Olá, meu nome é Vladislav e sou membro da equipe de desenvolvimento do
Tarantool . Tarantool é um DBMS e um servidor de aplicativos, tudo em um. Hoje vou contar a história de como implementamos a escala horizontal no Tarantool por meio do módulo
VShard .
Algum conhecimento básico primeiro.
Existem dois tipos de escala: horizontal e vertical. E existem dois tipos de dimensionamento horizontal: replicação e sharding. A replicação garante o dimensionamento computacional, enquanto o sharding é usado para o dimensionamento de dados.
O sharding também é subdividido em dois tipos: sharding baseado em intervalo e sharding baseado em hash.
O sharding baseado em intervalo implica que alguma chave de shard é computada para cada registro de cluster. As chaves de fragmentos são projetadas em uma linha reta, separada em intervalos e alocada para diferentes nós físicos.
O sharding baseado em hash é menos complicado: uma função de hash é calculada para cada registro em um cluster; registros com a mesma função de hash são alocados para o mesmo nó físico.
Vou me concentrar no dimensionamento horizontal usando sharding baseado em hash.
Implementação mais antiga
O Tarantool Shard foi nosso módulo original para dimensionamento horizontal. Utilizou sharding simples baseado em hash e calculou chaves shard por chave primária para todos os registros em um cluster.
function shard_function(primary_key) return guava(crc32(primary_key), shard_count) end
Mas, eventualmente, o Tarantool Shard se tornou incapaz de realizar novas tarefas.
Primeiro, um de nossos eventuais requisitos tornou-se a
localidade garantida
de dados relacionados logicamente . Em outras palavras, quando temos dados logicamente relacionados, sempre queremos armazená-los em um único nó físico, independentemente da topologia do cluster e das alterações de balanceamento. O Tarantool Shard não pode garantir isso. Ele calculava hashes apenas com chaves primárias e, portanto, o reequilíbrio poderia causar a separação temporária de registros com o mesmo hash, porque as alterações não são realizadas atomicamente.
Essa falta de localidade dos dados foi o principal problema para nós. Aqui está um exemplo. Digamos que exista um banco em que um cliente tenha aberto uma conta. As informações sobre a conta e o cliente devem ser armazenadas fisicamente juntas para que possam ser recuperadas em uma única solicitação ou alteradas em uma única transação, por exemplo, durante uma transferência de dinheiro. Se usarmos o sharding tradicional do Tarantool Shard, haverá diferentes valores de função de hash para contas e clientes. Os dados podem acabar em nós físicos separados. Isso realmente complica a leitura e a transação com os dados de um cliente.
format = {{'id', 'unsigned'}, {'email', 'string'}} box.schema.create_space('customer', {format = format}) format = {{'id', 'unsigned'}, {'customer_id', 'unsigned'}, {'balance', 'number'}} box.schema.create_space('account', {format = format})
No exemplo acima, os campos de identificação das contas e do cliente podem ser inconsistentes. Eles são conectados pelo campo customer_id da conta e pelo campo id do cliente. O mesmo campo de ID violaria a restrição de exclusividade da chave primária da conta. E o Shard não pode realizar sharding de nenhuma outra maneira.
Outro problema foi
o compartilhamento compartilhado lento , que é o problema fundamental de todos os shards de hash. A conclusão é que, ao alterar os componentes do cluster, a função shard muda porque geralmente depende do número de nós. Portanto, quando a função muda, é necessário passar por todos os registros no cluster e recalcular a função. Também pode ser necessário transferir alguns registros. E durante a transferência de dados, nem sabemos se o registro necessário? Na solicitação, os dados já foram transferidos ou estão sendo transferidos no momento. Assim, durante o novo compartilhamento, é necessário fazer solicitações de leitura com as funções de shard antigas e novas. As solicitações são tratadas duas vezes mais devagar, e isso é inaceitável.
Outro problema com o Tarantool Shard foi a baixa disponibilidade de leituras no caso de falha do nó em um conjunto de réplicas.
