
O que mais o enfurece quando você tenta organizar logs legíveis no seu aplicativo NodeJS? Pessoalmente, estou extremamente irritado com a falta de padrões saudáveis para criar IDs de rastreamento. Neste artigo, falaremos sobre as opções para criar um ID de rastreamento, vamos ver como o armazenamento local de continuação ou CLS funciona em nossos dedos e chamar a força do Proxy para obter tudo isso com qualquer criador de logs.
Por que existe algum problema no NodeJS com a criação de um ID de rastreamento para cada solicitação?
Nos velhos e velhos tempos, quando os mamutes ainda andavam pela terra, todos os servidores eram multiencadeados e criavam um novo encadeamento para uma solicitação. Dentro da estrutura desse paradigma, a criação de um ID de rastreamento é trivial, porque existe algo como armazenamento local de encadeamento ou TLS , que permite colocar na memória alguns dados que estão disponíveis para qualquer função nesse fluxo. No início do processamento da solicitação, você pode resgatar o ID de rastreamento aleatório, colocá-lo no TLS e, em seguida, lê-lo em qualquer serviço e fazer algo com ele. O problema é que isso não funcionará no NodeJS.
O NodeJS é de thread único (não exatamente, dada a aparência dos trabalhadores, mas dentro da estrutura do problema com o ID de rastreamento, os trabalhadores não desempenham nenhum papel), para que você possa esquecer o TLS. Aqui, o paradigma é diferente - manipular um monte de retornos de chamada diferentes dentro do mesmo encadeamento e, assim que a função quiser fazer algo assíncrono, envie essa solicitação assíncrona e dê ao processador tempo para outra função na fila (se você estiver interessado em saber como isso funciona, orgulhosamente chamado Loop de Evento) por baixo do capô, recomendo a leitura desta série de artigos ). Se você pensar em como o NodeJS entende qual retorno de chamada chamar quando, você pode assumir que cada um deles deve corresponder a algum ID. Além disso, o NodeJS ainda possui uma API que fornece acesso a esses IDs. Nós vamos usá-lo.
Antigamente, quando os mamutes eram extintos, mas as pessoas ainda não conheciam os benefícios do esgoto central (NodeJS v0.11.11), tínhamos o addAsyncListener . Com base nisso, o Forrest Norvell criou a primeira implementação do armazenamento local de continuação ou CLS . Mas não falaremos sobre como funcionou na época, pois essa API (estou falando de addAsyncLustener) exigiu uma vida longa. Ele já morreu no NodeJS v0.12.
Antes do NodeJS 8, não havia uma maneira oficial de acompanhar a fila de eventos assíncronos. E finalmente, na versão 8, os desenvolvedores do NodeJS restauraram a justiça e nos apresentaram a API async_hooks . Se você quiser saber mais sobre o async_hooks, recomendo que você leia este artigo . Com base em async_hooks, foi feita a refatoração da implementação anterior do CLS. A biblioteca é chamada cls-hooked .
CLS sob o capô
Em termos gerais, o esquema de operação do CLS pode ser representado da seguinte maneira:
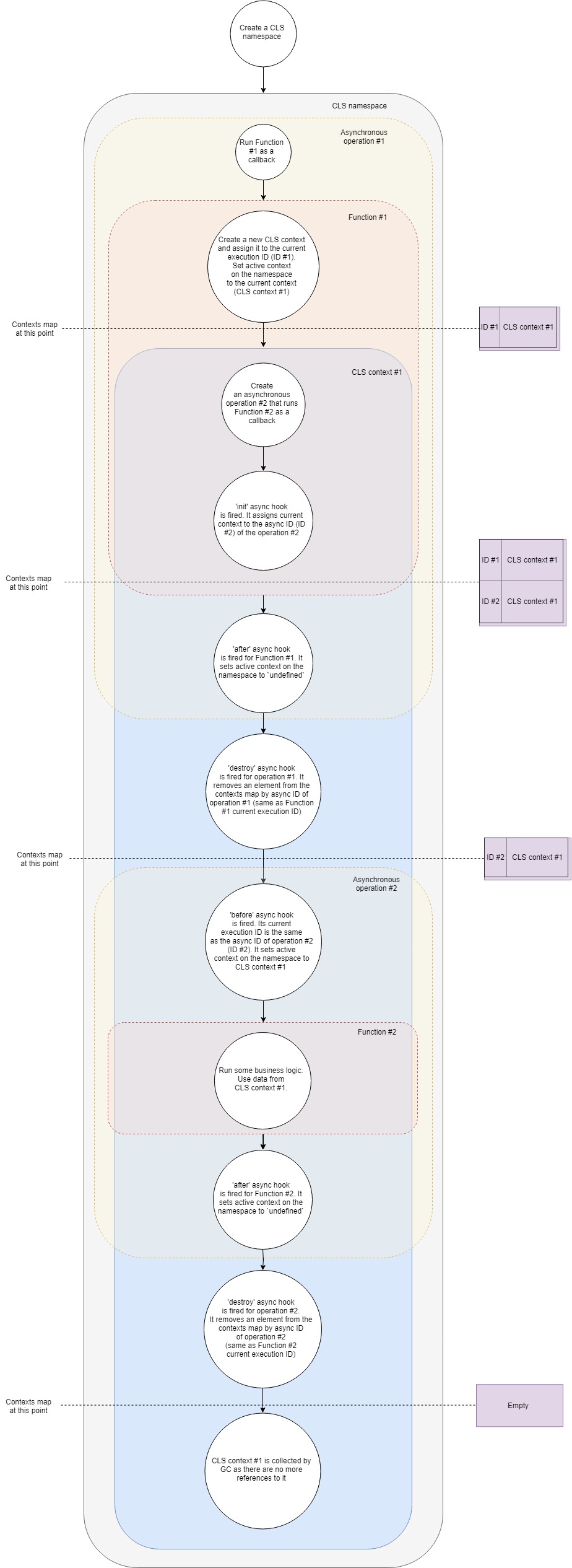
Vamos dar um pouco mais em detalhes:
- Suponha que tenhamos um servidor Web Express típico. Primeiro, crie um novo espaço para nome do CLS. Uma vez e durante toda a vida útil do aplicativo.
- Em segundo lugar, criaremos o middleware, que criará nosso próprio contexto CLS para cada solicitação.
- Quando chega uma nova solicitação, esse middleware (Função 1) é chamado.
- Nesta função, crie um novo contexto CLS (como uma opção, você pode usar Namespace.run ). No Namespace.run, passamos uma função que será executada no escopo do nosso contexto.
- O CLS adiciona um contexto recém-criado ao Map com contextos com a chave de ID de execução atual .
- Cada namespace do CLS possui uma propriedade
active . O CLS atribui a essa propriedade uma referência ao nosso contexto. - Em um escopo de contexto, fazemos algum tipo de consulta assíncrona, digamos, no banco de dados. Passamos o retorno de chamada para o driver do banco de dados, que será chamado quando a solicitação for concluída.
- O gancho init assíncrono é acionado . Ele adiciona o contexto atual ao Mapa com contextos por ID assíncrono (ID da nova operação assíncrona).
- Porque nossa função não possui mais instruções adicionais, completa a execução.
- Um gancho posterior assíncrono funciona para ela. Ele atribui a propriedade
active ao espaço para nome undefined (na verdade, nem sempre, porque podemos ter vários contextos aninhados, mas, no caso mais simples, é). - O gancho assíncrono de destruição é acionado para a nossa primeira operação assíncrona. Ele remove o contexto do Mapa com contextos pelo ID assíncrono desta operação (é o mesmo que o ID de execução atual do primeiro retorno de chamada).
- A consulta no banco de dados é concluída e o segundo retorno de chamada é chamado.
- Gancho assíncrono antes . Seu ID de execução atual é igual ao ID assíncrono da segunda operação (consulta ao banco de dados). A propriedade
active espaço para nome recebe o contexto encontrado no Mapa com contextos pelo ID de execução atual. Este é o contexto que criamos antes. - Agora o segundo retorno de chamada é executado. Algum tipo de lógica de negócios está funcionando, os demônios estão dançando, a vodka está derramando. Dentro disso, podemos obter qualquer valor do contexto por chave . O CLS tentará encontrar a chave fornecida no contexto atual ou retornar
undefined . - O gancho posterior assíncrono para esse retorno de chamada é acionado quando é concluído. Ele define a propriedade
active do espaço para nome como undefined . - O gancho assíncrono de destruição é acionado para esta operação. Ele remove o contexto do Mapa com contextos pelo ID assíncrono desta operação (é o mesmo que o ID de execução atual do segundo retorno de chamada).
