Alexander Rubin trabalha na Percona e se apresentou no
HighLoad ++ mais de uma vez, familiar aos participantes como um especialista em MySQL. É lógico supor que hoje falaremos sobre algo relacionado ao MySQL. É assim, mas apenas parcialmente, porque também falaremos sobre a
Internet das coisas . A história será meio divertida, especialmente sua primeira parte, na qual analisamos o dispositivo que Alexander criou para colher damascos. Essa é a natureza de um verdadeiro engenheiro - se você quer frutas, compra uma taxa.

Antecedentes
Tudo começou com um simples desejo de plantar uma árvore frutífera em sua área. Parece muito simples fazer isso - você vem à loja e compra uma muda. Mas na América, a primeira pergunta que os vendedores fazem é quanta luz solar a árvore receberá. Para Alexander, isso acabou sendo um mistério gigante - não se sabe ao certo quanto luz solar existe no local.
Para descobrir, um aluno pode sair diariamente para o quintal, ver a quantidade de sol e escrevê-lo em um caderno. Mas este não é o caso - é necessário equipar tudo e automatizá-lo.
Durante a apresentação, muitos exemplos foram executados e tocados ao vivo. Quer uma imagem mais completa do que no texto, mude para assistir ao vídeo.Portanto, para não registrar observações meteorológicas em um notebook, há um grande número de dispositivos para coisas na Internet - Raspberry Pi, o novo Raspberry Pi, Arduino - milhares de plataformas diferentes. Mas eu escolhi um dispositivo chamado
Particle Photon para este projeto. É muito fácil de usar, custa US $ 19 no site oficial.
A coisa boa sobre o Particle Photon é:
- Solução 100% na nuvem;
- Qualquer sensor é adequado, por exemplo, para o Arduino. Todos custam menos de um dólar.
Eu fiz esse dispositivo e coloquei na grama no local. Possui uma nuvem de dispositivo de partículas e um console. Este dispositivo se conecta via ponto de acesso Wi-Fi e envia dados: luz, temperatura e umidade. O testador durou 24 horas com uma bateria pequena, o que é muito bom.
Além disso, preciso não apenas medir a iluminação e transferi-las para o telefone (o que é realmente bom - posso ver em tempo real que tipo de iluminação tenho), mas também
armazenar dados . Para isso, naturalmente, como veterano do MySQL, escolhi o MySQL.
Como escrevemos dados no MySQL
Eu escolhi um esquema bastante complicado:
- Eu obtenho dados do console do Particle;
- Eu uso o Node.js para escrevê-los no MySQL.
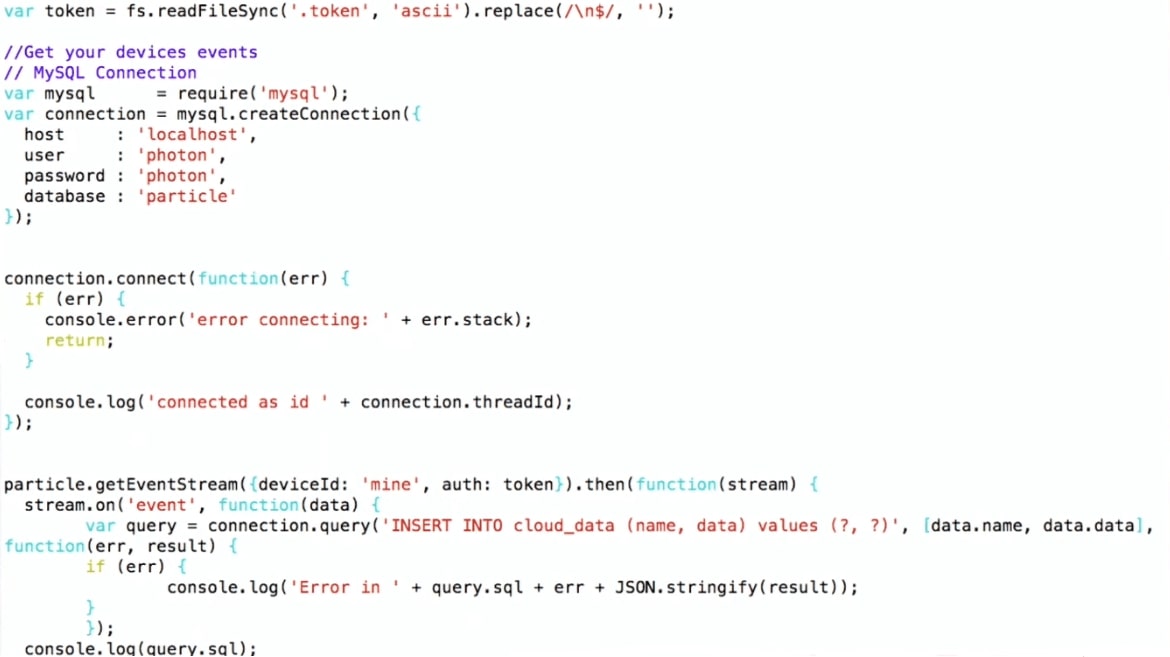
Estou usando a API Particle JS, que pode ser baixada no site da Particle. Eu estabeleço uma conexão com o MySQL e escrevo, ou seja, apenas insiro os valores INSERT INTO. Tal pipeline.
