Em resposta a um aumento no número de aplicativos em execução e no número de dispositivos de rede, a largura de banda da rede aumenta e os requisitos de entrega de pacotes são reforçados. Em uma escala de datacenters críticos para a nuvem, essenciais para os negócios, a abordagem tradicional para manutenção da infraestrutura não permite mais resolver tarefas típicas. Portanto, nasceu o conceito de AIOps (Algorithmic IT Operations).
Segundo o Gartner, cerca de 50% das empresas usarão AIOps até o próximo ano. Podemos falar sobre o que ferramentas semelhantes podem fazer hoje, usando o exemplo do Huawei FabricInsight, um analisador de rede que faz parte de uma solução abrangente para os data centers da Huawei CloudFabric.
A transformação digital das empresas oferece novas oportunidades - a introdução da análise de Big Data, o desenvolvimento de algoritmos de aprendizado de máquina - não é mais apenas uma moda passageira, mas uma necessidade consciente, cujo fechamento traz lucro real. No entanto, novas implementações acarretam um aumento múltiplo na complexidade da infraestrutura, o que ao mesmo tempo coloca novos desafios em termos de manutenção.
O principal problema de manter uma grande infraestrutura hoje é a quantidade de dados que devem ser coletados e processados para obter informações sobre o status do datacenter, bem como a velocidade com a qual é necessário dar uma resposta relevante às causas das falhas. Por um lado, o número de parâmetros monitorados está em constante crescimento; por outro, o tempo está jogando contra as organizações, porque o objetivo de qualquer empresa é restaurar a disponibilidade de seus serviços o mais rápido possível, se algo der errado (especialmente considerando os rigorosos requisitos de SLA). A velocidade da "ascensão" do serviço após o colapso é amplamente determinada pela velocidade da investigação do incidente. E, por sua vez, depende da integridade das informações sobre o que está acontecendo. Porém, se pelo menos 50 a 100 racks de servidor estiverem instalados no datacenter, os mecanismos de monitoramento padrão não poderão lidar com os altos requisitos de largura de banda e entrega oportuna de pacotes.
Por que o SNMP falha?
Mecanismos padrão - SNMP e xFlow - coletam dados apenas a cada 5-15 minutos, amostrando informações. Eles foram inicialmente desenvolvidos tendo em vista as limitações do pós-processamento de dados acumulados sem a tarefa de identificar problemas em tempo real. E mesmo essa coleta limitada de dados afeta a operação dos dispositivos de rede.
Considerando que o tráfego problemático é de apenas 3,65%, a abordagem tradicional, baseada nos resultados da análise, revela apenas 30% dos problemas de rede, 70% não são visíveis para os sistemas de monitoramento.
Administradores experientes que sabem o que e onde procurar são necessários para identificar a raiz do problema a partir dos dados coletados pelo SNMP e xFlow. Os problemas precisam ser identificados analisando enormes logs e várias mensagens de erro e, em seguida, manualmente, alterando a configuração. Mas com o desenvolvimento do SDN, com a virtualização de recursos físicos, a configuração manual é coisa do passado. Hoje, mesmo toda uma equipe de administradores de sistemas não pode mais garantir a conformidade contínua dos parâmetros de infraestrutura com os requisitos de negócios.
O FabricInsight funciona de maneira diferente
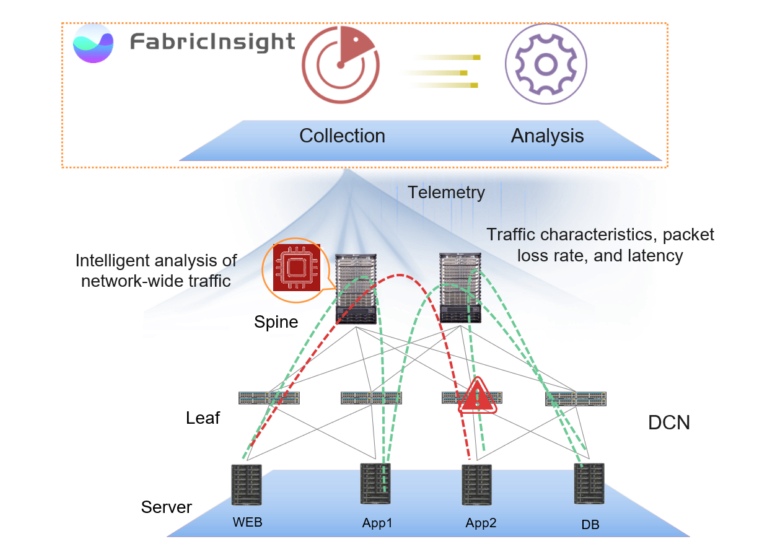
A FabricInsight Network Analysis Platform oferece uma abordagem diferente, automatizando a manutenção da rede e a detecção de pontos de falha. O FabricInsight analisa o comportamento dos aplicativos, identifica os caminhos de rede que eles usam e rastreia o status dos dispositivos neles.

Essa abordagem é baseada em dois componentes principais - a coleta de todos os dados disponíveis e sua análise automática. Complementada com visualização funcional e uma política de abertura de dados, essa abordagem nos permite resolver muitos dos problemas que antes eram becos sem saída.
Colete todos os dados disponíveis.
A chave para uma resposta rápida à situação é a imagem completa do que está acontecendo dentro do data center no nível da rede. O FabricInsight usa um mecanismo de assinatura de telemetria push para coletar todos os dados de serviço de segundo nível em tempo hábil, sem amostragem. Para obter uma imagem completa da rede, são coletados dados sobre a operação de dispositivos, aplicativos e a passagem do tráfego de rede (pacotes TCP SYN, FIN e RST) - o ERSPAN é suportado para espelhar pacotes sem usar a CPU do dispositivo e o GRPC do Google para relatar o desempenho dos próprios dispositivos.
Os dados coletados através do FabricInsight LEAF são transmitidos ao FabricInsight Collector, que monitora os parâmetros temporais do pacote que passa pela rede. O Collector fornece dados de tráfego de rede com registros de data e hora, codifica e envia por HTTP ao FabricInsight Analyzer. Essa abordagem permite coletar o máximo de informações sobre a rede, capturando até mesmo rajadas de tráfego de curto prazo que não podem ser detectadas por soluções "clássicas".
Ao mesmo tempo, o FabricInsight não procura pacotes IP (não captura seu conteúdo), usando apenas cabeçalhos em seu trabalho. Assim, ele pode ser usado em áreas críticas para os negócios, por exemplo, onde há trabalho com dados pessoais.
Análise em tempo real
O segundo elemento integrante do sistema é o FabricInsight Analyzer. Recebendo os dados coletados, ele identifica caminhos de tráfego e executa algoritmos que analisam a situação quase em tempo real. Em geral, o FabricInsight Analyzer correlaciona o tráfego de rede com aplicativos, permitindo identificar e corrigir problemas rapidamente. Devido ao aprendizado de máquina, os algoritmos são "treinados" para identificar o comportamento normal e anormal da infraestrutura.
O NetworkInsight reflete os resultados da análise de rede em sua interface na forma de mapas do status da rede, interações de aplicativos, análises de aplicativos individuais, etc., atualizados em tempo real. A interface é implementada de forma a relacionar visualmente o nível de aplicativos e dispositivos físicos específicos responsáveis pela operacionalidade da rede, o que acelera a solução de problemas e os métodos para resolvê-los.
Se alguma anomalia for detectada, as informações iniciais serão salvas automaticamente, de acordo com os quais os problemas foram identificados (a duração do armazenamento é ajustável); se necessário, o FabricInsight avisa o usuário. Além disso, os procedimentos para corrigir a situação “com um clique com o mouse” através da interface gráfica são inicializados. Ao mesmo tempo, vários padrões de correção de erros são analisados para encontrar a abordagem mais relevante.
Estojos
Para identificar anomalias do datacenter, é usada uma análise de correlação da operação de aplicativos, dispositivos e caminhos de tráfego, assim, vários tipos de anomalias são registrados - tanto temporários quanto a longo prazo.

A propósito, a maioria das anomalias temporárias mencionadas acima não pode ser corrigida usando a abordagem clássica. Isso também se aplica a algumas anomalias de longo prazo. Um exemplo bastante comum é uma atualização de software "torta". Suponha que um determinado aplicativo estivesse operando no datacenter que gerava certo tráfego. Depois de atualizá-lo, o volume desse tráfego mudou drasticamente, por exemplo, a taxa de transferência do aplicativo diminuiu, os atrasos aumentaram. Essa anomalia será corrigida pelo FabricInsight.
Outro exemplo é a degradação gradual do módulo de comunicação óptica (perda de desempenho), precedendo a falha. A degradação determina a instabilidade da transmissão, que por longos períodos de tempo pode indicar a necessidade de uma substituição antecipada do equipamento. Mas identificar isso com uma abordagem padrão é extremamente difícil.

Como resposta a esse problema, a interface do FabricInsight exibe os status de todos os módulos ópticos no sistema, além de uma estimativa da probabilidade de falha.

Integração
Embora o FabricInsight tenha aparecido no mercado russo em janeiro deste ano, ele já foi implantado no ICBC, na China UnionPay, no China Merchants Bank, no PICC e em outros grandes data centers baseados na infraestrutura da Huawei.
Até o momento, a solução suporta apenas nossos switches (nos chipsets Broadcom), mas no futuro está planejado ir além do ecossistema de um fabricante. Além disso, ao trabalhar no FabricInsight, inicialmente nos concentramos em padrões abertos, para que pudéssemos fazer amizade com ferramentas de terceiros normalmente. Por exemplo, o Druid pode ser usado para exportar dados do FabricInsight, através dos quais você pode enviar informações para visualizadores de terceiros. O FabricInsight também já está integrado à ferramenta de renderização aberta da Grafana.
Em geral, ferramentas AIOps como o FabricInsight são uma maneira lógica de desenvolver ferramentas de monitoramento e manutenção de infraestrutura. Parece-nos que esta é a única maneira de continuar em conformidade com o SLA para serviços.