- O coletor de lixo (GC) libera memória associada ao objeto de contexto, porque em nosso aplicativo, não há mais links para ele.
Esta é uma visão simplificada do que está acontecendo sob o capô, mas abrange as principais fases e etapas. Se você deseja aprofundar um pouco mais, recomendo que você se familiarize com os tipos . Existem apenas 500 linhas de código.
Criar ID de rastreio
Então, tendo lidado com o CLS, tentaremos usar isso para o benefício da humanidade. Vamos criar middleware, que para cada solicitação cria seu próprio contexto CLS, cria um ID de rastreamento aleatório e o adiciona ao contexto usando a chave traceID . Então, dentro do grande número de nossos controladores e serviços, obtemos esse ID de rastreamento.
Para o express, um middleware semelhante pode ser assim:
const cls = require('cls-hooked') const uuidv4 = require('uuid/v4') const clsNamespace = cls.createNamespace('app') const clsMiddleware = (req, res, next) => {
E em nosso controlador ou serviço, podemos obter esse traceID em apenas uma linha de código:
const controller = (req, res, next) => { const traceID = clsNamespace.get('traceID') }
É verdade que, sem adicionar esse ID de rastreamento aos logs, ele se beneficia dele, como um soprador de neve no verão.
Vamos escrever um simples formatador winston que adicionará o ID de rastreamento automaticamente.
const { createLogger, format, transports } = require('winston') const addTraceId = printf((info) => { let message = info.message const traceID = clsNamespace.get('taceID') if (traceID) { message = `[TraceID: ${traceID}]: ${message}` } return message }) const logger = createLogger({ format: addTraceId, transports: [new transports.Console()], })
E se todos os registradores suportassem o formatador personalizado na forma de funções (muitos deles têm motivos para não fazer isso), provavelmente este artigo não teria sido. Então, como você pode adicionar um ID de rastreamento aos logs do pino adorado?
Apelamos ao Proxy para fazer amigos QUALQUER logger e CLS
Algumas palavras sobre o próprio Proxy: isso é algo que envolve nosso objeto original e nos permite redefinir seu comportamento em determinadas situações. Em uma lista limitada estritamente definida de situações (na ciência são chamadas de traps ). Você pode encontrar a lista completa aqui , estamos interessados apenas em obter uma armadilha. Isso nos dá a oportunidade de substituir o valor de retorno ao acessar a propriedade do objeto, ou seja, se pegarmos o objeto const a = { prop: 1 } e o envolvermos em Proxy, com a ajuda do trap get , podemos retornar tudo o que gostamos ao acessar a.prop .
No caso de pino idéia é a seguinte: criamos um ID de rastreamento aleatório para cada solicitação, criamos uma instância filho de pino na qual passamos esse ID de rastreamento e colocamos essa instância filho no CLS. Em seguida, agrupamos nosso criador de logs de origem no Proxy, que usará a mesma instância filho para fazer logon se houver um contexto ativo e houver um criador de filhos, ou usar o criador de logs original.
Nesse caso, o proxy terá a seguinte aparência:
const pino = require('pino') const logger = pino() const loggerCls = new Proxy(logger, { get(target, property, receiver) {
Nosso middleware ficará assim:
const cls = require('cls-hooked') const uuidv4 = require('uuid/v4') const clsMiddleware = (req, res, next) => {
E podemos usar o logger como este:
const controller = (req, res, next) => { loggerCls.info('Long live rocknroll!')
Com base na idéia acima, uma pequena biblioteca cls-proxify foi criada. Ela trabalha fora da caixa com express , koa e fastify . Além de criar interceptação para get , ele cria outras interceptações para dar ao desenvolvedor mais liberdade. Por esse motivo, podemos usar o Proxy para agrupar funções, classes e muito mais. Há uma demonstração ao vivo sobre como integrar pino e fastify, pino e express .
Espero que você não tenha perdido tempo em vão, e o artigo tenha sido pelo menos um pouco útil para você. Por favor, chute e critique. Vamos aprender a codificar melhor juntos.