
O Apache Spark hoje é talvez a plataforma mais popular para analisar dados de grande volume. Uma contribuição considerável para sua popularidade é feita pela possibilidade de usá-lo no Python. Ao mesmo tempo, todos concordam que, dentro da estrutura da API padrão, o desempenho do código Python e Scala / Java é comparável, mas não há um ponto de vista único em relação às funções definidas pelo usuário (User Defined Function, UDF). Vamos tentar descobrir como os custos indiretos aumentam nesse caso, usando o exemplo da tarefa de verificar a solução SNA Hackathon 2019 .
Como parte da competição, os participantes resolvem o problema de classificar o feed de notícias de uma rede social e enviar soluções na forma de um conjunto de listas classificadas. Para verificar a qualidade da solução obtida, primeiro, para cada uma das listas carregadas, a AUC do ROC é calculada e, em seguida, o valor médio é exibido. Observe que você precisa calcular não um ROC AUC comum, mas pessoal para cada usuário - não há um projeto pronto para resolver esse problema, portanto você terá que escrever uma função especializada. Uma boa razão para comparar as duas abordagens na prática.
Como uma plataforma de comparação, usaremos um contêiner na nuvem com quatro núcleos e o Spark lançado no modo local e trabalharemos com ele através do Apache Zeppelin . Para comparar a funcionalidade, espelharemos o mesmo código no PySpark e Scala Spark. [aqui] Vamos começar carregando os dados.
data = sqlContext.read.csv("sna2019/modelCappedSubmit") trueData = sqlContext.read.csv("sna2019/collabGt") toValidate = data.withColumnRenamed("_c1", "submit") \ .join(trueData.withColumnRenamed("_c1", "real"), "_c0") \ .withColumnRenamed("_c0", "user") \ .repartition(4).cache() toValidate.count()
val data = sqlContext.read.csv("sna2019/modelCappedSubmit") val trueData = sqlContext.read.csv("sna2019/collabGt") val toValidate = data.withColumnRenamed("_c1", "submit") .join(trueData.withColumnRenamed("_c1", "real"), "_c0") .withColumnRenamed("_c0", "user") .repartition(4).cache() toValidate.count()
Ao usar a API padrão, a identidade quase completa do código é digna de nota, até a palavra-chave val . O tempo de operação não é significativamente diferente. Agora vamos tentar determinar a UDF que precisamos.
parse = sqlContext.udf.register("parse", lambda x: [int(s.strip()) for s in x[1:-1].split(",")], ArrayType(IntegerType())) def auc(submit, real): trueSet = set(real) scores = [1.0 / (i + 1) for i,x in enumerate(submit)] labels = [1.0 if x in trueSet else 0.0 for x in submit] return float(roc_auc_score(labels, scores)) auc_udf = sqlContext.udf.register("auc", auc, DoubleType())
val parse = sqlContext.udf.register("parse", (x : String) => x.slice(1,x.size - 1).split(",").map(_.trim.toInt)) case class AucAccumulator(height: Int, area: Int, negatives: Int) val auc_udf = sqlContext.udf.register("auc", (byScore: Seq[Int], gt: Seq[Int]) => { val byLabel = gt.toSet val accumulator = byScore.foldLeft(AucAccumulator(0, 0, 0))((accumulated, current) => { if (byLabel.contains(current)) { accumulated.copy(height = accumulated.height + 1) } else { accumulated.copy(area = accumulated.area + accumulated.height, negatives = accumulated.negatives + 1) } }) (accumulator.area).toDouble / (accumulator.negatives * accumulator.height) })
Ao implementar uma função específica, fica claro que o Python é mais conciso, principalmente devido à capacidade de usar a função interna de scikit-learn . No entanto, existem momentos desagradáveis - você deve especificar explicitamente o tipo do valor de retorno, enquanto que no Scala é determinado automaticamente. Vamos executar a operação:
toValidate.select(auc_udf(parse("submit"), parse("real"))).groupBy().avg().show()
toValidate.select(auc_udf(parse($"submit"), parse($"real"))).groupBy().avg().show()
O código parece quase idêntico, mas os resultados são desanimadores.

A implementação no PySpark funcionou um minuto e meio em vez de dois segundos no Scala, ou seja, o Python ficou 45 vezes mais lento . Durante a execução, o topo mostra 4 processos Python ativos em execução a toda velocidade, e isso sugere que o Bloqueio Global de Intérpretes não cria problemas aqui. Mas! Talvez o problema esteja na implementação interna do scikit-learn - vamos tentar reproduzir o código Python literalmente, sem recorrer a bibliotecas padrão.
def auc(submit, real): trueSet = set(real) height = 0 area = 0 negatives = 0 for candidate in submit: if candidate in trueSet: height = height + 1 else: area = area + height negatives = negatives + 1 return float(area) / (negatives * height) auc_udf_modified = sqlContext.udf.register("auc_modified", auc, DoubleType()) toValidate.select(auc_udf_modified(parse("submit"), parse("real"))).groupBy().avg().show()

O experimento mostra resultados interessantes. Por um lado, com essa abordagem, a produtividade foi nivelada, mas, por outro, o laconicismo desapareceu. Os resultados obtidos podem indicar que, ao trabalhar em Python usando módulos C ++ adicionais, são exibidas despesas significativas para alternar entre contextos. Obviamente, há uma sobrecarga semelhante ao usar o JNI no Java / Scala, no entanto, não tive que lidar com exemplos de degradação 45 vezes ao usá-los.
Para uma análise mais detalhada, realizaremos duas experiências adicionais: usando o Python puro sem Spark para medir a contribuição da chamada do pacote e com o aumento do tamanho dos dados no Spark para amortizar a sobrecarga e obter uma comparação mais precisa.
def parse(x): return [int(s.strip()) for s in x[1:-1].split(",")] def auc(submit, real): trueSet = set(real) height = 0 area = 0 negatives = 0 for candidate in submit: if candidate in trueSet: height = height + 1 else: area = area + height negatives = negatives + 1 return float(area) / (negatives * height) def sklearn_auc(submit, real): trueSet = set(real) scores = [1.0 / (i + 1) for i,x in enumerate(submit)] labels = [1.0 if x in trueSet else 0.0 for x in submit] return float(roc_auc_score(labels, scores))
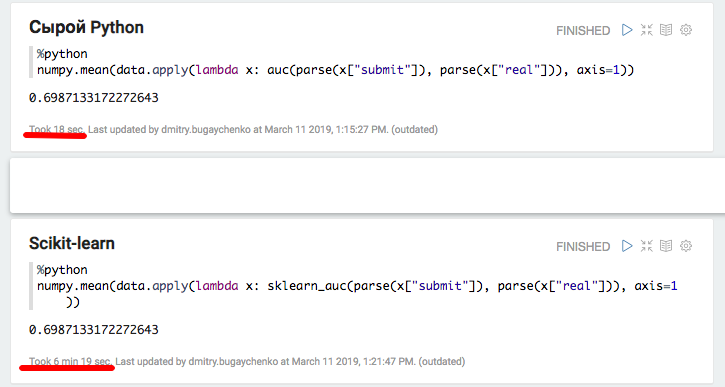
O experimento com Python local e Pandas confirmou a suposição de sobrecarga significativa ao usar pacotes adicionais - ao usar o scikit-learn, a velocidade diminui em mais de 20 vezes. No entanto, 20 não é 45 - vamos tentar "aumentar" os dados e comparar o desempenho do Spark novamente.
k4 = toValidate.union(toValidate) k8 = k4.union(k4) m1 = k8.union(k8) m2 = m1.union(m1) m4 = m2.union(m2).repartition(4).cache() m4.count()

A nova comparação mostra a vantagem de velocidade de uma implementação Scala sobre Python em 7-8 vezes - 7 segundos versus 55. Finalmente, vamos tentar "o mais rápido que está em Python" - numpy para calcular a soma da matriz:
import numpy numpy_sum = sqlContext.udf.register("numpy_sum", lambda x: float(numpy.sum(x)), DoubleType())
val my_sum = sqlContext.udf.register("my_sum", (x: Seq[Int]) => x.map(_.toDouble).sum)
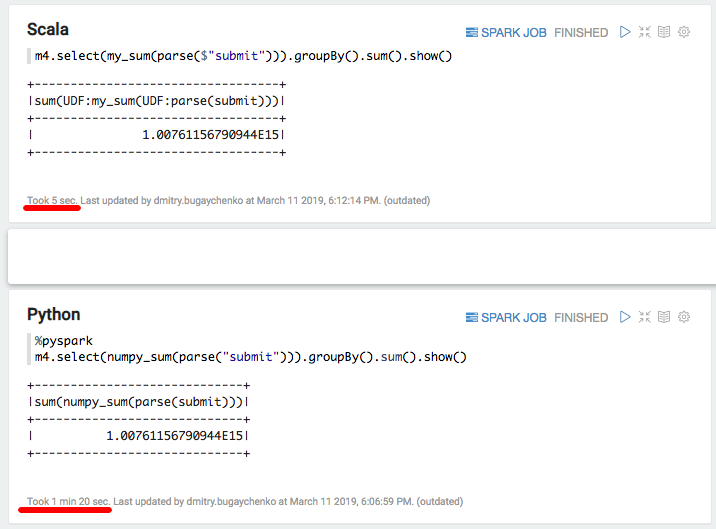
Novamente uma desaceleração significativa - 5 segundos de Scala versus 80 segundos de Python. Em resumo, podemos tirar as seguintes conclusões:
- Embora o PySpark opere dentro da estrutura da API padrão, ele pode ser realmente comparável em velocidade ao Scala.
- Quando a lógica específica aparece na forma de Funções definidas pelo usuário, o desempenho do PySpark diminui visivelmente. Com informações suficientes, quando o tempo de processamento de um bloco de dados excede vários segundos, a implementação do Python é de 5 a 10 mais lenta devido à necessidade de mover dados entre processos e desperdiçar recursos na interpretação do Python.
- Se o uso de funções adicionais implementadas nos módulos C ++ aparecer, surgem custos adicionais de chamadas e a diferença entre Python e Scala aumenta de 10 a 50 vezes.
Como resultado, apesar de todo o charme do Python, seu uso em conjunto com o Spark nem sempre parece justificado. Se não houver muitos dados para tornar a sobrecarga do Python significativa, você deve pensar se o Spark é necessário aqui? Se houver muitos dados, mas o processamento ocorrer dentro da estrutura da API Spark SQL padrão, o Python é necessário aqui?
Se houver muitos dados e muitas vezes precisar lidar com tarefas que ultrapassam os limites da API do SQL, para executar a mesma quantidade de trabalho ao usar o PySpark, você precisará aumentar significativamente o cluster. Por exemplo, para Odnoklassniki, o custo das despesas de capital do cluster Spark aumentaria em muitas centenas de milhões de rublos. E se você tentar tirar proveito dos recursos avançados das bibliotecas do ecossistema Python, ou seja, o risco de abrandar não é apenas às vezes, mas uma ordem de magnitude.
Alguma aceleração pode ser obtida usando a funcionalidade relativamente nova das funções vetorizadas. Nesse caso, nenhuma linha é alimentada na entrada UDF, mas um pacote de várias linhas na forma de um Dataframe do Pandas. No entanto, o desenvolvimento dessa funcionalidade ainda não está concluído e, mesmo nesse caso, a diferença será significativa .
Uma alternativa seria manter uma extensa equipe de engenheiros de dados, capaz de atender rapidamente às necessidades dos cientistas de dados com funções adicionais. Ou mergulhar no mundo do Scala, já que não é tão difícil: muitas das ferramentas necessárias já existem , programas de treinamento aparecem que vão além do PySpark.