Nova solução
Criamos o
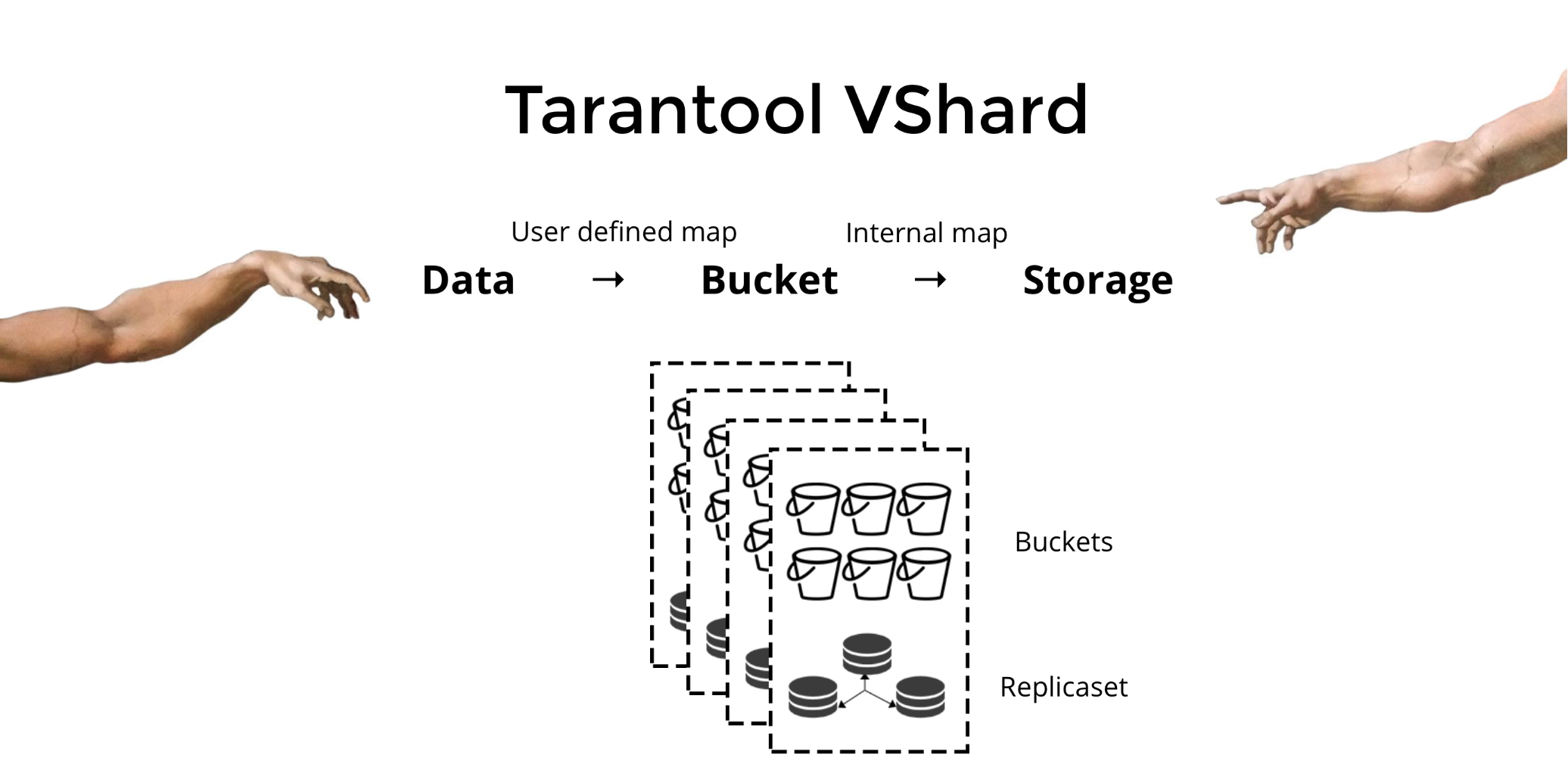
Tarantool VShard para resolver os três problemas mencionados acima. Sua principal diferença é que seu nível de armazenamento de dados é virtualizado, ou seja, os armazenamentos físicos hospedam os armazenamentos virtuais e os registros de dados são alocados pelos virtuais. Esses armazenamentos são chamados de
baldes . O usuário não precisa se preocupar com o que está localizado em um determinado nó físico. Um balde é uma unidade de dados indivisível atômica, como uma tupla no sharding tradicional. O VShard sempre armazena um depósito inteiro em um nó físico e, durante o novo compartilhamento, migra todos os dados de um depósito atomicamente. Este método garante a localização dos dados. Apenas colocamos os dados em um único balde e sempre podemos ter certeza de que eles não serão separados durante as alterações do cluster.

