Oi Habr! O RBKmoney entra em contato novamente e continua uma série de artigos sobre como escrever o processamento de pagamento faça você mesmo.

Eu queria mergulhar imediatamente nos detalhes da descrição da implementação de um processo de negócios de pagamento como uma máquina de estado, mostrar exemplos dessa máquina com um conjunto de eventos, recursos de implementação ... Mas parece que você não pode prescindir de mais alguns artigos de revisão. A área de assunto acabou sendo muito grande. Este post irá revelar as nuances do trabalho e a interação entre os microsserviços de nossa plataforma, a interação com sistemas externos e como gerenciamos a configuração de negócios.
Serviço de macro
Nosso sistema consiste em muitos microsserviços, que, implementando cada parte final da lógica de negócios, interagem entre si e juntos formam um serviço de macro. Na verdade, o serviço de macro implantado no data center, conectado a bancos e outros sistemas de pagamento, é o nosso processamento de pagamentos.
Modelo de microsserviço
Utilizamos uma abordagem unificada para o desenvolvimento de qualquer microsserviço, em qualquer idioma que ele seja escrito. Cada microsserviço é um contêiner do Docker que contém:
- o próprio aplicativo que implementa a lógica de negócios escrita em Erlang ou Java;
- RPClib - uma biblioteca que implementa a comunicação entre microsserviços;
- usamos o Apache Thrift, suas principais vantagens são bibliotecas cliente-servidor prontas e a capacidade de tipificar estritamente a descrição de todos os métodos públicos que cada microsserviço fornece;
- o segundo recurso da biblioteca é a implementação do Google Dapper , que permite rastrear solicitações rapidamente com uma simples pesquisa no Elasticsearch. O primeiro microsserviço que recebeu uma solicitação de um sistema externo gera um
trace_id exclusivo, que é salvo por cada cadeia de solicitações subsequente. Além disso, geramos e salvamos parent_id e span_id , o que permite criar uma árvore de consultas, monitorando visualmente toda a cadeia de microsserviços envolvidos no processamento da solicitação; - o terceiro recurso - usamos ativamente a transferência no nível de transporte de informações diferentes sobre o contexto da solicitação. Por exemplo, prazos (a vida útil esperada da solicitação definida no cliente) ou em nome de quem fazemos uma chamada para um método;
- O modelo Consul é um agente de descoberta de serviço que mantém informações sobre a localização, disponibilidade e status de um microsserviço. Os microsserviços se encontram pelos nomes DNS, a zona TTL é zero, o serviço que morreu ou não passou na verificação de integridade pára de resolver e, portanto, recebe tráfego;
- os logs que o aplicativo grava em um formato compreensível para o Elasticsearch no arquivo e na
filebeat arquivos do contêiner local, que está sendo executado na máquina host em relação ao contêiner, coleta esses logs e os envia ao cluster Elasticsearch;
- como implementamos a plataforma de acordo com o modelo de Event Sourcing, as cadeias de logs resultantes também são usadas para visualização na forma de diferentes painéis Grafana, o que nos permite reduzir o tempo para implementar métricas diferentes (também usamos métricas separadas).

Ao desenvolver microsserviços, usamos as limitações que inventamos especialmente, projetadas para resolver o problema de alta disponibilidade da plataforma e sua tolerância a falhas:
- limites estritos de memória para cada contêiner, quando você ultrapassa os limites - OOM, a maioria dos microsserviços vive dentro de 256-512M. Isso torna a implementação da lógica de negócios mais fragmentada, protege contra desvios para o monólito, reduz o custo do ponto de falha, oferece uma vantagem adicional ao trabalhar com hardware barato (a plataforma é implantada e é executada em servidores de processador único baratos);
- o menor número possível de microsserviços com estado e o maior número possível de implementações sem estado. Isso nos permite resolver os problemas de tolerância a falhas, velocidade de recuperação e, em geral, minimizar locais com comportamento potencialmente incompreensível. Isso se torna especialmente importante com o aumento da vida útil do sistema quando um grande legado é acumulado;
- deixe travar e "definitivamente quebrará" abordagens. Sabemos que qualquer parte do nosso sistema falhará necessariamente; portanto, o projetamos para que isso não afete a correção geral das informações acumuladas na plataforma. Ajuda a minimizar o número de estados indefinidos no sistema.
