1. Introdução
A Netcracker é uma empresa internacional, desenvolvedora de soluções integradas de TI, incluindo serviços para a colocação e suporte de equipamentos de clientes, além de hospedagem para o sistema de TI criado para operadoras de telecomunicações.
Essas são principalmente decisões relacionadas à organização das atividades operacionais e comerciais das operadoras de telecomunicações. Mais detalhes podem ser encontrados
aqui .
A disponibilidade contínua da solução que está sendo desenvolvida é muito importante. Se o operador de telecomunicações parar de trabalhar por pelo menos uma hora, isso resultará em grandes perdas financeiras e de reputação para o operador e o fornecedor do software. Portanto, um dos principais requisitos da solução é o parâmetro de
disponibilidade , cujo valor varia de 99,995% a 99,95%, dependendo do tipo de solução.
A solução em si é um conjunto complexo de sistemas de TI monolíticos centrais, incluindo equipamentos complexos de telecomunicações e software de serviço localizado em uma nuvem pública, além de muitos microsserviços integrados a um núcleo central.
Portanto, é muito importante para a equipe de suporte monitorar todos os sistemas de hardware e software integrados em uma única solução. Na maioria das vezes, a empresa usa o monitoramento tradicional. Esse processo está bem estabelecido: podemos construir um sistema de monitoramento semelhante do zero e sabemos como organizar adequadamente os processos de resposta a incidentes. No entanto, existem várias dificuldades nessa abordagem que enfrentamos de projeto para projeto.
- O que monitorar
Qual métrica é atualmente importante e quais serão importantes no futuro? Não há uma resposta definitiva aqui, então tentamos monitorar tudo . Dificuldade número um - o número de métricas. Há problemas de desempenho, os painéis operacionais estão cada vez mais parecendo um painel de controle da espaçonave.
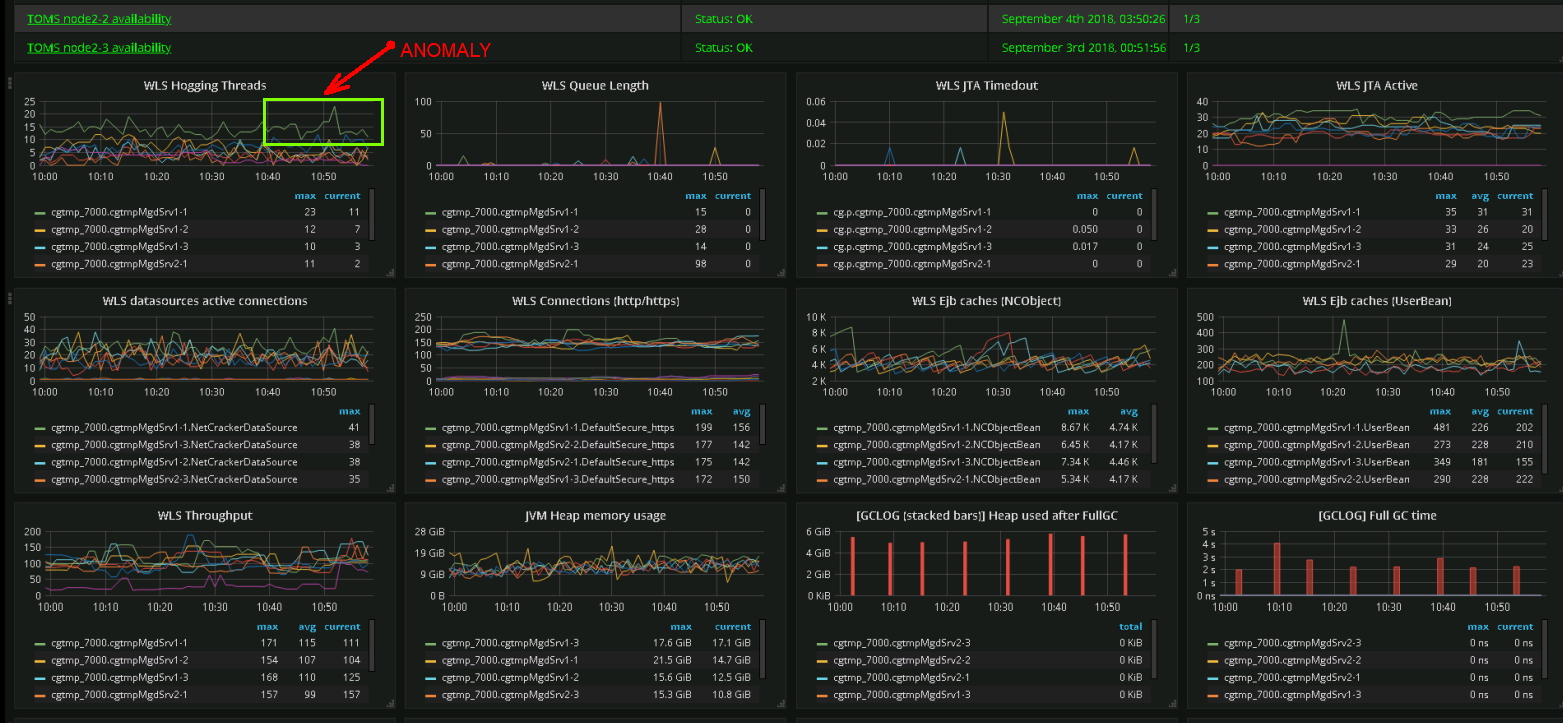
Captura de tela de um painel real. Os engenheiros da equipe de suporte podem identificar anormalidades no comportamento do sistema com base em sua representação gráfica
- Alerta / limiar
Apesar de termos experiência em operar muitos sistemas grandes, monitorá-los ainda é uma tarefa difícil devido às especificidades do equipamento utilizado e às versões de software de vários fornecedores. A experiência e as regras prontas geralmente não podem ser completamente transferidas de uma solução para outra. Existe um certo conjunto básico, cuja melhoria ocorre iterativamente, como a análise de incidentes decorrentes da operação da solução.
A dificuldade número dois é a falta de regras claras para personalização. - Interpretação do resultado
Quando um incidente ocorre, é muito importante localizá-lo rapidamente. Isso depende muito da experiência da equipe de suporte, pois, sob o eixo das mensagens secundárias sobre falhas, você não pode perceber a causa raiz dos problemas e perder tempo com uma resposta rápida. E isso é complexidade três.
Com a ajuda de processos adequadamente organizados, a equipe é capaz de lidar com as dificuldades acima, no entanto, a solicitação moderna de uma mudança de decisão reativa - quando o tempo para passar de uma idéia para a implementação é medido em dias - complica significativamente a tarefa. É necessário treinamento contínuo da equipe. Mudanças constantes levam ao fato de que certas regras e relações de causa e efeito perdem seu significado e, como resultado, o incidente, não sendo eliminado a tempo, pode se transformar em um acidente.
Como o aprendizado de máquina nos ajuda
A previsão de mau funcionamento dos sistemas de hardware e software torna-se uma função muito popular de uma resposta preventiva ou reativa a incidentes.
A NEC Corporation, nossa controladora, investe fortemente no desenvolvimento da ideia de monitoramento. Um resultado desse investimento é a
tecnologia patenteada de
análise invariável do sistema (SIAT) .
O SIAT é uma tecnologia de aprendizado de máquina que, entre o conjunto de dados de sensores ou métricas apresentados como séries temporais, encontra usando algoritmos ML relacionamentos funcionais constantes e constrói um modelo geral - um gráfico desses relacionamentos. Detalhes podem ser encontrados
aqui .
Figura que ilustra a relação encontrada entre sensores de objetos físicos
A idéia, originalmente desenvolvida para sistemas de TI, atualmente se espalhou apenas para monitorar complexos físicos, como fábricas, fábricas, usinas nucleares.
A Lockheed Martin , por exemplo,
implementa essas tecnologias em sua divisão espacial. Em 2018, o
Netcracker, junto com a
NEC, repensou essa idéia e criou um produto adequado para monitorar sistemas de TI como uma ferramenta para análises adicionais.
Importante : isso é apenas uma adição ao sistema de monitoramento, mas não sua substituição.
Aplicações SIAT para sistemas de TI
Qual é a diferença entre um complexo físico e um software? Nos sistemas de software, são utilizadas métricas, nas físicas - sensores. A métrica é usada muito mais, pois um sensor físico sempre vale o dinheiro e é colocado somente onde faz sentido. As métricas de software, quando devidamente organizadas, não custam nada. Além disso, as métricas de dados dos sistemas de informação são muito mais difíceis de interpolar corretamente para o estado do sistema. É mais fácil para uma pessoa entender os sensores relacionados ao mundo físico, enquanto valores específicos das métricas de software fazem sentido apenas em relação a um hardware, configuração e carga específicos.
O relacionamento
funcional no modelo também pressupõe que, se substituirmos a versão do hardware ou software (por exemplo, patches do SO) e todas as operações se tornarem igualmente mais rápidas ou lentas, isso não levará a mensagens falsas sobre acidentes devido ao fato de não termos mudado.
limiares . Se as métricas deixaram de se correlacionar, isso significa um desvio da norma no comportamento do sistema. Além disso, a tecnologia
SIAT permite que até pequenos desvios no comportamento em tempo real sejam detectados, incluindo as chamadas
falhas silenciosas - falhas que não são acompanhadas por nenhuma mensagem de erro. E se esse desvio é apenas um presságio de uma falha maior, temos tempo para reagir corretamente.
Verificamos essa declaração simulando um pequeno servidor Web Apache sob carga, emulando erros internos usando o mecanismo de
injeção de falhas no Linux .
O resultado é apresentado na forma de uma
pontuação de anomalia métrica numérica, cujo valor está associado a este modelo. Quanto maior o valor, mais grave a falha: mais métricas se comportam de maneira anormal. O valor limite é 100% das métricas são anormais, o sistema não funciona. Além disso, o resultado indica aquelas métricas cujo comportamento no momento pode ser considerado anormal. Isso acelera bastante a análise da causa e a identificação do subsistema que está atualmente falhando no modelo de comportamento atual.
Em geral, o
SIAT permite que
você responda mesmo a pequenas mudanças no comportamento que quase não são detectáveis usando o monitoramento tradicional ou de linha de base.
Figura ilustrando uma perturbação na relação entre sensores
Uma vantagem adicional do
SIAT é o algoritmo para construir um modelo de comportamento que não requer a indicação de nenhum senso comercial das métricas. O algoritmo seleciona automaticamente todas as métricas cujo comportamento está interconectado e esse relacionamento é constante. As métricas isoladas restantes são subsistemas de pontos que não afetam a solução de TI ou métricas que não são importantes para o estado da solução no momento. Se fizer sentido, o monitoramento de tais métricas é implementado na estrutura da abordagem tradicional, com base no
alerta de limite .
É muito importante que a criação de um modelo exija dados relacionados ao funcionamento normal do sistema, o que é
muito mais simples do que quando se aborda o treinamento para acidentes.
O modelo é refinado e reconstruído ainda mais se o comportamento mudou ou se adicionamos novas métricas a ele.
Como o comportamento normal do sistema é uma característica variável, dependendo da hora do dia e de outras condições de negócios, para obter uma resposta mais precisa, faz sentido criar vários modelos que descrevam o comportamento do sistema em determinadas condições.
Como é o processo
O processo da organização de monitoramento é o seguinte.
- Começamos o monitoramento tradicional. A escolha certa do nome das métricas é muito importante. O fato é que o resultado inclui os nomes das métricas cujo comportamento é anormal, o que significa que quanto mais precisa a métrica descreve o local e o significado, mais rápido o resultado será obtido. Por exemplo, uma métrica chamada ncp. erp_netcracker _com.apps.erp. clust4.wls .jdbc. LMSDataSource . ActiveConnectionsCurrentCount indica que, no sistema Netcracker ERP , uma métrica chamada ActiveConnectionsCurrentCount falha no quarto cluster Weblogic para o LMSDataSource . Para o especialista, essas informações são mais que suficientes para localizar com precisão a anomalia.
- Em seguida, nos integramos ao sistema de armazenamento de dados de métricas - no nosso caso, ClickHouse - e obtemos os dados de todas as métricas por um certo período do comportamento normal da solução: os melhores modelos são construídos com base nos resultados de monitoramento de 30 dias. Para obter modelos mais precisos, usamos dados métricos por minuto sem agregação.
- Construímos um modelo usando SIAT com base nos dados de um sistema de monitoramento. Dentro da estrutura do modelo construído, filtramos as relações funcionais de acordo com o grau de similaridade. Em resumo, esse é o grau de desvio de comportamento de um dado, expresso como uma porcentagem.
- Verificamos o modelo nos dados dos dias anteriores, onde foram detectadas falhas usando a equipe tradicional de monitoramento e suporte.
- Iniciamos o monitoramento on-line: a cada 10 minutos, os dados de todas as métricas são transferidos para o modelo ou modelos. Obtemos o resultado - pontuação de anomalia e, se o resultado não for zero, também obtemos uma lista de métricas cujo comportamento é atualmente anormal.
- O resultado é enviado ao sistema de monitoramento geral, onde se torna parte dos painéis comuns e outras ferramentas de monitoramento tradicionais.
Teste
Nem uma única implementação ocorre sem verificação. Como sistemas testados, escolhemos nosso próprio
ERP (monólito,
Weblogic ,
Oracle , 4500 métricas) e o sistema de roteamento de todo o nosso sistema de monitoramento, 7 milhões de métricas por minuto, -
relé c-carbono (1200 métricas).
Despejos de todas as métricas foram usados como entrada e os dias em que as falhas foram registradas também foram indicados. Para avaliar o resultado, introduzimos os seguintes conceitos:
- O número de erros do segundo tipo ocorre quando um sistema ou equipe de suporte tradicional de monitoramento encontra uma falha, mas o SIAT não.
- O número de detecções corretas - quando o monitoramento tradicional e o SIAT detectaram um problema.
- O número de erros do primeiro tipo - quando o SIAT detectou um desvio de comportamento, mas a equipe de suporte não o encontrou.
Não encontramos nenhum erro do segundo tipo para os dois sistemas testados. O número de detecções corretas - 85% do número total de falhas encontradas pelo
SIAT e, no caso de falha do equipamento - uma matriz RAID no banco de dados
falhou - o
SIAT detectou uma degradação do comportamento com uma indicação exata das métricas associadas ao banco de dados, sete horas antes de atingir defina o valor limite no sistema de monitoramento.
Os 15% restantes das falhas indicadas no
SIAT são erros do primeiro tipo - comportamento anormal que a equipe de suporte não pode explicar. Provavelmente, isso se deve ao fato de que, ao construir o modelo, essas métricas foram incluídas automaticamente que possuem significado funcional, mas não têm um efeito perceptível no comportamento geral do sistema. Após vários falsos positivos, um especialista em TI pode marcar essas métricas como sem importância e removê-las do modelo, tendo previamente acordado isso com a
PME .
Os resultados mostraram que este produto automatiza completamente o processo de detecção de falhas (incluindo as ocultas), localizando o incidente em tempo hábil e avaliando sua escala.
O que vem a seguir
Agora, estamos acumulando experiência na operação do produto para vários tipos de sistemas de hardware e software, a fim de analisar a aplicabilidade dessa abordagem a vários sistemas: dispositivos de rede, dispositivos
IoT , microsserviços em nuvem e assim por diante.
No momento, a tarefa de reconstruir o modelo é o gargalo. Isso requer um poder computacional significativo, mas, felizmente, a recontagem pode ser realizada em uma máquina isolada, exportando o resultado como um modelo acabado. O monitoramento em tempo real em si não requer recursos significativos e é realizado em paralelo com o monitoramento tradicional no mesmo equipamento.
Conclusão
Resumindo, quero observar que o uso de uma combinação de técnicas tradicionais de monitoramento e algoritmos de aprendizado de máquina permite criar um modelo simples que o ajude a responder a tempo, descobrir onde o problema se originou e também manter o sistema em condições de funcionamento.
Além da promissora tecnologia
SIAT , estamos analisando as possibilidades de usar outra tecnologia
NEC -
Next Generation Log Analytics . A tecnologia permite o uso de algoritmos de aprendizado de máquina e o uso de logs do sistema para determinar anomalias relacionadas ao estado interno do produto que não afetam a degradação geral do sistema em termos de desempenho.
Quais análises você usa para monitorar os sistemas de TI?