Como colocamos dados em um balde? Vamos adicionar um novo campo de ID do depósito à tabela para nosso cliente bancário. Se esse valor do campo for o mesmo para dados relacionados, todos os registros estarão em um intervalo. A vantagem é que podemos armazenar registros com o mesmo ID de bucket em espaços diferentes e até em mecanismos diferentes. A localidade dos dados com base no ID do bucket é garantida, independentemente do método de armazenamento.
format = {{'id', 'unsigned'}, {'email', 'string'}, {'bucket_id', 'unsigned'}} box.schema.create_space('customer', {format = format}) format = {{'id', 'unsigned'}, {'customer_id', 'unsigned'}, {'balance', 'number'}, {'bucket_id', 'unsigned'}} box.schema.create_space('account', {format = format})
Por que isso é tão importante? Ao usar o sharding tradicional, os dados estendem-se a vários armazenamentos físicos existentes. Para o nosso exemplo bancário, teríamos que entrar em contato com cada nó ao solicitar todas as contas para um determinado cliente. Portanto, obtemos uma complexidade de leitura O (N), onde N é o número de armazenamentos físicos. É assustadoramente lento.
O uso de buckets e a localidade pelo ID do bucket tornam possível ler os dados necessários de um nó usando uma solicitação - independentemente do tamanho do cluster.

No VShard, você calcula seu ID de bucket e o atribui. Para algumas pessoas, isso é uma vantagem, enquanto outros a consideram uma desvantagem. Acredito que a capacidade de escolher sua própria função para o cálculo da identificação do bucket seja uma vantagem.
Qual é a principal diferença entre o sharding tradicional e o sharding virtual com buckets?
No primeiro caso, quando alteramos os componentes do cluster, temos dois estados: o atual (antigo) e o novo a ser implementado. No processo de transição, é necessário não apenas migrar dados, mas também recalcular a função de hash para cada registro. Isso não é muito conveniente, porque em um dado momento não sabemos se os dados necessários já foram migrados ou não. Além disso, esse método não é confiável e as alterações não são atômicas, pois a migração atômica do conjunto de registros com o mesmo valor de função de hash exigiria um armazenamento persistente do estado de migração, caso a recuperação fosse necessária. Como resultado, existem conflitos e erros, e a operação deve ser reiniciada várias vezes.
O sharding virtual é muito mais simples. Não temos dois estados de cluster diferentes; nós só temos estado de bucket. O cluster é mais flexível, move-se suavemente de um estado para outro. Existem mais de dois estados agora? (claro). Com a transição suave, é possível alterar o balanceamento em tempo real ou remover os novos armazenamentos adicionados. Ou seja, o controle de balanceamento aumentou bastante e se tornou mais granular.
Uso
Digamos que selecionamos uma função para nosso ID de bucket e carregamos tantos dados no cluster que não resta espaço. Agora, gostaríamos de adicionar alguns nós e mover dados automaticamente para eles. É assim que fazemos no VShard: primeiro, começamos novos nós e rodamos o Tarantool lá, depois atualizamos nossa configuração do VShard. Ele contém informações sobre todos os componentes do cluster, todas as réplicas, conjuntos de réplicas, mestres, URIs atribuídos e muito mais. Agora, adicionamos nossos novos nós ao arquivo de configuração e aplicamos a todos os nós do cluster usando VShard.storage.cfg.
function create_user(email) local customer_id = next_id() local bucket_id = crc32(customer_id) box.space.customer:insert(customer_id, email, bucket_id) end function add_account(customer_id) local id = next_id() local bucket_id = crc32(customer_id) box.space.account:insert(id, customer_id, 0, bucket_id) end
Como você deve se lembrar, ao alterar o número de nós no sharding tradicional, a própria função shard também muda. Isso não acontece no VShard. Aqui temos um número fixo de armazenamentos virtuais, ou buckets. Essa é uma constante que você escolhe ao iniciar o cluster. Pode parecer que a escalabilidade esteja restrita, mas na verdade não é. Você pode especificar um grande número de baldes, dezenas e centenas de milhares. O importante é saber que deve haver pelo menos duas ordens de magnitude a mais do que o número máximo de conjuntos de réplicas que você jamais terá no cluster.
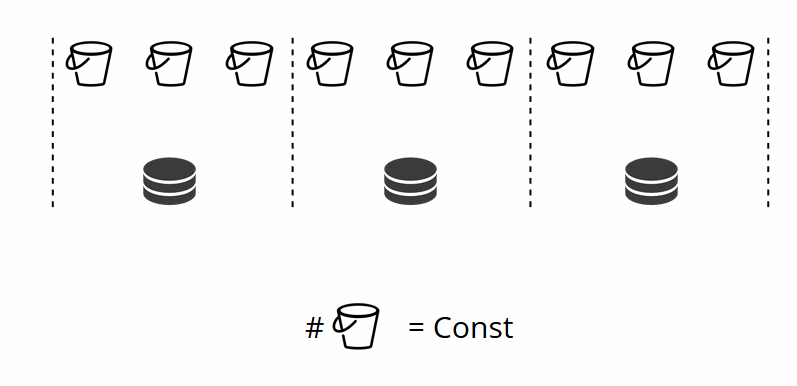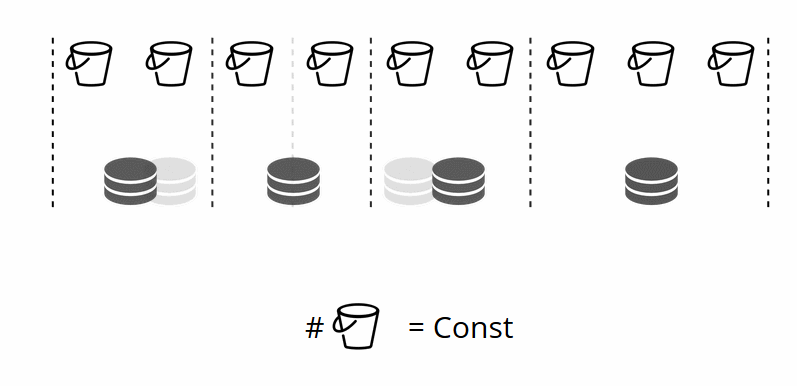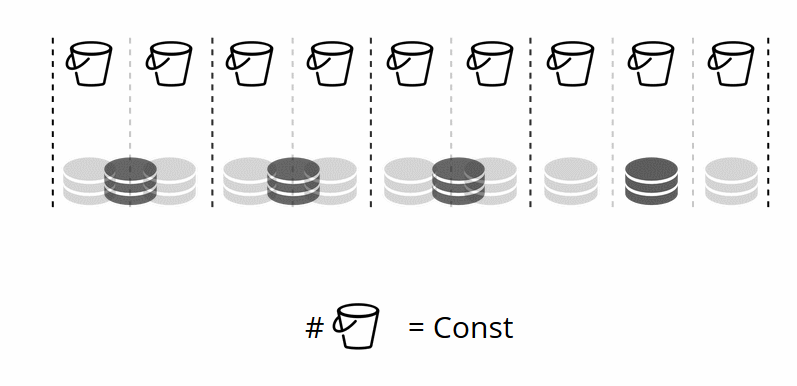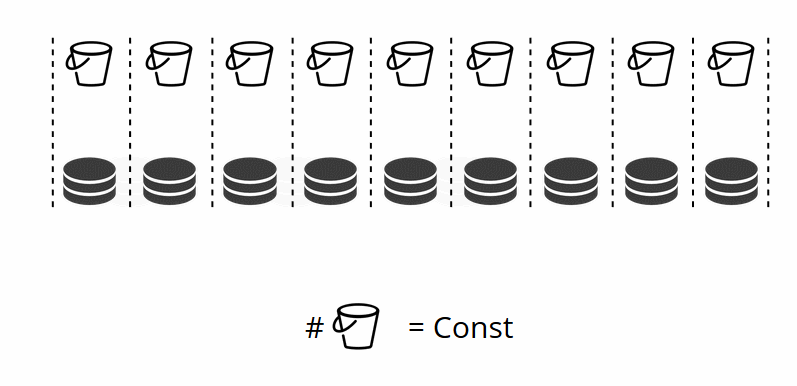
Como o número de armazenamentos virtuais não muda e a função shard depende apenas desse valor, podemos adicionar quantos armazenamentos físicos desejarmos sem recalcular a função shard.