Assim, o dispositivo fica no quintal, se conecta via Wi-Fi ao roteador doméstico e, usando o protocolo MQTT, transfere dados para o Particle. Em seguida, o próprio esquema: o programa no Node.js é executado na máquina virtual, que recebe dados do Particle e os grava no MySQL.
Para começar, construí os gráficos a partir dos dados brutos em R. Os gráficos mostram que a temperatura e a iluminação aumentam durante o dia, caem à noite e a umidade aumenta - isso é natural. Mas também há ruído no gráfico, o que é típico para dispositivos da Internet das Coisas. Por exemplo, quando um bug entra no dispositivo e o fecha, o sensor pode transmitir dados completamente irrelevantes. Isso será importante para uma análise mais aprofundada.
Agora vamos falar sobre MySQL e JSON, o que mudou ao trabalhar com JSON do MySQL 5.7 para o MySQL 8. Em seguida, mostrarei uma demonstração para a qual uso o MySQL 8 (no momento do relatório, esta versão ainda não estava pronta para produção, uma versão estável já foi lançada).
Armazenamento de dados MySQL
Quando tentamos armazenar dados recebidos dos sensores, nosso primeiro pensamento é
criar uma tabela no MySQL :
CREATE TABLE 'sensor_wide' ( 'id' int (11) NOT NULL AUTO_INCREMENT, 'light' int (11) DEFAULT NULL, 'temp' double DEFAULT NULL, 'humidity' double DEFAULT NULL, PRIMARY KEY ('id') ) ENGINE=InnoDB
Aqui, para cada sensor e para cada tipo de dados, há uma coluna: luz, temperatura, umidade.
Isso é lógico o suficiente, mas
há um problema - não é flexível . Suponha que desejemos adicionar outro sensor e medir outra coisa. Por exemplo, algumas pessoas medem a cerveja restante em um barril. O que fazer neste caso?
alter table sensor_wide add water level double ...;
Como perverter para adicionar algo à tabela? Você precisa criar uma tabela de alteração, mas se você fez uma tabela de alteração no MySQL, então você sabe do que estou falando - isso é completamente difícil. Alterar tabela no MySQL 8 e MariaDB é muito mais simples, mas historicamente este é um grande problema. Portanto, se precisarmos adicionar uma coluna, por exemplo, com o nome da cerveja, não será tão simples.
Novamente, os sensores aparecem, desaparecem, o que devemos fazer com os dados antigos? Por exemplo, paramos de receber informações sobre iluminação. Ou estamos criando uma nova coluna - como armazenar o que não existia antes? A abordagem padrão é nula, mas, para análise, não será muito conveniente.
Outra opção é um armazenamento de chave / valor.
Armazenamento de dados MySQL: chave / valor
Isso será
mais flexível : em chave / valor, haverá um nome, por exemplo, temperatura e, consequentemente, dados.
CREATE TABLE 'cloud_data' ( 'id' int (11) NOT NULL AUTO_INCREMENT, 'name' varchar(255) DEFAULT NULL, 'data' text DEFAULT NULL, 'updated_at' timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP PRIMARY KEY ('id') ) ENGINE=InnoDB
Nesse caso,
outro problema aparece
- não há tipos . Não sabemos o que estamos armazenando no campo 'dados'. Teremos que declará-lo como um campo de texto. Quando crio meu dispositivo Internet of things, sei que tipo de sensor existe e, portanto, o tipo, mas se você precisar armazenar os dados de outra pessoa na mesma tabela, não saberei quais dados estão sendo coletados.
Você pode armazenar muitas tabelas, mas criar uma nova tabela inteira para cada sensor não é muito boa.
O que pode ser feito? - Use JSON.
Armazenamento de dados MySQL: JSON
A boa notícia é que no MySQL 5.7 você pode armazenar JSON como um campo.
CREATE TABLE 'cloud_data_json' ( 'id' int (11) NOT NULL AUTO_INCREMENT, 'name' varchar(255) DEFAULT NULL, 'data' JSON, 'updated_at' timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP PRIMARY KEY ('id') ) ENGINE=InnoDB;
Antes do MySQL 5.7 aparecer, as pessoas também armazenavam JSON, mas como um campo de texto. O campo JSON no MySQL permite armazenar o próprio JSON com mais eficiência. Além disso, com base no JSON, você pode criar colunas e índices virtuais com base neles.
O único pequeno problema é
que a tabela aumentará de tamanho durante o armazenamento . Mas então temos muito mais flexibilidade.
O campo JSON é melhor para armazenar JSON do que o campo de texto porque:
- Fornece validação automática de documentos . Ou seja, se tentarmos escrever algo que não é válido lá, ocorrerá um erro.
- Este é um formato de armazenamento otimizado . O JSON é armazenado no formato binário, que permite alternar de um documento JSON para outro - o que é chamado de ignorar.
Para armazenar dados em JSON, podemos simplesmente usar o SQL: faça um INSERT, coloque 'data' lá e obtenha dados do dispositivo.
… stream.on('event', function(data) { var query = connection.query( 'INSERT INTO cloud_data_json (client_name, data) VALUES (?, ?)', ['particle', JSON.stringify(data)] ) … (demo)
Demo
Para demonstrar (
aqui no começo do vídeo), o exemplo usa uma máquina virtual na qual existe SQL.

Abaixo está um fragmento do programa.
INSERT INTO cloud_data (name, data) , já obtenho os dados no formato JSON e posso gravá-los diretamente no MySQL, sem pensar no que está dentro.
Como se viu, usando essa nuvem, você pode acessar não apenas os dados do meu dispositivo, mas geralmente
todos os dados que esse Particle usa. Parece funcionar até agora. As pessoas que usam o Particle Photon em todo o mundo estão enviando alguns dados: a porta da garagem está aberta, ou o resto da cerveja é tal e tal ou algo mais. Não se sabe onde esses dispositivos estão localizados, mas esses dados podem ser obtidos. A única diferença é que, quando obtenho meus dados, escrevo algo como:
deviceId: 'mine' .
Quando executamos o código, obtemos um fluxo de alguns dados dos dispositivos de outras pessoas que estão fazendo algo.
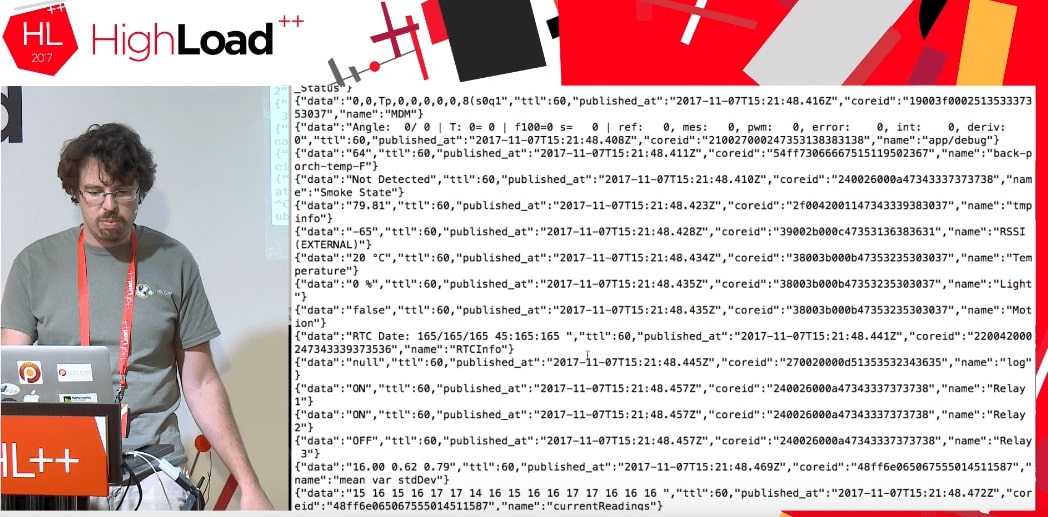
Não sabemos absolutamente o que são esses dados: TTL, publicado_at, coreid, status da porta (porta aberta), retransmitir.
Este é um ótimo exemplo. Suponha que eu tente colocar isso no MySQL em uma estrutura de dados normal. Eu deveria saber qual é a porta, por que está aberta e quais parâmetros gerais ela pode receber. Se eu tenho JSON, escrevo-o diretamente no MySQL como um campo JSON.
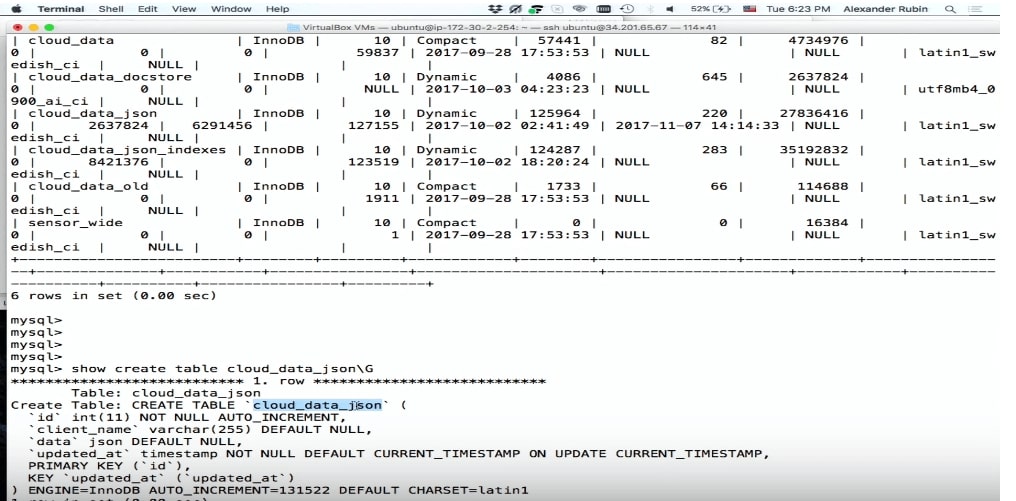
Por favor, tudo foi gravado.
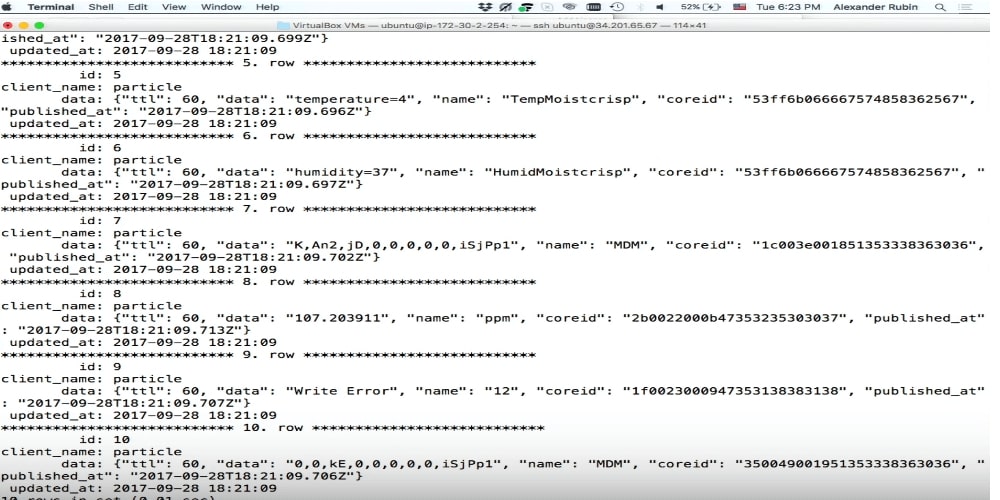
Armazenamento de documentos
O armazenamento de documentos é uma tentativa no MySQL de fazer armazenamento para JSON. Eu realmente amo SQL, estou familiarizado com ele, posso fazer qualquer consulta SQL, etc. Mas muitas pessoas não gostam do SQL por vários motivos, e o repositório de documentos pode ser uma solução para eles, porque com ele você pode abstrair do SQL, conectar-se ao MySQL e escrever JSON diretamente lá.

Existe outra possibilidade que apareceu no MySQL 5.7: usar um protocolo diferente, uma porta diferente e outro driver também é necessário. Para o Node.js (de fato, para qualquer linguagem de programação - PHP, Java etc.), nós nos conectamos ao MySQL usando um protocolo diferente e podemos transferir dados no formato JSON. Novamente, não sei o que tenho neste JSON - informações sobre portas ou qualquer outra coisa, apenas despejo os dados no MySQL e depois vamos descobrir.
const mysqlx = require('@mysql/xdevapi*); // MySQL Connection var mySession = mysqlx.gctSession({ host: 'localhost', port: 33060, dbUser: 'photon* }); … session.getSchema("particle").getCollection("cloud_data_docstore") .add( data ) .execute(function (row) { }).catch(err => { console.log(err); }) .then( -Function (notices) { console.log("Wrote to MySQL") }); ...https:
Se você quiser experimentar isso, pode configurar o MySQL 5.7 para que ele entenda e ouça no armazenamento de documentos da porta apropriada ou no X DevAPI. Eu usei connector-nodejs.
Este é um exemplo do que escrevo lá em baixo: cerveja, etc. Eu absolutamente não sei o que está lá. Agora, escrevemos e analisamos mais tarde.

O próximo ponto do nosso programa é como ver o que há lá?
Armazenamento de dados MySQL: índices JSON +
Há um ótimo recurso no JSON e no MySQL 5.7 que pode extrair campos do JSON. Esse é um açúcar sintático na função JSON_EXTRACT. Eu acho que isso é muito conveniente.
Os dados no nosso caso são o nome da coluna na qual o JSON está armazenado e o nome é o nosso campo. Nome, dados, publicado_at - é tudo o que podemos extrair dessa maneira.
select data->>'$.name' as data_name, data->>'$.data' as data, data->>'$.published_at' as published from cloud_data_json order by data->'$.published_at' desc limit 10;
Neste exemplo, quero ver o que escrevi na tabela MySQL e os últimos 10 registros. Eu faço esse pedido e tento executá-lo. Infelizmente,
isso funcionará por muito tempo .
De uma maneira lógica, o MySQL não utilizará nenhum índice nesse caso. Retiramos os dados do JSON e tentamos aplicar algum tipo de filtro e classificação. Nesse caso, obtemos Using filesort.
EXPLAIN select data->>'$.name' as data_name ... order by data->>'$.published_at' desc limit 10 select_type: SIMPLE table: cloud_data_json possible_keys: NULL key: NULL … rows: 101589 filtered: 100.00 Extra: Using filesort
O uso do filesort é muito ruim, é uma classificação externa.
A boa notícia é que você pode dar dois passos para acelerar.
Etapa 1. Crie uma coluna virtual
mysql> ALTER TABLE cloud_data_json -> ADD published_at DATETIME(6) -> GENERATED ALWAYS AS (STR_TO_DATE(data->>'$.published_at',"%Y-%m-%dT%T.%fZ")) VIRTUAL; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0
Eu faço EXTRACT, ou seja, extraio dados do JSON e, com base nele, crio uma coluna virtual. A coluna virtual não é armazenada no MySQL 5.7 e no MySQL 8 - é apenas a capacidade de criar uma coluna separada.
Você pergunta como é, você disse que o ALTER TABLE é uma operação tão longa. Mas aqui não é tão ruim.
Criar uma coluna virtual é rápido . Existe uma falha lá, mas na verdade no MySQL há um bloqueio em todas as operações DDL. ALTER TABLE é uma operação bastante rápida e não reconstrói a tabela inteira.
Criamos uma coluna virtual aqui. Eu tive que converter a data, porque no JSON ela é armazenada no formato iso, mas aqui o MySQL usa um formato completamente diferente. Para criar uma coluna, chamei-a, dei um tipo e disse que gravaria lá.
Para otimizar a consulta original, você precisa extrair o nome_da publicação. Published_at já existe, o nome é mais fácil - basta criar uma coluna virtual.
mysql> ALTER TABLE cloud_data_json -> ADD data_name VARCHAR(255) -> GENERATED ALWAYS AS (data->>'$.name') VIRTUAL; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0
Etapa 2. Criando um Índice
No código abaixo, eu crio um índice em publish_at e executo a consulta:
mysql> alter table cloud_data_json add key (published_at); Query OK, 0 rows affected (0.31 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> explain select data_name, published_at, data->>'$.data' as data from cloud_data_json order by published_at desc limit 10\G table: cloud_data_json type: index possible_keys: NULL key: published_at key_len: 9 rows: 10 filtered: 100.00 Extra: Backward index scan
Você pode ver que o MySQL realmente usa o índice. Esta é uma otimização por pedido. Neste exemplo, dados e nome não são indexados. O MySQL usa a ordem por dados e, como temos um índice em publish_at, ele o usa.
Além disso, eu poderia usar a mesma sintaxe açúcar
STR_TO_DATE(data->>'$.published_at',"%Y-%m-%dT%T.%fZ") vez de publicado_at em ordem. O MySQL ainda entenderia que existe um índice nesta coluna e começaria a usá-lo.
Na verdade, há um pequeno problema com isso. Suponha que eu queira classificar os dados não apenas por publish_at, mas também por nome.
mysql> explain select data_name, published_at, data->>'$.data' as data from cloud_data_json order by published_at desc, data_name asc limit 10\G select_type: SIMPLE table: cloud_data_json partitions: NULL type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 101589 filtered: 100.00 Extra: Using filesort
Se o seu dispositivo processar dezenas de milhares de eventos por segundo, o publish_at não fornecerá uma boa classificação, pois haverá duplicatas. Portanto, adicionamos outra classificação por data_name. Essa é uma consulta típica, não apenas para a Internet das coisas: forneça os últimos 10 eventos, mas os classifique por data e, por exemplo, pelo sobrenome da pessoa em ordem crescente. Para fazer isso, no exemplo acima, existem dois campos e duas chaves de classificação são especificadas: decrescente e crescente.
Primeiro de tudo, neste caso, o MySQL não usará índices. Nesse caso em particular, o MySQL decide que uma varredura completa de tabela será mais lucrativa do que usar um índice e, novamente, a operação muito lenta de separação de arquivos é usada.
Novo no MySQL 8.0
descendente / ascendente
No MySQL 5.7, essa consulta não pode ser otimizada, mesmo que à custa de outras coisas. No MySQL 8, havia uma oportunidade real de especificar a classificação para cada campo.
mysql> alter table cloud_data_json add key published_at_data_name (published_at desc, data_name asc); Query OK, 0 rows affected (0.44 sec) Records: 0 Duplicates: 0 Warnings: 0
O mais interessante é que a chave descendente / ascendente após o nome do índice está no SQL há muito tempo. Mesmo na primeira versão do MySQL 3.23, você poderia especificar o publish_at descending ou o publicado_at ascending. O MySQL aceitou isso,
mas não fez nada , ou seja, sempre classificou em uma direção.
No MySQL 8, isso foi corrigido e agora existe esse recurso. Você pode criar um campo em ordem decrescente e com classificação padrão.
Vamos voltar um segundo e ver o exemplo da etapa 2 novamente.
Por que funciona, caso contrário, não funciona? Isso funciona porque, nos índices do MySQL, é uma árvore B, e os índices da árvore B podem ser lidos desde o início e até o final. Nesse caso, o MySQL lê o índice do final e está tudo bem. Mas se fizermos descendente e ascendente, você não poderá ler. Você pode ler na mesma ordem, mas
não pode combinar duas classificações - é necessário reordenar.
Como estamos otimizando um caso muito específico, podemos criar um índice para ele e especificar uma classificação específica: aqui o publish_at está descendo, o data_name está subindo. O MySQL usa esse índice, e tudo ficará bem e rápido.
mysql> explain select data_name, published_at, data->>'$.data' as data from cloud_data_json order by published_at desc limit 10\G select_type: SIMPLE table: cloud_data_json partitions: NULL type: index possible_keys: NULL key: published_at_data_name key_len: 267 ref: NULL rows: 10 filtered: 100.00 Extra: NULL
Esse é um recurso do MySQL 8, que está agora, no momento da publicação, já disponível e pronto para uso na produção.
Resultados de Saída
Há mais duas coisas interessantes que quero mostrar:
1. Impressão bonita, ou seja, uma saída bonita de dados para a tela. Com o SELECT normal, o JSON não será formatado.
mysql> select json_pretty(data) from cloud_data_json where data->>'$.data' like '%beer%' limit 1\G … json_pretty(data): { "ttl": 60, "data": "FvGav,tagkey=beer-store spFridge=7.00,pvFridge=7.44", "name": "LOG_DATA_DEBUG", "coreid": "3600....", "published_at": "2017-09-28T18:21:16.517Z" }
2. Podemos dizer que o MySQL produzirá o resultado na forma de uma matriz JSON ou objeto JSON, especificar os campos e, em seguida, a saída será formatada como JSON.
Pesquisa de texto completo em documentos JSON
Se usarmos um sistema de armazenamento flexível e não soubermos o que está dentro do nosso JSON, seria lógico usar a pesquisa de texto completo.
Infelizmente,
a pesquisa de texto completo tem suas limitações . A primeira coisa que tentei foi apenas criar uma chave de texto completo. Eu tentei fazer uma coisa dessas:
mysql> alter table cloud_data_json_indexes add fulltext key (data); ERROR 3152 (42000): JSON column 'data' supports indexing only via generated columns on a specified ISON path.
Infelizmente isso não funciona. Mesmo no MySQL 8, criar um índice de texto completo simplesmente pelo campo JSON é infelizmente impossível. Obviamente, eu gostaria de ter essa função - a capacidade de pesquisar pelo menos pelas chaves JSON seria muito útil.
Mas se isso ainda não for possível, vamos criar uma coluna virtual. No nosso caso, há um campo de dados e seria interessante ver o que está dentro.
mysql> ALTER TABLE cloud_data_json_indexes -> ADD data_data VARCHAR(255) -> GENERATED ALWAYS AS (data->>'$.data') VIRTUAL; Query OK, 0 rows affected (0.01 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> alter table cloud_data_json_indexes add fulltext key ft_json(data_name, data_data); ERROR 3106 (HY000): 'Fulltext index on virtual generated column' is not supported for generated columns.
Infelizmente, isso também não funciona -
você não pode criar um índice de texto completo em uma coluna virtual .
Nesse caso, vamos criar uma coluna armazenada. O MySQL 5.7 permite declarar uma coluna como um campo armazenado.
mysql> ALTER TABLE cloud_data_json_indexes -> ADD data_name VARCHAR(255) CHARACTER SET UTF8MB4 -> GENERATED ALWAYS AS (data->>'$.name') STORED; Query OK, 123518 rows affected (1.75 sec) Records: 123518 Duplicates: 0 Warnings: 0 mysql> alter table cloud_data_json_indexes add fulltext key ft_json(data_name); Query OK, 0 rows affected, 1 warning (3.78 sec) Records: 0 Duplicates: 0 Warnings: 1 mysql> show warnings; +
Nos exemplos anteriores, criamos colunas virtuais que não são armazenadas, mas os índices são criados e armazenados. Nesse caso, eu tive que dizer ao MySQL que esta é uma coluna STORED, ou seja, ela será criada e os dados serão copiados para ela. Depois disso, o MySQL criou um índice de texto completo, para isso tivemos que recriar a tabela. Mas essa limitação é realmente a pesquisa de texto completo do InnoDB e do InnoDB: você precisa recriar a tabela para adicionar um identificador de pesquisa de texto completo especial.
Curiosamente, no MySQL 8 havia uma
nova codificação UTF8 MB4 para emoticons . Claro, não exatamente para eles, mas porque no UTF8MB3 existem alguns problemas com o russo, chinês, japonês e outros idiomas.
mysql> ALTER TABLE cloud_data_json_indexes -> ADD data_data TEXT CHARACTER SET UTF8MB4 -> GENERATED ALWAYS AS ( CONVERT(data->>'$.data' USING UTF8MB4) ) STORED Query OK, 123518 rows affected (3.14 sec) Records: 123518 Duplicates: 0 Warnings: 0
Assim, o MySQL 8 deve armazenar dados JSON em UTF8MB4. Mas, devido ao fato de o Node.js se conectar ao Device Cloud, e algo estar escrito lá incorretamente ou ser um bug da versão beta, isso não aconteceu. Portanto, tive que converter os dados antes de gravá-los em uma coluna armazenada.
mysql> ALTER TABLE cloud_data_json_indexes DROP KEY ft_json, ADD FULLTEXT KEY ft_json(data_name, data_data); Query OK, 0 rows affected (1.85 sec) Records: 0 Duplicates: 0 Warnings: 0
Depois disso, consegui criar uma pesquisa de texto completo em dois campos: no nome JSON e nos dados JSON.
Não apenas a IoT
JSON não é apenas a Internet das coisas. Pode ser usado para outras coisas interessantes:
- Campos personalizados (CMS);
- Estruturas complexas, etc;
Algumas coisas podem ser muito mais convenientemente implementadas usando um esquema flexível de armazenamento de dados. Um excelente exemplo foi fornecido no Oracle OpenWorld: reservas de cinema. É muito difícil implementar isso no modelo relacional - você obtém muitas tabelas dependentes, junções etc. Por outro lado, podemos armazenar a sala inteira como uma estrutura JSON, respectivamente, gravá-la no MySQL em outras tabelas e usá-la da maneira usual: criar índices com base no JSON, etc.
Estruturas complexas são convenientemente armazenadas no formato JSON.
Esta é uma árvore que foi plantada com sucesso. Infelizmente, alguns anos depois, o cervo comeu, mas essa é uma história completamente diferente.
Este relatório é um excelente exemplo de como uma seção inteira cresce de um tópico em uma grande conferência e depois de um evento separado. No caso da Internet das coisas, recebemos o InoThings ++ - uma conferência para profissionais do mercado da Internet das Coisas, que será realizada pela segunda vez em 4 de abril.
O evento central da conferência, ao que parece, será a mesa redonda “Precisamos de padrões nacionais na Internet das Coisas?”, Que organicamente será complementada por relatórios aplicados abrangentes. Venha se seus sistemas com muita carga estiverem se movendo corretamente para a IIoT.