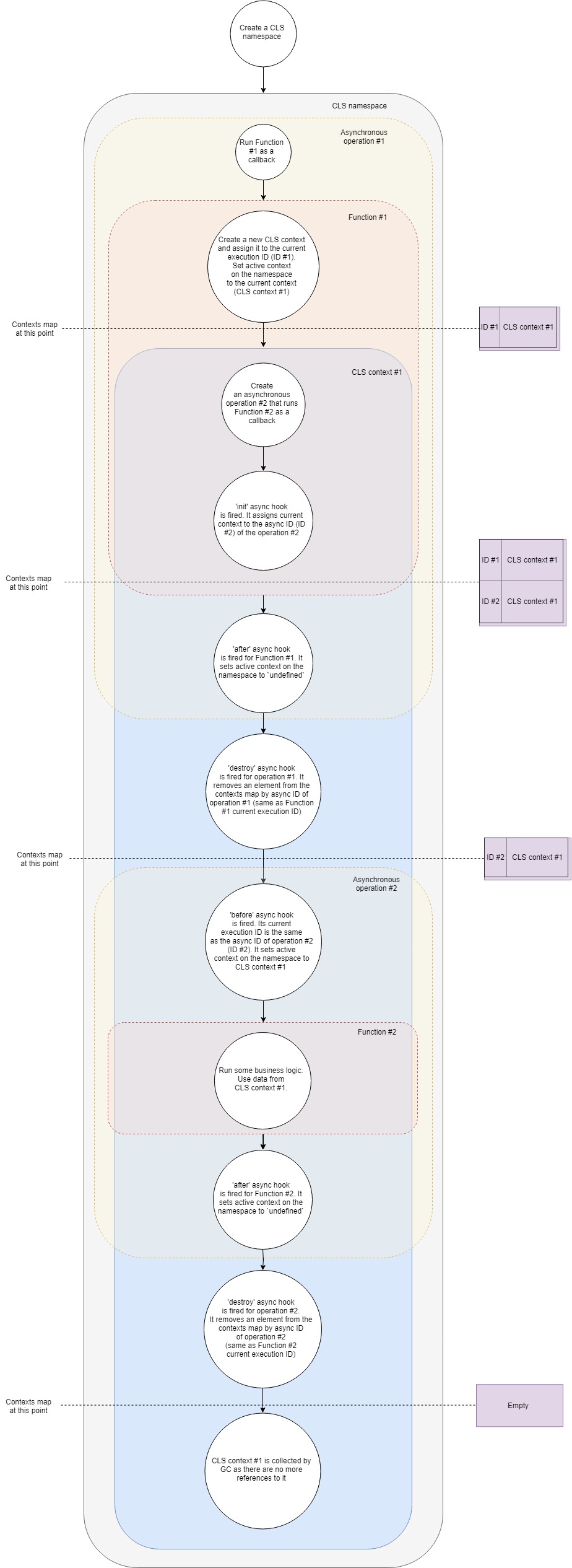
Vamos detalhar passo a passo:
- Digamos, temos um servidor Web típico. Primeiro, precisamos criar um espaço para nome CLS. Uma vez por toda a vida útil de nosso aplicativo.
- Segundo, temos que configurar um middleware para criar um novo contexto CLS para cada solicitação. Para simplificar, vamos supor que esse middleware seja apenas um retorno de chamada chamado ao receber uma nova solicitação.
- Portanto, quando chega uma nova solicitação, chamamos essa função de retorno de chamada.
- Dentro dessa função, criamos um novo contexto CLS (uma das maneiras é usar a chamada de API de execução ).
- Nesse ponto, o CLS coloca o novo contexto em um mapa de contextos pelo atual ID de execução .
- Cada espaço para nome do CLS possui propriedade
active . Nesta fase, o CLS atribui active ao contexto. - Dentro do contexto, fazemos uma chamada para um recurso assíncrono, por exemplo, solicitamos alguns dados do banco de dados. Passamos um retorno de chamada para a chamada, que será executada assim que a solicitação ao banco de dados for concluída.
- O gancho init async é acionado para uma nova operação assíncrona. Ele adiciona o contexto atual ao mapa de contextos por ID assíncrono (considere um identificador da nova operação assíncrona).
- Como não temos mais lógica dentro do nosso primeiro retorno de chamada, ele sai efetivamente, encerrando nossa primeira operação assíncrona.
- após o gancho assíncrono ser acionado para o primeiro retorno de chamada. Ele define o contexto ativo no espaço para nome como
undefined (nem sempre é verdade, pois podemos ter vários contextos aninhados, mas, no caso mais simples, é verdade). - O gancho de destruição é disparado para a primeira operação. Ele remove o contexto do nosso mapa de contextos pelo seu ID assíncrono (é o mesmo que o ID de execução atual do nosso primeiro retorno de chamada).