Então, como os baldes são alocados para armazenamentos físicos? Se VShard.storage.cfg for chamado, um processo de rebalanceador será ativado em um dos nós. Este é um processo analítico que calcula o equilíbrio perfeito para o cluster. O processo vai para cada nó físico e recupera seu número de buckets e cria rotas de seus movimentos para equilibrar a alocação. Em seguida, o rebalanceador envia as rotas para os armazenamentos sobrecarregados, que por sua vez começam a enviar baldes. Um pouco mais tarde, o cluster está equilibrado.
Em projetos do mundo real, um equilíbrio perfeito pode não ser alcançado com tanta facilidade. Por exemplo, um conjunto de réplicas pode conter menos dados que o outro porque possui menos capacidade de armazenamento. Nesse caso, o VShard pode pensar que tudo está equilibrado, mas na verdade o primeiro armazenamento está prestes a sobrecarregar. Para combater isso, fornecemos um mecanismo para corrigir as regras de balanceamento por meio de pesos. Um peso pode ser atribuído a qualquer conjunto de réplicas ou armazenamento. Quando o rebalanceador decide quantos baldes devem ser enviados e para onde, considera os
relacionamentos de todos os pares de pesos.
Por exemplo, se um armazenamento pesa 100 e o outro 200, o segundo armazenará duas vezes mais baldes do que o primeiro. Observe que estou falando especificamente sobre
relacionamentos de peso. Valores absolutos não têm nenhuma influência. Você escolhe pesos com base na distribuição de 100% em um cluster: portanto, 30% para um armazenamento renderia 70% para o outro. Você pode considerar a capacidade de armazenamento em gigabytes ou medir o peso no número de buckets. O mais importante é manter a proporção necessária.

Esse método tem um efeito colateral interessante: se um peso zero for atribuído a um armazenamento, o rebalanceador fará esse armazenamento redistribuir todos os seus buckets. Depois disso, você pode remover todo o conjunto de réplicas da configuração.
Migração de bucket atômica
Nós temos um balde; ele aceita algumas leituras e gravações e, em um determinado momento, o rebalanceador solicita sua migração para outro armazenamento. O bucket deixa de aceitar solicitações de gravação, caso contrário, ele seria atualizado durante a migração, depois atualizado novamente durante a migração da atualização, a atualização seria atualizada e assim por diante. Portanto, as solicitações de gravação são bloqueadas, mas a leitura do depósito ainda é possível. Os dados agora estão sendo migrados para o novo local. Quando a migração é concluída, o bucket começa a aceitar solicitações novamente. Ainda existe no local antigo, mas está marcado como lixo e, posteriormente, o coletor de lixo o exclui peça por peça.
Existem alguns metadados armazenados fisicamente no disco associado a cada bloco. Todas as etapas descritas acima são armazenadas no disco e, não importa o que aconteça com o armazenamento, o estado do bucket será restaurado automaticamente.
Você pode ter algumas das seguintes perguntas:
- O que acontece com as solicitações que estão trabalhando com o bucket quando a migração é iniciada?
Existem dois tipos de referências nos metadados de cada bloco: RO e RW. Quando um usuário faz uma solicitação para um bucket, ele indica se o trabalho deve estar no modo somente leitura ou no modo leitura / gravação. Para cada solicitação, o contador de referência correspondente é aumentado.
Por que precisamos de contadores de referência para solicitações de gravação? Digamos que um balde esteja sendo migrado e, de repente, o coletor de lixo deseja excluí-lo. O coletor de lixo reconhece que o contador de referência está acima de zero e, portanto, o balde não será excluído. Quando todas as solicitações são concluídas, o coletor de lixo pode fazer seu trabalho.
O contador de referência para gravações também garante que a migração do bucket não seja iniciada se houver pelo menos uma solicitação de gravação em processo. Porém, novamente, as solicitações de gravação podem ser recebidas uma após a outra, e o bucket nunca será migrado. Portanto, se o rebalanceador desejar mover o bucket, o sistema bloqueará novas solicitações de gravação enquanto aguarda a conclusão das solicitações atuais durante um determinado período de tempo limite. Se as solicitações não forem concluídas dentro do tempo limite especificado, o sistema começará a aceitar novas solicitações de gravação novamente ao adiar a migração do bucket. Dessa forma, o rebalanceador tentará migrar o bucket até que a migração seja bem-sucedida.
O VShard possui uma API bucket_ref de baixo nível, caso você precise mais do que apenas recursos de alto nível. Se você realmente deseja fazer alguma coisa, consulte esta API. - É possível deixar os registros desbloqueados?
Não. Se o bucket contiver dados críticos e exigir acesso permanente de gravação, você deverá bloquear completamente sua migração. Temos uma função bucket_pin para fazer exatamente isso. Ele fixa o balde ao conjunto de réplicas atual para que o rebalanceador não possa migrar o balde. Nesse caso, os buckets adjacentes poderão se mover sem restrições.

Um bloqueio de conjunto de réplicas é uma ferramenta ainda mais forte que o bucket_pin. Isso não é mais feito no código, mas na configuração. Um bloqueio do conjunto de réplicas desativa a migração de qualquer intervalo de entrada / saída do conjunto de réplicas. Portanto, todos os dados estarão permanentemente disponíveis para gravações.

VShard.router
O VShard consiste em dois submódulos: VShard.storage e VShard.router. Podemos criar e dimensionar esses itens independentemente em uma única instância. Ao solicitar um cluster, não sabemos onde um determinado depósito está localizado, e o VShard.router pesquisará por ID do depósito.
Vamos olhar para o nosso exemplo, o cluster bancário com contas de clientes. Gostaria de poder obter todas as contas de um determinado cliente do cluster. Isso requer uma função padrão para pesquisa local:

Ele procura todas as contas do cliente por seu ID. Agora tenho que decidir onde devo executar a função. Para esse propósito, calculo o ID do bucket pelo identificador do cliente em minha solicitação e solicito ao VShard.router para chamar a função no armazenamento em que o bucket com o ID do bucket de destino está localizado. O submódulo possui uma tabela de roteamento que descreve os locais dos buckets nos conjuntos de réplicas. O VShard.router redireciona minha solicitação.
Certamente pode acontecer que o sharding comece nesse exato momento e que os baldes comecem a se mover. O roteador em segundo plano atualiza gradualmente a tabela em grandes partes solicitando as tabelas de bucket atuais dos armazenamentos.
Podemos até solicitar um bucket migrado recentemente, pelo qual o roteador ainda não atualizou sua tabela de roteamento. Nesse caso, ele solicitará o armazenamento antigo, que redirecionará o roteador para outro armazenamento ou responderá simplesmente que não possui os dados necessários. Em seguida, o roteador passará por cada armazenamento em busca do balde necessário. E nem perceberemos um erro na tabela de roteamento.
Ler failover
Vamos relembrar nossos problemas iniciais:
- Sem localidade de dados. Resolvido por meio de baldes.
