Quando os participantes do
HighLoad ++ chegaram ao relatório de
Alexander Krasheninnikov , eles esperavam ouvir sobre o processamento de 1.600.000 eventos por segundo. As expectativas não se tornaram realidade ... Porque durante a preparação para o desempenho, esse número chegou a
1.800.000 - portanto, no HighLoad ++, a realidade excede as expectativas.
Há 3 anos, Alexander contou como eles criaram um sistema de processamento de eventos escalonável quase em tempo real no Badoo. Desde então, ele evoluiu, os volumes cresceram no processo, foi necessário resolver os problemas de escala e tolerância a falhas e, em determinado momento, foram necessárias medidas radicais - uma
mudança na pilha tecnológica .

Com a descriptografia, você aprenderá como no Badoo você substituiu o pacote Spark + Hadoop pelo ClickHouse,
salvou o hardware 3 vezes e aumentou a carga 6 vezes , por que e como meios para coletar estatísticas no projeto e o que fazer com esses dados.
Sobre o palestrante: Alexander Krasheninnikov (
alexkrash ) - Diretor de engenharia de dados do Badoo. Ele está envolvido na infraestrutura de BI, dimensionando cargas de trabalho e gerencia as equipes que constroem a infraestrutura de processamento de dados. Ele ama tudo o que é distribuído: Hadoop, Spark, ClickHouse. Estou certo de que sistemas distribuídos legais podem ser preparados a partir do OpenSource.
Coleta de estatísticas
Se não temos dados, somos cegos e não podemos gerenciar nosso projeto. É por isso que precisamos de estatísticas - para
monitorar a viabilidade do projeto. Nós, como engenheiros, devemos nos esforçar para melhorar nossos produtos e, se
você quiser melhorar, medi-lo. Este é o meu lema no trabalho. Primeiro de tudo, nosso objetivo são os benefícios comerciais. As estatísticas
fornecem respostas para perguntas de negócios . Métricas técnicas são métricas técnicas, mas os negócios também estão interessados em indicadores e também precisam ser considerados.
Ciclo de vida das estatísticas
Eu defino o ciclo de vida das estatísticas em 4 pontos, cada um dos quais discutiremos separadamente.
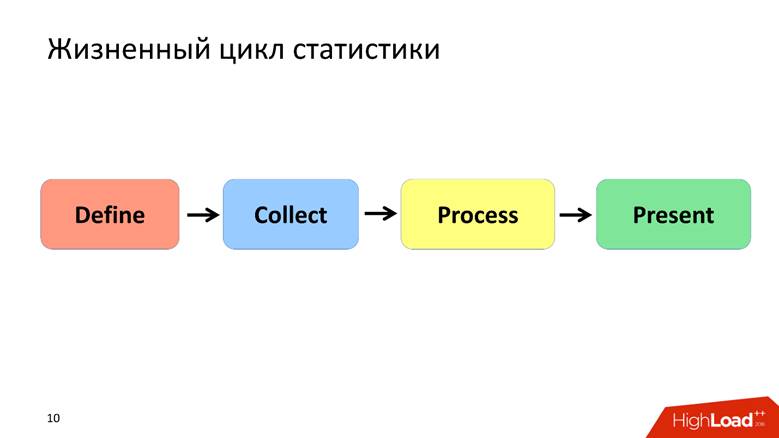
Definir Fase - Formalização
No aplicativo, coletamos várias métricas. Primeiro de tudo, essas são
métricas de negócios . Se você possui um serviço de fotos, por exemplo, está se perguntando quantas fotos são carregadas por dia, por hora e por segundo. As seguintes métricas são
"semi-técnicas" : capacidade de resposta de um aplicativo ou site móvel, operação da API, velocidade com que um usuário interage com um site, instalação de aplicativo, UX.
Rastrear o comportamento do usuário é a terceira métrica importante. São sistemas como o Google Analytics e o Yandex.Metrics. Temos nosso próprio sistema de rastreamento legal, no qual investimos muito.
No processo de trabalhar com estatísticas, muitos usuários estão envolvidos - são desenvolvedores e análises de negócios. É importante que todos falem o mesmo idioma, então você precisa concordar.
É possível negociar verbalmente, mas é muito melhor quando isso ocorre formalmente - em uma estrutura clara de eventos.
A formalização da estrutura dos eventos de negócios é quando o desenvolvedor diz quantos registros temos, o analista entende que ele recebeu informações não apenas sobre o número total de registros, mas também por país, gênero e outros parâmetros. E todas essas informações são formalizadas e são de
domínio público para todos os usuários da empresa . O evento tem uma estrutura digitada e uma descrição formal. Por exemplo, armazenamos essas informações no formato
Buffers de Protocolo .
Descrição do evento "Registration":
enum Gender { FEMALE = 1; MALE = 2; } message Registration { required int32 userid =1; required Gender usergender = 2; required int32 time =3; required int32 countryid =4; }
O evento de registro contém informações sobre o
usuário, campo, hora do evento e o
país de registro do usuário. Essas informações estão disponíveis para analistas e, no futuro, a empresa entende o que coletamos.
Por que preciso de uma descrição formal?
Uma descrição formal é
uniformidade para desenvolvedores, analistas e o departamento de produtos. Então essas informações permeiam a descrição da lógica de negócios do aplicativo. Por exemplo, temos um sistema interno para descrever os processos de negócios e, em uma tela, temos um novo recurso.
No
documento de requisitos do
produto, há uma seção com as instruções de que, quando o usuário interage com o aplicativo dessa maneira, devemos enviar um evento com exatamente os mesmos parâmetros. Posteriormente, poderemos validar como nossos recursos funcionam e se os medimos corretamente. Uma descrição formal nos permite entender melhor como salvar esses dados em um banco de dados: NoSQL, SQL ou outros. Temos
um esquema de dados , e isso é legal.
Em alguns sistemas analíticos fornecidos como serviço, existem apenas 10 a 15 eventos no armazenamento secreto. Em nosso país, esse número cresceu mais de 1000 e não vai parar -
é impossível viver sem um único registro .
Definir Resumo da Fase
Decidimos que as
estatísticas - isso é importante e
descrevemos uma determinada área de assunto - isso é bom, você pode viver.
Fase de coleta - coleta de dados
Decidimos construir o sistema para que, quando ocorrer um evento comercial - registro, envio de uma mensagem, como - ao mesmo tempo em que salvar essas informações, enviaremos separadamente um determinado evento estatístico.
No código, as estatísticas são enviadas simultaneamente com o evento de negócios.
É processado de forma completamente independente dos armazenamentos de dados nos quais o aplicativo é executado, porque o
fluxo de dados passa por um pipeline de processamento separado.Descrição via EDL:
enum Gender { FEMALE = 1; MALE = 2; } message Registration { required int32 user_id =1; required Gender user_gender = 2; required int32 time =3; required int32 country_id =4; }
Temos uma descrição do evento de registro. Uma API é gerada automaticamente, acessível aos desenvolvedores a partir do código, que em 4 linhas permite enviar estatísticas.
API baseada em EDL:
\EDL\Event\Regist ration::create() ->setUserId(100500) ->setGender(Gender: :MALE) ->setTime(time()) ->send();
Entrega de Eventos
Este é o nosso sistema externo. Fazemos isso porque temos serviços incríveis que fornecem uma API para trabalhar com dados de fotos, sobre outra coisa. Todos eles armazenam dados em bancos de dados novos e atualizados, como Aerospike e CockroachDB.
Quando você precisa criar algum tipo de relatório, não precisa lutar: "Gente, quanto disso você tem e quanto?" - Todos os dados são enviados em um fluxo separado. Transportador de processamento - sistema externo. No contexto do aplicativo, desatamos todos os dados do repositório de lógica de negócios e os enviamos para um pipeline separado.
A fase Coletar assume a disponibilidade dos servidores de aplicativos. Nós temos esse PHP.
Transporte
Este é um subsistema que nos permite enviar para outro pipeline o que fizemos no contexto do aplicativo. O transporte é selecionado apenas de seus requisitos, dependendo da situação no projeto.
O transporte tem características, e o primeiro são
garantias de entrega. Características do transporte: pelo menos uma vez, exatamente uma vez, você escolhe estatísticas para suas tarefas, com base na importância desses dados. Por exemplo, para sistemas de cobrança, é inaceitável que as estatísticas mostrem mais transações do que existem - isso é dinheiro, não é possível.
O segundo parâmetro é
ligações para linguagens de programação. De alguma forma, precisamos interagir com o transporte, para que ele seja selecionado de acordo com o idioma em que o projeto foi escrito.
