O primeiro artigo descreveu o
mecanismo de indexação do PostgreSQL , o segundo tratou
da interface dos métodos de acesso e agora estamos prontos para discutir tipos específicos de índices. Vamos começar com o índice de hash.
Hash
Estrutura
Teoria geral
Muitas linguagens de programação modernas incluem tabelas de hash como o tipo de dados base. Do lado de fora, uma tabela de hash se parece com uma matriz regular indexada com qualquer tipo de dados (por exemplo, string) e não com um número inteiro. O índice de hash no PostgreSQL é estruturado de maneira semelhante. Como isso funciona?
Como regra, os tipos de dados têm intervalos muito grandes de valores permitidos: quantas seqüências diferentes podemos imaginar em uma coluna do tipo "texto"? Ao mesmo tempo, quantos valores diferentes são realmente armazenados em uma coluna de texto de alguma tabela? Normalmente, não muitos deles.
A idéia do hash é associar um número pequeno (de 0 a
N -1,
N valores no total) a um valor de qualquer tipo de dado. Uma associação como essa é chamada de
função hash . O número obtido pode ser usado como um índice de uma matriz regular, onde as referências às linhas da tabela (TIDs) serão armazenadas. Os elementos dessa matriz são chamados de
buckets da tabela de hash - um bucket pode armazenar vários TIDs se o mesmo valor indexado aparecer em linhas diferentes.
Quanto mais uniformemente uma função hash distribuir valores de origem por buckets, melhor ela é. Mas mesmo uma boa função de hash às vezes produz resultados iguais para diferentes valores de origem - isso é chamado de
colisão . Portanto, um depósito pode armazenar TIDs correspondentes a chaves diferentes e, portanto, os TIDs obtidos no índice precisam ser verificados novamente.
Apenas por exemplo: em que função de hash para strings podemos pensar? Deixe o número de buckets ser 256. Então, por exemplo, um número de buckets, podemos pegar o código do primeiro caractere (assumindo uma codificação de caracteres de byte único). Essa é uma boa função de hash? Evidentemente, não: se todas as seqüências começarem com o mesmo caractere, todas elas entrarão em um balde, então a uniformidade está fora de questão, todos os valores precisarão ser verificados novamente e o hash não fará nenhum sentido. E se somarmos códigos de todos os caracteres do módulo 256? Isso será muito melhor, mas longe de ser o ideal. Se você está interessado nas características internas de uma função hash no PostgreSQL, consulte a definição de hash_any () no
hashfunc.c .
Estrutura de índice
Vamos voltar ao índice de hash. Para um valor de algum tipo de dado (uma chave de índice), nossa tarefa é encontrar rapidamente o TID correspondente.
Ao inserir no índice, vamos calcular a função hash da chave. As funções de hash no PostgreSQL sempre retornam o tipo "número inteiro", que está na faixa de 2
32 ≈ 4 bilhões de valores. O número de buckets inicialmente é igual a dois e aumenta dinamicamente para se ajustar ao tamanho dos dados. O número do bucket pode ser calculado a partir do código hash usando a aritmética de bits. E este é o balde onde colocaremos nossa TID.
Mas isso é insuficiente, pois os TIDs correspondentes a chaves diferentes podem ser colocados no mesmo bucket. O que devemos fazer? É possível armazenar o valor de origem da chave em um bucket, além do TID, mas isso aumentaria significativamente o tamanho do índice. Para economizar espaço, em vez de uma chave, o bucket armazena o código de hash da chave.
Ao pesquisar no índice, calculamos a função hash da chave e obtemos o número do intervalo. Agora, resta analisar o conteúdo do bucket e retornar apenas os TIDs correspondentes aos códigos de hash apropriados. Isso é feito com eficiência, pois os pares armazenados "código de hash - TID" são solicitados.
No entanto, duas chaves diferentes podem acontecer não apenas para entrar em um depósito, mas também para ter os mesmos códigos de hash de quatro bytes - ninguém eliminou a colisão. Portanto, o método de acesso solicita ao mecanismo de indexação geral que verifique cada TID, verificando novamente a condição na linha da tabela (o mecanismo pode fazer isso junto com a verificação de visibilidade).
Mapeando estruturas de dados para páginas
Se observarmos um índice como exibido pelo gerenciador de cache de buffer, e não da perspectiva do planejamento e execução de consultas, acontece que todas as informações e todas as linhas de índice devem ser compactadas em páginas. Essas páginas de índice são armazenadas no cache do buffer e removidas de lá exatamente da mesma maneira que as páginas da tabela.
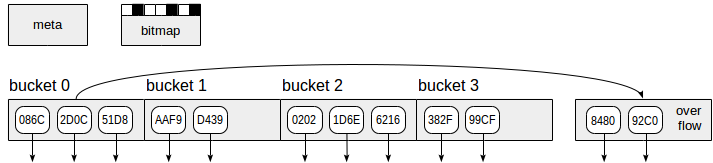
O índice de hash, conforme mostrado na figura, usa quatro tipos de páginas (retângulos cinza):
- Meta página - número da página zero, que contém informações sobre o que está dentro do índice.
- Páginas de intervalo - páginas principais do índice, que armazenam dados como pares "código de hash - TID".
- Páginas excedentes - estruturadas da mesma maneira que as páginas de intervalo e usadas quando uma página é insuficiente para um intervalo.
- Páginas de bitmap - que acompanham as páginas de estouro que estão limpas no momento e podem ser reutilizadas para outros buckets.
As setas para baixo que começam nos elementos da página de índice representam TIDs, ou seja, referências às linhas da tabela.
Cada vez que o índice aumenta, o PostgreSQL cria instantaneamente o dobro de buckets (e, portanto, páginas) que foram criados pela última vez. Para evitar a alocação desse número potencialmente grande de páginas de uma só vez, a versão 10 fez o tamanho aumentar mais suavemente. Quanto às páginas excedentes, elas são alocadas conforme a necessidade e são rastreadas em páginas de bitmap, que também são alocadas conforme a necessidade.
Observe que o índice de hash não pode diminuir de tamanho. Se excluirmos algumas das linhas indexadas, as páginas alocadas não serão retornadas ao sistema operacional, mas serão reutilizadas apenas para novos dados após VACUUMING. A única opção para diminuir o tamanho do índice é reconstruí-lo do zero usando o comando REINDEX ou VACUUM FULL.
Exemplo
Vamos ver como o índice de hash é criado. Para evitar a criação de nossas próprias tabelas, a partir de agora usaremos
o banco de
dados demo de transporte aéreo e, desta vez, consideraremos a tabela de voos.
demo=# create index on flights using hash(flight_no);
WARNING: hash indexes are not WAL-logged and their use is discouraged CREATE INDEX
demo=# explain (costs off) select * from flights where flight_no = 'PG0001';
QUERY PLAN ---------------------------------------------------- Bitmap Heap Scan on flights Recheck Cond: (flight_no = 'PG0001'::bpchar) -> Bitmap Index Scan on flights_flight_no_idx Index Cond: (flight_no = 'PG0001'::bpchar) (4 rows)
O que é inconveniente na implementação atual do índice de hash é que as operações com o índice não são registradas no log write-ahead (do qual o PostgreSQL avisa quando o índice é criado). Em conseqüência, os índices de hash não podem ser recuperados após a falha e não participam de replicações. Além disso, o índice de hash está muito abaixo da "árvore B" em versatilidade, e sua eficiência também é questionável. Portanto, agora é impraticável usar esses índices.
No entanto, isso mudará já neste outono (2017) quando a versão 10 do PostgreSQL for lançada. Nesta versão, o índice de hash finalmente conseguiu suporte para o log write-ahead; Além disso, a alocação de memória foi otimizada e o trabalho simultâneo tornado mais eficiente.
Isso é verdade. Desde o PostgreSQL 10, os índices de hash têm suporte total e podem ser usados sem restrições. O aviso não é mais exibido.
Semântica hash
Mas por que alguma vez o índice de hash sobreviveu quase desde o nascimento do PostgreSQL até o 9.6 ser inutilizável? O fato é que o DBMS faz uso extensivo do algoritmo de hash (especificamente, para junções e agrupamentos de hash), e o sistema deve estar ciente de qual função de hash se aplica a quais tipos de dados. Mas essa correspondência não é estática e não pode ser definida de uma vez por todas, pois o PostgreSQL permite que novos tipos de dados sejam adicionados em tempo real. E este é um método de acesso por hash, onde essa correspondência é armazenada, representada como uma associação de funções auxiliares com famílias de operadores.
demo=# select opf.opfname as opfamily_name, amproc.amproc::regproc AS opfamily_procedure from pg_am am, pg_opfamily opf, pg_amproc amproc where opf.opfmethod = am.oid and amproc.amprocfamily = opf.oid and am.amname = 'hash' order by opfamily_name, opfamily_procedure;
opfamily_name | opfamily_procedure --------------------+-------------------- abstime_ops | hashint4 aclitem_ops | hash_aclitem array_ops | hash_array bool_ops | hashchar ...
Embora essas funções não estejam documentadas, elas podem ser usadas para calcular o código de hash para um valor do tipo de dados apropriado. Por exemplo, a função "hashtext" se usada para a família de operadores "text_ops":
demo=# select hashtext('one');
hashtext ----------- 127722028 (1 row)
demo=# select hashtext('two');
hashtext ----------- 345620034 (1 row)
Propriedades
Vejamos as propriedades do índice de hash, onde esse método de acesso fornece ao sistema informações sobre ele mesmo. Fornecemos consultas da
última vez . Agora não vamos além dos resultados:
name | pg_indexam_has_property ---------------+------------------------- can_order | f can_unique | f can_multi_col | f can_exclude | t name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | t bitmap_scan | t backward_scan | t name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | f returnable | f search_array | f search_nulls | f
Uma função de hash não retém a relação de ordem: se o valor de uma função de hash para uma chave for menor que para a outra, é impossível tirar conclusões sobre como as próprias chaves são ordenadas. Portanto, em geral, o índice de hash pode suportar a única operação "igual":
demo=# select opf.opfname AS opfamily_name, amop.amopopr::regoperator AS opfamily_operator from pg_am am, pg_opfamily opf, pg_amop amop where opf.opfmethod = am.oid and amop.amopfamily = opf.oid and am.amname = 'hash' order by opfamily_name, opfamily_operator;
opfamily_name | opfamily_operator ---------------+---------------------- abstime_ops | =(abstime,abstime) aclitem_ops | =(aclitem,aclitem) array_ops | =(anyarray,anyarray) bool_ops | =(boolean,boolean) ...
Conseqüentemente, o índice de hash não pode retornar dados ordenados ("can_order", "orderable"). O índice de hash não manipula NULLs pelo mesmo motivo: a operação "igual" não faz sentido para NULL ("search_nulls").
Como o índice de hash não armazena chaves (mas apenas seus códigos de hash), ele não pode ser usado para acesso somente ao índice ("retornável").
Este método de acesso também não suporta índices com várias colunas ("can_multi_col").
Internals
A partir da versão 10, será possível procurar internals no índice de hash por meio da extensão "
pageinspect ". É assim que será:
demo=# create extension pageinspect;
A página meta (obtemos o número de linhas no índice e o número máximo de buckets usados):
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',0));
hash_page_type ---------------- metapage (1 row)
demo=# select ntuples, maxbucket from hash_metapage_info(get_raw_page('flights_flight_no_idx',0));
ntuples | maxbucket ---------+----------- 33121 | 127 (1 row)
Uma página de intervalo (obtemos o número de tuplas ativas e mortas, ou seja, aquelas que podem ser aspiradas):
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',1));
hash_page_type ---------------- bucket (1 row)
demo=# select live_items, dead_items from hash_page_stats(get_raw_page('flights_flight_no_idx',1));
live_items | dead_items ------------+------------ 407 | 0 (1 row)
E assim por diante Mas dificilmente é possível descobrir o significado de todos os campos disponíveis sem examinar o código-fonte. Se você deseja fazer isso, comece com
README .
Continue lendo .