
Muitos clientes que alugam recursos da nuvem usam o Check Points virtual. Com a ajuda deles, os clientes resolvem vários problemas: alguém controla o acesso do segmento de servidores à Internet ou publica seus serviços para nossos equipamentos. Alguém precisa executar todo o tráfego através do blade IPS, enquanto alguém precisa do Check Point como um gateway VPN para acessar recursos internos no data center a partir das filiais. Há quem precise proteger sua infraestrutura na nuvem para passar na certificação de acordo com o FZ-152, mas vou falar sobre isso separadamente.
Em serviço, estou envolvido no suporte e na administração de pontos de verificação. Hoje vou dizer o que você deve considerar ao implantar um cluster de pontos de verificação em um ambiente virtual. Vou abordar momentos do nível de virtualização, rede, configurações do próprio Check Point e monitoramento.
Não prometo descobrir a América - muito está nas recomendações e nas melhores práticas do fornecedor. Mas ninguém os lê), então eles dirigiram.
Modo de cluster
Temos Check Points ao vivo em clusters. A instalação mais comum é um cluster de dois nós no modo de espera ativa. Se algo acontecer com o nó ativo, ele se tornará inativo e o nó em espera será ativado. A mudança para um nó "sobressalente" geralmente ocorre devido a problemas na sincronização entre membros do cluster, o estado das interfaces, a política de segurança estabelecida, simplesmente por causa de uma carga pesada no equipamento.
Em um cluster de dois nós, não usamos o modo ativo-ativo.
Se um dos nós cair, o nó sobrevivente pode simplesmente não ser capaz de suportar a carga dupla e perderemos tudo. Se você realmente deseja ativo-ativo, o cluster deve ter pelo menos 3 nós.
Configurações de rede e virtualização
O tráfego multicast entre as interfaces SYNC dos membros do cluster é permitido no equipamento de rede. Se o tráfego multicast não for possível, o protocolo de sincronização (CCP) será usado na transmissão. Os nós no cluster do Check Point são sincronizados entre si. Mensagens sobre alterações são transmitidas de nó para nó por multicast. O Check Point usa uma implementação multicast não padrão (um endereço IP não multicast é usado). Por esse motivo, alguns equipamentos, como o switch Cisco Nexus, não entendem essas mensagens e, portanto, as bloqueiam. Nesse caso, mude para transmissão.
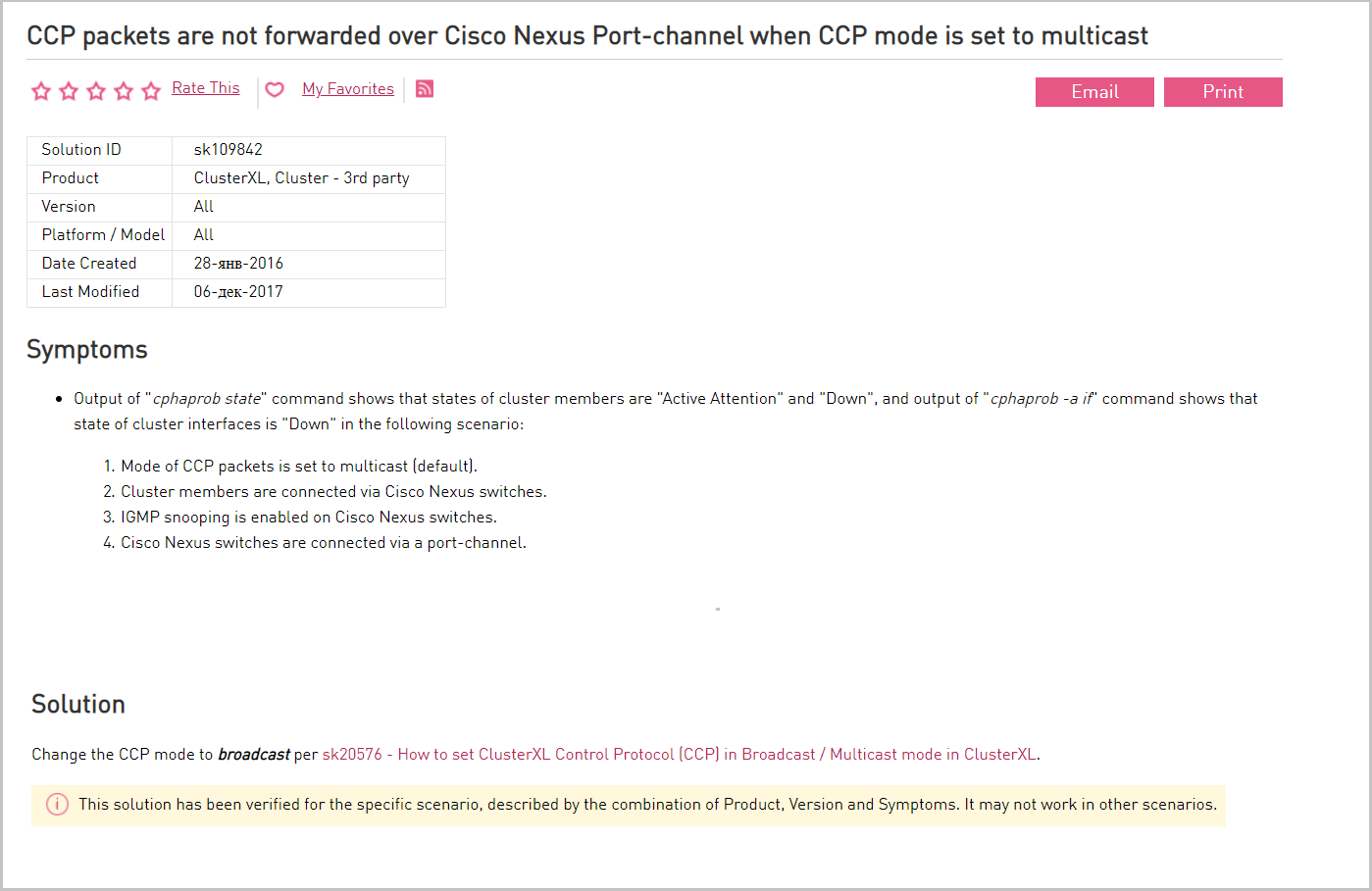 Descrição do problema com o Cisco Nexus e suas soluções no portal do fornecedor.