Certamente familiar para muitos que se integram com terceiros, a situação. Esperávamos uma resposta de terceiros à solicitação para amortizar o dinheiro de acordo com o protocolo, e uma resposta completamente diferente veio, não descrita em nenhuma especificação, que não se sabe como interpretá-lo.
Nessa situação, matamos a máquina de estado que atende a esse pagamento, qualquer ação externa recebe um erro de 500. E por dentro descobrimos o estado atual do pagamento, alinhamos o estado da máquina com a realidade e revivemos a máquina de estado.
Desenvolvimento Orientado a Protocolo

No momento da redação deste artigo, 636 verificações diferentes foram registradas em nosso Service Discovery para serviços que garantem o funcionamento da plataforma. Mesmo considerando que várias verificações estão sendo executadas em um serviço e também que a maioria dos serviços sem estado funciona em pelo menos uma instância tripla, ainda é possível obter cinquenta aplicativos que precisam ser capazes de se conectar de alguma forma e não falhar no inferno da RPC.
A situação é complicada pelo fato de termos três linguagens de desenvolvimento na pilha - Erlang, Java, JS e todas elas precisam ser capazes de se comunicar de forma transparente.
A primeira tarefa que precisou ser resolvida foi projetar a arquitetura correta para a troca de dados entre microsserviços. Como base, adotamos o Apache Thrift. Todos os microsserviços trocam binários de trift; usamos o HTTP como transporte.
Colocamos as especificações de fonte na forma de repositórios separados no nosso github, para que estejam disponíveis para qualquer desenvolvedor que tenha acesso a elas. Inicialmente, eles usaram um repositório comum para todos os protocolos, mas com o tempo chegaram à conclusão de que isso é inconveniente - o trabalho paralelo conjunto de protocolos se transformou em uma dor de cabeça constante. Equipes diferentes e até desenvolvedores diferentes foram forçados a concordar com o nome das variáveis, uma tentativa de dividir em espaço para nome também não ajudou.
Em geral, podemos dizer que temos um desenvolvimento orientado a protocolos. Antes de iniciar qualquer implementação, desenvolvemos o futuro protocolo de microsserviço na forma de uma especificação de elevação, passamos por 7 círculos de revisão, atraindo futuros clientes desse microsserviço e temos a oportunidade de começar a desenvolver simultaneamente vários microsserviços em paralelo, porque conhecemos todos os seus métodos futuros e já podemos escrever seus manipuladores, opcionalmente usando moki.
Uma etapa separada no processo de desenvolvimento de protocolo é uma revisão de segurança, na qual os caras examinam, do ponto de vista de seus detetives, as nuances da especificação que está sendo desenvolvida.
Também consideramos apropriado destacar uma função separada do proprietário do protocolo na equipe. A tarefa é difícil, uma pessoa precisa ter em mente as especificidades de todos os microsserviços, mas compensa em grande escala e a presença de um único ponto de escalação.
Sem a aprovação final da solicitação de recebimento por esses funcionários, o protocolo não pode ser mesclado em uma filial principal. Existe uma funcionalidade muito conveniente no github para isso - proprietários de código , nós a usamos com prazer.
Assim, resolvemos o problema de comunicação entre microsserviços, possíveis problemas de mal-entendido que tipo de microsserviço apareceu na plataforma e por que é necessário. Esse conjunto de protocolos é talvez a única parte da plataforma em que escolhemos incondicionalmente a qualidade em relação ao custo e à velocidade do desenvolvimento, porque a implementação de um microsserviço pode ser reescrita de maneira relativamente indolor e o protocolo no qual várias dezenas já são caras e dolorosas.
Ao longo do caminho, o registro preciso ajuda a resolver o problema da documentação. Nomes razoavelmente escolhidos de métodos e parâmetros, alguns comentários e uma especificação auto-documentada economizam muito tempo!
Por exemplo, é assim que a especificação do método de um de nossos microsserviços é exibida, permitindo que você obtenha uma lista de eventos que ocorreram na plataforma:
/** */ typedef i64 EventID /* Event sink service definitions */ service EventSink { /** * , * , , `range`. * `0` `range.limit` . * * `range.after` , * , , * `EventNotFound`. */ Events GetEvents (1: EventRange range) throws (1: EventNotFound ex1, 2: base.InvalidRequest ex2) /** * * . */ base.EventID GetLastEventID () throws (1: NoLastEvent ex1) } /* Events */ typedef list<Event> Events /** * , -, . */ struct Event { /** * . * , * (total order). */ 1: required base.EventID id /** * . */ 2: required base.Timestamp created_at /** * -, . */ 3: required EventSource source /** * , ( ) * -, . */ 4: required EventPayload payload /** * . * . */ 5: optional base.SequenceID sequence } // Exceptions exception EventNotFound {} exception NoLastEvent {} /** * , - */ exception InvalidRequest { /** */ 1: required list<string> errors }
Cliente do console Thrift
Às vezes, somos confrontados com a tarefa de chamar certos métodos do microsserviço necessário diretamente, por exemplo, com as mãos do terminal. Isso pode ser útil para depuração, obtenção de um conjunto de dados brutos ou quando a tarefa é tão rara que o desenvolvimento de uma interface de usuário separada é impraticável.
Portanto, desenvolvemos uma ferramenta para nós mesmos que combina as funções de curl , mas permite que você faça solicitações de trift na forma de estruturas JSON. Nós o chamamos de acordo - woorl . O utilitário é universal, basta transferir a localização de qualquer especificação de elevação para ele usando o parâmetro de linha de comando; ele fará o resto sozinho. Um utilitário muito conveniente, você pode iniciar um pagamento diretamente no terminal, por exemplo.
É assim que o apelo é direcionado diretamente ao microsserviço da plataforma, responsável pelo gerenciamento de aplicativos (por exemplo, para criar uma loja). Solicitei dados na minha conta de teste:

Os leitores observadores provavelmente notaram um recurso na captura de tela. Também não gostamos disso. É necessário fixar a autorização de trift calls entre microsserviços, é necessário colar o TLS de maneira adequada. Mas enquanto os recursos, como sempre, não são suficientes. Nós nos limitamos à cobertura total do perímetro em que vivem os microsserviços de processamento.
Protocolos para comunicação com sistemas externos
Para publicar especificações externas de elevação e forçar nossos comerciantes a se comunicar usando o protocolo binário, consideramos isso muito cruel para eles. Era necessário escolher um protocolo legível por humanos que nos permitisse integrar convenientemente conosco, depurar e poder documentar convenientemente. Escolhemos o padrão Open API, também conhecido como Swagger .
Voltando ao problema de documentar protocolos, o Swagger permite que você resolva esse problema de maneira rápida e barata. A rede possui muitas implementações do belo design da especificação Swagger na forma de documentação do desenvolvedor. Examinamos tudo o que pudemos encontrar e, finalmente, escolhemos o ReDoc , uma biblioteca JS que aceita o swagger.json como entrada e gera essa documentação de três colunas na saída: https://developer.rbk.money/api/ .
As abordagens para o desenvolvimento de ambos os protocolos, Thrift interno e Swagger externo, são absolutamente idênticas para nós. Isso adiciona tempo ao desenvolvimento, mas compensa a longo prazo.
