
As ferramentas tradicionais no campo da ciência de dados são linguagens como R e Python - sintaxe relaxada e um grande número de bibliotecas para aprendizado de máquina e processamento de dados permitem obter rapidamente algumas soluções de trabalho. No entanto, há situações em que as limitações dessas ferramentas se tornam um obstáculo significativo - primeiro, se você precisar obter alto desempenho em termos de velocidade de processamento e / ou trabalhar com conjuntos de dados realmente grandes. Nesse caso, o especialista precisa recorrer com relutância à ajuda do "lado negro" e conectar ferramentas nas linguagens de programação "industriais": Scala , Java e C ++ .
Mas esse lado é tão escuro? Ao longo dos anos de desenvolvimento, as ferramentas da ciência de dados "industrial" percorreram um longo caminho e hoje são bastante diferentes de suas próprias versões há 2-3 anos. Vamos tentar usar o exemplo da tarefa SNA Hackathon 2019 para descobrir o quanto o ecossistema Scala + Spark pode corresponder à Python Data Science.
No âmbito do SNA Hackathon 2019, os participantes resolvem o problema de classificar o feed de notícias de um usuário de uma rede social em uma das três "disciplinas": usando dados de textos, imagens ou registros de recursos. Nesta publicação, veremos como no Spark é possível resolver um problema com base em um log de sinais usando ferramentas clássicas de aprendizado de máquina.
Na solução do problema, seguiremos o caminho padrão que qualquer especialista em análise de dados seguirá ao desenvolver um modelo:
- Iremos realizar análises de dados de pesquisa, construir gráficos.
- Analisamos as propriedades estatísticas dos sinais nos dados, observamos suas diferenças entre os conjuntos de treinamento e teste.
- Conduziremos uma seleção inicial de recursos com base nas propriedades estatísticas.
- Calculamos as correlações entre os sinais e a variável alvo, bem como a correlação cruzada entre os sinais.
- Vamos formar o conjunto final de recursos, treinar o modelo e verificar sua qualidade.
- Vamos analisar a estrutura interna do modelo para identificar pontos de crescimento.
Durante nossa "jornada", conheceremos ferramentas como o notebook interativo Zeppelin , a biblioteca de aprendizado de máquina Spark ML e sua extensão PravdaML , o pacote de gráficos GraphX , a biblioteca de visualização de Vegas e, é claro, o Apache Spark em toda a sua glória: ) Todos os resultados de código e experimento estão disponíveis na plataforma de notebook colaborativo Zepl .
Carregamento de dados
A peculiaridade dos dados apresentados no SNA Hackathon 2019 é que é possível processá-los diretamente usando Python, mas é difícil: os dados originais são compactados de maneira bastante eficiente, graças aos recursos do formato de coluna Apache Parquet e ao ler na memória "pela testa", são descompactados em várias dezenas de gigabytes. Ao trabalhar com o Apache Spark, não há necessidade de carregar completamente os dados na memória, a arquitetura Spark foi projetada para processar dados em partes, carregando do disco conforme necessário.
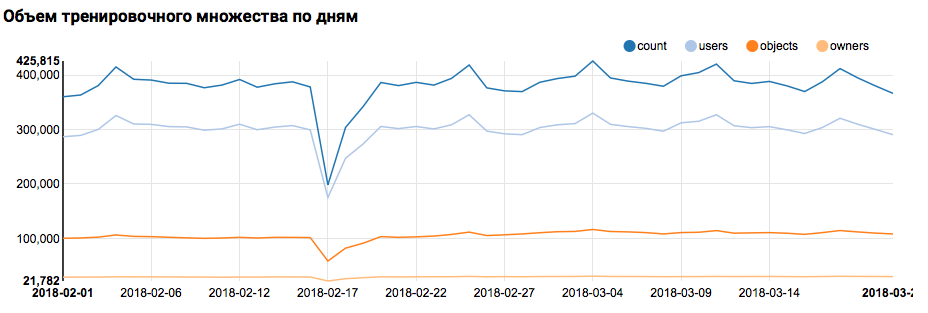
Portanto, a primeira etapa - verificar a distribuição dos dados por dia - é facilmente executada por ferramentas in a box:
val train = sqlContext.read.parquet("/events/hackatons/SNAHackathon/2019/collabTrain") z.show(train.groupBy($"date").agg( functions.count($"instanceId_userId").as("count"), functions.countDistinct($"instanceId_userId").as("users"), functions.countDistinct($"instanceId_objectId").as("objects"), functions.countDistinct($"metadata_ownerId").as("owners")) .orderBy("date"))
O que o gráfico correspondente exibirá no Zeppelin:
Devo dizer que a sintaxe do Scala é bastante flexível, e o mesmo código pode parecer, por exemplo, assim:
val train = sqlContext.read.parquet("/events/hackatons/SNAHackathon/2019/collabTrain") z.show( train groupBy $"date" agg( count($"instanceId_userId") as "count", countDistinct($"instanceId_userId") as "users", countDistinct($"instanceId_objectId") as "objects", countDistinct($"metadata_ownerId") as "owners") orderBy "date" )
Um aviso importante deve ser feito aqui: ao trabalhar em uma equipe grande, onde todos abordam a escrita do código Scala exclusivamente do ponto de vista de seu próprio gosto, a comunicação é muito mais difícil. Portanto, é melhor desenvolver um conceito unificado de estilo de código.