O terceiro parâmetro é
escalabilidade. Como estamos falando de milhões de eventos por segundo, seria bom ter em mente a escalabilidade futura.
Existem muitas opções de transporte: aplicativos RDBMS, Flume, Kafka ou LSD. Usamos
LSD - esta é a nossa maneira especial.
Daemon de transmissão ao vivo
O LSD não tem nada a ver com substâncias proibidas. Este é um
daemon de transmissão animado e muito rápido que não fornece nenhum agente para gravar nele. Podemos ajustá-lo, temos
integração com outros sistemas : HDFS, Kafka - podemos reorganizar os dados enviados. O LSD não possui uma chamada de rede no INSERT e você pode controlar a topologia de rede.
Mais importante, este é
o OpenSource do Badoo - não há razão para não confiar neste software.
Se fosse um demônio perfeito, então, em vez de Kafka, discutiríamos o LSD em todas as conferências, mas todo LSD tem uma mosca na pomada. Temos nossas próprias limitações com as quais nos sentimos confortáveis:
não temos suporte à replicação no LSD e ele tem
pelo menos uma garantia de entrega. Além disso, para transações com dinheiro, esse não é o transporte mais adequado, mas você geralmente precisa se comunicar com dinheiro exclusivamente por meio de bancos de dados "ácidos" - suportando o
ACID .
Resumo da fase de coleta
Com base nos resultados da série anterior, recebemos uma
descrição formal dos dados, geramos uma
API excelente e conveniente
para os expedidores de eventos e descobrimos como
transferir esses dados
do contexto do aplicativo para um pipeline separado . Já não é ruim, e estamos nos aproximando da próxima fase.
Processo de fase - processamento de dados
Coletamos dados de registros, upload de fotos, pesquisas - o que fazer com tudo isso? A partir desses dados, queremos obter
gráficos com um longo histórico e
dados brutos . Os gráficos compreendem tudo - você não precisa ser um desenvolvedor para entender pela curva que a receita da empresa está crescendo. Usamos dados brutos para relatórios on-line e ad-hoc. Para casos mais complexos, nossos analistas desejam realizar consultas analíticas sobre esses dados. Tanto isso quanto essa funcionalidade são necessárias para nós.
Gráficos
Os gráficos são apresentados de várias formas.
Ou, por exemplo, um gráfico com um histórico que mostra dados por 10 anos.
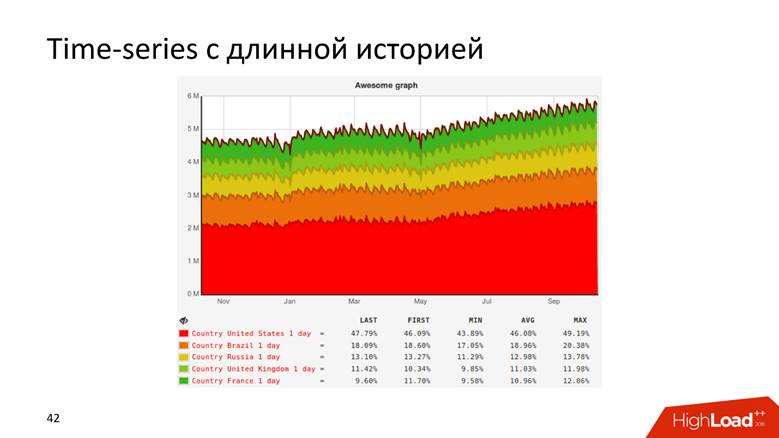
Os gráficos são assim mesmo.
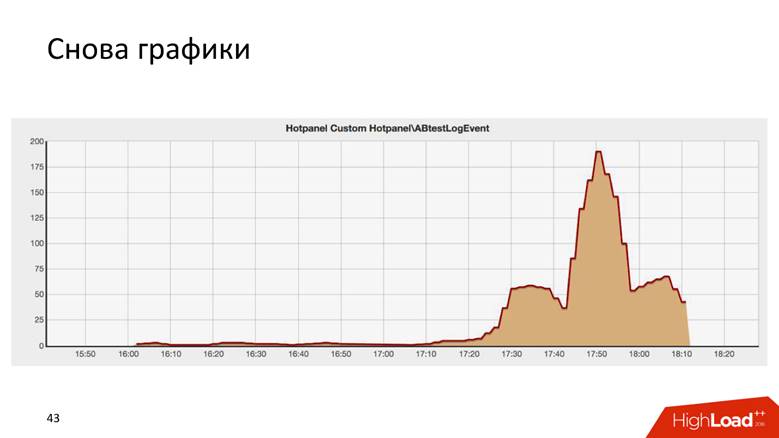
Este é o resultado de algum teste AB, e é surpreendentemente semelhante ao edifício Chrysler em Nova York.
