Neste artigo, falarei sobre minas colocadas sob o desempenho, bem como sua detecção (preferencialmente antes da explosão) e descarte.
Uma imagem para atrair a atenção O que é uma mina?
Vamos começar com o que está nas origens de qualquer conhecimento - com definição. Os antigos disseram que nomear corretamente significa entender corretamente. Eu acho que a definição de uma mina com desempenho é melhor expressa por contraste com um erro claro, por exemplo,
String concat(String... strings) { String result = ""; for (String str : strings) { result += str; } return result; }
Até desenvolvedores iniciantes sabem que as linhas são imutáveis e colá-las em um loop não significa adicionar dados ao final de uma linha existente, mas criar uma nova linha a cada passagem. Se você estiver enganado, não desanime - a “Ideia” o alertará imediatamente sobre o perigo, e o “Sonar” certamente inundará sua assembléia.
Mas esse código atrairá muito menos atenção e a Idea ( antes da versão 2018.2 ) ficará em silêncio:
Long total = 0L; List<Long> totals = query.getResultList(); for (Long element : totals) { total += element == null ? 0 : element; }
O problema aqui é o mesmo: os invólucros para tipos simples são imutáveis, o que significa adicionar 5 unidades ao número do objeto significa criar um novo invólucro e gravar o número 6 nele.
A piada aqui é a presença em Java de duas representações de certos tipos de dados - simples e objeto, bem como sua transformação automática por meio da própria linguagem. Por causa disso, muitos desenvolvedores novatos pensam algo assim: "Bem, a execução de alguma forma os transforma lá por si só, é apenas um número".
De fato, nem tudo é tão simples. Pegue a referência e tente adicionar os números da maneira especificada:
De repente, saiu muito, muito barato (a seguir JDK 11, a menos que explicitamente indicado de outra forma) (size) Mode Cnt Score Error Units wrapper 10 avgt 100 23,5 ± 0,1 ns/op wrapper 100 avgt 100 352,3 ± 2,1 ns/op wrapper 1000 avgt 100 4424,5 ± 25,2 ns/op wrapper 10 avgt 100 0 ± 0 B/op wrapper 100 avgt 100 1872 ± 0 B/op wrapper 1000 avgt 100 23472 ± 0 B/op
Compare com um tipo simples:
primitive 10 avgt 100 6,4 ± 0,0 ns/op primitive 100 avgt 100 39,8 ± 0,1 ns/op primitive 1000 avgt 100 252,5 ± 1,3 ns/op primitive 10 avgt 100 0 ± 0 B/op primitive 100 avgt 100 0 ± 0 B/op primitive 1000 avgt 100 0 ± 0 B/op
A partir daqui, derivamos uma das definições de minas em desempenho - este é um código que não chama a atenção, não é detectado (pelo menos no momento em que você o encontrou) pelos analisadores estáticos, mas pode desacelerar em alguns usos. No nosso caso, enquanto a soma não excede 127 objetos, o cache é retirado e Long apenas 4 vezes mais lento que o long . No entanto, para uma matriz de tamanho 100, a velocidade é quase 10 vezes menor.
Grandes pequenas coisas
Às vezes, uma pequena mudança, que quase não muda o significado da execução, em algumas circunstâncias se torna um freio forte.
Suponha que tenhamos um código:
Como é a lógica do método?
Não se apresse em espionar, penseEste é ConcurrentHashMap::computeIfAbsent !