- Processo de re-compartilhamento atolando e retendo tudo. Implementamos a transferência de dados atômicos por meio de baldes e nos livramos do recálculo da função shard.
- Leia o failover.
O último problema foi solucionado pelo VShard.router, suportado pelo subsistema de failover de leitura automática.
De tempos em tempos, o roteador faz ping nos armazenamentos especificados na configuração. Digamos, por exemplo, o roteador não pode executar ping em um deles. O roteador tem uma conexão de backup quente para cada réplica; portanto, se a réplica atual não estiver respondendo, ela apenas alterna para outra. As solicitações de leitura serão processadas normalmente porque podemos ler as réplicas (mas não gravar). E podemos especificar a prioridade das réplicas como um fator para o roteador escolher o failover para leituras. Isso é feito por meio de zoneamento.

Atribuímos um número de zona a cada réplica e a cada roteador e especificamos uma tabela na qual indicamos a distância entre cada par de zonas. Quando o roteador decide para onde deve enviar uma solicitação de leitura, ele seleciona uma réplica na zona mais próxima.
Isto é o que parece na configuração:

Geralmente, você pode solicitar qualquer réplica, mas se o cluster for grande, complexo e altamente distribuído, o zoneamento poderá ser muito útil. Racks de servidor diferentes podem ser selecionados como zonas para que a rede não seja sobrecarregada pelo tráfego. Como alternativa, pontos geograficamente isolados podem ser selecionados.
O zoneamento também ajuda quando as réplicas demonstram comportamentos diferentes. Por exemplo, cada conjunto de réplicas possui uma réplica de backup que não deve aceitar solicitações, mas deve armazenar apenas uma cópia dos dados. Nesse caso, a colocamos em uma zona distante de todos os roteadores da tabela, para que o roteador não endereça essa réplica, a menos que seja absolutamente necessário.
Failover de gravação
Já falamos sobre failover de leitura. E o failover de gravação ao alterar o mestre? No VShard, a imagem não é tão otimista quanto era antes: a seleção principal não é implementada, portanto teremos que fazer isso sozinhos. Quando de alguma forma designamos um mestre, a instância designada deve agora assumir o controle de mestre. Em seguida, atualizamos a configuração especificando master = false para o antigo mestre e master = true para o novo, aplicamos a configuração por meio do VShard.storage.cfg e as compartilhamos com cada armazenamento. Tudo o resto é feito automaticamente. O mestre antigo para de aceitar solicitações de gravação e inicia a sincronização com o novo, porque pode haver dados que já foram aplicados no mestre antigo, mas não no novo. Depois disso, o novo mestre é responsável e começa a aceitar solicitações, e o antigo mestre é uma réplica. É assim que o failover de gravação funciona no VShard.
replicas = new_cfg.sharding[uud].replicas replicas[old_master_uuid].master = false replicas[new_master_uuid].master = true vshard.storage.cfg(new_cfg)
Como rastreamos esses vários eventos?
VShard.storage.info e VShard.router.info são suficientes.
VShard.storage.info exibe informações em várias seções.
vshard.storage.info() --- - replicasets: <replicaset_2>: uuid: <replicaset_2> master: uri: storage@127.0.0.1:3303 <replicaset_1>: uuid: <replicaset_1> master: missing bucket: receiving: 0 active: 0 total: 0 garbage: 0 pinned: 0 sending: 0 status: 2 replication: status: slave Alerts: - ['MISSING_MASTER', 'Master is not configured for ''replicaset <replicaset_1>']
A primeira seção é para replicação. Aqui você pode ver o status do conjunto de réplicas em que a função está sendo chamada: seu atraso de replicação, suas conexões disponíveis e indisponíveis, sua configuração principal etc.
Na seção bucket, você pode ver em tempo real o número de buckets que estão sendo migrados para / do conjunto de réplicas atual, o número de buckets trabalhando no modo regular, o número de buckets marcados como lixo e o número de buckets fixados.
A seção Alertas exibe os problemas que o VShard conseguiu determinar: "o mestre não está configurado", "há um nível de redundância insuficiente", "o mestre está lá, mas todas as réplicas falharam" etc.
E a última seção (q: é esse "status"?) É uma luz que fica vermelha quando tudo dá errado. É um número de zero a três, pelo qual um número maior é pior.
VShard.router.info possui as mesmas seções, mas seu significado é um pouco diferente.
vshard.router.info() --- - replicasets: <replicaset_2>: replica: &0 status: available uri: storage@127.0.0.1:3303 uuid: 1e02ae8a-afc0-4e91-ba34-843a356b8ed7 bucket: available_rw: 500 uuid: <replicaset_2> master: *0 <replicaset_1>: replica: &1 status: available uri: storage@127.0.0.1:3301 uuid: 8a274925-a26d-47fc-9e1b-af88ce939412 bucket: available_rw: 400 uuid: <replicaset_1> master: *1 bucket: unreachable: 0 available_ro: 800 unknown: 200 available_rw: 700 status: 1 alerts: - ['UNKNOWN_BUCKETS', '200 buckets are not discovered']
A primeira seção é para replicação, embora não contenha informações sobre atrasos na replicação, mas informações sobre disponibilidade: conexões do roteador a um conjunto de réplicas; conexão quente e conexão de backup caso o mestre falhe; o mestre selecionado; e o número de caçambas RW e RO disponíveis em cada conjunto de réplicas.
A seção bucket exibe o número total de buckets de leitura e gravação e somente leitura atualmente disponíveis para este roteador; o número de baldes com um local desconhecido; e o número de buckets com um local conhecido, mas sem uma conexão com o conjunto de réplicas necessário.
A seção de alertas descreve principalmente conexões, eventos de failover e buckets não identificados.
Finalmente, há também o status simples? Indicador de zero a três.
O que você precisa para usar o VShard?
Primeiro, você deve selecionar um número constante de buckets. Por que não apenas configurá-lo para int32_max? Como os metadados são armazenados junto com cada intervalo, 30 bytes no armazenamento e 16 bytes no roteador. Quanto mais baldes você tiver, mais espaço será ocupado pelos metadados. Mas, ao mesmo tempo, o tamanho do bucket será menor, o que significa maior granularidade do cluster e maior velocidade de migração por bucket. Portanto, você deve escolher o que é mais importante para você e o nível de escalabilidade necessário.
Segundo, você precisa selecionar uma função de fragmento para calcular a identificação do intervalo. As regras são as mesmas que ao selecionar uma função de fragmento no sharding tradicional, já que um bucket aqui é igual ao número fixo de armazenamentos no sharding tradicional. A função deve distribuir uniformemente os valores de saída, caso contrário, o crescimento do tamanho do balde não será equilibrado, e o VShard opera apenas com o número de baldes. Se você não equilibrar sua função de shard, será necessário migrar os dados de um bucket para outro e alterar a função de shard. Assim, você deve escolher com cuidado.
Sumário
O VShard garante:
- localidade dos dados
- compartilhamento atômico
- maior flexibilidade de cluster
- failover de leitura automática
- vários controladores de balde.
VShard está em desenvolvimento ativo. Algumas tarefas planejadas já estão sendo implementadas. A primeira tarefa é
o balanceamento de carga do roteador . Se houver solicitações de leitura intensas, nem sempre é recomendável endereçá-las ao mestre. O roteador deve equilibrar solicitações para diferentes réplicas de leitura por conta própria.
A segunda tarefa é a
migração de bucket sem bloqueio . Um algoritmo já foi implementado que ajuda a manter os buckets desbloqueados, mesmo durante a migração. O bucket será bloqueado apenas no final para documentar a própria migração.
A terceira tarefa é
a aplicação atômica da configuração . Não é conveniente ou atômico aplicar a configuração separadamente, pois algum armazenamento pode estar indisponível e, se a configuração não for aplicada, o que faremos a seguir? É por isso que estamos trabalhando em um mecanismo para transferência automática de configuração.