Interface
No
primeiro artigo , mencionamos que um método de acesso deve fornecer informações sobre si mesmo. Vamos examinar a estrutura da interface do método de acesso.
Propriedades
Todas as propriedades dos métodos de acesso são armazenadas na tabela "pg_am" ("am" significa método de acesso). Também podemos obter uma lista de métodos disponíveis nesta mesma tabela:
postgres=# select amname from pg_am;
amname -------- btree hash gist gin spgist brin (6 rows)
Embora a verificação seqüencial possa ser legitimamente referida aos métodos de acesso, ela não está nesta lista por razões históricas.
Nas versões 9.5 e inferiores do PostgreSQL, cada propriedade era representada com um campo separado da tabela "pg_am". A partir da versão 9.6, as propriedades são consultadas com funções especiais e são separadas em várias camadas:
- Propriedades do método de acesso - "pg_indexam_has_property"
- Propriedades de um índice específico - "pg_index_has_property"
- Propriedades de colunas individuais do índice - "pg_index_column_has_property"
A camada do método de acesso e a camada de índice são separadas de olho no futuro: a partir de agora, todos os índices baseados em um método de acesso sempre terão as mesmas propriedades.
As quatro propriedades a seguir são as do método de acesso (por um exemplo de "btree"):
postgres=# select a.amname, p.name, pg_indexam_has_property(a.oid,p.name) from pg_am a, unnest(array['can_order','can_unique','can_multi_col','can_exclude']) p(name) where a.amname = 'btree' order by a.amname;
amname | name | pg_indexam_has_property --------+---------------+------------------------- btree | can_order | t btree | can_unique | t btree | can_multi_col | t btree | can_exclude | t (4 rows)
- can_order.
O método de acesso nos permite especificar a ordem de classificação dos valores quando um índice é criado (aplicável apenas a "btree" até o momento). - can_unique
Suporte da restrição exclusiva e da chave primária (aplicável apenas a "btree"). - can_multi_col.
Um índice pode ser criado em várias colunas. - can_exclude
Suporte da restrição de exclusão EXCLUDE.
As seguintes propriedades pertencem a um índice (vamos considerar uma existente, por exemplo):
postgres=# select p.name, pg_index_has_property('t_a_idx'::regclass,p.name) from unnest(array[ 'clusterable','index_scan','bitmap_scan','backward_scan' ]) p(name);
name | pg_index_has_property ---------------+----------------------- clusterable | t index_scan | t bitmap_scan | t backward_scan | t (4 rows)
- agrupável.
Possibilidade de reordenar linhas de acordo com o índice (armazenamento em cluster com o mesmo nome comando CLUSTER). - index_scan.
Suporte de varredura de índice. Embora essa propriedade possa parecer estranha, nem todos os índices podem retornar TIDs um por um - alguns retornam resultados de uma só vez e suportam apenas a verificação de bitmap. - bitmap_scan.
Suporte à verificação de bitmap. - backward_scan.
O resultado pode ser retornado na ordem inversa da especificada ao criar o índice.
Finalmente, a seguir estão as propriedades da coluna: postgres=# select p.name, pg_index_column_has_property('t_a_idx'::regclass,1,p.name) from unnest(array[ 'asc','desc','nulls_first','nulls_last','orderable','distance_orderable', 'returnable','search_array','search_nulls' ]) p(name);
name | pg_index_column_has_property --------------------+------------------------------ asc | t desc | f nulls_first | f nulls_last | t orderable | t distance_orderable | f returnable | t search_array | t search_nulls | t (9 rows)
- asc, desc, nulls_first, nulls_last, ordenável.
Essas propriedades estão relacionadas à ordem dos valores (discutiremos sobre eles quando chegarmos a uma descrição dos índices "btree"). - distance_orderable.
O resultado pode ser retornado na ordem de classificação determinada pela operação (aplicável apenas aos índices GiST e RUM até o momento). - retornável
Possibilidade de usar o índice sem acessar a tabela, ou seja, suporte a verificações apenas de índice. - matriz de pesquisa.
Suporte à pesquisa de vários valores com a expressão " campo indexado IN ( lista_de_constantes )", que é igual a " campo indexado = ANY ( matriz_de_constantes )". - search_nulls.
Possibilidade de pesquisar pelas condições IS NULL e NOT NULL.
Já discutimos algumas das propriedades em detalhes. Algumas propriedades são específicas para certos métodos de acesso. Discutiremos essas propriedades ao considerar esses métodos específicos.
Classes de operadores e famílias
Além das propriedades de um método de acesso exposto pela interface descrita, são necessárias informações para saber quais tipos de dados e quais operadores o método de acesso aceita. Para esse fim, o PostgreSQL apresenta
os conceitos de
classe e
família de operadores .
Uma classe de operadores contém um conjunto mínimo de operadores (e talvez funções auxiliares) para um índice manipular um determinado tipo de dados.
Uma classe de operadores está incluída em algumas famílias de operadores. Além disso, uma família de operadores comum pode conter várias classes de operadores se elas tiverem a mesma semântica. Por exemplo, a família "integer_ops" inclui as classes "int8_ops", "int4_ops" e "int2_ops" para os tipos "bigint", "integer" e "smallint", com tamanhos diferentes, mas com o mesmo significado:
postgres=# select opfname, opcname, opcintype::regtype from pg_opclass opc, pg_opfamily opf where opf.opfname = 'integer_ops' and opc.opcfamily = opf.oid and opf.opfmethod = ( select oid from pg_am where amname = 'btree' );
opfname | opcname | opcintype -------------+----------+----------- integer_ops | int2_ops | smallint integer_ops | int4_ops | integer integer_ops | int8_ops | bigint (3 rows)
Outro exemplo: a família "datetime_ops" inclui classes de operadores para manipular datas (com e sem hora):
postgres=# select opfname, opcname, opcintype::regtype from pg_opclass opc, pg_opfamily opf where opf.opfname = 'datetime_ops' and opc.opcfamily = opf.oid and opf.opfmethod = ( select oid from pg_am where amname = 'btree' );
opfname | opcname | opcintype --------------+-----------------+----------------------------- datetime_ops | date_ops | date datetime_ops | timestamptz_ops | timestamp with time zone datetime_ops | timestamp_ops | timestamp without time zone (3 rows)
Uma família de operadores também pode incluir operadores adicionais para comparar valores de diferentes tipos. O agrupamento em famílias permite que o planejador use um índice para predicados com valores de tipos diferentes. Uma família também pode conter outras funções auxiliares.
Na maioria dos casos, não precisamos saber nada sobre famílias e classes de operadores. Normalmente, apenas criamos um índice, usando uma certa classe de operadores por padrão.
No entanto, podemos especificar explicitamente a classe do operador. Este é um exemplo simples de quando a especificação explícita é necessária: em um banco de dados com o agrupamento diferente de C, um índice regular não suporta a operação LIKE:
postgres=# show lc_collate;
lc_collate ------------- en_US.UTF-8 (1 row)
postgres=# explain (costs off) select * from t where b like 'A%';
QUERY PLAN ----------------------------- Seq Scan on t Filter: (b ~~ 'A%'::text) (2 rows)
Podemos superar essa limitação criando um índice com a classe de operador "text_pattern_ops" (observe como a condição no plano mudou):
postgres=# create index on t(b text_pattern_ops); postgres=# explain (costs off) select * from t where b like 'A%';
QUERY PLAN ---------------------------------------------------------------- Bitmap Heap Scan on t Filter: (b ~~ 'A%'::text) -> Bitmap Index Scan on t_b_idx1 Index Cond: ((b ~>=~ 'A'::text) AND (b ~<~ 'B'::text)) (4 rows)
Catálogo do sistema
Na conclusão deste artigo, fornecemos um diagrama simplificado de tabelas no catálogo do sistema que estão diretamente relacionadas às classes e famílias de operadores.