Descrição do problema com o Cisco Nexus e suas soluções no portal do fornecedor.No nível da virtualização, também permitimos a passagem de tráfego multicast. Se o multicast for proibido para sincronização de cluster (CCP), use a difusão.
No console do Check Point, usando o comando cphaprob -a if, é possível ver as configurações do CPP e seu modo operacional (multicast ou broadcast). Para alterar o modo de operação, use o comando cphaconf set_ccp broadcast.
 Os nós de cluster devem estar em diferentes hosts ESXi.
Os nós de cluster devem estar em diferentes hosts ESXi. Tudo está claro aqui: quando o host físico cai, o segundo nó continua a funcionar. Isso pode ser conseguido usando regras de anti-afinidade DRS.
Dimensões da máquina virtual na qual o Check Point será executado. As recomendações do fornecedor são 2 vCPUs e 6 GB, mas isso é para uma configuração mínima, por exemplo, se você tiver um firewall com largura de banda mínima. Em nossa experiência de implementação, ao usar vários blades de software, é recomendável usar pelo menos 4 vCPUs, 8 GB de RAM.
Em um nó, alocamos uma média de 150 GB de disco. Ao implantar um ponto de verificação virtual, o disco é particionado e podemos ajustar quanto espaço é alocado para troca do sistema, raiz do sistema, logs, backup e atualização.
Ao aumentar a raiz do sistema, a partição de backup e atualização também precisa ser aumentada para manter a proporção entre elas. Se a proporção não for respeitada, o próximo backup poderá não caber no disco.
Provisionamento de disco - Provisão espessa Lazy Zeroed. O Check Point gera muitos eventos e logs, a cada segundo 1000 entradas são exibidas. Sob eles, é melhor reservar um lugar imediatamente. Para fazer isso, ao criar uma máquina virtual, alocamos um disco para ela usando a tecnologia Thick Provisioning, ou seja, reservamos espaço no armazenamento físico no momento da criação do disco.
Reserva de recurso 100% configurada para o Check Point durante a migração entre hosts ESXi. Recomendamos que você reserve 100% dos recursos para que a máquina virtual na qual o Check Point está implantado não concorra por recursos com outras VMs no host.
Misc. Usamos a versão Check Point do R77.30. Para isso, é recomendável usar o RedHat Enterprise Linux versão 5 (64 bits) como um SO convidado em uma máquina virtual. De drivers de rede - VMXNET3 ou Intel E1000.