Mas voltando à nossa tarefa. Uma análise simples por dia mostrou a presença de pontos anormais nos dias 17 e 18 de fevereiro; provavelmente hoje em dia foram coletados dados incompletos e a distribuição de características pode ser tendenciosa. Isso deve ser levado em consideração em análises posteriores. Além disso, é impressionante que o número de usuários únicos esteja muito próximo do número de objetos; portanto, faz sentido estudar a distribuição de usuários com diferentes números de objetos:
z.show(filteredTrain .groupBy($"instanceId_userId").count .groupBy("count").agg(functions.log(functions.count("count")).as("withCount")) .orderBy($"withCount".desc) .limit(100) .orderBy($"count"))
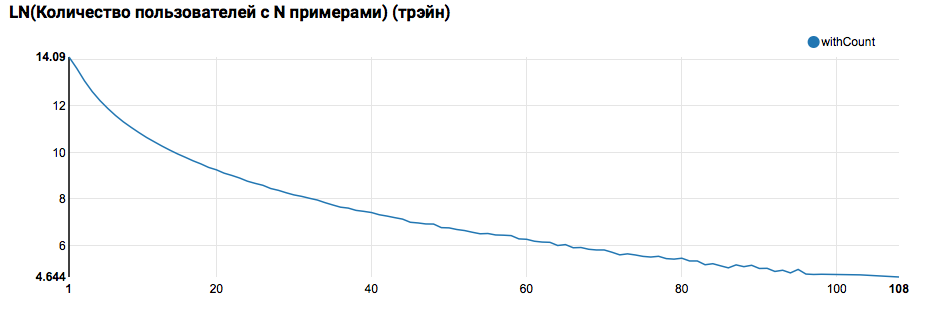
Espera-se ver uma distribuição próxima ao exponencial, com uma cauda muito longa. Em tais tarefas, como regra, é possível obter uma melhoria na qualidade do trabalho, segmentando modelos para usuários com diferentes níveis de atividade. Para verificar se vale a pena fazer isso, compare a distribuição do número de objetos por usuário no conjunto de testes:
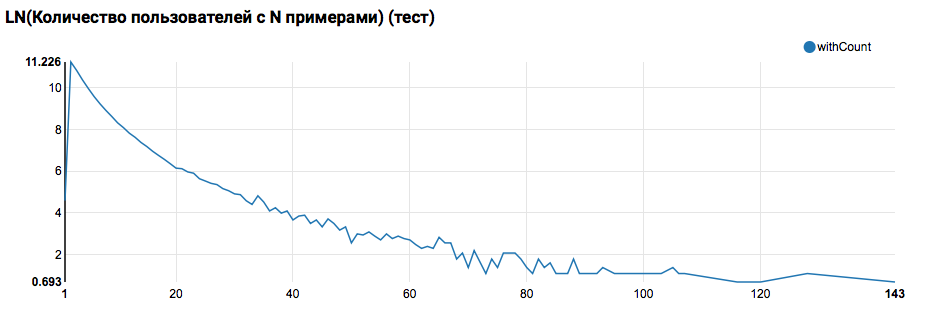
A comparação com o teste mostra que os usuários do teste têm pelo menos dois objetos nos logs (como o problema de classificação foi resolvido no hackathon, essa é uma condição necessária para avaliar a qualidade). No futuro, recomendo examinar mais de perto os usuários no conjunto de treinamento, para os quais declaramos Função Definida pelo Usuário com um filtro:
Uma observação importante também deve ser feita aqui: é do ponto de vista da definição de UDF que o uso do Spark no Scala / Java e no Python é muito diferente. Enquanto o código PySpark usa a funcionalidade básica, tudo funciona quase tão rápido, mas quando as funções substituídas aparecem, o desempenho do PySpark diminui por uma ordem de magnitude.
O primeiro pipeline de ML
Na próxima etapa, tentaremos calcular as estatísticas básicas de ações e atributos. Mas, para isso, precisamos dos recursos do SparkML; primeiro, veremos sua arquitetura geral:

O SparkML é construído com base nos seguintes conceitos:
- Transformador - pega um conjunto de dados como entrada e retorna um conjunto modificado (transformação). Como regra, ele é usado para implementar algoritmos de pré e pós-processamento, extração de recursos e também pode representar os modelos de ML resultantes.
- Estimador - pega um conjunto de dados como entrada e retorna o transformador (em forma). Naturalmente, o Estimator pode representar o algoritmo ML.
- Pipeline é um caso especial do Estimator, que consiste em uma cadeia de transformadores e estimadores. Quando o método é chamado, o ajuste passa pela cadeia e, se ele vê um transformador, aplica-o aos dados e, se vê um estimador, treina o transformador com ele, aplica-o aos dados e vai além.
- PipelineModel - o resultado do Pipeline também contém uma cadeia interna, mas composta exclusivamente por transformadores. Por conseguinte, o próprio PipelineModel também é um transformador.
Essa abordagem para a formação de algoritmos ML ajuda a obter uma estrutura modular clara e boa reprodutibilidade - tanto modelos quanto pipelines podem ser salvos.
Para começar, criaremos um pipeline simples com o qual calcularemos as estatísticas da distribuição de ações (campo de feedback) dos usuários no conjunto de treinamento:
val feedbackAggregator = new Pipeline().setStages(Array(
Nesse pipeline, a funcionalidade do PravdaML é usada ativamente - bibliotecas com blocos úteis estendidos para o SparkML, a saber:
- MultinominalExtractor é usado para codificar um caractere do tipo "array of strings" em um vetor, de acordo com o princípio one-hot. Este é o único estimador no pipeline (para criar uma codificação, você deve coletar linhas exclusivas do conjunto de dados).
- VectorStatCollector é usado para calcular estatísticas de vetores.
- VectorExplode é usado para converter o resultado em um formato conveniente para visualização.
O resultado do trabalho será um gráfico mostrando que as classes no conjunto de dados não são balanceadas, no entanto, o desequilíbrio para a classe Liked de destino não é extremo:

A análise de uma distribuição semelhante entre usuários semelhantes aos de teste (com "positivo" e "negativo" nos logs) mostra que ela é enviesada para a classe positiva:
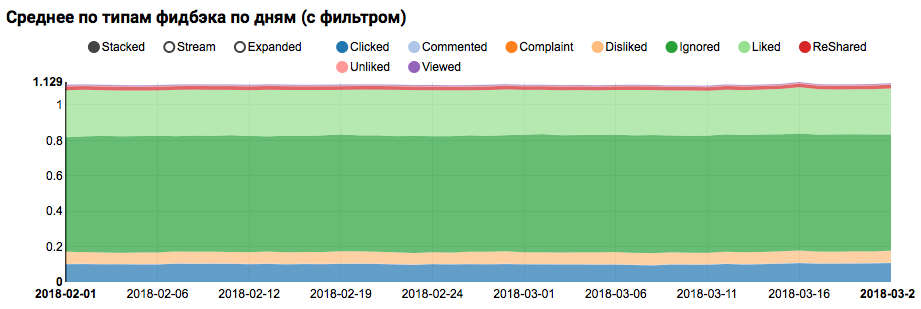
Análise estatística de sinais
Na próxima etapa, realizaremos uma análise detalhada das propriedades estatísticas dos atributos. Desta vez, precisamos de um transportador maior:
val statsAggregator = new Pipeline().setStages(Array( new NullToDefaultReplacer(),
Como agora precisamos trabalhar não com um campo separado, mas com todos os atributos de uma só vez, usaremos mais dois utilitários PravdaML úteis:
- NullToDefaultReplacer permite substituir elementos ausentes nos dados por seus valores padrão (0 para números, falso para variáveis lógicas etc.). Se você não fizer essa conversão, os valores de NaN aparecerão nos vetores resultantes, o que é fatal para muitos algoritmos (embora, por exemplo, o XGBoost possa sobreviver a isso). Uma alternativa para substituir por zeros pode ser substituir por médias, isso é implementado no NaNToMeanReplacerEstimator.
- O AutoAssembler é um utilitário muito poderoso que analisa o layout da tabela e, para cada coluna, seleciona um esquema de vetorização que corresponde ao tipo de coluna.