- A solicitação para o banco de dados foi concluída e nosso segundo retorno de chamada está prestes a ser acionado.
- Nesse ponto, antes que o gancho assíncrono entre em jogo. Seu ID de execução atual é igual ao ID assíncrono da segunda operação (solicitação do banco de dados). Ele define
active propriedade active do espaço para nome no contexto encontrado por seu ID de execução atual. É o contexto que criamos antes. - Agora, executamos nosso segundo retorno de chamada. Execute alguma lógica comercial dentro. Dentro dessa função, podemos obter qualquer valor por chave do CLS e ele retornará o que encontrar pela chave no contexto que criamos anteriormente.
- Assumindo que é o fim do processamento da solicitação, nossa função retorna.
- após o gancho assíncrono ser acionado para o segundo retorno de chamada. Ele define o contexto ativo no espaço para nome como
undefined . destroy gancho de destroy é acionado para a segunda operação assíncrona. Ele remove nosso contexto do mapa de contextos por seu ID assíncrono, deixando-o absolutamente vazio.- Como não mantemos mais nenhuma referência ao objeto de contexto, nosso coletor de lixo libera a memória associada a ele.
É uma versão simplificada do que está acontecendo sob o capô, mas abrange todas as principais etapas. Se você quiser aprofundar, pode dar uma olhada no código fonte . São menos de 500 linhas.
Gerando IDs de Rastreio
Então, uma vez que tenhamos uma compreensão geral do CLS, vamos pensar em como podemos utilizá-lo para nosso próprio bem. Uma coisa que poderíamos fazer é criar um middleware que agrupe todas as solicitações em um contexto, gere um identificador aleatório e o coloque no CLS pela chave traceID . Mais tarde, dentro de um dos nossos zilhões de controladores e serviços, poderíamos obter esse identificador no CLS.
Para expressar esse middleware, poderia ser assim:
const cls = require('cls-hooked') const uuidv4 = require('uuid/v4') const clsNamespace = cls.createNamespace('app') const clsMiddleware = (req, res, next) => {
Então, em nosso controlador, podemos obter o ID de rastreamento gerado assim:
const controller = (req, res, next) => { const traceID = clsNamespace.get('traceID') }
Não há muito uso desse ID de rastreamento, a menos que o adicione aos nossos logs.
Vamos adicioná-lo ao nosso winston .
const { createLogger, format, transports } = require('winston') const addTraceId = printf((info) => { let message = info.message const traceID = clsNamespace.get('taceID') if (traceID) { message = `[TraceID: ${traceID}]: ${message}` } return message }) const logger = createLogger({ format: addTraceId, transports: [new transports.Console()], })
Bem, se todos os registradores suportassem formatadores em uma forma de funções (muitos deles não fazem isso por um bom motivo), este artigo não existiria. Então, como adicionar um ID de rastreamento ao meu amado pino ? Proxy para o resgate!
Combinando Proxy e CLS
O proxy é um objeto que envolve nosso objeto original, permitindo que você substitua seu comportamento em determinadas situações. A lista dessas situações (na verdade, elas são chamadas de armadilhas) é limitada e você pode dar uma olhada em todo o conjunto aqui , mas estamos interessados apenas em obter armadilhas. Ele nos fornece a capacidade de interceptar o acesso à propriedade. Isso significa que se tivermos um objeto const a = { prop: 1 } e o envolvermos em um Proxy, com get trap, poderemos retornar o que quisermos para a.prop .
Portanto, a ideia é gerar um ID de rastreio aleatório para cada solicitação e criar um criador de log pino filho com o ID de rastreio e colocá-lo no CLS. Em seguida, poderíamos agrupar nosso criador de logs original com um Proxy, que redirecionaria todas as solicitações de registro para o criador de logs filho no CLS, se encontrado, e continuaria usando o criador de logs original.
Nesse cenário, nosso proxy pode ficar assim:
const pino = require('pino') const logger = pino() const loggerCls = new Proxy(logger, { get(target, property, receiver) {
Nosso middleware se transformaria em algo assim:
const cls = require('cls-hooked') const uuidv4 = require('uuid/v4') const clsMiddleware = (req, res, next) => {
E poderíamos usar o logger como este:
const controller = (req, res, next) => { loggerCls.info('Long live rocknroll!')
Com base na idéia acima, uma pequena biblioteca chamada cls-proxify foi criada. Possui integração com express , koa e fastify out of the box.
Ele se aplica não apenas get armadilha ao objeto original, mas muitos outros também. Portanto, existem inúmeras aplicações possíveis. Você poderia chamar chamadas de funções, construção de classes, praticamente qualquer coisa! Você é limitado apenas pela sua imaginação!
Dê uma olhada nas demonstrações ao vivo de usá-lo com pino e fastify, pino e express .
Felizmente, você encontrou algo útil para o seu projeto. Sinta-se livre para me comunicar seus comentários! Certamente aprecio qualquer crítica e pergunta.