Configurações do ponto de verificação
As atualizações mais recentes do Check Point são instaladas nos gateways e no servidor de gerenciamento. Verifique se há atualizações via CPUSE.
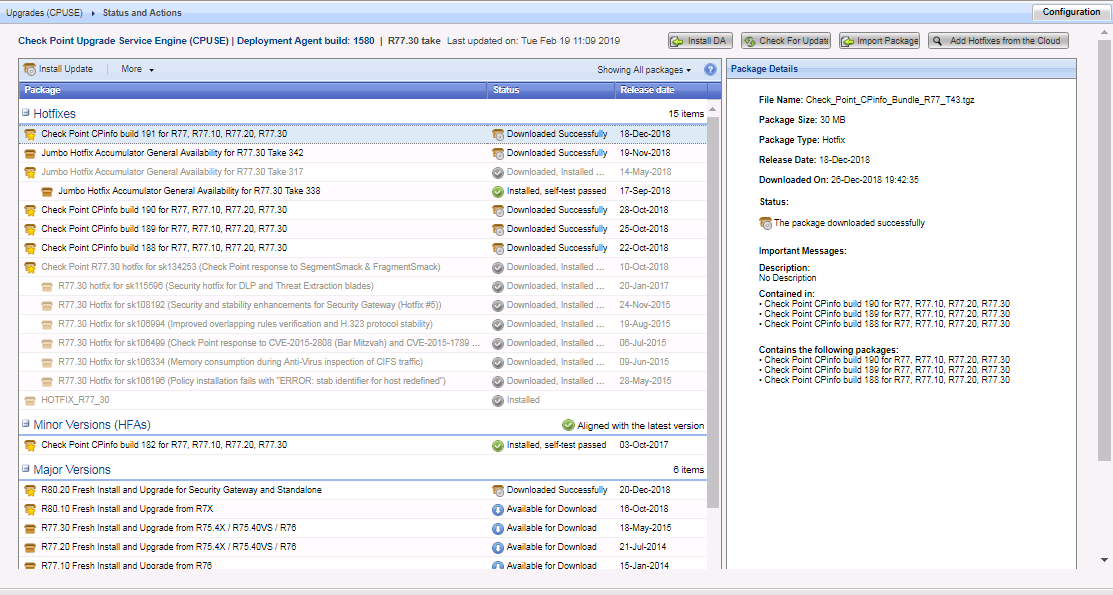
Usando o Verifier, verificamos se o service pack que estamos prestes a instalar não entra em conflito com o sistema.

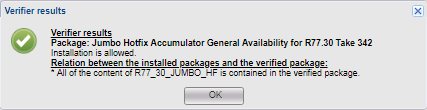
O verificador, é claro, é uma coisa boa, mas há nuances. Algumas atualizações não são compatíveis com o complemento, mas o Verifier não mostrará esses conflitos e permitirá a atualização. No final da atualização, você receberá um erro e somente a partir dela descobrirá o que impede a atualização. Por exemplo, essa situação ocorreu com o service pack MABDA_001 (Mobile Access Blade Deployment Agent), que resolve o problema de iniciar o Java Plugin em navegadores que não sejam o IE.
Atualizações diárias automáticas de assinaturas configuradas para IPS e outros blades de software. O Check Point libera assinaturas que podem ser usadas para detectar ou bloquear novas vulnerabilidades. As vulnerabilidades recebem automaticamente um nível de criticidade. De acordo com este nível e o filtro definido, o sistema decide se deve detectar ou bloquear a assinatura. É importante aqui não exagerar nos filtros, verificar periodicamente e fazer ajustes para que o tráfego legítimo não seja bloqueado.
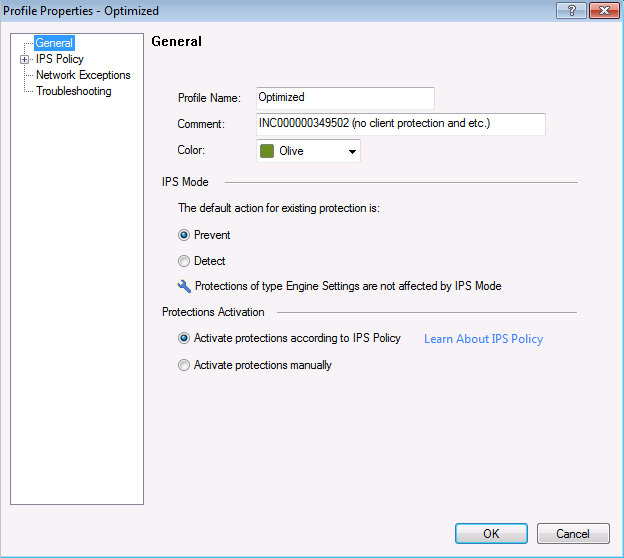 Perfil IPS, onde selecionamos a ação em relação à assinatura de acordo com seus parâmetros.
Perfil IPS, onde selecionamos a ação em relação à assinatura de acordo com seus parâmetros.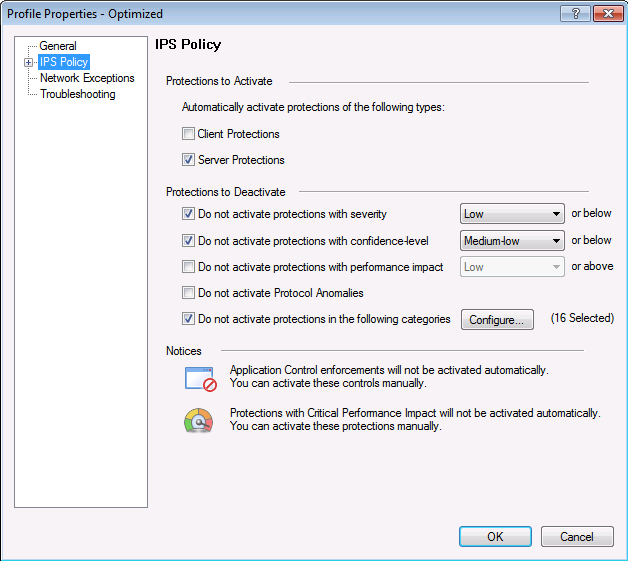 Configurações de política para esse perfil IPS de acordo com as configurações de assinatura: nível de gravidade, impacto no desempenho etc.O hardware do Check Point é configurado com o protocolo de sincronização de hora NTP.
Configurações de política para esse perfil IPS de acordo com as configurações de assinatura: nível de gravidade, impacto no desempenho etc.O hardware do Check Point é configurado com o protocolo de sincronização de hora NTP. Com base nas
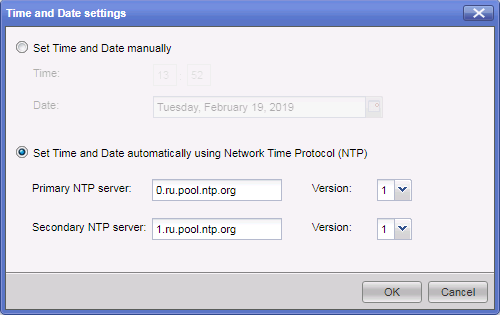
recomendações , o Check Point deve usar um servidor NTP externo para sincronizar o tempo no equipamento. Isso pode ser feito através do portal da web gaia.
O tempo impreciso pode causar a sincronização do cluster. Se a hora estiver errada, é extremamente inconveniente procurar a entrada de log que nos interessa. Cada entrada nos logs de eventos é marcada com um chamado carimbo de data / hora.
 Evento inteligente configurado para alertas sobre IPS, App Control, Anti-Bot, etc.
Evento inteligente configurado para alertas sobre IPS, App Control, Anti-Bot, etc. Este é um módulo separado com sua própria licença. Se você tiver um, use-o para visualizar informações sobre a operação de todos os blades e dispositivos de software. Por exemplo, ataques, número de operações de IPS, nível de criticidade de ameaças, aplicativos proibidos usados pelos usuários etc.
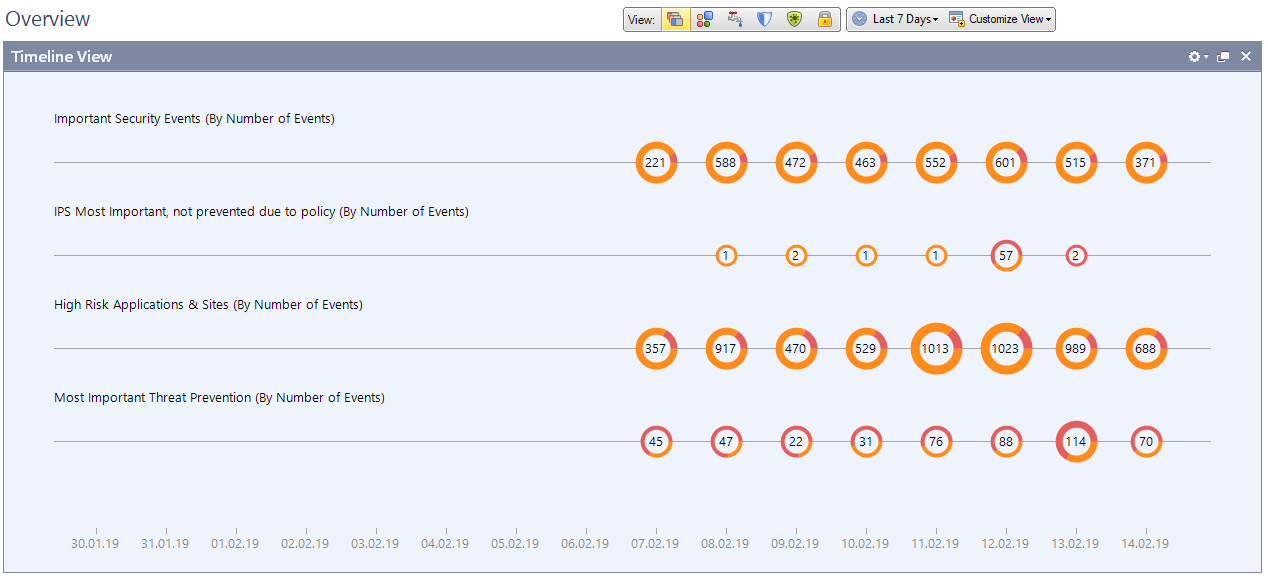
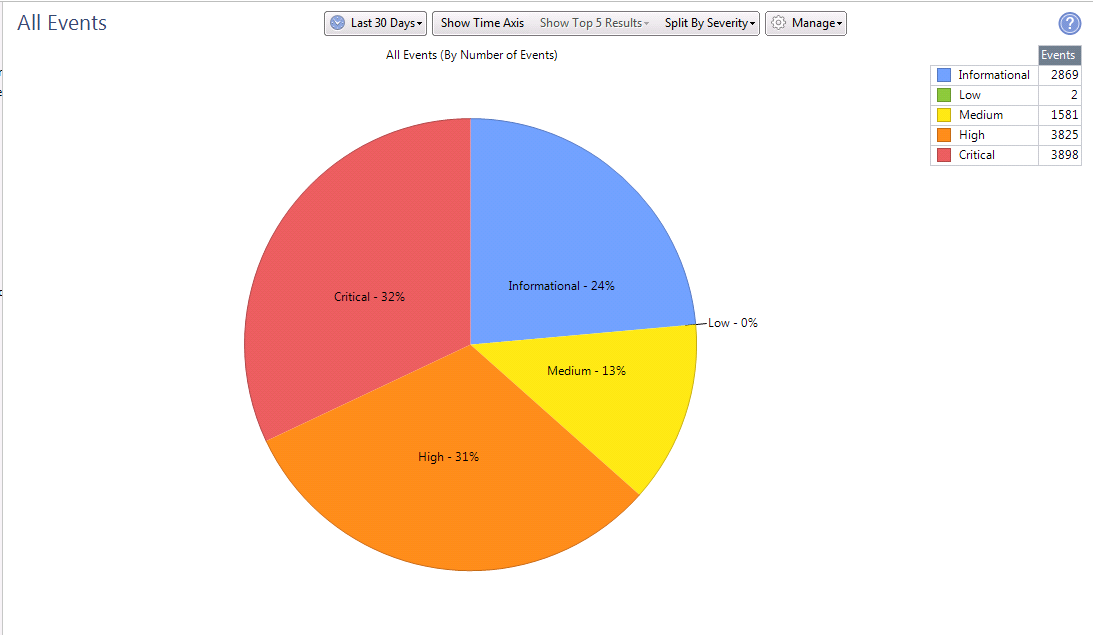 São estatísticas para 30 dias, de acordo com o número de assinaturas e o grau de criticidade.
São estatísticas para 30 dias, de acordo com o número de assinaturas e o grau de criticidade.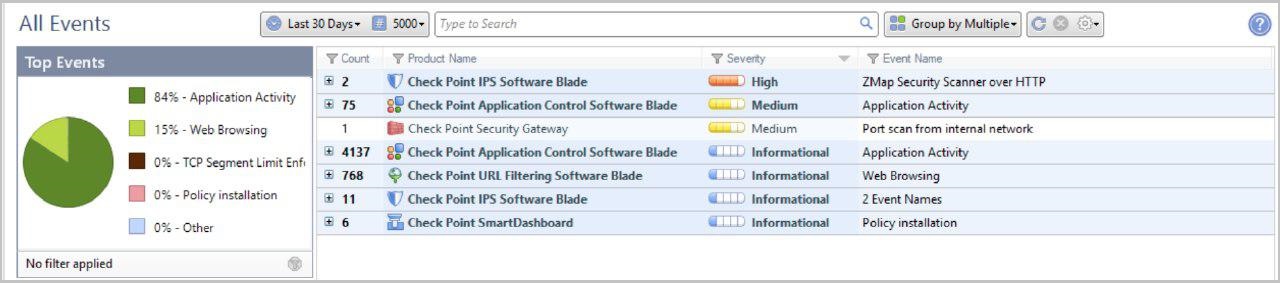 Informações mais detalhadas sobre as assinaturas detectadas em cada blade de software.
Informações mais detalhadas sobre as assinaturas detectadas em cada blade de software.Monitoramento
É importante monitorar pelo menos os seguintes parâmetros:
- estado do cluster;
- disponibilidade de componentes do Check Point;
- Carga da CPU
- espaço restante em disco;
- memória livre.
O Check Point possui um blade de software separado - Smart Monitoring (licença separada). Nele, é possível monitorar adicionalmente a disponibilidade dos componentes do Check Point, cargas em lâminas individuais e status da licença.
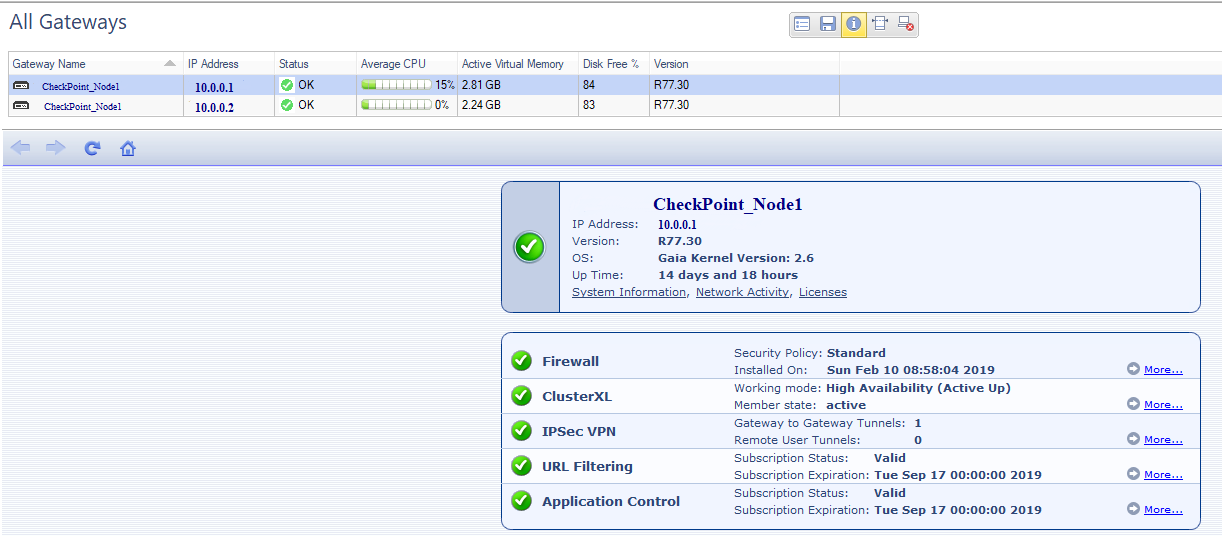
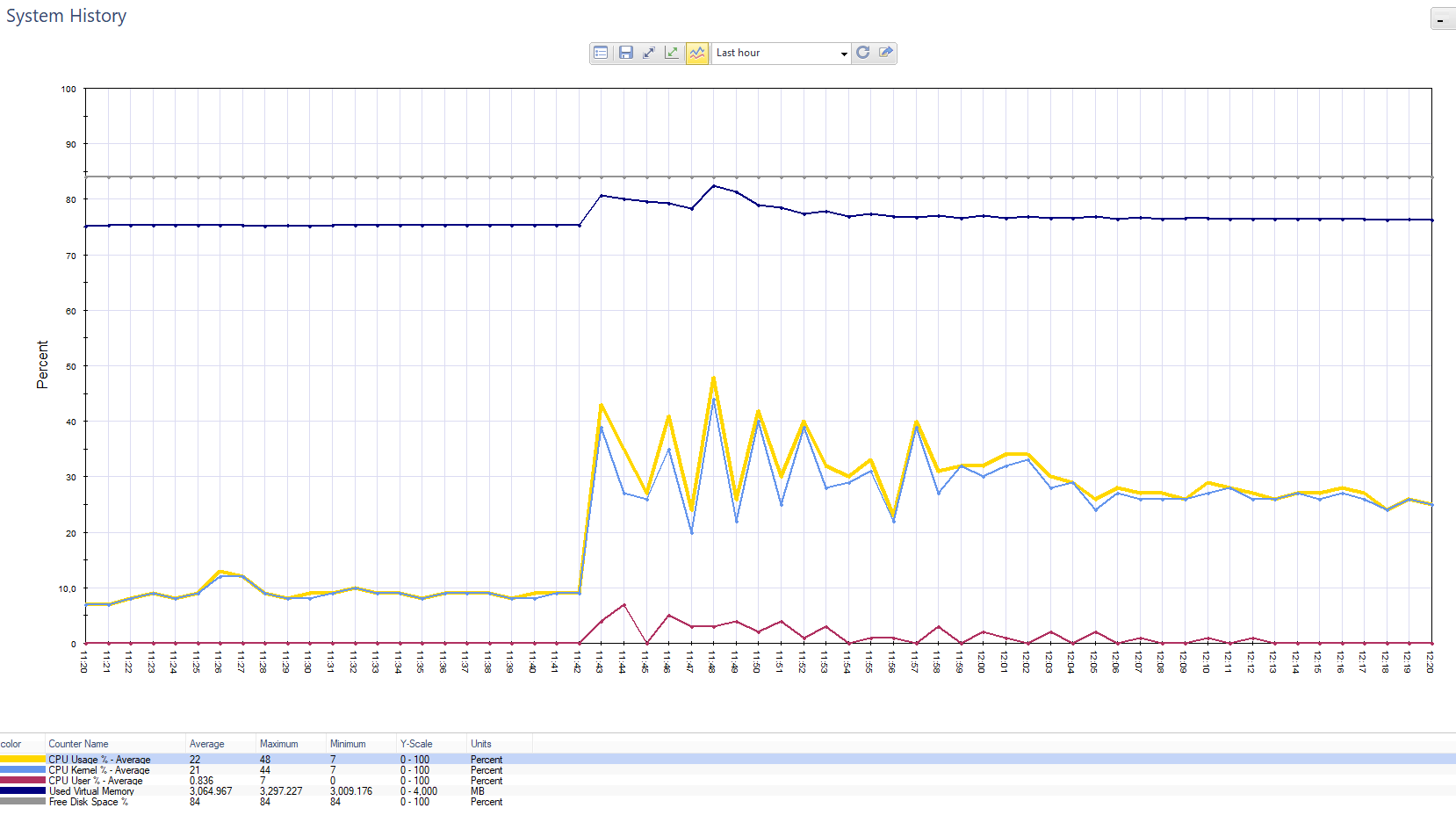 Gráfico de carga do Chek Point. Splash - este é o cliente que enviou notificações push para 800 mil clientes.
Gráfico de carga do Chek Point. Splash - este é o cliente que enviou notificações push para 800 mil clientes. O gráfico da carga no painel Firewall na mesma situação.
O gráfico da carga no painel Firewall na mesma situação.O monitoramento também pode ser configurado através de serviços de terceiros. Por exemplo, também usamos o Nagios, onde monitoramos:
- disponibilidade de equipamentos em rede;
- Disponibilidade de endereço de cluster
- Carregamento da CPU por núcleos. Ao baixar mais de 70%, um alerta de email chega. Uma carga tão alta pode indicar tráfego específico (vpn, por exemplo). Se isso for repetido com frequência, talvez não haja recursos suficientes e valha a pena expandir o pool.
- RAM grátis. Se restar menos de 80%, descobriremos isso.
- carregamento de disco em determinadas partições, por exemplo var / log. Se logo entupir, é necessário expandir.
- Cérebro dividido (no nível do cluster). Monitoramos o estado quando os dois nós se tornam ativos e a sincronização entre eles desaparece.
- Modo de alta disponibilidade - monitoramos se o cluster está no modo de espera ativa. Observamos os estados dos nós - ativo, em espera, em baixo.
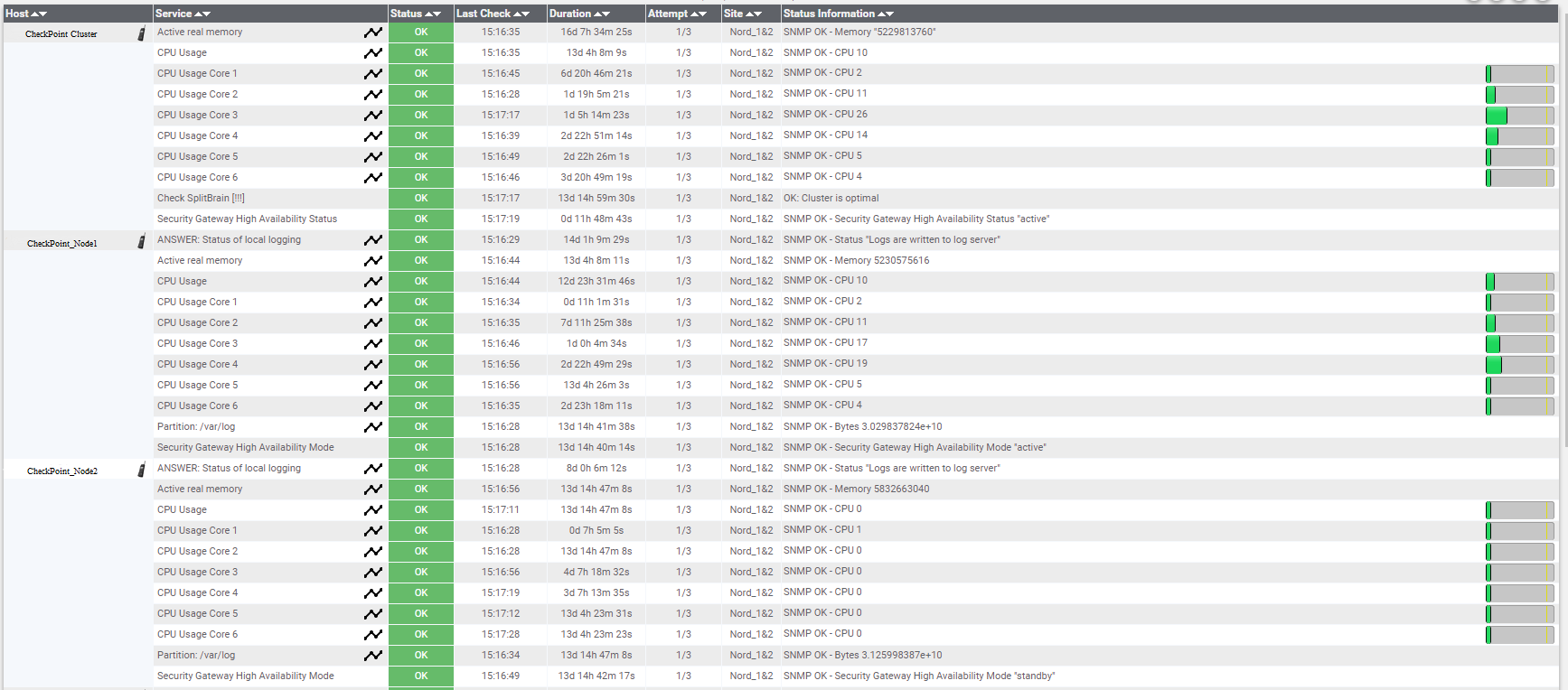 Opções de monitoramento em Nagios.
Opções de monitoramento em Nagios.Também vale a pena monitorar o status dos servidores físicos nos quais os hosts ESXi estão implantados.
Backup
O próprio fornecedor recomenda tirar um instantâneo imediatamente após a instalação da atualização (Hotfixies).
Dependendo da frequência das alterações, um backup completo é configurado uma vez por semana ou por mês. Em nossa prática, fazemos cópias incrementais diárias dos arquivos do Check Point e um backup completo uma vez por semana.
Só isso. Esses foram os pontos mais básicos a serem considerados ao implantar os Check Points virtuais. Mas mesmo atingir esse mínimo ajudará a evitar problemas com seu trabalho.