Usando o pipeline resultante, calculamos as estatísticas para três conjuntos (treinamento, treinamento com filtro e teste do usuário) e salvamos em arquivos separados:
Após receber três conjuntos de dados com estatísticas de atributos, analisamos o seguinte:
- Temos sinais para os quais existem grandes emissões?
- Esses sinais devem ser limitados ou os registros externos devem ser filtrados. - Temos sinais com um grande viés da média em relação à mediana.
- Essa mudança geralmente ocorre na presença de uma distribuição de energia; faz sentido logaritmo esses sinais. - Há uma mudança nas distribuições médias entre os conjuntos de treinamento e teste.
- Quão bem preenchida nossa matriz de recursos.
Para esclarecer esses aspectos, essa solicitação nos ajudará:
def compareWithTest(data: DataFrame) : DataFrame = { data.where("date = 'All'") .select( $"features",
Nesse estágio, a questão da visualização é urgente: é difícil exibir todos os aspectos imediatamente usando as ferramentas regulares do Zeppelin, e os notebooks com um grande número de gráficos começam a ficar visivelmente mais lentos devido ao DOM inchado. A biblioteca Vegas - DSL no Scala para criar especificações vega-lite pode resolver esse problema. Vegas não apenas fornece recursos de visualização mais avançados (comparáveis ao matplotlib), mas também os desenha no Canvas sem inflar o DOM :).
A especificação do gráfico em que estamos interessados ficará assim:
vegas.Vegas(width = 1024, height = 648)
O gráfico abaixo deve ser assim:
- O eixo X mostra o deslocamento dos centros de distribuição entre os conjuntos de teste e treinamento (quanto mais próximo de 0, mais estável o sinal).
- A porcentagem de elementos diferentes de zero é plotada ao longo do eixo Y (quanto maior, mais dados existem para o maior número de pontos por atributo).
- O tamanho mostra a mudança da média em relação à mediana (quanto maior o ponto, maior a distribuição da lei de energia para ele).
- Cor indica emissões (quanto mais vermelho, mais emissões).
- Bem, o formulário é diferenciado por um modo de comparação: com um filtro de usuário no conjunto de treinamento ou sem filtro.
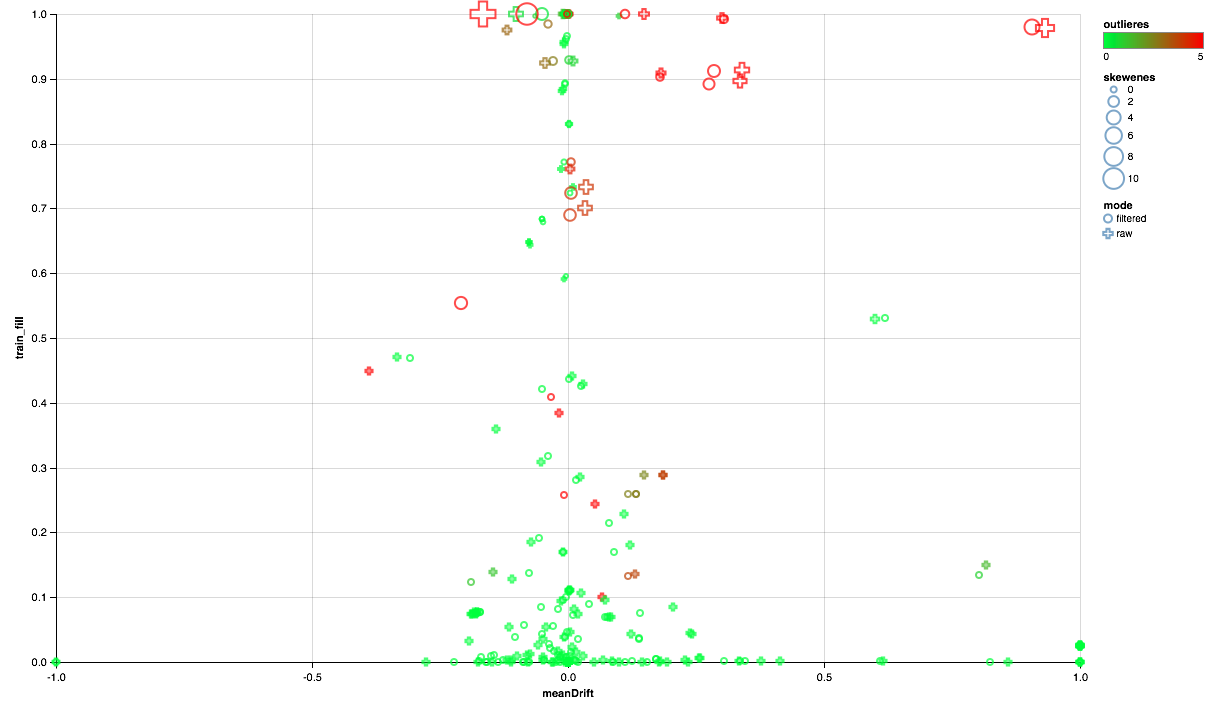
Assim, podemos tirar as seguintes conclusões:
- Alguns sinais precisam de um filtro de emissão - limitaremos os valores máximos para o 90º percentil.
