
Marcadores são uma coisa boa. Útil em quantidades razoáveis. Quando há muitos deles, os benefícios desaparecem. O que fazer se você quiser marcar os resultados da pesquisa no mapa, em que dezenas de milhares de objetos? No artigo, mostrarei como solucionamos esse problema em uma placa WebGL sem comprometer sua aparência e desempenho.
Antecedentes
Em 2016, a 2GIS lançou seu primeiro projeto WebGL, Floors: plantas de edifícios em 3D.
Pisos do Aura do centro comercial de Novosibirsk
Imediatamente após o lançamento do Floors, nossa equipe começou a desenvolver um mecanismo cartográfico tridimensional completo no WebGL. O mecanismo foi desenvolvido em conjunto com a nova versão 2gis.ru e agora está no status beta público .
Praça Vermelha desenhada no WebGL. Os planos de construção agora estão integrados diretamente no mapa.
Tarefa de generalização de assinatura
Quem quiser escrever seu próprio mecanismo de mapa, mais cedo ou mais tarde, enfrentará o problema de colocar assinaturas no mapa. Existem muitos objetos no mapa e é impossível assinar cada um deles para que as assinaturas não se sobreponham.
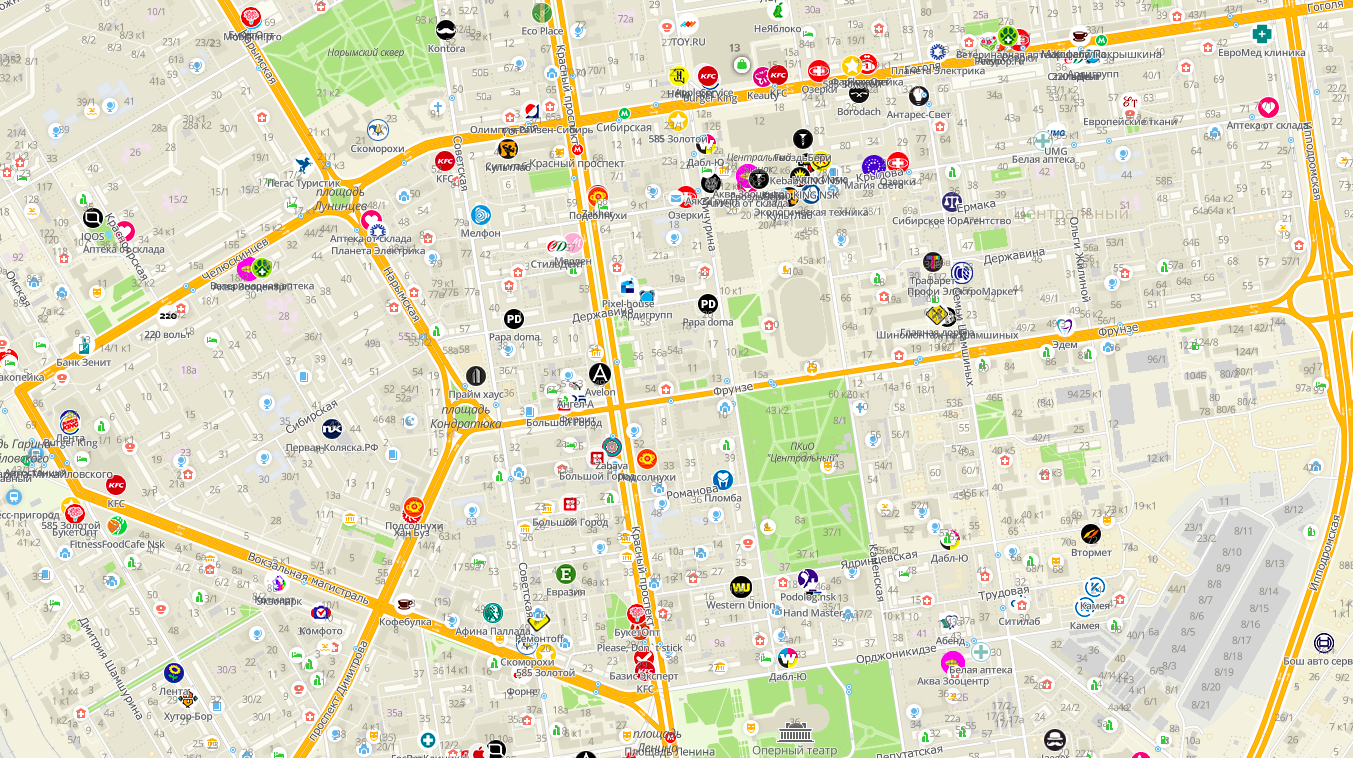
O que acontecerá se em Novosibirsk todos os objetos forem assinados de uma só vez
Para resolver esse problema, é necessária a generalização de assinaturas. A generalização no sentido geral é a transformação dos dados do mapa para que sejam adequados para exibição em pequenas escalas. Isso pode ser feito por diferentes métodos. Para assinaturas, o método de seleção é geralmente usado: do número total, um subconjunto das assinaturas mais prioritárias que não se cruzam entre si é selecionado.
A prioridade da assinatura é determinada pelo seu tipo, bem como pela escala atual do mapa. Por exemplo, em pequena escala, são necessárias assinaturas de cidades e países e, em grande escala, assinaturas de rodovias e números de residências se tornam muito mais importantes. Freqüentemente, a prioridade do nome de um assentamento é determinada pelo tamanho de sua população. Quanto maior, mais importante é a assinatura.
A generalização é necessária não apenas para assinaturas, mas também para marcadores que marcam os resultados da pesquisa no mapa. Por exemplo, ao pesquisar "loja" em Moscou, existem mais de 15.000 resultados. Marcá-los todos no mapa de uma só vez é obviamente uma má ideia.
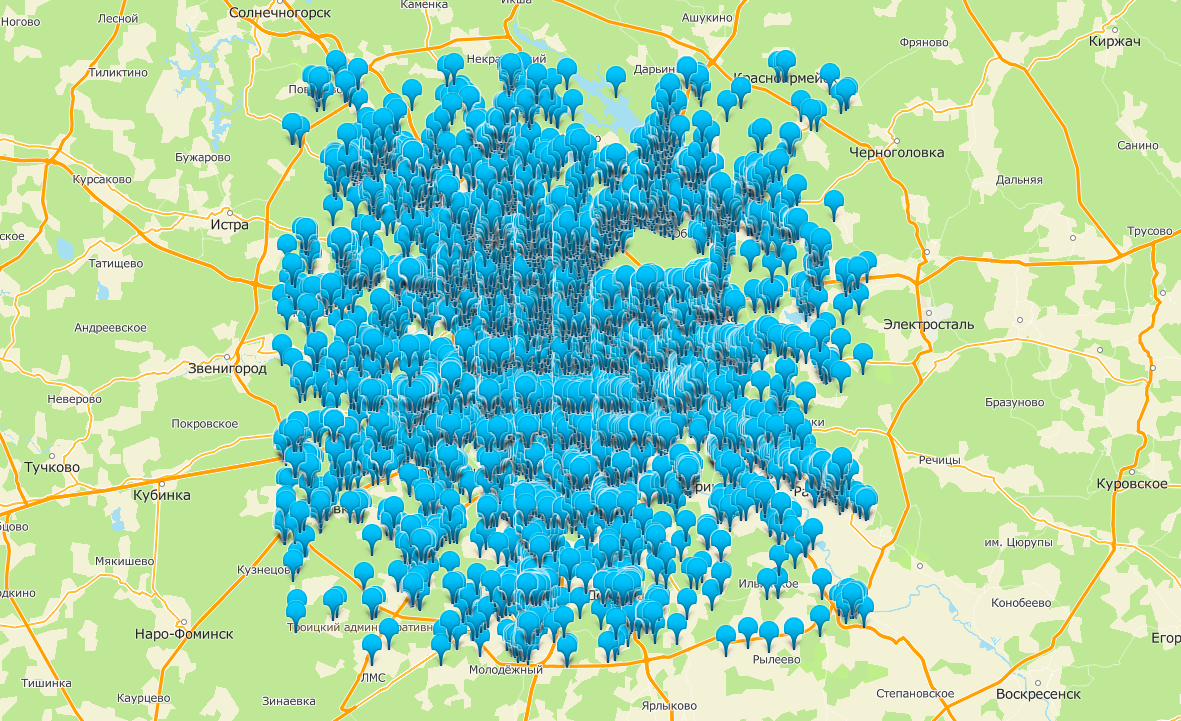
Todas as lojas de Moscou no mapa. Não há como ficar sem generalização
Qualquer interação do usuário com o mapa (movimento, zoom, giro e inclinação) leva a uma alteração na posição dos marcadores na tela; portanto, você deve poder recalcular a generalização em tempo real. Portanto, deve ser rápido.
Neste artigo, usando o exemplo de generalização de marcadores, mostrarei diferentes maneiras de resolver esse problema, que foram usadas em momentos diferentes em nossos projetos.
Abordagem geral à generalização
- Projete cada marcador no plano da tela e calcule para ele um limite - a área retangular que ele ocupa na tela.
- Classifique os marcadores por prioridade.
- Examine sequencialmente cada marcador e coloque-o na tela se ele não se cruzar com outros marcadores colocados na frente dele.
Com o ponto 1, tudo está claro - é apenas um cálculo. No item 2, também tivemos sorte: a lista de marcadores que nos chega do back-end já está classificada por prioridade, por algoritmos de busca. Os resultados mais relevantes com maior probabilidade de interesse do usuário estão no topo dos resultados.
O principal problema está no parágrafo 3: o tempo de cálculo da generalização pode depender muito de como ela é implementada.
Para procurar interseções entre marcadores, precisamos de alguma estrutura de dados que:
- Armazena os limites dos marcadores adicionados à tela.
- Possui um método de
insert(marker) para adicionar um marcador à tela. - Possui um método de
collides(marker) para verificar a interseção do marcador com os que já foram adicionados à tela.
Considere várias implementações dessa estrutura. Todos os exemplos adicionais serão escritos em TypeScript, que usamos na maioria dos nossos projetos. Em todos os exemplos, os marcadores serão representados por objetos da seguinte forma:
interface Marker { minX: number; maxX: number; minY: number; maxY: number; }
Todas as abordagens consideradas serão implementações da seguinte interface:
interface CollisionDetector { insert(item: Marker): void; collides(item: Marker): boolean; }
Para comparar o desempenho, o tempo de execução do seguinte código será medido:
for (const marker of markers) { if (!impl.collides(marker)) { impl.insert(marker); } }
A matriz de markers conterá 100.000 elementos 30x50 colocados aleatoriamente em um plano do tamanho de 1920x1080.
O desempenho será medido no Macbook Air 2012.
Os testes e exemplos de código fornecidos no artigo também são publicados no GitHub .
Implementação ingênua
Para começar, considere a opção mais simples, quando o marcador está marcado para interseção com os outros em um ciclo simples.
class NaiveImpl implements CollisionDetector { private markers: Marker[]; constructor() { this.markers = []; } insert(marker: Marker): void { this.markers.push(marker); } collides(candidate: Marker): boolean { for (marker of this.markers) { if ( candidate.minX <= marker.maxX && candidate.minY <= marker.maxY && candidate.maxX >= marker.minX && candidate.maxY >= marker.minY ) { return true; } } return false; } }
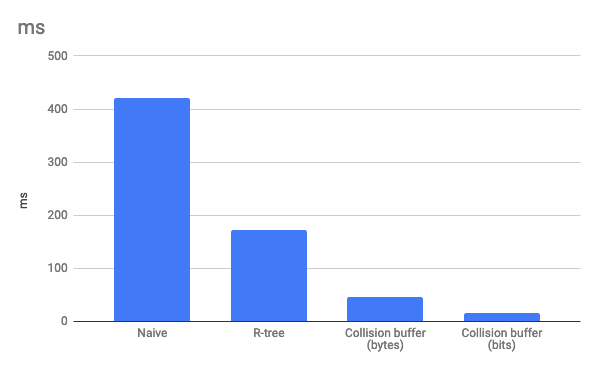
Tempo de cálculo da generalização para 100.000 marcadores: 420 ms . Demais. Mesmo que o cálculo da generalização seja feito em um trabalhador da Web e não bloqueie o encadeamento principal, esse atraso será perceptível a olho nu, principalmente porque essa operação deve ser executada após cada movimento do cartão. Além disso, em dispositivos móveis com um processador fraco, o atraso pode ser ainda maior.
Implementação da árvore R
Como em uma implementação ingênua, cada marcador é verificado quanto à interseção com todos os anteriores, no pior caso, a complexidade desse algoritmo é quadrática. Você pode aprimorá-lo aplicando a estrutura de dados da árvore R. Como uma implementação da árvore R, pegue a biblioteca RBush :
import * as rbush from 'rbush'; export class RTreeImpl implements CollisionDetector { private tree: rbush.RBush<Marker>; constructor() { this.tree = rbush(); } insert(marker: Marker): void { this.tree.insert(marker); } collides(candidate: Marker): boolean { return this.tree.collides(candidate); } }
Tempo de cálculo da generalização para 100.000 marcadores: 173 ms . Significativamente melhor. Usamos essa abordagem nos pisos (isso foi mencionado no meu artigo anterior ).
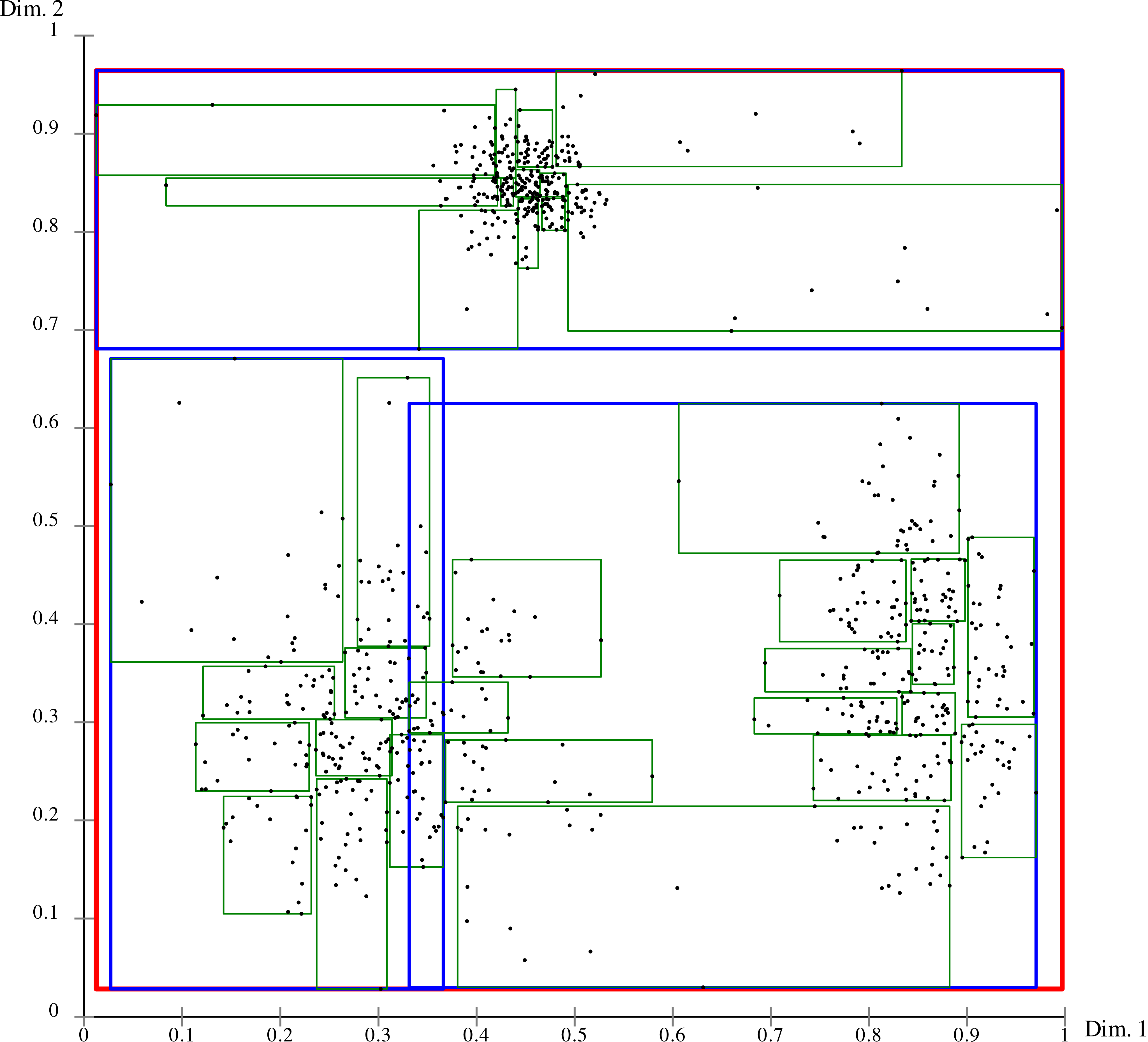
Visualização de armazenamento de pontos na árvore R. A divisão hierárquica do plano em retângulos permite restringir rapidamente a área de pesquisa e não classificar todos os objetos
Implementação de buffer de colisão
Desenhar um mapa é uma tarefa muito mais complicada do que desenhar um plano de um edifício. Isso também se manifesta na generalização. Mesmo nos maiores shopping centers do mundo, 1.000 organizações raramente estão no mesmo andar. Ao mesmo tempo, uma simples consulta de pesquisa em uma cidade grande pode retornar dezenas de milhares de resultados.
Quando começamos a desenvolver um mapa WebGL, começamos a pensar: ainda é possível acelerar a generalização. Uma ideia interessante nos foi oferecida pelo stellarator que trabalhou para nós: em vez da árvore R, use um buffer para armazenar o estado de cada pixel da tela (ocupado ou não ocupado). Ao inserir um marcador na tela, “preencha” o local correspondente no buffer e, ao verificar a possibilidade de colar, verifique os valores de pixel na área requerida.
class CollisionBufferByteImpl implements CollisionDetector { private buffer: Uint8Array; private height: number; constructor(width: number, height: number) { this.buffer = new Uint8Array(width * height); this.height = height; } insert(marker: Marker): void { const { minX, minY, maxX, maxY } = marker; for (let i = minX; i < maxX; i++) { for (let j = minY; j < maxY; j++) { buffer[i * this.height + j] = 1; } } } collides(candidate: Marker): boolean { const { minX, minY, maxX, maxY } = candidate; for (let i = minX; i < maxX; i++) { for (let j = minY; j < maxY; j++) { if (buffer[i * this.height + j]) { return true; } } } return false; } }
Tempo de cálculo da generalização para 100.000 marcadores: 46 ms .
Por que tão rápido? Essa abordagem parece ingênua à primeira vista, e os loops aninhados nos dois métodos não são como código rápido. No entanto, se você olhar mais de perto o código, perceberá que o tempo de execução dos dois métodos não depende do número total de marcadores. Assim, para um tamanho fixo de marcadores WxH, obtemos a complexidade O (W * H * n), ou seja, linear!
Abordagem otimizada do buffer de colisão
Você pode melhorar a abordagem anterior, tanto na velocidade quanto na memória ocupada, se garantir que um pixel seja representado na memória, não por um byte, mas por um bit. O código após essa otimização, no entanto, é visivelmente complicado e cresce com um pouco de mágica:
Código fonte export class CollisionBufferBitImpl implements CollisionDetector { private width: number; private height: number; private buffer: Uint8Array; constructor(width: number, height: number) { this.width = Math.ceil(width / 8) * 8; this.height = height; this.buffer = new Uint8Array(this.width * this.height / 8); } insert(marker: Marker): void { const { minX, minY, maxX, maxY } = marker; const { width, buffer } = this; for (let j = minY; j < maxY; j++) { const start = j * width + minX >> 3; const end = j * width + maxX >> 3; if (start === end) { buffer[start] = buffer[start] | (255 >> (minX & 7) & 255 << (8 - (maxX & 7))); } else { buffer[start] = buffer[start] | (255 >> (minX & 7)); for (let i = start + 1; i < end; i++) { buffer[i] = 255; } buffer[end] = buffer[end] | (255 << (8 - (maxX & 7))); } } } collides(marker: Marker): boolean { const { minX, minY, maxX, maxY } = marker; const { width, buffer } = this; for (let j = minY; j < maxY; j++) { const start = j * width + minX >> 3; const end = j * width + maxX >> 3; let sum = 0; if (start === end) { sum = buffer[start] & (255 >> (minX & 7) & 255 << (8 - (maxX & 7))); } else { sum = buffer[start] & (255 >> (minX & 7)); for (let i = start + 1; i < end; i++) { sum = buffer[i] | sum; } sum = buffer[end] & (255 << (8 - (maxX & 7))) | sum; } if (sum !== 0) { return true; } } return false; } }
Tempo de cálculo da generalização para 100.000 marcadores: 16 ms . Como você pode ver, a complexidade da lógica se justifica e nos permite acelerar o cálculo da generalização em quase três vezes.
Limitações do buffer de colisão
É importante entender que o buffer de colisão não é um substituto completo para a R-tree. Possui muito menos recursos e mais restrições:
- Você não pode entender com o que exatamente o marcador se cruza. O buffer armazena apenas dados sobre quais pixels estão ocupados e quais não. Portanto, é impossível implementar uma operação que retorne uma lista de marcadores que se cruzam com o dado.
- Não é possível excluir o marcador adicionado anteriormente. O buffer não armazena dados sobre quantos marcadores existem em um determinado pixel. Portanto, é impossível implementar corretamente a operação de remoção de um marcador do buffer.
- Alta sensibilidade ao tamanho dos elementos. Se você tentar adicionar marcadores que ocupam a tela inteira ao buffer de colisão, o desempenho cairá drasticamente.
- Trabalha em uma área limitada. O tamanho do buffer é definido quando ele é criado, e é impossível colocar nele um marcador que ultrapasse esse tamanho. Portanto, ao usar essa abordagem, é necessário filtrar manualmente os marcadores que não aparecem na tela.
Todas essas restrições não interferiram na solução do problema da generalização de marcadores. Agora, esse método é usado com sucesso para marcadores na versão beta do 2gis.ru.
No entanto, para generalizar as principais assinaturas no mapa, os requisitos são mais complexos. Por exemplo, para eles, é necessário garantir que o ícone do POI não possa "matar" sua própria assinatura. Como o buffer de colisão não distingue com o que exatamente ocorreu a interseção, ele não permite implementar essa lógica. Portanto, eles tiveram que deixar uma solução com o RBush.
Conclusão
O artigo mostra o caminho que seguimos da solução mais simples para a usada agora.
O uso da árvore R foi o primeiro passo importante que nos permitiu acelerar a implementação ingênua várias vezes. Funciona muito bem no Floors, mas na verdade usamos apenas uma pequena fração dos recursos dessa estrutura de dados.
Depois de abandonar a árvore R e substituí-la por uma matriz bidimensional simples, que faz exatamente o que precisamos e nada mais, obtivemos um aumento ainda maior na produtividade.
Este exemplo nos mostrou o quanto é importante escolher uma solução para um problema dentre várias opções, para entender e perceber as limitações de cada uma delas. Limitações são importantes e úteis, e você não deve ter medo delas: limitando-se habilmente a algo insignificante, você pode obter enormes benefícios em troca, quando é realmente necessário. Por exemplo, para simplificar a solução de um problema ou para se proteger de toda uma classe de problemas ou, como no nosso caso, para melhorar a produtividade várias vezes.