Temos o "oito" e podemos melhorar o código de maneira interessante: substitua 6 linhas por uma, tornando o código mais curto e fácil de entender. A propósito, os conhecedores de multithreading provavelmente ConcurrentHashMap::computeIfAbsent outra melhoria que ConcurrentHashMap::computeIfAbsent traz consigo, mas um pouco mais tarde;)
Vamos realizar um ótimo pensamento:
Reunidos, iniciados, choraramPara ver o tamanho completo, clique com o botão direito do mouse na imagem e selecione "Abrir imagem em uma nova guia"
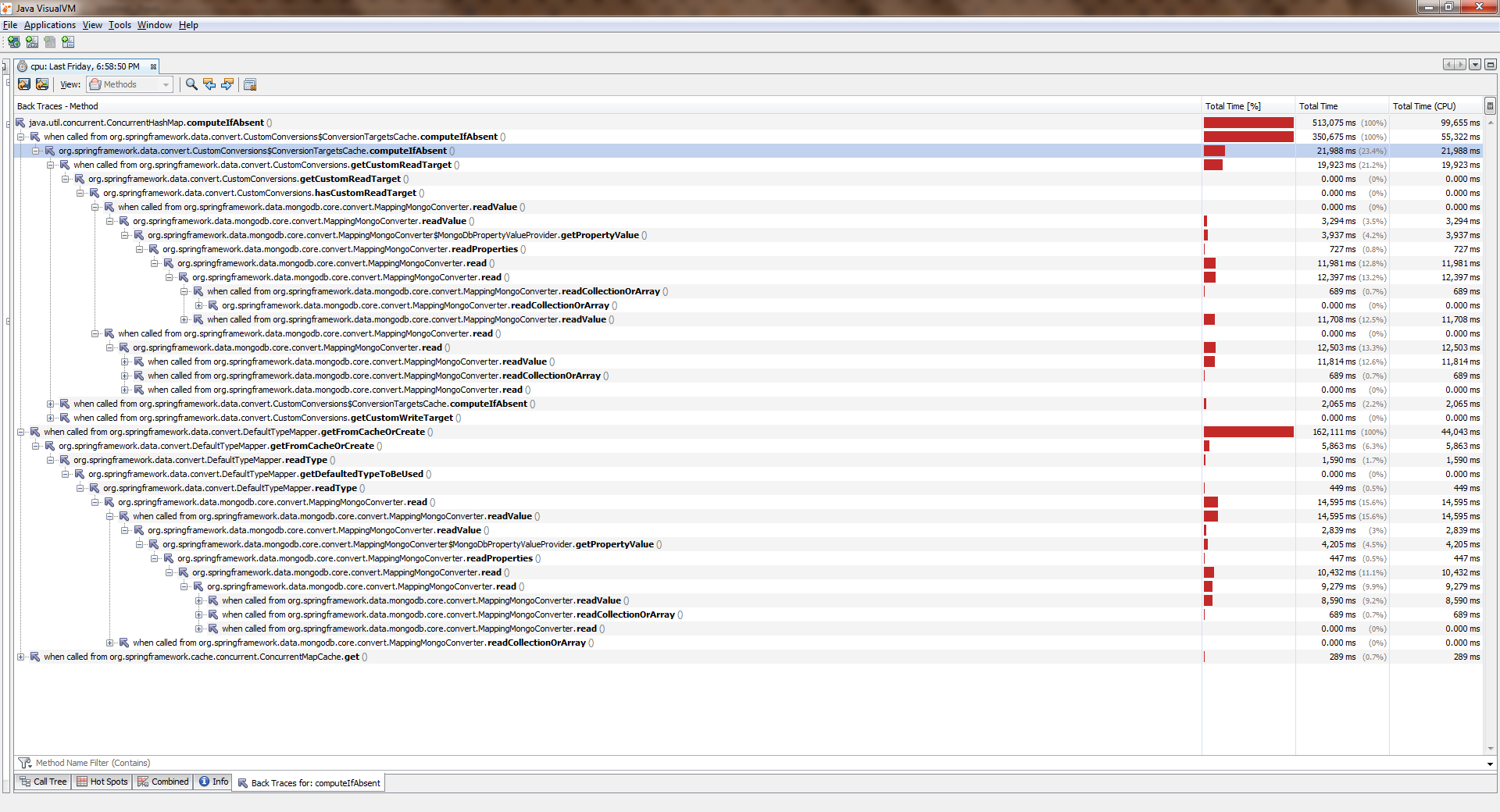
Enquanto o aplicativo trabalhava com um thread, tudo era mais ou menos bom. Os fluxos tornaram-se mais e pioraram significativamente. Verificou- ConcurrentHashMap::computeIfAbsent que ConcurrentHashMap::computeIfAbsent bloqueado, mesmo que a chave já tenha sido adicionada ao dicionário . E esse se tornou o motivo de um bug no Spring Date Mongo.
Você pode verificar isso com uma medição simples ("oito"). Aqui está sua conclusão:
Benchmark Mode Cnt Score Error Units 1 thread computeIfAbsent avgt 20 19,405 ± 0,411 ns/op getAndPut avgt 20 4,578 ± 0,045 ns/op 2 threads computeIfAbsent avgt 20 66,492 ± 2,036 ns/op getAndPut avgt 20 4,454 ± 0,110 ns/op 4 threads computeIfAbsent avgt 20 155,975 ± 8,850 ns/op getAndPut avgt 20 5,616 ± 2,073 ns/op 6 threads computeIfAbsent avgt 20 203,188 ± 10,547 ns/op getAndPut avgt 20 7,024 ± 0,456 ns/op 8 threads computeIfAbsent avgt 20 302,036 ± 31,702 ns/op getAndPut avgt 20 7,990 ± 0,144 ns/op
Isso pode ser claramente considerado um erro pelos desenvolvedores? Na minha humilde opinião, não, não. A documentação diz:
Algumas tentativas de atualização de operações neste mapa por outros encadeamentos podem ser bloqueadas enquanto a computação está em andamento; portanto, a computação deve ser curta e simples e não deve tentar atualizar nenhum outro mapeamento desse mapa.
Em outras palavras, ConcurrentHashMap::computeIfAbsent fecha a célula que contém a chave do mundo externo (ao contrário de ConcurrentHashMap::get ), o que geralmente é verdadeiro, pois permite evitar a corrida ao chamar o método de diferentes threads quando a chave ainda não foi adicionada.
Por outro lado, no modo de operação mais comum, o cálculo do valor e sua ligação com a chave ocorre apenas na primeira chamada e todas as chamadas subsequentes retornam apenas o valor calculado anteriormente. Portanto, faz sentido alterar a lógica para que o bloqueio seja definido apenas ao alterar. Foi feito aqui .
Nas edições mais recentes (> 8), ConcurrentHashMap::computeIfAbsent se ConcurrentHashMap::computeIfAbsent :
JDK 11 Benchmark Mode Cnt Score Error Units 1 thread computeIfAbsent avgt 20 6,983 ± 0,066 ns/op getAndPut avgt 20 5,291 ± 1,220 ns/op 2 threads computeIfAbsent avgt 20 7,173 ± 0,249 ns/op getAndPut avgt 20 5,118 ± 0,395 ns/op 4 threads computeIfAbsent avgt 20 7,991 ± 0,447 ns/op getAndPut avgt 20 5,270 ± 0,366 ns/op 6 threads computeIfAbsent avgt 20 11,919 ± 0,865 ns/op getAndPut avgt 20 7,249 ± 0,199 ns/op 8 threads computeIfAbsent avgt 20 14,360 ± 0,892 ns/op getAndPut avgt 20 8,511 ± 0,229 ns/op
Preste atenção à insidiosidade deste exemplo: o conteúdo semântico não mudou muito, porque à primeira vista usamos apenas uma sintaxe mais avançada. Ao mesmo tempo, enquanto o aplicativo é executado em um thread, o usuário quase não sente a diferença! É assim que mudanças aparentemente inofensivas o porco mina sob nosso desempenho.
Por que eu escrevi 'quase inalterado'ConcurrentHashMap::computeIfAbsent nem sempre é intercambiável com a expressão getAndPut , porque ConcurrentHashMap::computeIfAbsent é uma operação atômica. No mesmo código
private TypeInformation<?> getFromCacheOrCreate(Alias alias) { TypeInformation<?> info = cache.get(alias); if (info == null) { info = getAlias.apply(alias); cache.put(alias, info); } return info; }
devido à falta de sincronização externa , uma corrida aparece . Se a função passada para ConcurrentHashMap::computeIfAbsent para a chave especificada sempre retornar o mesmo valor, então esta é uma corrida "segura", o máximo que enfrentamos é o cálculo do mesmo valor 2 ou mais vezes. Se não houver tais garantias, uma substituição mecânica estará repleta de falhas na aplicação. Cuidado!
Essas mãos não mudaram nada
Também acontece que o código não muda, mas de repente começa a ficar mais lento.
Imagine que somos confrontados com a tarefa de transformar os elementos de uma matriz em uma coleção. O mais lógico seria usar o Collection::addAll , mas aqui está a má sorte - ele aceita a coleção:
public interface Collection<E> extends Iterable<E> { boolean addAll(Collection<? extends E> c); }
A maneira mais fácil é Arrays::asList a matriz em Arrays::asList . Acontecerá algo como
boolean addItems(Collection<T> collection) { T[] items = getArray(); return collection.addAll(Arrays.asList(items)); }
Durante a revisão, colegas preocupados com o desempenho provavelmente nos dirão que existem dois problemas neste código ao mesmo tempo:
- agrupando uma matriz em uma lista (objeto extra)
- criando um iterador (outro objeto extra) e passando por ele
De fato, na implementação de referência de Collection::addAll , veremos isso:
public abstract class AbstractCollection<E> implements Collection<E> { public boolean addAll(Collection<? extends E> c) { boolean modified = false; for (E e : c) { if (add(e)) modified = true; } return modified; } }
Portanto, um iterador é criado aqui e os elementos são classificados usando-o. Portanto, camaradas experientes oferecem sua solução:
boolean addItems(Collection<T> collection) { T[] items = getArray(); return Collections.addAll(collection, items); }
Dentro do código, com razão, parecendo mais produtivo:
public static <T> boolean addAll(Collection<? super T> c, T... elements) { boolean result = false; for (T element : elements) result |= c.add(element); return result; }
Primeiro, um iterador não é criado. Em segundo lugar, o passe passa no ciclo de contagem usual, além disso, as matrizes se encaixam bem nos caches, seus elementos estão localizados na memória sequencialmente (o que significa que haverá poucas falhas de cache) e o acesso a eles pelo índice é muito rápido. Bem, também não é criada uma lista de wrapper. Parece bom e bom som.
Finalmente, os colegas citam ultima ratio regum: documentation. E ali, cinza no branco (ou verde no preto) diz:
@SafeVarargs public static <T> boolean addAll(Collection<? super T> c, T... elements) {
Ou seja, os próprios desenvolvedores (e em quem eles devem acreditar, se não eles?) Escreva que, para a maioria das implementações, o método utilitário funciona muito mais rápido. E ele é realmente mais rápido. As vezes
A referência , que lançaremos para o HashSet no G8, ajudará a HashSet :
Benchmark (collection) (size) Mode Cnt Score Error Units addAll HashSet 10 avgt 100 155,2 ± 2,8 ns/op addAll HashSet 100 avgt 100 1884,4 ± 37,4 ns/op addAll HashSet 1000 avgt 100 17917,3 ± 298,8 ns/op collectionsAddAll HashSet 10 avgt 100 136,1 ± 0,8 ns/op collectionsAddAll HashSet 100 avgt 100 1538,3 ± 31,4 ns/op collectionsAddAll HashSet 1000 avgt 100 15168,6 ± 289,4 ns/op
Parece que os camaradas mais experientes estavam certos. Quase.
Nas edições posteriores (por exemplo, em 11), o brilho do método utilitário desaparecerá um pouco:
Benchmark (collection) (size) Mode Cnt Score Error Units addAll HashSet 10 avgt 100 143,1 ± 0,6 ns/op addAll HashSet 100 avgt 100 1738,4 ± 7,3 ns/op addAll HashSet 1000 avgt 100 16853,9 ± 101,0 ns/op collectionsAddAll HashSet 10 avgt 100 132,1 ± 1,1 ns/op collectionsAddAll HashSet 100 avgt 100 1661,1 ± 7,1 ns/op collectionsAddAll HashSet 1000 avgt 100 15450,9 ± 93,9 ns/op
Pode-se ver que não estamos falando de nenhum "muito mais rápido". E se repetirmos o experimento para ArrayList -a, acontece que o método utilitário começa a perder muito (quanto mais forte):
Benchmark (collection) (size) Mode Cnt Score Error Units JDK 8 addAll ArrayList 10 avgt 100 38,5 ± 0,5 ns/op addAll ArrayList 100 avgt 100 188,4 ± 7,0 ns/op addAll ArrayList 1000 avgt 100 1278,8 ± 42,9 ns/op collectionsAddAll ArrayList 10 avgt 100 62,7 ± 0,7 ns/op collectionsAddAll ArrayList 100 avgt 100 495,1 ± 2,0 ns/op collectionsAddAll ArrayList 1000 avgt 100 4892,5 ± 48,0 ns/op JDK 11 addAll ArrayList 10 avgt 100 26,1 ± 0,0 ns/op addAll ArrayList 100 avgt 100 161,1 ± 0,4 ns/op addAll ArrayList 1000 avgt 100 1276,7 ± 3,7 ns/op collectionsAddAll ArrayList 10 avgt 100 41,6 ± 0,0 ns/op collectionsAddAll ArrayList 100 avgt 100 492,6 ± 1,5 ns/op collectionsAddAll ArrayList 1000 avgt 100 6792,7 ± 165,5 ns/op
Não há nada inesperado aqui, o ArrayList construído em torno de um array, portanto os desenvolvedores redefiniram de maneira previdente o Collection::addAll :
public boolean addAll(Collection<? extends E> c) { Object[] a = c.toArray(); modCount++; int numNew = a.length; if (numNew == 0) return false; Object[] elementData; final int s; if (numNew > (elementData = this.elementData).length - (s = size)) elementData = grow(s + numNew); System.arraycopy(a, 0, elementData, s, numNew); <--- size = s + numNew; return true; }
Agora de volta às nossas minas. Suponha que, no entanto, aceitemos a solução proposta na revisão e deixemos este código:
boolean addItems(Collection<T> collection) { T[] items = getArray(); return Collections.addAll(collection, items); }
Por enquanto, está tudo bem, mas depois de adicionar novas funcionalidades, o método às vezes fica quente e começa a desacelerar. Abrimos códigos fonte - o código não mudou. A quantidade de dados é a mesma. E o desempenho caiu muito. Este é outro tipo meu.
Descubra o depurador e encontre o belo:

Observe: não alteramos o algoritmo, a quantidade de dados processados não mudou, mas sua natureza mudou e um problema de desempenho foi iniciado em nosso código:
Java 8 Java 11 addAll 10 56,9 25,2 ns/op collectionsAddAll 10 352,2 142,9 ns/op addAll 100 159,9 84,3 ns/op collectionsAddAll 100 4607,1 3964,3 ns/op addAll 1000 1244,2 760,2 ns/op collectionsAddAll 1000 355796,9 364677,0 ns/op
Em matrizes grandes, a diferença entre Collections::addAll e Collection::addAll é modesta em 500 vezes. O fato é que COWList não apenas expande a matriz existente, mas cria uma nova sempre que elementos são adicionados:
public boolean add(E e) { synchronized (lock) { Object[] es = getArray(); int len = es.length; es = Arrays.copyOf(es, len + 1); <---- es[len] = e; setArray(es); return true; } }
Quem é o culpado?
O principal problema aqui é que o Collections::addAll aceita uma interface, enquanto o método addAll não addAll corpo. Nenhum corpo - nenhum negócio, portanto, a documentação é escrita com base na implementação existente em AbstractCollection::addAll , que é um algoritmo generalizado aplicável a todas as coleções. Isso significa que implementações mais específicas de estruturas de dados que estão em um nível mais baixo de abstração podem alterar esse comportamento.
Agora humanamente Collection::addAll – AbstractCollection::addAll – <--- ArrayList::addAll HashSet::addAll – <--- COWList::addAll
Mais sobre abstrações
Já que estamos falando de níveis de abstração, vou lhe contar um exemplo da vida.
Vamos comparar essas duas maneiras de salvar o enésimo número de entidades no banco de dados:
@Transactional void save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.save(e); } } @Transactional void _save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.saveAndFlush(e); } }
À primeira vista, o desempenho de ambos os métodos não deve ser muito diferente, porque
- nos dois casos, o mesmo número de entidades será armazenado no banco de dados
- se a tecla for retirada da sequência, o número de chamadas será o mesmo
- a quantidade de dados transferidos é a mesma
SimpleJpaRepository::saveAndFlush para o SimpleJpaRepository::saveAndFlush :
@Transactional public <S extends T> S save(S entity) { if (entityInformation.isNew(entity)) { em.persist(entity); return entity; } else { return em.merge(entity); } } @Transactional public <S extends T> S saveAndFlush(S entity) { S result = save(entity); flush(); return result; } @Transactional public void flush() { em.flush(); }
O ponto escuro aqui é o método flush() . Por que burro? Parece-me que sua divulgação na interface JpaRepository foi um erro dos desenvolvedores. Vou tentar justificar meu pensamento. Normalmente, esse método não é usado pelo desenvolvedor, porque a chamada para EntityManager::flush vinculada à conclusão de uma transação controlada pelo Spring:
Observe: O EntityManager faz parte da especificação JPA implementada no Hibernate como uma sessão (interface Session e classe SessionImpl, respectivamente). Spring Date é uma estrutura executada em cima de um ORM, neste caso, em cima do Hibernate. Acontece que o JpaRepository::saveAndFlush nos dá acesso aos níveis mais baixos da API, embora a tarefa da estrutura seja ocultar os detalhes de baixo nível (a situação é um pouco semelhante à história insegura no JDK).
No nosso caso, ao usar JpaRepository::saveAndFlush entramos nas camadas inferiores do aplicativo, quebrando algo.
Tome seu tempo para espreitar, pense por si mesmoA capacidade do Hibernate de enviar dados em lotes está quebrada, um múltiplo da configuração jdbc.batch_size , especificada em application.yml :
spring: jpa: properties: hibernate: jdbc.batch_size: 500
O trabalho do Hibernate é baseado em eventos, portanto, quando você salva 1000 entidades como esta
@Transactional void save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.save(e); } }
chamar repository.save(e) não salva instantaneamente. Em vez disso, é criado um evento que está na fila. Após a conclusão da transação, os dados são mesclados usando EntityManager::flush , que divide as inserções / atualizações em vários pacotes de jdbc.batch_size e cria solicitações a partir deles. No nosso caso, jdbc.batch_size: 500 , portanto, salvar 1000 entidades na realidade significa apenas 2 solicitações.
Mas com uma descarga manual da sessão a cada passagem do ciclo
@Transactional void _save(int n) { for (int i = 0; i < n; i++) { SimpleEntity e = new SimpleEntity(); repository.saveAndFlush(e); } }
a fila é limpa e salvar 1000 entidades significa 1000 consultas.
Assim, interferir nas camadas inferiores do aplicativo pode facilmente se tornar uma mina, e não apenas uma mina de produtividade (consulte Inseguro e seu uso não controlado).
Quanto diminui a velocidade? Tome o melhor caso (para nós) - o banco de dados está no mesmo host que o aplicativo. Minha medida mostra a seguinte imagem:
(entityCount) Mode Cnt Score Error Units bulkSave 10 ss 500 16,613 ± 1,714 ms/op bulkSave 100 ss 500 31,371 ± 1,453 ms/op bulkSave 1000 ss 500 35,687 ± 1,973 ms/op bulkSaveUsingFlush 10 ss 500 32,653 ± 2,166 ms/op bulkSaveUsingFlush 100 ss 500 61,983 ± 6,304 ms/op bulkSaveUsingFlush 1000 ss 500 184,814 ± 6,976 ms/op
Obviamente, se o banco de dados estiver localizado em um host remoto, o custo da transferência de dados diminuirá cada vez mais o desempenho à medida que o volume de dados aumenta.
Assim, trabalhar no nível errado de abstração pode facilmente criar uma bomba-relógio. A propósito, em um dos meus artigos anteriores , falei sobre uma tentativa curiosa de melhorar o StringBuilder -a: lá não StringBuilder êxito exatamente ao tentar entrar em um nível de código mais abstrato.
Fronteiras do campo minado
Vamos jogar um sapador? Encontre o meu:
Encontrou? Verifique a resposta correta. "Você está brincando comigo?", Exclama o crítico. "Mas há apenas uma colagem de duas linhas? O que isso significa em E. sangrenta?" Deixe-me chamar sua atenção para o fato de eu destacar não apenas a colagem de strings, mas também o nome da classe e o nome do método. De fato, o perigo de colar strings não está em si mesmo, mas no que acontece no método que cria as chaves para o cache, ou seja, em certos cenários, teremos muitos acessos a esse método, o que significa muitas linhas de lixo.
Portanto, uma mensagem de erro deve ser criada apenas quando esse erro é realmente lançado:
Assim, os campos minados têm limites - é a quantidade de dados, a frequência de acesso ao método, etc. indicadores quantitativos, ao atingir e exceder os quais uma leve desvantagem se torna estatisticamente significativa.
Por outro lado, esse é o recurso, ao qual a complicação do código não oferece uma melhoria significativa (mensurável).
Essa é outra conclusão para o desenvolvedor: na maioria dos casos, enganar é ruim, levando a uma complicação sem sentido do código. Em 99 casos em 100, não ganhamos nada.
Deve-se lembrar que sempre há
O centésimo caso
Aqui está o código que Nitzan Wakart fornece em seu artigo A volátil surpresa de leitura :
@BenchmarkMode(Mode.AverageTime) @OutputTimeUnit(TimeUnit.NANOSECONDS) @State(Scope.Thread) public class LoopyBenchmarks { @Param({ "32", "1024", "32768" }) int size; byte[] bunn; @Setup public void prepare() { bunn = new byte[size]; } @Benchmark public void goodOldLoop(Blackhole fox) { for (int y = 0; y < bunn.length; y++) {
Quando configuramos a experiência, descobriremos uma diferença incrível entre as duas maneiras de iterar em uma matriz:
Benchmark (size) Score Score error Units goodOldLoop 32 46.630 0.097 ns/op goodOldLoop 1024 1199.338 0.705 ns/op goodOldLoop 32768 37813.600 56.081 ns/op sweetLoop 32 19.304 0.010 ns/op sweetLoop 1024 475.141 1.227 ns/op sweetLoop 32768 14295.800 36.071 ns/op
Aqui, um desenvolvedor inexperiente pode fazer uma conclusão tão óbvia e comparada: passar por uma matriz usando a nova sintaxe funciona mais rápido que um ciclo de contagem. Esta é a conclusão errada, porque vale a pena alterar um goodOldLoop o método goodOldLoop :
@Benchmark public void goodOldLoopReturns(Blackhole fox) { byte[] sunn = bunn;
e seu desempenho é comparável ao do método sweetLoop "mais rápido":
Benchmark (size) Score Score error Units goodOldLoopReturns 32 19.306 0.045 ns/op goodOldLoopReturns 1024 476.493 1.190 ns/op goodOldLoopReturns 32768 14292.286 16.046 ns/op sweetLoop 32 19.304 0.010 ns/op sweetLoop 1024 475.141 1.227 ns/op sweetLoop 32768 14295.800 36.071 ns/op
Blackhole::consume :
, , . goodOldLoop this.bunn , for-each , (, Java Concurrency In Practice " "). .
: " ? , Blackhole::consume — JMH . , , ?"
:
byte[] bunn; public void goodOldLoop(Blackhole fox) { for (int y = 0; y < bunn.length; y++) { fox.consume(bunn[y]); } }
? ? , :
E[] bunn; public void forEach(Consumer<E> fox) { for (int y = 0; y < bunn.length; y++) { fox.consume(bunn[y]); } }
Iterable::forEach ! , , , ( JDK 13):
, . , Collections.nCopies()::forEach :
@Override public void forEach(final Consumer<? super E> action) { Objects.requireNonNull(action); for (int i = 0; i < this.n; i++) { action.accept(this.element); } }
, . . this.n this.element :
private static class CopiesList<E> extends AbstractList<E> implements RandomAccess, Serializable { final int n; final E element; CopiesList(int n, E e) { assert n >= 0; this.n = n; element = e; }
, , @Stable .
: 99 100 , , 1 100, . , .
" volatile".
, :
- , ( java.lang.Integer , java.lang.Long , java.lang.Short , java.lang.Byte , java.lang.Character ). , ,
Integer intgr = Integer.valueOf(42);
.
:
Integer intgr = new Integer(42);
, , Integer::valueOf .
: . , , "" ( ). , , Integer::valueOf . " " .
. , . , . , , .