- Alguns sinais mostram uma distribuição próxima da exponencial - vamos usar o logaritmo.
- Alguns recursos não são apresentados no teste - vamos excluí-los do treinamento.
Análise de correlação
Depois de ter uma idéia geral de como os atributos são distribuídos e como eles se relacionam entre os conjuntos de treinamento e teste, vamos tentar analisar as correlações. Para fazer isso, configure o extrator de recursos com base em observações anteriores:
Das novas máquinas desse pipeline, o utilitário SQLTransformer atrai a atenção, o que permite transformações arbitrárias de SQL da tabela de entrada.
Ao analisar as correlações, é importante filtrar o ruído criado pela correlação natural dos recursos one-hot. Para fazer isso, eu gostaria de entender quais elementos do vetor correspondem a quais colunas de origem. Esta tarefa no Spark é realizada usando metadados da coluna (armazenados com dados) e grupos de atributos. O seguinte bloco de código é usado para filtrar pares de nomes de atributos provenientes da mesma coluna do tipo String:
val attributes = AttributeGroup.fromStructField(raw.schema("features")).attributes.get val originMap = filteredTrain .schema.filter(_.dataType == StringType) .flatMap(x => attributes.map(_.name.get).filter(_.startsWith(x.name + "_")).map(_ -> x.name)) .toMap
Tendo em mãos um conjunto de dados com uma coluna de vetor, o cálculo de correlações cruzadas usando o Spark é bastante simples, mas o resultado é uma matriz, cuja implantação você precisará reproduzir um pouco em um conjunto de pares:
val pearsonCorrelation =
E, é claro, visualização: precisaremos novamente da ajuda de Vegas para desenhar um mapa de calor:
vegas.Vegas("Pearson correlation heatmap") .withDataFrame(pearsonCorrelation .withColumn("isPositive", $"corr" > 0) .withColumn("abs_corr", functions.abs($"corr")) .where("feature1 < feature2 AND abs_corr > 0.05") .orderBy("feature1", "feature2")) .encodeX("feature1", Nom) .encodeY("feature2", Nom) .encodeColor("abs_corr", Quant, scale=Scale(rangeNominals=List("#FFFFFF", "#FF0000"))) .encodeShape("isPositive", Nom) .mark(vegas.Point) .show
O resultado é melhor procurar no Zepl-e . Para uma compreensão geral:
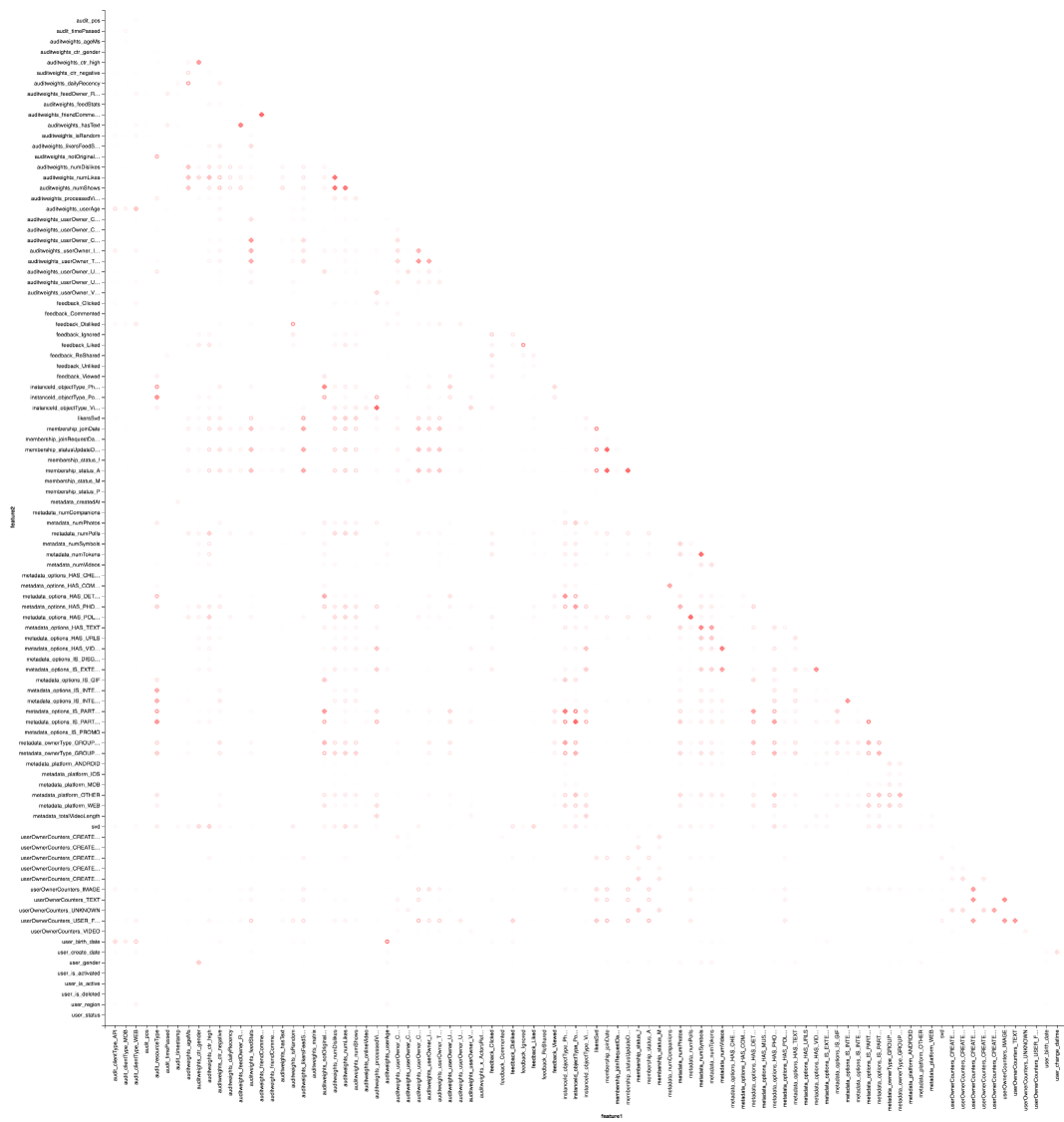
O mapa de calor mostra que algumas correlações estão claramente lá. Vamos tentar selecionar os blocos dos recursos mais fortemente correlacionados, para isso usamos a biblioteca GraphX : transformamos a matriz de correlação em um gráfico, filtramos as arestas por peso, após o qual encontramos os componentes conectados e deixamos apenas os não degenerados (de mais de um elemento). Esse procedimento é essencialmente semelhante à aplicação do algoritmo DBSCAN e é o seguinte:
O resultado é apresentado na forma de uma tabela:
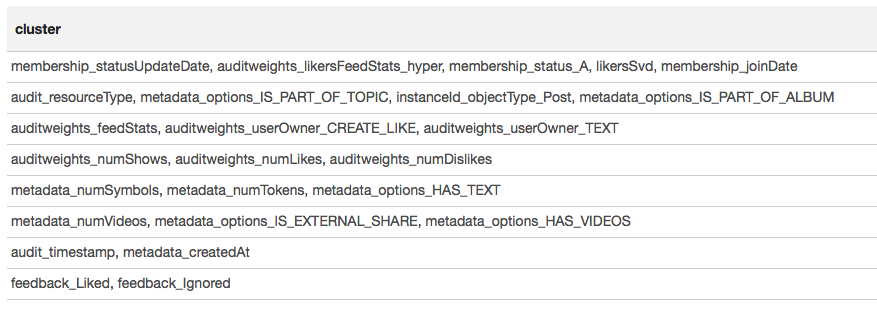
Com base nos resultados do clustering, podemos concluir que os grupos mais correlacionados se formaram em torno de sinais associados à associação de usuários no grupo (Membership_status_A), bem como em torno do tipo de objeto (instanceId_objectType). Para a melhor modelagem da interação de sinais, faz sentido aplicar a segmentação de modelos - treinar modelos diferentes para diferentes tipos de objetos, separadamente para grupos nos quais o usuário está e não está.
Aprendizado de máquina
Abordamos a coisa mais interessante - aprendizado de máquina. O pipeline para treinar o modelo mais simples (regressão logística) usando as extensões SparkML e PravdaML é o seguinte:
new Pipeline().setStages(Array( new SQLTransformer().setStatement( """SELECT *, IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label FROM __THIS__"""), new NullToDefaultReplacer(), new AutoAssembler() .setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label") .setOutputCol("features"), Scaler.scale(Interceptor.intercept(UnwrappedStage.repartition( new LogisticRegressionLBFSG(), numPartitions = 127)))
Aqui vemos não apenas muitos elementos familiares, mas também vários novos:
- LogisticRegressionLBFSG é um estimador com treinamento distribuído de regressão logística.
- Para obter o desempenho máximo dos algoritmos ML distribuídos. os dados devem ser idealmente distribuídos entre partições. O utilitário UnwrappedStage.repartition ajudará nisso, adicionando uma operação de repartição ao pipeline para que seja usada apenas no estágio de treinamento (afinal, ao criar previsões, não é mais necessário).
- Para que o modelo linear possa dar um bom resultado. os dados devem ser dimensionados, pelos quais o utilitário Scaler.scale é responsável. No entanto, a presença de duas transformações lineares consecutivas (escala e multiplicação pelos pesos de regressão) leva a gastos desnecessários, e é desejável recolher essas operações. Ao usar o PravdaML, a saída será um modelo limpo com uma transformação :).
- Bem, é claro, para esses modelos, você precisa de um membro gratuito, que adicionamos usando a operação Interceptor.intercept.
O pipeline resultante, aplicado a todos os dados, fornece AUC por usuário 0,6889 (o código de validação está disponível no Zepl ). Agora resta aplicar toda a nossa pesquisa: filtrar dados, transformar recursos e modelos de segmento. O pipeline final ficará assim:
new Pipeline().setStages(Array( new SQLTransformer().setStatement(s"SELECT instanceId_userId, instanceId_objectId, ${expressions.mkString(", ")} FROM __THIS__"), new SQLTransformer().setStatement("""SELECT *, IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label, concat(IF(membership_status = 'A', 'OwnGroup_', 'NonUser_'), instanceId_objectType) AS type FROM __THIS__"""), new NullToDefaultReplacer(), new AutoAssembler() .setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label", "type","instanceId_objectType") .setOutputCol("features"), CombinedModel.perType( Scaler.scale(Interceptor.intercept(UnwrappedStage.repartition( new LogisticRegressionLBFSG(), numPartitions = 127))), numThreads = 6) ))
PravdaML — CombinedModel.perType. , numThreads = 6. .
, , per-user AUC 0.7004. ? , " " XGBoost :
new Pipeline().setStages(Array( new SQLTransformer().setStatement("""SELECT *, IF(array_contains(feedback, 'Liked'), 1.0, 0.0) AS label FROM __THIS__"""), new NullToDefaultReplacer(), new AutoAssembler() .setColumnsToExclude("date", "instanceId_userId", "instanceId_objectId", "feedback", "label") .setOutputCol("features"), new XGBoostRegressor() .setNumRounds(100) .setMaxDepth(15) .setObjective("reg:logistic") .setNumWorkers(17) .setNthread(4) .setTrackerConf(600000L, "scala") ))
, — XGBoost Spark ! DLMC , PravdaML , ( ). XGboost " " 10 per-user AUC 0.6981.
, , , . SparkML , . PravdaML : Parquet Spark:
Parquet, PravdaML — TopKTransformer, .
Vegas ( Zepl ):
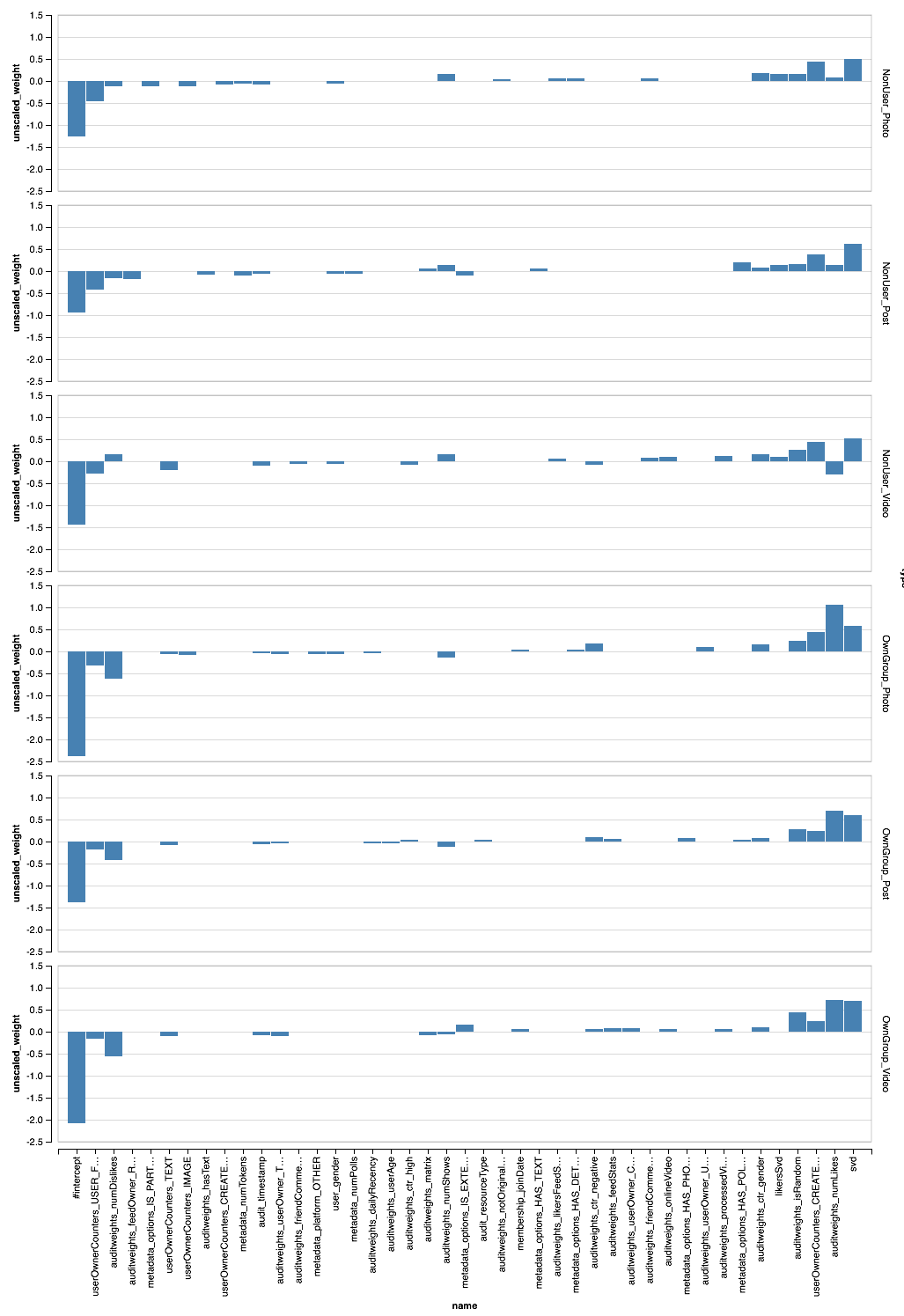
, - . XGBoost?
val significance = sqlContext.read.parquet( "sna2019/xgBoost15_100_raw/stages/*/featuresSignificance" vegas.Vegas() .withDataFrame(significance.na.drop.orderBy($"significance".desc).limit(40)) .encodeX("name", Nom, sortField = Sort("significance", AggOps.Mean)) .encodeY("significance", Quant) .mark(vegas.Bar) .show
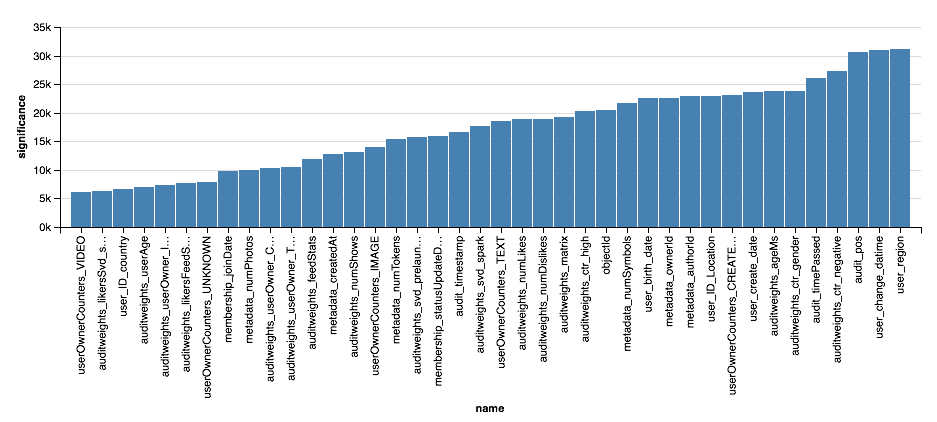
, , XGBoost, , . . , XGBoost , , .
Conclusões
, :). :
- , Scala Spark , , , , .
- Scala Spark Python: ETL ML, , , .
- , , , (, ) , , .
- , , . , , , -, .
, , , , -. , , " Scala " Newprolab.
, , — SNA Hackathon 2019 .