Também precisávamos resolver outro problema importante - não apenas aceitamos solicitações de baixa de dinheiro, mas também as enviamos ainda mais - para bancos e sistemas de pagamento.
Forçá-los a implementar nosso elevador seria uma tarefa ainda mais impraticável do que enviá-lo para APIs públicas.
Portanto, criamos e implementamos o conceito de adaptadores de protocolo. Esse é apenas outro microsserviço que implementa nossa especificação de elevação interna de um lado, que é a mesma para toda a plataforma, e o segundo é um protocolo externo específico para um banco ou subestação específica.
Os problemas que surgem ao escrever esses adaptadores quando você precisa interagir com terceiros é um tópico rico em histórias diferentes. Em nossa prática, encontramos coisas diferentes, respostas do formulário: "é claro que você pode implementar essa função conforme descrito no protocolo que lhe fornecemos, mas não dou garantias. Aí vem nossa pessoa doente em duas semanas, que é para tudo isso responde, e você pede a ele confirmação ". Além disso, tais situações não são incomuns: "aqui está o nome de usuário e a senha do nosso servidor, vá lá e configure tudo sozinho".
Acho isso particularmente interessante quando nos integramos a um parceiro de pagamento, que, por sua vez, já havia se integrado à nossa plataforma e efetuado pagamentos com sucesso por meio de nós (isso geralmente acontece, as especificidades comerciais do setor de pagamentos). Em resposta à nossa solicitação de um ambiente de teste, o parceiro respondeu que não possuía um ambiente de teste como tal, mas poderia obter tráfego para integração com o RBC, ou seja, com nossa plataforma, onde poderíamos nos envolver. É assim que nós, por meio de um parceiro, nos integramos uma vez.
Assim, resolvemos simplesmente o problema de implementar a conexão paralela em massa de vários sistemas de pagamento e outros terceiros. Na grande maioria dos casos, você não precisa tocar no código da plataforma para isso, basta escrever os adaptadores e adicionar mais instrumentos de pagamento à enumeração.
Como resultado, conseguimos esse esquema de trabalho - procuramos fora dos microsserviços da API do RBKmoney (os chamamos de API comum ou capi *, você os viu no cônsul acima), que validam os dados de entrada de acordo com a especificação pública do Swagger, autorizam clientes, transmitem esses métodos para nossas chamadas internas de elevação e envia solicitações da cadeia para o próximo microsserviço. Além disso, esses serviços implementam outro requisito de plataforma, cuja especificação técnica foi formulada como: "o sistema sempre deve ter a oportunidade de adquirir um gato".
Quando precisamos fazer uma chamada para algum sistema externo, os microsserviços internos extraem os métodos de elevação do adaptador de protocolo correspondente, eles os traduzem para o idioma de um banco ou sistema de pagamento específico e os enviam.
Dificuldades de compatibilidade com versões anteriores do protocolo
A plataforma está em constante evolução, novas funções são adicionadas, antigas são alteradas. Em tais circunstâncias, você deve investir no suporte à compatibilidade com versões anteriores ou atualizar constantemente os microsserviços dependentes. E se a situação em que o campo obrigatório se tornar opcional for simples, você não poderá fazer nada; no caso contrário, precisará gastar recursos adicionais.
Com um conjunto de protocolos internos, as coisas ficam mais fáceis. O setor de pagamentos raramente muda para que apareçam alguns métodos de interação fundamentalmente novos. Tomemos, por exemplo, uma tarefa comum para nós - conectar um novo provedor a um novo instrumento de pagamento. Por exemplo, processamento de carteira local, que permite processar pagamentos no Cazaquistão em tenge. Essa é uma nova carteira para nossa plataforma, mas, em princípio, não difere da mesma carteira Qiwi - ela sempre possui alguns identificadores e métodos exclusivos que permitem debitar / cancelar o débito nela.
Assim, nossa especificação de elevador para todos os fornecedores de carteiras é assim:
typedef string DigitalWalletID struct DigitalWallet { 1: required DigitalWalletProvider provider 2: required DigitalWalletID id } enum DigitalWalletProvider { qiwi rbkmoney }
e adicionar um novo meio de pagamento na forma de uma nova carteira simplesmente complementa a enumeração:
enum DigitalWalletProvider { qiwi rbkmoney newwallet }
Agora, resta aumentar todos os microsserviços usando essa especificação, sincronizando com o assistente de repositório com a especificação e implementando-os via CI / CD.
Protocolos externos são mais complicados. Cada atualização da especificação Swagger, especialmente sem compatibilidade com versões anteriores, é quase impossível de aplicar dentro de um período de tempo razoável - é improvável que nossos parceiros mantenham recursos gratuitos para desenvolvedores especificamente para atualizar nossa plataforma.
E às vezes isso é simplesmente impossível, ocasionalmente encontramos situações como: "o programador nos escreveu e foi embora, levou as fontes conosco, como trabalhamos, não sabemos, funciona e não tocamos".
Portanto, investimos no suporte à compatibilidade com versões anteriores em protocolos externos. Em nossa arquitetura, isso é um pouco mais fácil - já que usamos adaptadores de protocolo separados para cada versão específica da API comum, deixamos os microsserviços capi antigos para trabalhar, alterando apenas a parte que parece uma triagem dentro da plataforma, se necessário. Assim, os microsserviços capi-v1 , capi-v2 , capi-v3 e assim por diante aparecem e permanecem conosco para sempre.
O que acontecerá quando o capi-v33 , provavelmente teremos que descontinuar algumas versões antigas.
Nesse ponto, geralmente começo a entender muito bem empresas como a Microsoft e toda a sua dor no suporte à compatibilidade com versões anteriores de soluções que estão funcionando há décadas.
Personalize o sistema
E, encerrando o tópico, mostraremos como gerenciamos as configurações de plataforma específicas da empresa.
Apenas efetuar um pagamento não é tão fácil quanto parece. Para cada pagamento, o cliente comercial deseja anexar um grande número de condições - desde a comissão até, em princípio, a possibilidade de uma implementação bem-sucedida, dependendo da hora do dia. Nós nos propusemos a tarefa de digitalizar todo o conjunto de condições que um cliente comercial pode apresentar agora e no futuro e aplicamos esse conjunto a cada pagamento recém-lançado.
Como resultado, decidimos desenvolver nosso próprio DSL, para o qual parafusamos ferramentas para um gerenciamento conveniente que nos permite descrever o modelo de negócios da maneira correta: a escolha dos adaptadores de protocolo, uma descrição do plano de postagem, segundo o qual o dinheiro será espalhado nas contas do sistema, estabelecendo limites, comissões, categorias e outras coisas específicas ao sistema de pagamento.
Por exemplo, quando queremos receber uma comissão de 1% pela aquisição de cartões do maestro e do MS e espalhá-la nas contas dentro do sistema, configuramos o domínio da seguinte maneira:
{ "cash_flow": { "decisions": [ { "if_": { "any_of": [ { "condition": { "payment_tool": { "bank_card": { "definition": { "payment_system_is": "maestro" } } } } }, { "condition": { "payment_tool": { "bank_card": { "definition": { "payment_system_is": "mastercard" } } } } } ] }, "then_": { "value": [ { "source": { "system": "settlement" }, "destination": { "provider": "settlement" }, "volume": { "share": { "parts": { "p": 1, "q": 100 }, "of": "operation_amount" } }, "details": "1% processing fee" } ] } } ] } }
, , . , JSON. , , , . , , . , CVS/SVN-.
" ". , , , 1%, , , . , , . , .
cvs-like , . , — stateless, , . . .
- . , , . , , .
. , 10 , , .
, , , -, woorl-. - JSON- . - JS, , UX:
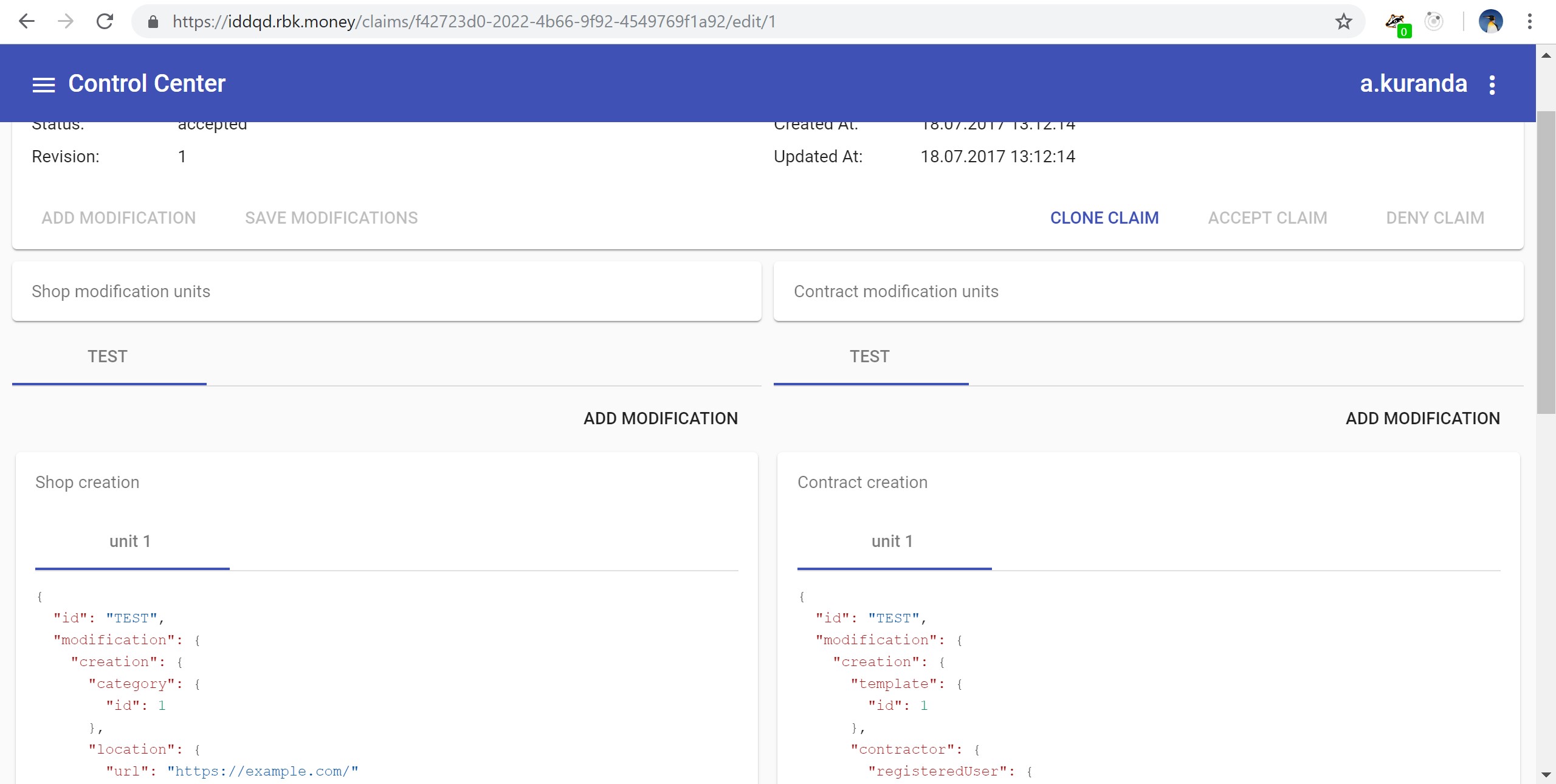
, , , .
, , .
, , SaltStack.
, !