Há duas maneiras de desenhar um gráfico: uma
consulta para dados brutos e uma
série temporal . Ambas as abordagens têm desvantagens e vantagens, sobre as quais não nos aprofundaremos em detalhes. Utilizamos uma
abordagem híbrida : mantemos uma pequena distância dos dados brutos para relatórios operacionais e séries temporais para armazenamento a longo prazo. O segundo é calculado a partir do primeiro.
Como crescemos para 1,8 milhão de eventos por segundo
É uma longa história - milhões de RPS não acontecem em um dia. O Badoo é uma empresa com uma década de história, e podemos dizer que o sistema de processamento de dados cresceu com a empresa.
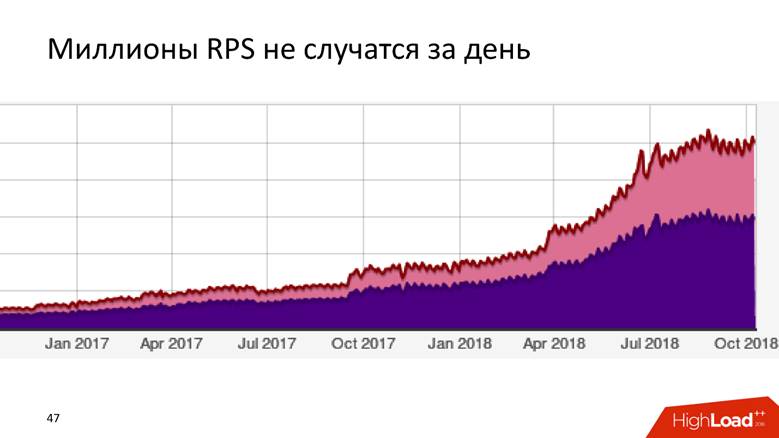
No começo não tínhamos nada. Começamos a coletar dados - foram
5.000 eventos por segundo. Um host MySQL e nada mais! Qualquer DBMS relacional irá lidar com essa tarefa, e será confortável com ela: você terá transacionalidade - coloque os dados, receberá solicitações - tudo funciona bem e bem. Então nós vivemos por um tempo.
Em algum momento, o sharding funcional aconteceu: dados de registro - aqui e sobre fotos - lá. Então, vivemos até
200.000 eventos por segundo e começamos a usar várias abordagens combinadas: para armazenar dados não brutos, mas
agregados , mas até agora no banco de dados relacional. Armazenamos contadores, mas a essência da maioria dos bancos de dados relacionais é tal que será impossível executar uma
consulta DISTINCT nesses dados - o modelo algébrico de contadores não permite calcular o DISTINCT.
Nós no Badoo temos o lema
"Força imparável" . Não íamos parar e crescer mais. No momento em que ultrapassamos o limite de
200.000 eventos por segundo , decidimos criar uma descrição formal, sobre a qual falei acima. Antes disso, havia um caos e agora temos um registro estruturado de eventos: começamos a dimensionar o sistema,
conectamos o Hadoop , todos os dados foram inseridos nas
tabelas do Hive.O Hadoop é um enorme pacote de software, sistema de arquivos. Para computação distribuída, o Hadoop diz: "Coloque os dados aqui, permitirei que você execute consultas analíticas sobre eles". Então fizemos - escrevemos um
cálculo regular de todos os gráficos - acabou bem. Mas os gráficos são valiosos quando são atualizados rapidamente - uma vez por dia, assistir a uma atualização dos gráficos não é tão divertido. Se lançássemos algo que levasse a um erro fatal na produção, gostaríamos de ver o gráfico cair imediatamente, e não todos os dias. Portanto, todo o sistema começou a se degradar após algum tempo. No entanto, percebemos que, nesta fase, você pode manter a pilha de tecnologia selecionada.
Para nós, o Java era novo, gostávamos e entendíamos o que poderia ser feito de maneira diferente.
