
Ao diagnosticar problemas em um cluster Kubernetes, geralmente observamos que algumas vezes um dos nós do cluster chove * e, é claro, isso é raro e estranho. Portanto, chegamos à necessidade de uma ferramenta que faça
ping de cada nó para cada nó e apresente os resultados de seu trabalho na forma
de métricas do Prometheus . Teríamos apenas que desenhar gráficos no Grafana e localizar rapidamente o nó com falha (e, se necessário, remover todos os pods dele e, em seguida, fazer o trabalho correspondente **) ...
* Por "chuvisco", entendo que o nó pode entrar no status NotReady e retornar repentinamente ao trabalho. Ou, por exemplo, parte do tráfego nos pods pode não alcançar os pods nos nós vizinhos.** Por que essas situações surgem? Uma das causas comuns pode ser problemas de rede no comutador no data center. Por exemplo, uma vez na Hetzner, configuramos o vswitch, mas em um momento maravilhoso um dos nós deixou de estar acessível nessa porta vswitch: por causa disso, verificou-se que o nó estava completamente inacessível na rede local.Além disso, gostaríamos de
lançar esse serviço diretamente no Kubernetes , para que toda a implantação ocorra usando a instalação do Helm-chart. (Antecipando perguntas - se usássemos o mesmo Ansible, teríamos que escrever funções para vários ambientes: AWS, GCE, bare metal ...) Depois de pesquisar um pouco na Internet por ferramentas prontas para a tarefa, não encontramos nada adequado. Portanto, eles fizeram os seus próprios.
Script e configurações
Portanto, o principal componente de nossa solução é um
script que monitora a alteração em qualquer nó do campo
.status.addresses e, se um nó alterou esse campo (ou seja, um novo nó foi adicionado), envia valores Helm para o gráfico usando esta lista de nós no formato do ConfigMap:
--- apiVersion: v1 kind: ConfigMap metadata: name: node-ping-config namespace: kube-prometheus data: nodes.json: > {{ .Values.nodePing.nodes | toJson }}
Ele
é executado em cada nó e envia pacotes ICMP para todas as outras instâncias do cluster Kubernetes 2 vezes por segundo, e os resultados são gravados nos arquivos de texto.
O script está incluído na
imagem do
Docker :
FROM python:3.6-alpine3.8 COPY rootfs / WORKDIR /app RUN pip3 install --upgrade pip && pip3 install -r requirements.txt && apk add --no-cache fping ENTRYPOINT ["python3", "/app/node-ping.py"]
Além disso, uma
ServiceAccount foi criada e uma função para ela, que permite que apenas uma lista de nós seja recebida (para conhecer seus endereços):
--- apiVersion: v1 kind: ServiceAccount metadata: name: node-ping namespace: kube-prometheus --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: kube-prometheus:node-ping rules: - apiGroups: [""] resources: ["nodes"] verbs: ["list"] --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: kube-prometheus:kube-node-ping subjects: - kind: ServiceAccount name: node-ping namespace: kube-prometheus roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: kube-prometheus:node-ping
Por fim, você precisa do
DaemonSet , que é executado em todas as instâncias do cluster:
--- apiVersion: extensions/v1beta1 kind: DaemonSet metadata: name: node-ping namespace: kube-prometheus labels: tier: monitoring app: node-ping version: v1 spec: updateStrategy: type: RollingUpdate template: metadata: labels: name: node-ping spec: terminationGracePeriodSeconds: 0 tolerations: - operator: "Exists" serviceAccountName: node-ping priorityClassName: cluster-low containers: - resources: requests: cpu: 0.10 image: private-registry.flant.com/node-ping/node-ping-exporter:v1 imagePullPolicy: Always name: node-ping env: - name: MY_NODE_NAME valueFrom: fieldRef: fieldPath: spec.nodeName - name: PROMETHEUS_TEXTFILE_DIR value: /node-exporter-textfile/ - name: PROMETHEUS_TEXTFILE_PREFIX value: node-ping_ volumeMounts: - name: textfile mountPath: /node-exporter-textfile - name: config mountPath: /config volumes: - name: textfile hostPath: path: /var/run/node-exporter-textfile - name: config configMap: name: node-ping-config imagePullSecrets: - name: antiopa-registry
Resumo de traços em palavras:
- Resultados do script Python - ou seja, os arquivos de texto colocados na máquina host no diretório
/var/run/node-exporter-textfile textfile entram no DaemonSet node-exportador. Os argumentos para executá-lo indicam --collector.textfile.directory /host/textfile , em que /host/textfile é o hostPath em /var/run/node-exporter-textfile . (Você pode ler sobre o coletor de arquivos de texto no nó-exportador aqui .) - Como resultado, o nó-exportador lê esses arquivos e o Prometheus coleta todos os dados do nó-exportador.
O que aconteceu?
Agora - para o tão esperado resultado. Quando essas métricas foram criadas, podemos examiná-las e, é claro, desenhar gráficos visuais. É assim que parece.
Primeiramente, existe um bloco geral com a capacidade (usando o seletor) de selecionar uma lista de nós a
partir dos quais o ping é executado e
em qual. Esta é a
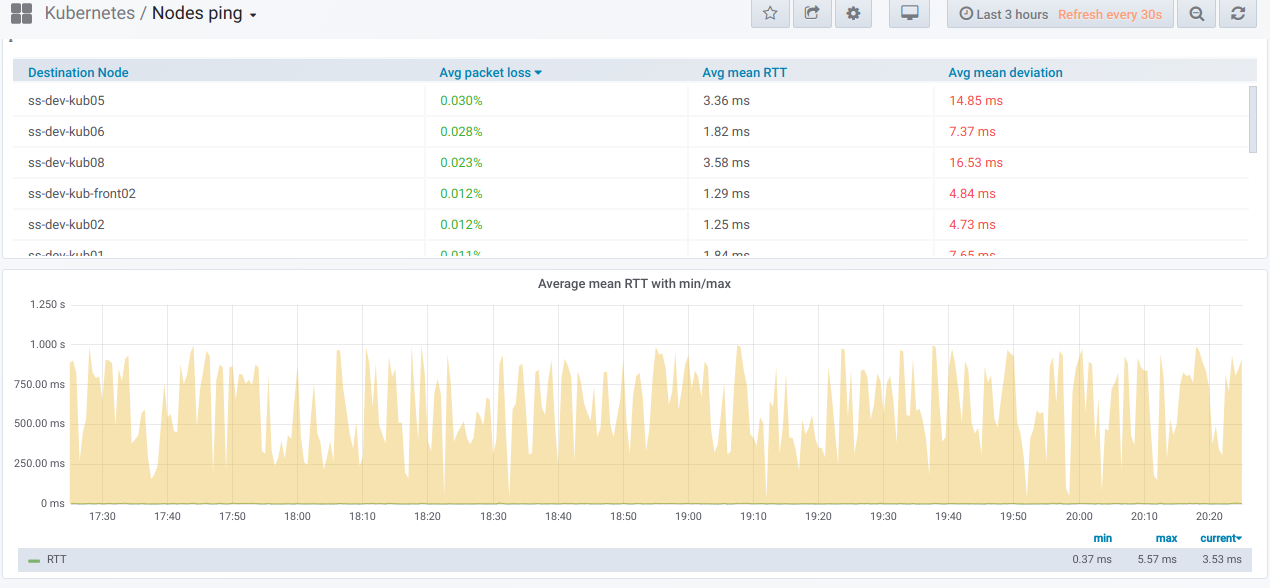
tabela de resumo para o ping entre os nós selecionados para o período especificado no painel Grafana:
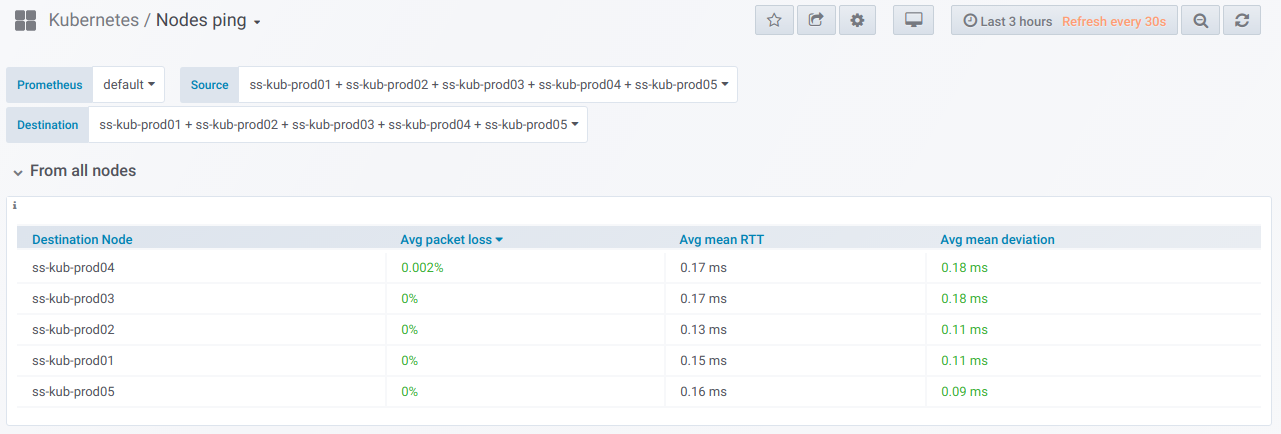
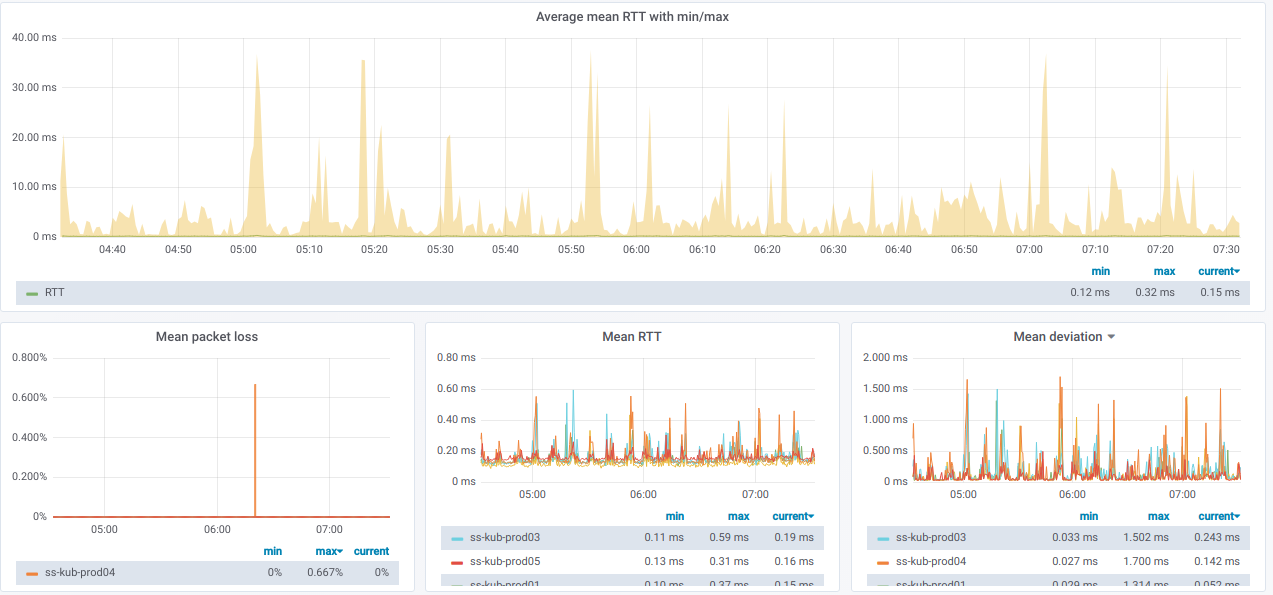
E aqui estão os gráficos com informações gerais
sobre os nós selecionados :
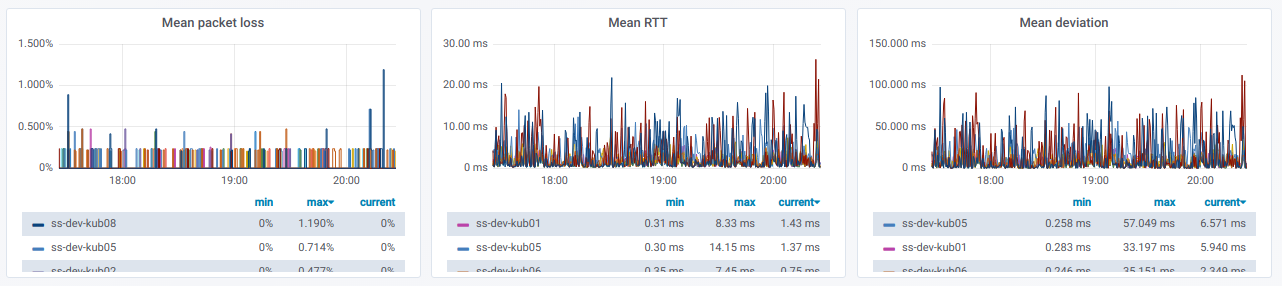
Também temos uma lista de linhas, cada uma das quais é um gráfico
para um nó separado do seletor do
nó de origem :

Se você expandir essa linha, poderá ver informações sobre pings
