
Ao longo dos anos em que operamos o Kubernetes em produção, acumulamos muitas histórias interessantes, pois bugs em vários componentes do sistema levavam a conseqüências desagradáveis e / ou incompreensíveis que afetam a operação de contêineres e vagens. Neste artigo, fizemos uma seleção de alguns dos mais frequentes ou interessantes. Mesmo que você nunca tenha a sorte de encontrar tais situações, ler sobre esses breves detetives - tanto em primeira mão - é sempre divertido, não é?
História 1. Docker supercrônico e congelante
Em um dos clusters, recebemos periodicamente um Docker congelado, que interferia no funcionamento normal do cluster. Ao mesmo tempo, o seguinte foi observado nos logs do Docker
level=error msg="containerd: start init process" error="exit status 2: \"runtime/cgo: pthread_create failed: No space left on device SIGABRT: abort PC=0x7f31b811a428 m=0 goroutine 0 [idle]: goroutine 1 [running]: runtime.systemstack_switch() /usr/local/go/src/runtime/asm_amd64.s:252 fp=0xc420026768 sp=0xc420026760 runtime.main() /usr/local/go/src/runtime/proc.go:127 +0x6c fp=0xc4200267c0 sp=0xc420026768 runtime.goexit() /usr/local/go/src/runtime/asm_amd64.s:2086 +0x1 fp=0xc4200267c8 sp=0xc4200267c0 goroutine 17 [syscall, locked to thread]: runtime.goexit() /usr/local/go/src/runtime/asm_amd64.s:2086 +0x1 …
Nesse erro, estamos mais interessados na mensagem:
pthread_create failed: No space left on device . Um rápido estudo da
documentação explicou que o Docker não pôde bifurcar o processo, o que causou o congelamento periódico.
Ao monitorar o que está acontecendo, a seguinte imagem corresponde:

Uma situação semelhante é observada em outros nós:


Nos mesmos nós, vemos:
root@kube-node-1 ~
Acontece que esse comportamento é uma consequência do trabalho do
pod com
supercronic (o utilitário Go que usamos para executar tarefas cron em pods):
\_ docker-containerd-shim 833b60bb9ff4c669bb413b898a5fd142a57a21695e5dc42684235df907825567 /var/run/docker/libcontainerd/833b60bb9ff4c669bb413b898a5fd142a57a21695e5dc42684235df907825567 docker-runc | \_ /usr/local/bin/supercronic -json /crontabs/cron | \_ /usr/bin/newrelic-daemon --agent --pidfile /var/run/newrelic-daemon.pid --logfile /dev/stderr --port /run/newrelic.sock --tls --define utilization.detect_aws=true --define utilization.detect_azure=true --define utilization.detect_gcp=true --define utilization.detect_pcf=true --define utilization.detect_docker=true | | \_ /usr/bin/newrelic-daemon --agent --pidfile /var/run/newrelic-daemon.pid --logfile /dev/stderr --port /run/newrelic.sock --tls --define utilization.detect_aws=true --define utilization.detect_azure=true --define utilization.detect_gcp=true --define utilization.detect_pcf=true --define utilization.detect_docker=true -no-pidfile | \_ [newrelic-daemon] <defunct> | \_ [curl] <defunct> | \_ [curl] <defunct> | \_ [curl] <defunct> …
O problema é o seguinte: quando uma tarefa começa em supercrônica, o processo gerado por ela
não pode ser concluído corretamente , transformando-se em um
zumbi .
Nota : Para ser mais preciso, os processos são gerados pelas tarefas cron, no entanto, supercronic não é um sistema init e não pode "adotar" os processos que seus filhos geraram. Quando os sinais SIGHUP ou SIGTERM ocorrem, eles não são transmitidos para os processos gerados, como resultado dos processos filhos não terminam, permanecendo no status de zumbi. Você pode ler mais sobre tudo isso, por exemplo, em um artigo desse tipo .Existem algumas maneiras de resolver problemas:
- Como solução temporária - aumente o número de PIDs no sistema em um único momento:
/proc/sys/kernel/pid_max (since Linux 2.5.34) This file specifies the value at which PIDs wrap around (ie, the value in this file is one greater than the maximum PID). PIDs greater than this value are not allo‐ cated; thus, the value in this file also acts as a system-wide limit on the total number of processes and threads. The default value for this file, 32768, results in the same range of PIDs as on earlier kernels
- Ou faça o lançamento de tarefas no supercronic não diretamente, mas com a ajuda do mesmo tini , capaz de finalizar corretamente os processos e não gerar um zumbi.
Histórico 2. "Zumbis" ao remover o cgroup
O Kubelet começou a consumir muita CPU:
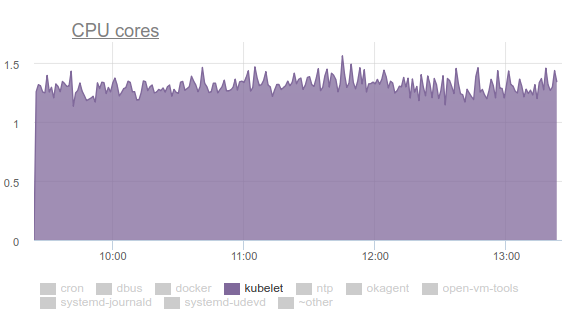
Ninguém gosta disso, então nos
preparamos com
perf e começamos a lidar com o problema. Os resultados da investigação foram os seguintes:
- O Kubelet gasta mais de um terço do tempo da CPU puxando dados da memória de todos os cgroups:

- Na lista de discussão dos desenvolvedores do kernel, você pode encontrar uma discussão sobre o problema . Resumindo, a conclusão é que diferentes arquivos tmpfs e outras coisas semelhantes não são completamente removidos do sistema quando o cgroup é excluído - o chamado zumbi memcg permanece. Mais cedo ou mais tarde, eles ainda serão removidos do cache da página, mas a memória no servidor é grande e o kernel não vê o ponto de perder tempo. Portanto, eles continuam a se acumular. Por que isso está acontecendo? Este é um servidor com tarefas cron que constantemente cria novas tarefas e, com elas, novos pods. Assim, novos cgroups são criados para contêineres neles, que serão excluídos em breve.
- Por que o cAdvisor em kubelet gasta tanto tempo? Isso é facilmente visto pela execução mais simples do
time cat /sys/fs/cgroup/memory/memory.stat . Se a operação demorar 0,01 segundos em uma máquina íntegra, 1,2 segundos em um cron02 problemático. O problema é que o cAdvisor, que lê os dados do sysfs muito lentamente, também leva em consideração a memória usada nos cgroups de zumbis. - Para remover zumbis à força, tentamos limpar os caches, conforme recomendado em LKML:
sync; echo 3 > /proc/sys/vm/drop_caches sync; echo 3 > /proc/sys/vm/drop_caches , mas o kernel acabou por ser mais complicado e travou a máquina.
O que fazer? O problema foi corrigido (
confirmação e descrição, veja
a mensagem de lançamento ) atualizando o kernel do Linux para a versão 4.16.
História 3. Systemd e sua montagem
Novamente, o kubelet consome muitos recursos em alguns nós, mas desta vez já é memória:

Aconteceu que há um problema no systemd usado no Ubuntu 16.04, e isso ocorre ao controlar as montagens criadas para conectar
subPath partir do ConfigMaps ou de segredos. Após a conclusão do pod, o
serviço systemd e sua montagem de serviço permanecem no sistema. Com o tempo, eles acumulam uma quantidade enorme. Existem até questões sobre este tópico:
- pulos # 5916 ;
- kubernetes # 57345 .
... no último dos quais se refere ao PR no systemd:
# 7811 (o problema no systemd é
# 7798 ).
O problema não está mais no Ubuntu 18.04, mas se você quiser continuar usando o Ubuntu 16.04, nossa solução alternativa para este tópico pode ser útil.
Então, criamos o seguinte DaemonSet:
--- apiVersion: extensions/v1beta1 kind: DaemonSet metadata: labels: app: systemd-slices-cleaner name: systemd-slices-cleaner namespace: kube-system spec: updateStrategy: type: RollingUpdate selector: matchLabels: app: systemd-slices-cleaner template: metadata: labels: app: systemd-slices-cleaner spec: containers: - command: - /usr/local/bin/supercronic - -json - /app/crontab Image: private-registry.org/systemd-slices-cleaner/systemd-slices-cleaner:v0.1.0 imagePullPolicy: Always name: systemd-slices-cleaner resources: {} securityContext: privileged: true volumeMounts: - name: systemd mountPath: /run/systemd/private - name: docker mountPath: /run/docker.sock - name: systemd-etc mountPath: /etc/systemd - name: systemd-run mountPath: /run/systemd/system/ - name: lsb-release mountPath: /etc/lsb-release-host imagePullSecrets: - name: antiopa-registry priorityClassName: cluster-low tolerations: - operator: Exists volumes: - name: systemd hostPath: path: /run/systemd/private - name: docker hostPath: path: /run/docker.sock - name: systemd-etc hostPath: path: /etc/systemd - name: systemd-run hostPath: path: /run/systemd/system/ - name: lsb-release hostPath: path: /etc/lsb-release
... e usa o seguinte script:
... e começa a cada 5 minutos com o supercrônico já mencionado. O arquivo Dockerfile fica assim:
FROM ubuntu:16.04 COPY rootfs / WORKDIR /app RUN apt-get update && \ apt-get upgrade -y && \ apt-get install -y gnupg curl apt-transport-https software-properties-common wget RUN add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu xenial stable" && \ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt-key add - && \ apt-get update && \ apt-get install -y docker-ce=17.03.0* RUN wget https://github.com/aptible/supercronic/releases/download/v0.1.6/supercronic-linux-amd64 -O \ /usr/local/bin/supercronic && chmod +x /usr/local/bin/supercronic ENTRYPOINT ["/bin/bash", "-c", "/usr/local/bin/supercronic -json /app/crontab"]
História 4. Competição no planejamento de pods
Observou-se que: se um pod é colocado em nosso nó e sua imagem é bombeada por um período muito longo, o outro pod que "chegou" ao mesmo nó simplesmente
não começa a puxar a imagem do novo pod . Em vez disso, ele espera que a imagem do pod anterior seja puxada. Como resultado, um pod que já foi planejado e cuja imagem pode ser baixada em apenas um minuto terminará no status
containerCreating por um longo tempo.
Nos eventos, haverá algo parecido com isto:
Normal Pulling 8m kubelet, ip-10-241-44-128.ap-northeast-1.compute.internal pulling image "registry.example.com/infra/openvpn/openvpn:master"
Acontece que
uma única imagem do registro lento pode bloquear a implantação no nó.
Infelizmente, não há muitas maneiras de sair da situação:
- Tente usar o Docker Registry diretamente no cluster ou diretamente com o cluster (por exemplo, GitLab Registry, Nexus etc.);
- Use utilitários como o kraken .
Histórico 5. Pendurar nós com memória insuficiente
Durante a operação de vários aplicativos, também recebemos uma situação em que o nó deixa completamente de ser acessível: o SSH não responde, todos os daemons de monitoramento caem e, em seguida, nada (ou quase nada) é anormal nos logs.
Vou lhe dizer nas imagens no exemplo de um nó em que o MongoDB funcionava.
É assim que o topo fica
antes do acidente:

E assim -
após o acidente:

Também no monitoramento, há um salto acentuado no qual o nó deixa de ser acessível:
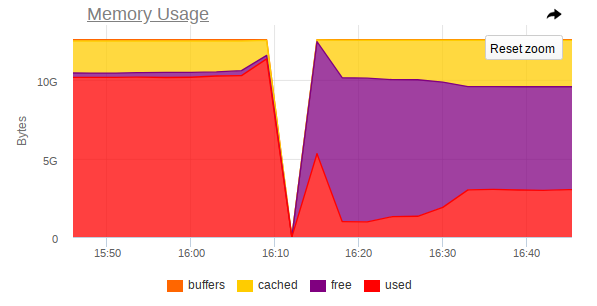
Assim, as capturas de tela mostram que:
- RAM na máquina está perto do fim;
- É observado um salto acentuado no consumo de RAM, após o qual o acesso a toda a máquina é fortemente desativado;
- Uma grande tarefa chega ao Mongo, o que força o processo DBMS a usar mais memória e ler ativamente do disco.
Acontece que, se o Linux ficar sem memória livre (ocorre pressão de memória) e não houver troca,
antes que o killer do OOM chegue, um equilíbrio poderá ocorrer entre jogar páginas no cache da página e gravá-las no disco. Isso é feito pelo kswapd, que corajosamente libera o máximo de páginas de memória possível para distribuição posterior.
Infelizmente, com uma grande carga de E / S, juntamente com uma pequena quantidade de memória livre, o
kswapd se torna o gargalo de todo o sistema , porque
todas as falhas de página das páginas de memória do sistema estão ligadas a ele. Isso pode durar muito tempo se os processos não quiserem mais usar memória, mas estiverem fixos no limite do abismo do OOM.
A questão lógica é: por que o assassino da OOM chega tão tarde? Na iteração atual do OOM, o killer é extremamente estúpido: ele mata o processo apenas quando a tentativa de alocar uma página de memória falha, ou seja, se a falha da página falhar. Isso não acontece por um longo tempo, porque o kswapd libera corajosamente as páginas de memória liberando o cache da página (de fato, todas as E / S de disco do sistema) de volta ao disco. Mais detalhadamente, com uma descrição das etapas necessárias para eliminar esses problemas no kernel, você pode ler
aqui .
Esse comportamento
deve melhorar com o kernel Linux 4.6+.
História 6. Pods estão pendentes
Em alguns clusters, nos quais existem realmente muitos pods, começamos a perceber que a maioria deles fica suspensa por um período muito longo no estado
Pending , embora, ao mesmo tempo, os contêineres do Docker já estejam em execução nos nós e você possa trabalhar manualmente com eles.
Não há nada de errado em
describe :
Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 1m default-scheduler Successfully assigned sphinx-0 to ss-dev-kub07 Normal SuccessfulAttachVolume 1m attachdetach-controller AttachVolume.Attach succeeded for volume "pvc-6aaad34f-ad10-11e8-a44c-52540035a73b" Normal SuccessfulMountVolume 1m kubelet, ss-dev-kub07 MountVolume.SetUp succeeded for volume "sphinx-config" Normal SuccessfulMountVolume 1m kubelet, ss-dev-kub07 MountVolume.SetUp succeeded for volume "default-token-fzcsf" Normal SuccessfulMountVolume 49s (x2 over 51s) kubelet, ss-dev-kub07 MountVolume.SetUp succeeded for volume "pvc-6aaad34f-ad10-11e8-a44c-52540035a73b" Normal Pulled 43s kubelet, ss-dev-kub07 Container image "registry.example.com/infra/sphinx-exporter/sphinx-indexer:v1" already present on machine Normal Created 43s kubelet, ss-dev-kub07 Created container Normal Started 43s kubelet, ss-dev-kub07 Started container Normal Pulled 43s kubelet, ss-dev-kub07 Container image "registry.example.com/infra/sphinx/sphinx:v1" already present on machine Normal Created 42s kubelet, ss-dev-kub07 Created container Normal Started 42s kubelet, ss-dev-kub07 Started container
Depois de pesquisar, assumimos que o kubelet simplesmente não tem tempo para enviar ao servidor da API todas as informações sobre o estado dos pods, amostras de vitalidade / prontidão.
E, tendo estudado a ajuda, encontramos os seguintes parâmetros:
--kube-api-qps - QPS to use while talking with kubernetes apiserver (default 5) --kube-api-burst - Burst to use while talking with kubernetes apiserver (default 10) --event-qps - If > 0, limit event creations per second to this value. If 0, unlimited. (default 5) --event-burst - Maximum size of a bursty event records, temporarily allows event records to burst to this number, while still not exceeding event-qps. Only used if --event-qps > 0 (default 10) --registry-qps - If > 0, limit registry pull QPS to this value. --registry-burst - Maximum size of bursty pulls, temporarily allows pulls to burst to this number, while still not exceeding registry-qps. Only used if --registry-qps > 0 (default 10)
Como você pode ver, os
valores padrão são muito pequenos e, em 90%, cobrem todas as necessidades ... No entanto, no nosso caso, isso não foi suficiente. Portanto, definimos estes valores:
--event-qps=30 --event-burst=40 --kube-api-burst=40 --kube-api-qps=30 --registry-qps=30 --registry-burst=40
... e reiniciou os kubelets, após o que viram a seguinte imagem nos gráficos de acesso ao servidor da API:

... e sim, tudo começou a voar!
PS
Para obter ajuda na coleta de bugs e na preparação do artigo, expresso minha profunda gratidão aos inúmeros engenheiros de nossa empresa e, em particular, a Andrei Klimentyev (colega de nossa equipe de P&D) (
zuzzas ).
PPS
Leia também em nosso blog: