
Qualquer processo relacionado ao banco de dados, mais cedo ou mais tarde, encontra problemas com o desempenho de consultas a esse banco de dados.
O data warehouse da Rostelecom é construído no Greenplum, a maioria dos cálculos (transformação) é realizada por consultas sql, que iniciam (ou geram e executam) o mecanismo ETL. O DBMS possui suas próprias nuances que afetam significativamente o desempenho. Este artigo é uma tentativa de destacar os aspectos mais críticos do trabalho com o Greenplum em termos de desempenho e compartilhamento de experiência.
Em poucas palavras sobre GreenplumGreenplum - servidor de banco de dados
MPP , cujo núcleo é construído no PostgreSql.
Representa várias instâncias diferentes do processo PostgreSql (instâncias). Um deles é o ponto de entrada para o cliente e é chamado de instância principal (mestre), todos os outros são chamados de instâncias de segmento (segmento, instâncias independentes, cada uma com seus próprios dados). Cada servidor (host do segmento) pode executar de um a vários serviços (segmento). Isso é feito para melhor utilizar os recursos do servidor e principalmente os processadores. O assistente armazena metadados, é responsável por comunicar clientes com dados e também distribui trabalho entre segmentos.
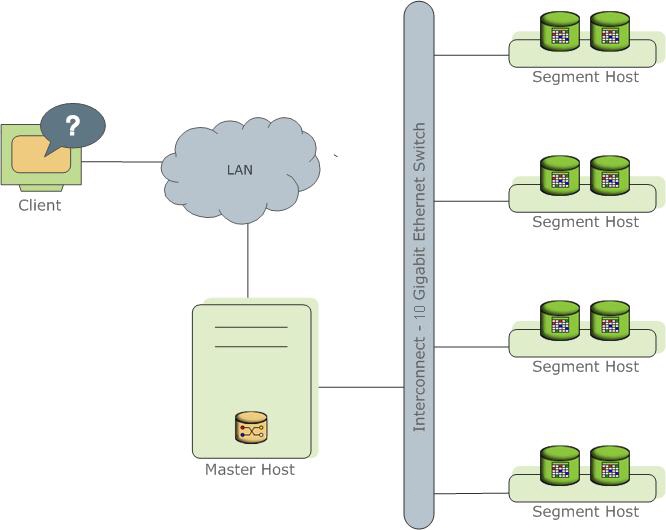
Leia mais na
documentação oficial .
Além disso, no artigo, haverá muitas referências ao plano de solicitação. Informações para Greenplum estão disponíveis
aqui .
Como escrever boas consultas no Greenplum (bem, ou pelo menos não muito triste)
Como estamos lidando com um banco de dados distribuído, é importante não apenas como a consulta sql é gravada, mas também como os dados são armazenados.
1. Distribuição
Os dados são fisicamente armazenados em diferentes segmentos. Você pode separar dados por segmentos aleatoriamente ou pelo valor da função hash de um campo ou um conjunto de campos.
Sintaxe (ao criar uma tabela):
DISTRIBUTED BY (some_field)
Ou então:
DISTRIBUTED RANDOMLY
O campo de distribuição deve ter boa seletividade e não ter valores nulos (ou ter um mínimo de tais valores), pois os registros com esses campos serão distribuídos em um segmento, o que pode levar a distorções nos dados.
O tipo de campo é preferencialmente inteiro. O campo é usado para ingressar nas tabelas. A junção de hash é uma das melhores maneiras de ingressar em tabelas (em termos de execução de consulta), funciona melhor com esse tipo de dados.
Para distribuição, é aconselhável escolher não mais que dois campos e, é claro, um é melhor que dois. Os campos adicionais nas chaves de distribuição, em primeiro lugar, requerem tempo adicional para o hash e, em segundo lugar, (na maioria dos casos) exigirão a transferência de dados entre segmentos ao executar junções.
Você pode usar a distribuição aleatória se não conseguir selecionar um ou dois campos adequados, bem como para rótulos pequenos. Mas devemos levar em conta que essa distribuição funciona melhor para inserção de dados em massa, e não para um registro. O GreenPlum distribui os dados de acordo com o algoritmo
cíclico e inicia um novo ciclo para cada operação de pastilha, começando no primeiro segmento, que, com pequenas pastilhas frequentes, leva a distorções (distorção de dados).
Com um campo de distribuição bem escolhido, todos os cálculos serão realizados no segmento, sem enviar dados para outros segmentos. Além disso, para uma junção ideal de tabelas (junção), os mesmos valores devem estar localizados no mesmo segmento.
Distribuição em imagensBoa chave de distribuição: Chave de distribuição ruim:
Chave de distribuição ruim: Distribuição aleatória:
Distribuição aleatória:
O tipo de campos usados na junção deve ser o mesmo em todas as tabelas.
Importante: não use como campos de distribuição aqueles que são usados para filtrar consultas em onde, pois nesse caso a carga durante a consulta também não será distribuída uniformemente.
2. Particionamento
O particionamento permite dividir tabelas grandes, como
fatos , em partes logicamente separadas. O Greenplum divide fisicamente sua tabela em tabelas separadas, cada uma das quais é dividida em segmentos com base nas configurações da página 1.
As tabelas devem ser divididas em seções logicamente; para esse fim, selecione o campo frequentemente usado no bloco where. Nas tabelas de fatos, esse será o período. Portanto, com acesso adequado à tabela em consultas, você trabalhará apenas com parte de toda a tabela grande.
Em geral, o particionamento é um tópico bastante conhecido, e eu queria enfatizar que você não deve escolher o mesmo campo para particionamento e distribuição. Isso levará ao fato de que a solicitação será executada inteiramente em um segmento.
É hora de ir, de fato, aos pedidos. A solicitação será executada em segmentos de acordo com um
plano específico:
3. O otimizador
O Greenplum possui dois otimizadores, o otimizador herdado incorporado e o otimizador Orca de terceiros: GPORCA - Orca - Otimizador de consulta dinâmica.
Ative o GPORCA mediante solicitação:
set optimizer = on;
Como regra , o otimizador GPORCA é melhor que o embutido. Funciona de forma mais adequada com subconsultas e
CTE (mais detalhes
aqui ).
Fez uma chamada para uma tabela grande no CTE com filtragem máxima de dados (não se esqueça da remoção de partição) e uma lista de campos explicitamente especificada - ela funciona muito bem.
Modifica levemente o plano de consulta, por exemplo, exibe as partições digitalizadas:
Otimizador padrão: Orca:
Orca:
O GPORCA também permite a atualização dos campos de partição / distribuição. Embora existam situações em que o otimizador embutido tenha um desempenho melhor. Um otimizador de terceiros é muito exigente em estatística; é importante não esquecer de
analisar .
Não importa o quão bom seja o otimizador, uma consulta mal escrita nem estenderá o Orca:
4. Manipulações com campos nas condições where block ou join
É importante lembrar que a função aplicada ao campo de filtro ou as condições da junção são aplicadas a
cada registro.
No caso do campo de particionamento (por exemplo, date_trunc para o campo de particionamento - date), mesmo o GPORCA não pode funcionar corretamente nesse caso, as
partições de recorte não funcionarão.
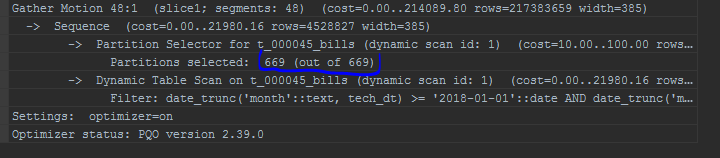
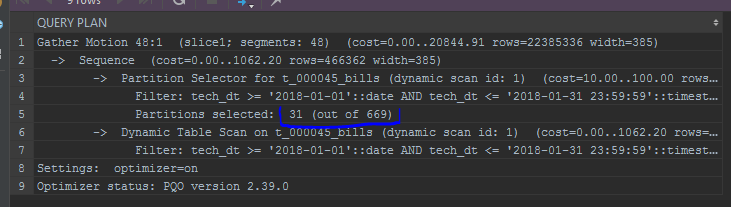 Também chamo a atenção para a exibição de partições. O otimizador interno exibirá partições em uma lista:
Também chamo a atenção para a exibição de partições. O otimizador interno exibirá partições em uma lista:
Aplique cuidadosamente funções a constantes nos mesmos filtros de partição. Um exemplo é o mesmo date_trunc:
date_trunc('month',to_date($p_some_dt, 'YYYYMMDD'))

O GPORCA lidará completamente com essa simulação e funcionará corretamente, o otimizador padrão não funcionará mais. No entanto, ao fazer uma conversão de tipo explícita, você pode fazê-la funcionar:
date_trunc('month',to_date($p_some_dt, 'YYYYMMDD'))::timestamp without time zone

E se tudo for feito errado?
5. Moções
Outro tipo de operação que pode ser observado no
plano de consulta são os movimentos. Movimentos de dados tão marcados entre segmentos:
- Reunir movimento - será exibido em quase todos os planos, significa combinar os resultados da execução de consultas de todos os segmentos em um fluxo (geralmente para o mestre).
Duas tabelas, distribuídas por uma chave, usada para a junção, executam todas as operações nos segmentos, sem mover dados. Caso contrário, ocorrerá um movimento de transmissão ou um movimento de redistribuição: - Movimento de transmissão - cada segmento envia sua cópia dos dados para outros segmentos. Em uma situação ideal, a transmissão ocorre apenas para tabelas pequenas.
- Movimento de redistribuição - para unir tabelas grandes distribuídas por chaves diferentes, a redistribuição é executada para fazer conexões localmente. Para tabelas grandes, isso pode ser uma operação bastante cara.
Transmissão e redistribuição são operações bastante desvantajosas. Eles são executados toda vez que a solicitação é executada. É recomendável evitá-los. Tendo visto esses pontos no plano de consulta, vale a pena prestar atenção nas chaves de distribuição. Operações distintas e sindicais também causam movimentos.
Esta lista não é exaustiva e baseia-se principalmente na experiência do autor. Não funcionou para encontrar tudo imediatamente na Internet ao mesmo tempo. Aqui, tentei identificar os fatores mais críticos que afetam o desempenho da solicitação e entender por que e por que isso está acontecendo.
Este artigo foi preparado pela equipe de gerenciamento de dados Rostelecom