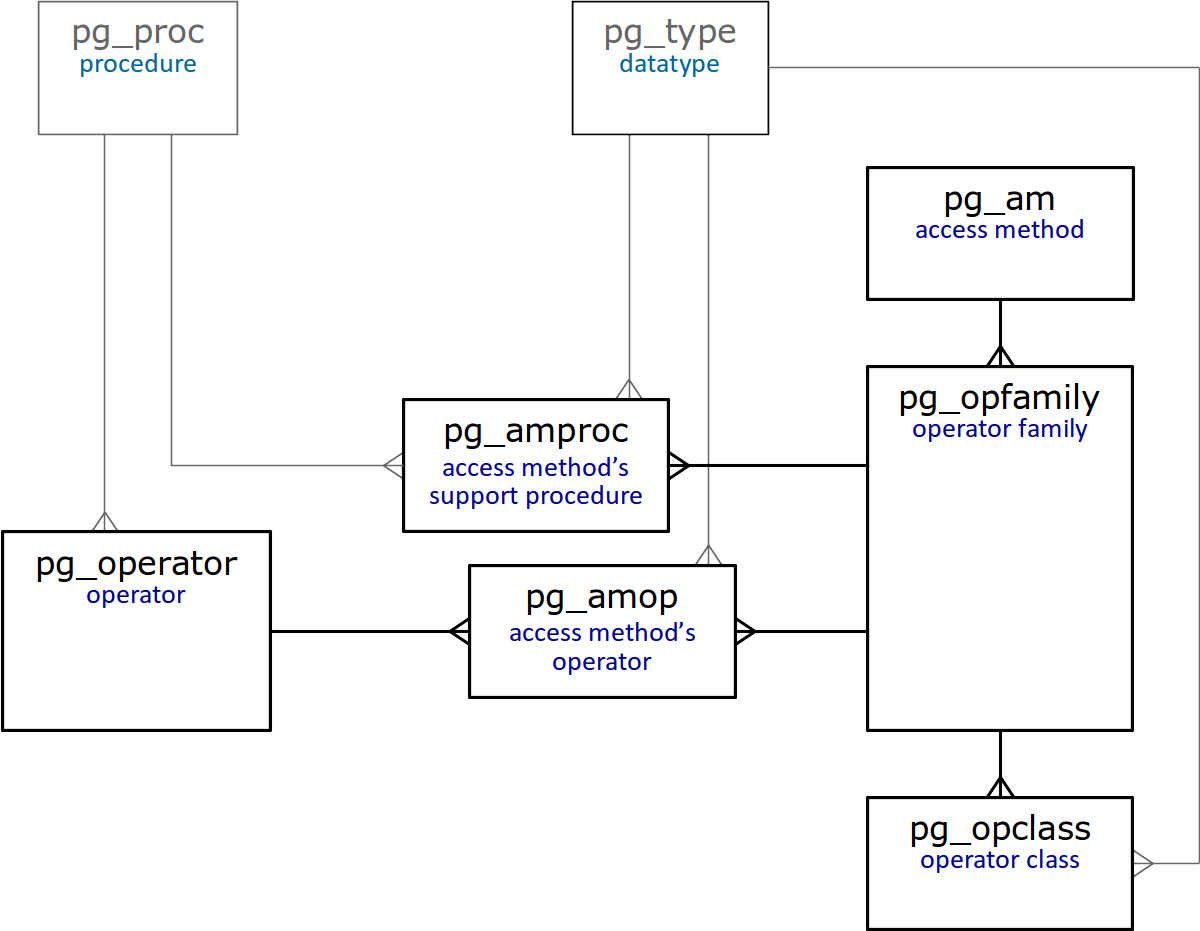
Escusado será dizer que todas essas tabelas
são descritas em detalhes .
O catálogo do sistema nos permite encontrar respostas para várias perguntas sem consultar a documentação. Por exemplo, quais tipos de dados um determinado método de acesso pode manipular?
postgres=# select opcname, opcintype::regtype from pg_opclass where opcmethod = (select oid from pg_am where amname = 'btree') order by opcintype::regtype::text;
opcname | opcintype ---------------------+----------------------------- abstime_ops | abstime array_ops | anyarray enum_ops | anyenum ...
Quais operadores uma classe de operadores contém (e, portanto, o acesso ao índice pode ser usado para uma condição que inclui esse operador)?
postgres=# select amop.amopopr::regoperator from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'array_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'btree' and amop.amoplefttype = opc.opcintype;
amopopr ----------------------- <(anyarray,anyarray) <=(anyarray,anyarray) =(anyarray,anyarray) >=(anyarray,anyarray) >(anyarray,anyarray) (5 rows)
Continue lendo .