No estágio de 400.000 a
800.000 eventos por segundo , substituímos o Hadoop em sua forma mais pura e o Hive, como executor de consultas analíticas, com
Spark Streaming , escreveu um
mapa genérico / redução e cálculo incremental de métricas. Há 3 anos,
contei como fizemos. Pareceu-nos que Spark viveria para sempre, mas a vida decretou o contrário - nos deparamos com as limitações do Hadoop. Talvez se tivéssemos outras condições, continuaríamos a viver com o Hadoop.
Outro problema, além de calcular gráficos no Hadoop, foram as incríveis consultas SQL de quatro andares, conduzidas por analistas, e os gráficos não foram atualizados rapidamente. O fato é que há um trabalho bastante complicado no processamento de dados operacionais, para que seja em tempo real, rápido e frio.
O Badoo é servido por dois data centers localizados nos dois lados do Oceano Atlântico - na Europa e na América do Norte. Para criar um relatório unificado, você precisa enviar dados da América para a Europa. É no data center europeu que mantemos todas as estatísticas estatísticas, porque há mais poder de computação.
Uma ida e
volta entre os data centers de cerca de
200 ms - a rede é bastante delicada - fazer uma solicitação para outro controlador de domínio não é a mesma coisa que ir para o próximo rack.
Quando começamos a formalizar eventos e desenvolvedores, e os gerentes de produto se envolveram, todos gostaram de tudo - houve apenas um
crescimento explosivo de eventos . No momento, era hora de comprar ferro no cluster, mas na verdade não queríamos fazer isso.
Quando passamos o pico de
800.000 eventos por segundo , descobrimos o que o Yandex havia carregado no OpenSource
ClickHouse e decidimos experimentá-lo.
Eles encheram um monte de cones enquanto tentavam fazer alguma coisa e, como resultado, quando tudo funcionou, fizeram uma pequena recepção sobre o primeiro milhão de eventos. Provavelmente, o ClickHouse poderia ter terminado o relatório.
Basta pegar o ClickHouse e viver com ele.
Mas isso não é interessante, por isso continuaremos falando sobre processamento de dados.
Clickhouse
O ClickHouse é um hype dos últimos dois anos e não precisa ser apresentado: somente no HighLoad ++ em 2018 lembro-me de
cinco relatórios sobre o assunto, além de seminários e reuniões.
Essa ferramenta foi projetada para resolver exatamente as tarefas que definimos para nós mesmos. Há
atualizações e chips em
tempo real que recebemos ao mesmo tempo do Hadoop: replicação, fragmentação. Não havia razão para não experimentar o ClickHouse, porque eles entenderam que com a implementação no Hadoop já tínhamos quebrado o fundo. A ferramenta é legal e a documentação geralmente é de fogo - eu mesmo escrevi lá, gosto muito de tudo e tudo é ótimo. Mas tivemos que resolver uma série de problemas.
Como mudar todo o fluxo de eventos no ClickHouse? Como combinar dados de dois data centers? Pelo fato de termos procurado os administradores e dito: “Gente, vamos instalar o ClickHouse”, eles não tornarão a rede duas vezes mais espessa e o atraso será metade do mesmo. Não, a rede ainda é tão pequena e pequena quanto o primeiro salário.
Como armazenar os resultados ? No Hadoop, entendemos como desenhar gráficos - mas como fazê-lo na mágica ClickHouse? Varinha mágica não está incluída.
Como entregar resultados ao armazenamento de séries temporais?
Como meu professor do instituto disse, considere três esquemas de dados: estratégico, lógico e físico.
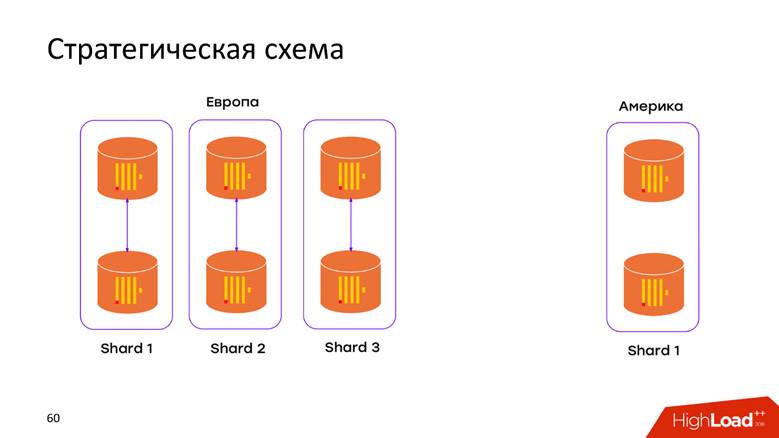
Esquema de armazenamento estratégico
Temos
2 data centers . Aprendemos que o ClickHouse não sabe nada sobre DCs e apenas instalamos o cluster em cada DC. Agora, os
dados não se movem através do cabo Atlântico - todos os dados que ocorreram no controlador de domínio são armazenados localmente em seu cluster. Quando queremos fazer uma solicitação sobre os dados combinados, por exemplo, para descobrir quantos registros existem nos dois CDs, o ClickHouse nos oferece essa oportunidade. Baixa latência e disponibilidade para a solicitação - apenas uma obra-prima!
Esquema de armazenamento físico
Novamente, perguntas: como nossos dados se enquadram no modelo relacional ClickHouse, o que deve ser feito para não perder a replicação e o sharding? Tudo está descrito extensivamente na
documentação do ClickHouse e, se você tiver mais de um servidor, encontrará este artigo. Portanto, não vamos nos aprofundar no que está no manual: replicações, sharding e consultas a todos os dados sobre shards.
Lógica de armazenamento
O diagrama lógico é o mais interessante. Em um pipeline, processamos eventos heterogêneos. Isso significa que temos um
fluxo de eventos heterogêneos : registro, voz, upload de fotos, métricas técnicas, rastreamento do comportamento do usuário - todos esses eventos têm
atributos completamente
diferentes . Por exemplo, olhei para a tela em um telefone celular - preciso de um ID de tela, votei em alguém - você precisa entender se o voto foi a favor ou contra. Todos esses eventos têm atributos diferentes, gráficos diferentes são desenhados neles, mas tudo isso deve ser processado em um único pipeline. Como colocá-lo no modelo ClickHouse?
Abordagem nº 1 - por tabela de eventos. Nesta primeira abordagem, extrapolamos a experiência adquirida com o MySQL - criamos um
tablet para cada evento no ClickHouse. Parece bastante lógico, mas nos deparamos com várias dificuldades.
Não temos restrições de que o evento altere sua estrutura quando a compilação de hoje for lançada. Esse patch pode ser feito por qualquer desenvolvedor. O esquema é geralmente mutável em todas as direções. O único
campo obrigatório é o
evento de registro de data e
hora e qual foi o evento. Tudo o resto muda rapidamente e, portanto, essas placas precisam ser modificadas. O ClickHouse tem a capacidade de executar
ALTER em um cluster , mas esse é um procedimento delicado e delicado que é difícil de automatizar para fazê-lo funcionar sem problemas. Portanto, este é um sinal de menos.
Temos mais de mil eventos diferentes, o que nos dá uma
taxa INSERT alta por máquina - registramos constantemente todos os dados em mil tabelas. Para ClickHouse, este é um anti-padrão. Se a Pepsi tiver o slogan - "Viva em grandes goles", clique em ClickHouse -
"Viva em grande lote" . Se isso não for feito, a replicação será bloqueada, o ClickHouse se recusará a aceitar novas inserções - um esquema desagradável.
Abordagem nº 2 - uma mesa ampla . Os homens siberianos tentaram deslizar a serra elétrica no trilho e aplicar um modelo de dados diferente. Fazemos uma tabela com
mil colunas , onde cada evento tem colunas reservadas para seus dados. Temos uma enorme
tabela esparsa - felizmente, isso não foi além do ambiente de desenvolvimento, porque desde as primeiras inserções ficou claro que o esquema é absolutamente ruim e não faremos isso.
Mas ainda quero usar um produto de software interessante, um pouco mais para terminar - e será o que você precisa.
Abordagem nº 3 - tabela genérica. Temos uma tabela enorme na qual armazenamos dados em matrizes, porque o ClickHouse suporta
tipos de dados não escalares . Ou seja, iniciamos uma coluna na qual os nomes dos atributos são armazenados e uma coluna separada com uma matriz na qual os valores dos atributos são armazenados.