de um nó específico para todos os outros que foram selecionados no seletor de
Nós de destino :
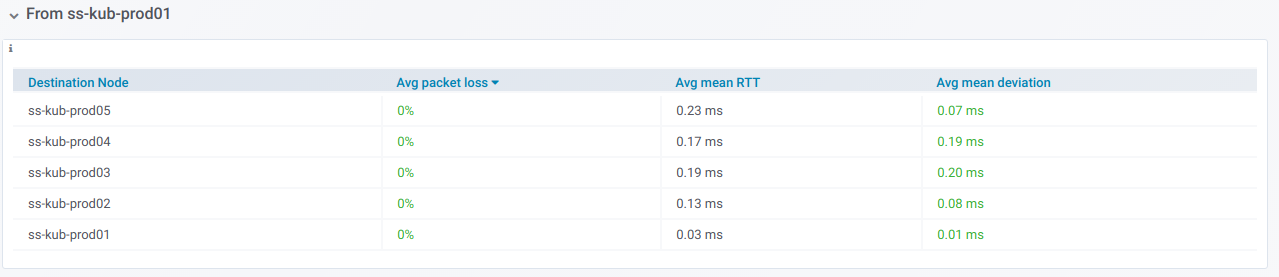
Esta informação está em gráficos:
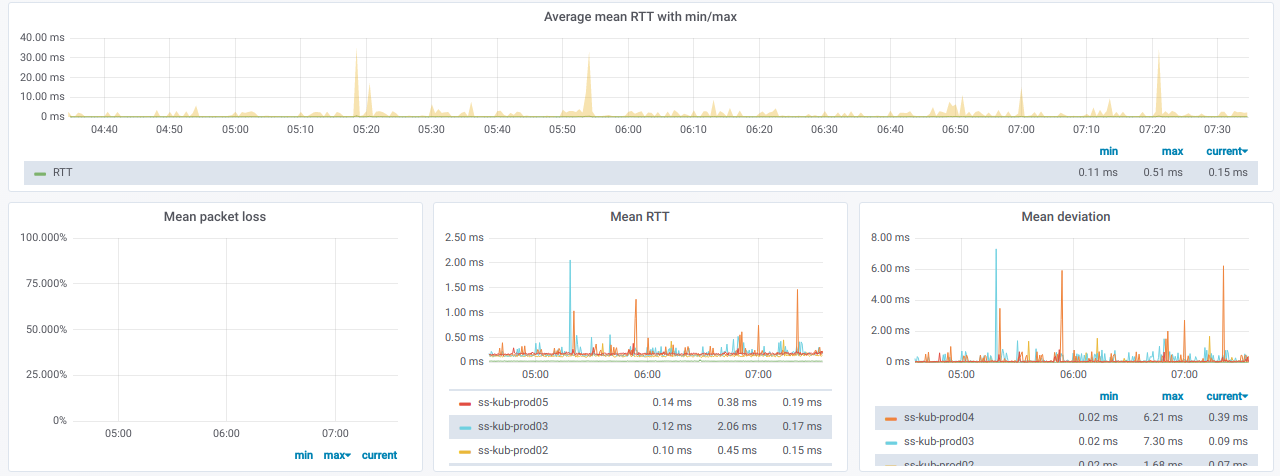
Finalmente, como serão os gráficos estimados com ping baixo entre os nós?
Se você observar isso em um ambiente real - é hora de descobrir os motivos.
PS
Leia também em nosso blog: