
Parte 1/3 aqui
Parte 3/3 aqui
Olá e bem vindo de volta! Esta é a segunda parte do artigo sobre como configurar um cluster Kubernetes no bare metal. Anteriormente, configuramos o cluster de HA do Kubernetes usando etcd externo, master-master e balanceamento de carga. Bem, agora é hora de configurar um ambiente e utilitários adicionais para tornar o cluster mais útil e o mais próximo possível do estado de trabalho.
Nesta parte do artigo, focaremos na configuração do balanceador de carga interno dos serviços de cluster - o MetalLB. Também instalaremos e configuramos o armazenamento de arquivos distribuídos entre nossos nós de trabalho. Usaremos o GlusterFS para volumes persistentes disponíveis no Kubernetes.
Depois de concluir todas as etapas, nosso diagrama de cluster ficará assim:
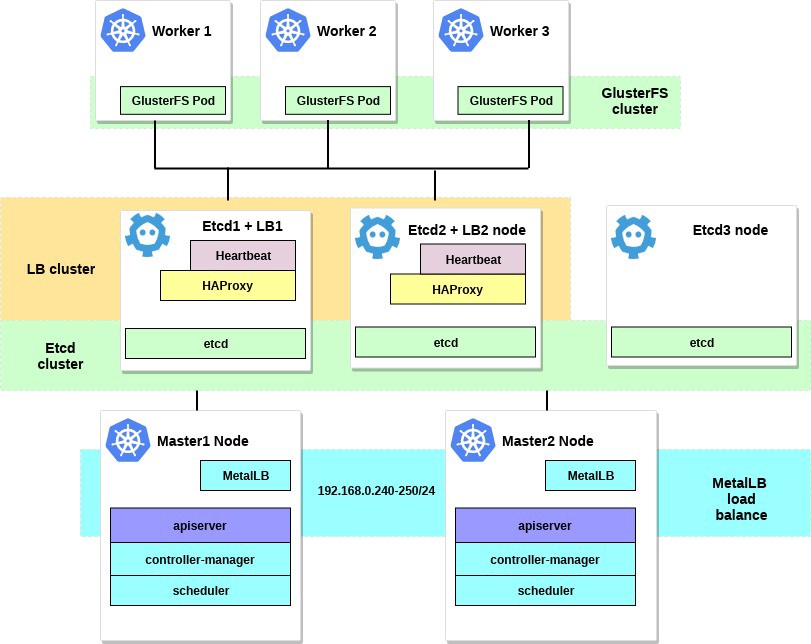
Algumas palavras sobre o MetalLB, diretamente da página do documento:
O MetalLB é uma implementação do balanceador de carga para clusters bare metal do Kubernetes com protocolos de roteamento padrão.
O Kubernetes não oferece a implementação de balanceadores de carga de rede ( tipo de serviço LoadBalancer ) para bare metal. Todas as opções de implementação de Network LB fornecidas com o Kubernetes são middleware e acessam várias plataformas de IaaS (GCP, AWS, Azure, etc.). Se você não estiver trabalhando em uma plataforma suportada por IaaS (GCP, AWS, Azure etc.), o LoadBalancer permanecerá no estado "em espera" por um período indeterminado após a criação.
Os operadores de servidor BM têm duas ferramentas menos eficazes para inserir o tráfego do usuário em seus clusters, os serviços NodePort e externalIPs. Ambas as opções apresentam falhas de produção significativas, o que transforma os clusters de BM em cidadãos de segunda classe no ecossistema de Kubernetes.
O MetalLB procura corrigir esse desequilíbrio oferecendo uma implementação de Network LB que se integra ao equipamento de rede padrão, para que os serviços externos nos clusters de BM também “funcionem” na velocidade máxima.
Assim, usando essa ferramenta, lançamos serviços no cluster Kubernetes usando um balanceador de carga, pelo qual muito obrigado à equipe do MetalLB. O processo de instalação é realmente simples e direto.
No início do exemplo, selecionamos a sub-rede 192.168.0.0/24 para as necessidades do nosso cluster. Agora pegue um pouco dessa sub-rede para o futuro balanceador de carga.
Entramos no sistema da máquina com o utilitário kubectl configurado e executamos:
control# kubectl apply -f https://raw.githubusercontent.com/google/metallb/v0.7.3/manifests/metallb.yaml
Isso implantará o MetalLB no cluster, no metallb-system do metallb-system . Verifique se todos os componentes do MetalLB estão funcionando corretamente:
control# kubectl get pod --namespace=metallb-system NAME READY STATUS RESTARTS AGE controller-7cc9c87cfb-ctg7p 1/1 Running 0 5d3h speaker-82qb5 1/1 Running 0 5d3h speaker-h5jw7 1/1 Running 0 5d3h speaker-r2fcg 1/1 Running 0 5d3h
Agora configure o MetalLB usando o configmap. Neste exemplo, estamos usando a personalização da Camada 2. Para obter informações sobre outras opções de personalização, consulte a documentação do MetalLB.
Crie o arquivo metallb-config.yaml em qualquer diretório dentro do intervalo de IP selecionado da sub-rede do nosso cluster:
control# vi metallb-config.yaml apiVersion: v1 kind: ConfigMap metadata: namespace: metallb-system name: config data: config: | address-pools: - name: default protocol: layer2 addresses: - 192.168.0.240-192.168.0.250
E aplique esta configuração:
control# kubectl apply -f metallb-config.yaml
Verifique e modifique o configmap posteriormente, se necessário:
control# kubectl describe configmaps -n metallb-system control# kubectl edit configmap config -n metallb-system
Agora, temos nosso próprio balanceador de carga local configurado. Vamos ver como funciona, usando o serviço Nginx como exemplo.
control# vi nginx-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: selector: matchLabels: app: nginx replicas: 3 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:latest ports: - containerPort: 80 control# vi nginx-service.yaml apiVersion: v1 kind: Service metadata: name: nginx spec: type: LoadBalancer selector: app: nginx ports: - port: 80 name: http
Em seguida, crie uma implantação de teste e um serviço Nginx:
control# kubectl apply -f nginx-deployment.yaml control# kubectl apply -f nginx-service.yaml
E agora - verifique o resultado:
control# kubectl get po NAME READY STATUS RESTARTS AGE nginx-deployment-6574bd76c-fxgxr 1/1 Running 0 19s nginx-deployment-6574bd76c-rp857 1/1 Running 0 19s nginx-deployment-6574bd76c-wgt9n 1/1 Running 0 19s control# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE nginx LoadBalancer 10.100.226.110 192.168.0.240 80:31604/TCP 107s
Criamos 3 pods Nginx, conforme indicado na implantação anteriormente. O serviço Nginx direcionará o tráfego para todos esses pods de acordo com o esquema de balanceamento cíclico. E você também pode ver o IP externo recebido do nosso balanceador de carga MetalLB.
Agora tente acessar o endereço IP 192.168.0.240 e você verá a página index.html do Nginx. Lembre-se de remover a implantação de teste e o serviço Nginx.
control# kubectl delete svc nginx service "nginx" deleted control# kubectl delete deployment nginx-deployment deployment.extensions "nginx-deployment" deleted
Bem, isso é tudo com o MetalLB, vamos seguir em frente - vamos configurar os volumes GlusterFS para Kubernetes.
2. Configurando o GlusterFS com Heketi nos nós de trabalho.
De fato, o cluster Kubernetes não pode ser usado sem volumes dentro dele. Como você sabe, os lares são efêmeros, ou seja, eles podem ser criados e excluídos a qualquer momento. Todos os dados dentro deles serão perdidos. Portanto, em um cluster real, é necessário armazenamento distribuído para garantir a troca de configurações e dados entre nós e aplicativos dentro dele.
No Kubernetes, os volumes estão disponíveis de várias maneiras; escolha os que você deseja. Neste exemplo, demonstrarei como criar o armazenamento GlusterFS para qualquer aplicativo interno, como volumes persistentes. Anteriormente, usei a instalação "sistema" do GlusterFS para todos os nós de trabalho do Kubernetes para isso e simplesmente criei volumes hostPath nos diretórios do GlusterFS.
Agora temos uma nova ferramenta útil da Heketi .
Algumas palavras da documentação da Heketi:
Infra-estrutura de gerenciamento de volume RESTful para GlusterFS.
A Heketi oferece uma interface de gerenciamento RESTful que pode ser usada para gerenciar o ciclo de vida dos volumes GlusterFS. Graças à Heketi, serviços em nuvem como o OpenStack Manila, Kubernetes e OpenShift podem fornecer dinamicamente os volumes GlusterFS com qualquer tipo de confiabilidade suportada. O Heketi determina automaticamente a localização dos blocos em um cluster, fornecendo a localização dos blocos e suas réplicas em diferentes áreas de falha. A Heketi também suporta qualquer número de clusters GlusterFS, permitindo que os serviços em nuvem ofereçam armazenamento de arquivos on-line, não apenas um único cluster GlusterFS.
Parece bom e, além disso, essa ferramenta aproximará nosso cluster de VM dos grandes clusters de nuvem do Kubernetes. No final, você poderá criar PersistentVolumeClaims , que serão gerados automaticamente e muito mais.
Você pode usar discos rígidos adicionais do sistema para configurar o GlusterFS ou apenas criar alguns dispositivos de bloqueio fictício. Neste exemplo, usarei o segundo método.
Crie dispositivos de bloco fictício nos três nós de trabalho:
worker1-3# dd if=/dev/zero of=/home/gluster/image bs=1M count=10000
Você receberá um arquivo com aproximadamente 10 GB de tamanho. Em seguida, use losetup - para adicioná-lo a esses nós, como um dispositivo de loopback:
worker1-3# losetup /dev/loop0 /home/gluster/image
Observe: se você já possui algum tipo de dispositivo de loopback 0, precisará escolher qualquer outro número.
Aproveitei o tempo e descobri por que a Heketi não quer funcionar corretamente. Portanto, para evitar problemas em configurações futuras, primeiro verifique se carregamos o módulo do kernel dm_thin_pool e instalamos o pacote glusterfs-client em todos os nós em funcionamento.
worker1-3# modprobe dm_thin_pool worker1-3# apt-get update && apt-get -y install glusterfs-client
Bem, agora você precisa que o arquivo / home / gluster / image e o dispositivo / dev / loop0 estejam presentes em todos os nós em funcionamento. Lembre-se de criar um serviço systemd que iniciará automaticamente o losetup e o modprobe toda vez que esses servidores forem inicializados.
worker1-3# vi /etc/systemd/system/loop_gluster.service [Unit] Description=Create the loopback device for GlusterFS DefaultDependencies=false Before=local-fs.target After=systemd-udev-settle.service Requires=systemd-udev-settle.service [Service] Type=oneshot ExecStart=/bin/bash -c "modprobe dm_thin_pool && [ -b /dev/loop0 ] || losetup /dev/loop0 /home/gluster/image" [Install] WantedBy=local-fs.target
E ative:
worker1-3# systemctl enable /etc/systemd/system/loop_gluster.service Created symlink /etc/systemd/system/local-fs.target.wants/loop_gluster.service → /etc/systemd/system/loop_gluster.service.
O trabalho preparatório está concluído e estamos prontos para implantar o GlusterFS e o Heketi em nosso cluster. Para isso, usarei este guia legal. A maioria dos comandos é iniciada a partir de um computador de controle externo e comandos muito pequenos são iniciados a partir de qualquer nó principal dentro do cluster.
Primeiro, copie o repositório e crie DaemonSet GlusterFS:
control# git clone https://github.com/heketi/heketi control# cd heketi/extras/kubernetes control# kubectl create -f glusterfs-daemonset.json
Agora vamos marcar nossos três nós de trabalho para o GlusterFS; após rotulá-los, os pods do GlusterFS serão criados:
control# kubectl label node worker1 storagenode=glusterfs control# kubectl label node worker2 storagenode=glusterfs control# kubectl label node worker3 storagenode=glusterfs control# kubectl get pod NAME READY STATUS RESTARTS AGE glusterfs-5dtdj 1/1 Running 0 1m6s glusterfs-hzdll 1/1 Running 0 1m9s glusterfs-p8r59 1/1 Running 0 2m1s
Agora crie uma conta de serviço Heketi:
control# kubectl create -f heketi-service-account.json
Fornecemos a essa conta de serviço a capacidade de gerenciar pods de gluster. Para fazer isso, crie uma função de cluster necessária para nossa conta de serviço recém-criada:
control# kubectl create clusterrolebinding heketi-gluster-admin --clusterrole=edit --serviceaccount=default:heketi-service-account
Agora vamos criar uma chave secreta do Kubernetes que bloqueia a configuração da nossa instância Heketi:
control# kubectl create secret generic heketi-config-secret --from-file=./heketi.json
Crie a primeira fonte em Heketi, que usamos nas primeiras operações de configuração e, em seguida, exclua:
control# kubectl create -f heketi-bootstrap.json service "deploy-heketi" created deployment "deploy-heketi" created control# kubectl get pod NAME READY STATUS RESTARTS AGE deploy-heketi-1211581626-2jotm 1/1 Running 0 2m glusterfs-5dtdj 1/1 Running 0 6m6s glusterfs-hzdll 1/1 Running 0 6m9s glusterfs-p8r59 1/1 Running 0 7m1s
Depois de criar e iniciar o serviço Bootstrap Heketi, precisaremos mudar para um de nossos nós principais, onde executaremos vários comandos, já que nosso nó de controle externo não está dentro do cluster, portanto, não podemos acessar os pods de trabalho e a rede interna do cluster.
Primeiro, vamos baixar o utilitário heketi-client e copiá-lo para a pasta bin system:
master1# wget https://github.com/heketi/heketi/releases/download/v8.0.0/heketi-client-v8.0.0.linux.amd64.tar.gz master1# tar -xzvf ./heketi-client-v8.0.0.linux.amd64.tar.gz master1# cp ./heketi-client/bin/heketi-cli /usr/local/bin/ master1# heketi-cli heketi-cli v8.0.0
Agora encontre o endereço IP do pod heketi e exporte-o como uma variável do sistema:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf describe pod deploy-heketi-1211581626-2jotm For me this pod have a 10.42.0.1 ip master1# curl http://10.42.0.1:57598/hello Handling connection for 57598 Hello from Heketi master1# export HEKETI_CLI_SERVER=http://10.42.0.1:57598
Agora vamos fornecer à Heketi informações sobre o cluster GlusterFS que ele deve gerenciar. Nós o fornecemos através de um arquivo de topologia. Uma topologia é um manifesto JSON com uma lista de todos os nós, discos e clusters usados pelo GlusterFS.
NOTA Certifique-se de que hostnames/manage indiquem o nome exato, como na seção kubectl get node , e que hostnames/storage sejam o endereço IP dos nós de armazenamento.
master1:~/heketi-client# vi topology.json { "clusters": [ { "nodes": [ { "node": { "hostnames": { "manage": [ "worker1" ], "storage": [ "192.168.0.7" ] }, "zone": 1 }, "devices": [ "/dev/loop0" ] }, { "node": { "hostnames": { "manage": [ "worker2" ], "storage": [ "192.168.0.8" ] }, "zone": 1 }, "devices": [ "/dev/loop0" ] }, { "node": { "hostnames": { "manage": [ "worker3" ], "storage": [ "192.168.0.9" ] }, "zone": 1 }, "devices": [ "/dev/loop0" ] } ] } ] }
Faça o download deste arquivo:
master1:~/heketi-client# heketi-cli topology load --json=topology.json Creating cluster ... ID: e83467d0074414e3f59d3350a93901ef Allowing file volumes on cluster. Allowing block volumes on cluster. Creating node worker1 ... ID: eea131d392b579a688a1c7e5a85e139c Adding device /dev/loop0 ... OK Creating node worker2 ... ID: 300ad5ff2e9476c3ba4ff69260afb234 Adding device /dev/loop0 ... OK Creating node worker3 ... ID: 94ca798385c1099c531c8ba3fcc9f061 Adding device /dev/loop0 ... OK
Em seguida, usamos o Heketi para fornecer volumes para armazenar o banco de dados. O nome da equipe é um pouco estranho, mas está tudo em ordem. Crie também um repositório heketi:
master1:~/heketi-client# heketi-cli setup-openshift-heketi-storage master1:~/heketi-client# kubectl --kubeconfig /etc/kubernetes/admin.conf create -f heketi-storage.json secret/heketi-storage-secret created endpoints/heketi-storage-endpoints created service/heketi-storage-endpoints created job.batch/heketi-storage-copy-job created
Esses são todos os comandos que você precisa executar no nó principal. Vamos voltar ao nó de controle e continuar a partir daí; Antes de tudo, verifique se o último comando em execução foi executado com sucesso:
control# kubectl get pod NAME READY STATUS RESTARTS AGE glusterfs-5dtdj 1/1 Running 0 39h glusterfs-hzdll 1/1 Running 0 39h glusterfs-p8r59 1/1 Running 0 39h heketi-storage-copy-job-txkql 0/1 Completed 0 69s
E o trabalho de heketi-storage-copy-job está concluído.
Se atualmente não houver nenhum pacote glusterfs-client instalado em seus nós de trabalho, ocorrerá um erro.
É hora de remover o arquivo de instalação do Heketi Bootstrap e fazer uma pequena limpeza:
control# kubectl delete all,service,jobs,deployment,secret --selector="deploy-heketi"
No último estágio, precisamos criar uma cópia a longo prazo do Heketi:
control# cd ./heketi/extras/kubernetes control:~/heketi/extras/kubernetes# kubectl create -f heketi-deployment.json secret/heketi-db-backup created service/heketi created deployment.extensions/heketi created control# kubectl get pod NAME READY STATUS RESTARTS AGE glusterfs-5dtdj 1/1 Running 0 39h glusterfs-hzdll 1/1 Running 0 39h glusterfs-p8r59 1/1 Running 0 39h heketi-b8c5f6554-knp7t 1/1 Running 0 22m
Se atualmente não houver nenhum pacote glusterfs-client instalado em seus nós de trabalho, ocorrerá um erro. E estamos quase terminando, agora o banco de dados Heketi é armazenado no volume GlusterFS e não é redefinido toda vez que o coração da Heketi é reiniciado.
Para começar a usar o cluster GlusterFS com alocação dinâmica de recursos, precisamos criar uma StorageClass.
Primeiro, vamos encontrar o ponto de extremidade de armazenamento Gluster, que será passado para o StorageClass como um parâmetro (heketi-storage-endpoints):
control# kubectl get endpoints NAME ENDPOINTS AGE heketi 10.42.0.2:8080 2d16h ....... ... ..
Agora crie alguns arquivos:
control# vi storage-class.yml apiVersion: storage.k8s.io/v1beta1 kind: StorageClass metadata: name: slow provisioner: kubernetes.io/glusterfs parameters: resturl: "http://10.42.0.2:8080" control# vi test-pvc.yml kind: PersistentVolumeClaim apiVersion: v1 metadata: name: gluster1 annotations: volume.beta.kubernetes.io/storage-class: "slow" spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi
Use estes arquivos para criar classe e pvc:
control# kubectl create -f storage-class.yaml storageclass "slow" created control# kubectl get storageclass NAME PROVISIONER AGE slow kubernetes.io/glusterfs 2d8h control# kubectl create -f test-pvc.yaml persistentvolumeclaim "gluster1" created control# kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE gluster1 Bound pvc-27f733cd-1c77-11e9-bb07-7efe6b0e6fa5 1Gi RWO slow 2d8h
Também podemos ver o volume fotovoltaico:
control# kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pvc-27f733cd-1c77-11e9-bb07-7efe6b0e6fa5 1Gi RWO Delete Bound default/gluster1 slow 2d8h
Agora temos um volume GlusterFS criado dinamicamente associado ao PersistentVolumeClaim , e podemos usar essa instrução em qualquer subtrama.
Crie um simples no Nginx e teste-o:
control# vi nginx-test.yml apiVersion: v1 kind: Pod metadata: name: nginx-pod1 labels: name: nginx-pod1 spec: containers: - name: nginx-pod1 image: gcr.io/google_containers/nginx-slim:0.8 ports: - name: web containerPort: 80 volumeMounts: - name: gluster-vol1 mountPath: /usr/share/nginx/html volumes: - name: gluster-vol1 persistentVolumeClaim: claimName: gluster1 control# kubectl create -f nginx-test.yaml pod "nginx-pod1" created
Navegue em (aguarde alguns minutos, pode ser necessário fazer o download da imagem, se ela ainda não existir):
control# kubectl get pods NAME READY STATUS RESTARTS AGE glusterfs-5dtdj 1/1 Running 0 4d10h glusterfs-hzdll 1/1 Running 0 4d10h glusterfs-p8r59 1/1 Running 0 4d10h heketi-b8c5f6554-knp7t 1/1 Running 0 2d18h nginx-pod1 1/1 Running 0 47h
Agora entre no contêiner e crie o arquivo index.html:
control# kubectl exec -ti nginx-pod1 /bin/sh # cd /usr/share/nginx/html # echo 'Hello there from GlusterFS pod !!!' > index.html # ls index.html # exit
Você precisará encontrar o endereço IP interno da lareira e se enrolar nele a partir de qualquer nó principal:
master1# curl 10.40.0.1 Hello there from GlusterFS pod !!!
Ao fazer isso, simplesmente testamos nosso novo volume persistente.
Alguns comandos úteis para verificar o novo cluster GlusterFS são: heketi-cli cluster list heketi-cli volume list . Eles podem ser executados no seu computador se o heketi-cli estiver instalado . Neste exemplo, este é o nó master1 .
master1# heketi-cli cluster list Clusters: Id:e83467d0074414e3f59d3350a93901ef [file][block] master1# heketi-cli volume list Id:6fdb7fef361c82154a94736c8f9aa53e Cluster:e83467d0074414e3f59d3350a93901ef Name:vol_6fdb7fef361c82154a94736c8f9aa53e Id:c6b69bd991b960f314f679afa4ad9644 Cluster:e83467d0074414e3f59d3350a93901ef Name:heketidbstorage
Nesse ponto, configuramos com êxito um balanceador de carga interno com armazenamento de arquivos e nosso cluster agora está mais próximo do estado operacional.
Na próxima parte do artigo, focaremos na criação de um sistema de monitoramento de cluster e também lançaremos um projeto de teste para usar todos os recursos que configuramos.
Fique em contato e tudo de bom!