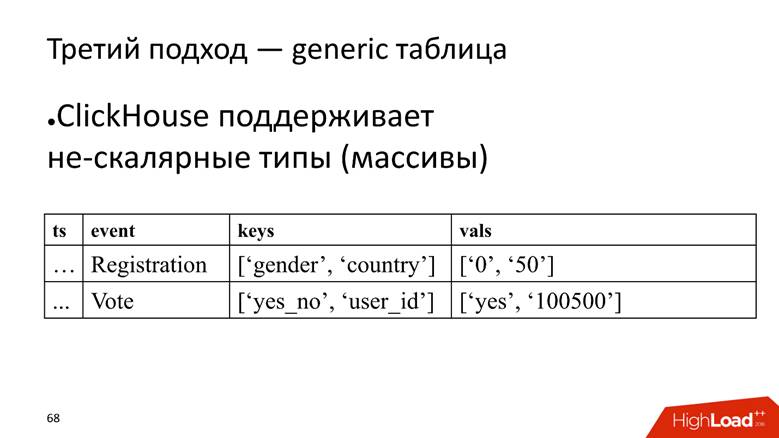
O ClickHouse aqui executa sua tarefa muito bem. Se tivéssemos apenas que inserir dados, provavelmente pressionaríamos mais 10 vezes na instalação atual.
No entanto, a mosca da pomada é que também é um anti-padrão para o ClickHouse -
armazenar matrizes de strings . Isso é ruim porque as matrizes de linha
ocupam mais espaço em disco - elas encolhem pior que as colunas simples e são
mais difíceis de processar . Mas, para nossa tarefa, fechamos os olhos para isso, pois as vantagens superam.
Como fazer SELECT a partir de uma tabela? Nossa tarefa é contar registros agrupados por gênero. Primeiro, você precisa encontrar em uma matriz qual posição corresponde à coluna de gênero, depois subir em outra coluna com esse índice e obter os dados.
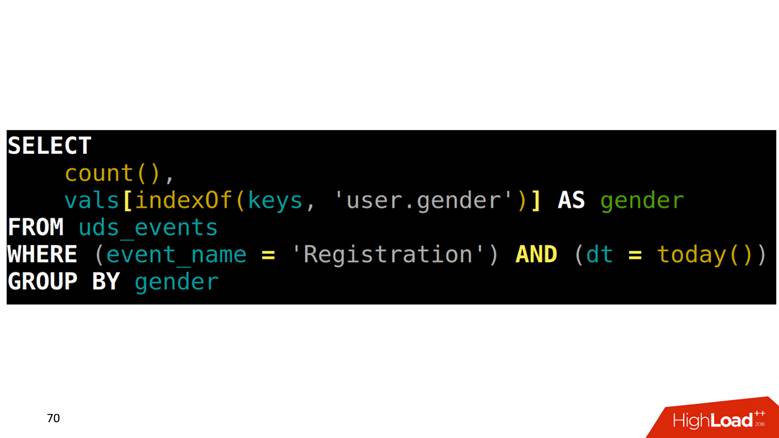
Como desenhar gráficos nesses dados
Como todos os eventos são descritos, eles têm uma estrutura rígida, formamos uma consulta SQL de quatro andares para cada tipo de evento, executamos e salvamos os resultados em outra tabela.
O problema é que, para desenhar dois pontos adjacentes no gráfico, você precisa
digitalizar a tabela inteira . Exemplo: analisamos a inscrição por dia. Este evento é da linha superior à penúltima. Digitalizado uma vez - excelente. Após 5 minutos, queremos desenhar um novo ponto no gráfico - novamente, verificamos o intervalo de dados que se cruza com a verificação anterior e assim por diante para cada evento. Parece lógico, mas não parece ótimo.
Além disso, quando adotamos algumas linhas, também precisamos
ler os resultados em agregação . Por exemplo, há um fato de que o servo de Deus foi registrado na Escandinávia e era homem, e precisamos calcular as estatísticas resumidas: quantos registros, quantos homens, quantos deles são pessoas e quantos são da Noruega. Isso é chamado em termos dos bancos de dados analíticos
ROLLUP, CUBE e
GROUPING SETS - transforme uma linha em várias.
Como tratar
Felizmente, o ClickHouse possui uma ferramenta para resolver esse problema, a saber, o
estado serializado de funções agregadas . Isso significa que você pode digitalizar uma parte dos dados uma vez e salvar esses resultados. Este é um
recurso matador . Há 3 anos, fizemos exatamente isso no Spark e no Hadoop, e é legal que, paralelamente conosco, as melhores mentes do Yandex implementaram um analógico no ClickHouse.
Pedido lento
Temos uma solicitação lenta - para contar usuários únicos para hoje e ontem.
SELECT uniq(user_id) FROM table WHERE dt IN (today(), yesterday())
No plano físico, podemos fazer SELECT para o estado de ontem, obter sua representação binária, salvá-la em algum lugar.
SELECT uniq(user_id), 'xxx' AS ts, uniqState(user id) AS state FROM table WHERE dt IN (today(), yesterday())
Hoje, apenas mudamos a condição que será hoje:
'yyy' AS ts e
WHERE dt = today() e carimbo de data e hora que chamaremos de "xxx" e "aaaa". , , 2 .
SELECT uniqMerge(state) FROM ageagate_table WHERE ts IN ('xxx', 'yyy')
:
, - .
. , , , , ClickHouse, : «, ! , !»
, , .
, . . — SQL-, . , , .

, - time series. : , , , time series.
time series : , , timestamp . , , . . , , , — , . , , ClickHouse -, , .
, , ClickHouse:
— « », — .
time series 2 , 20 20-80 . . ClickHouse
GraphiteMergeTree , time series, .
8 ClickHouse , 6 - , 2 : 2 — , .
1.8 . ,
500 . , 1,8 , 500 ! .
Hadoop
2 . .
3 , CPU —
4 . , .
Process
, , , . , , ClickHouse 3 000 . , , , overkill.
, , . ClickHouse,
. , , , . , 8 3–4 . — .
Present —
, ? time series,
time series , , , .
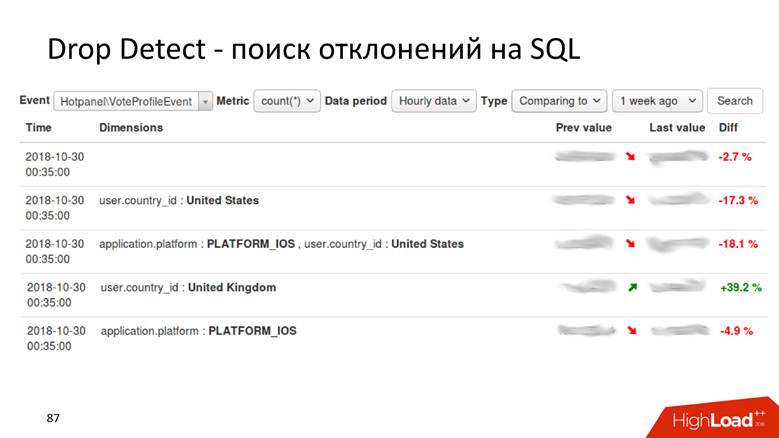
 Drop Detect — SQL
Drop Detect — SQL : SQL- , , .
 Anomaly Detection
Anomaly Detection — . , , 2% , — 40, , , , .
— , , - , Anomaly Detection.
Anomaly Detection
, time series . : , , . time series
. , , . ,
drop detection — , .
UI.
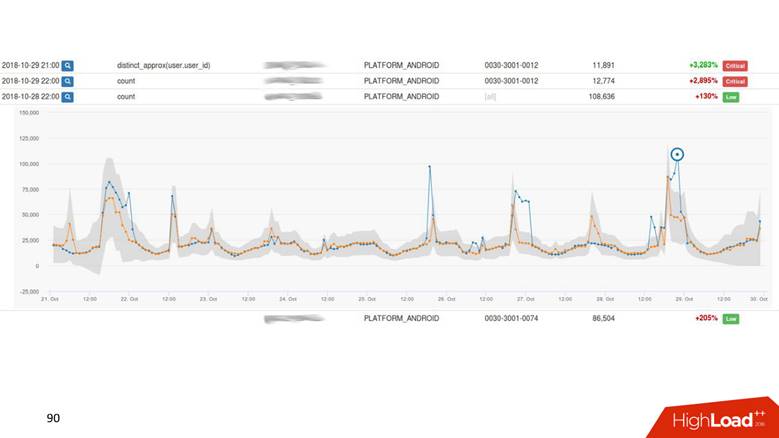
. - , — . -, .
Present
, ,
.
, : 1000 — alarm, 0 — alarm. .
Anomaly Detection , . Anomaly Detection
Exasol , ClickHouse. Anomaly Detection 2 , .
, , 4 .
,
, , . ,
, . ,
.
HighLoad++ , HighLoad++ - . , , :)
, PHP Russia , , . , , , 1,8 /, , 1 .