Olá Habr!
Meu nome é Anton Markelov, sou engenheiro de operações da United Traders. Estamos envolvidos em projetos de uma maneira ou de outra, relacionados a investimentos, trocas e outros assuntos financeiros. Não somos uma empresa muito grande, cerca de 30 engenheiros de desenvolvimento, as escalas são adequadas - um pouco menos de uma centena de servidores. Durante o crescimento quantitativo e qualitativo de nossa infraestrutura, a solução clássica “mantemos o aplicativo e seu banco de dados no mesmo servidor” deixou de nos servir tanto em termos de confiabilidade quanto de velocidade. Por parte dos analistas, havia a necessidade de criar consultas entre bancos de dados, o departamento de operações estava cansado de mexer com backup e monitorar um grande número de servidores de banco de dados. Além disso, o armazenamento do estado na mesma máquina que o próprio aplicativo reduziu bastante a flexibilidade do planejamento de recursos e a resiliência da infraestrutura.
O processo de transição para a arquitetura atual foi evolutivo, várias soluções foram testadas para fornecer uma interface conveniente para desenvolvedores e analistas e aumentar a confiabilidade e a capacidade de gerenciamento de toda essa economia. Eu quero falar sobre os principais estágios da modernização de nossos DBMSs, a qual rake chegamos e quais decisões tomamos, como resultado de um ambiente independente tolerante a falhas que fornece meios convenientes de interação para engenheiros, desenvolvedores e analistas de operação. Espero que nossa experiência seja útil para engenheiros de empresas da nossa escala.
Este artigo é um resumo do meu
relatório na conferência UPTIMEDAY, talvez o formato de vídeo seja mais confortável para alguém, embora o escritor seja um pouco melhor com minhas mãos do que um orador.
O "Homem dos Flocos de Neve" com KDPV foi descaradamente
emprestado de Maxim Dorofeev.
Doenças do crescimento
Temos uma arquitetura de microsserviço, os serviços são escritos principalmente em Java ou Kotlin usando a estrutura Spring. Ao lado de cada microsserviço há uma base do PostgreSQL, tudo é coberto pelo nginx na parte superior para fornecer acesso. Um microsserviço típico é um aplicativo no Spring Boot que grava seus dados no PostgreSQL (parte dos aplicativos ao mesmo tempo e no ClickHouse), se comunica com os vizinhos pelo Kafka e possui alguns pontos de extremidade REST ou GraphQL para comunicação com o mundo externo.
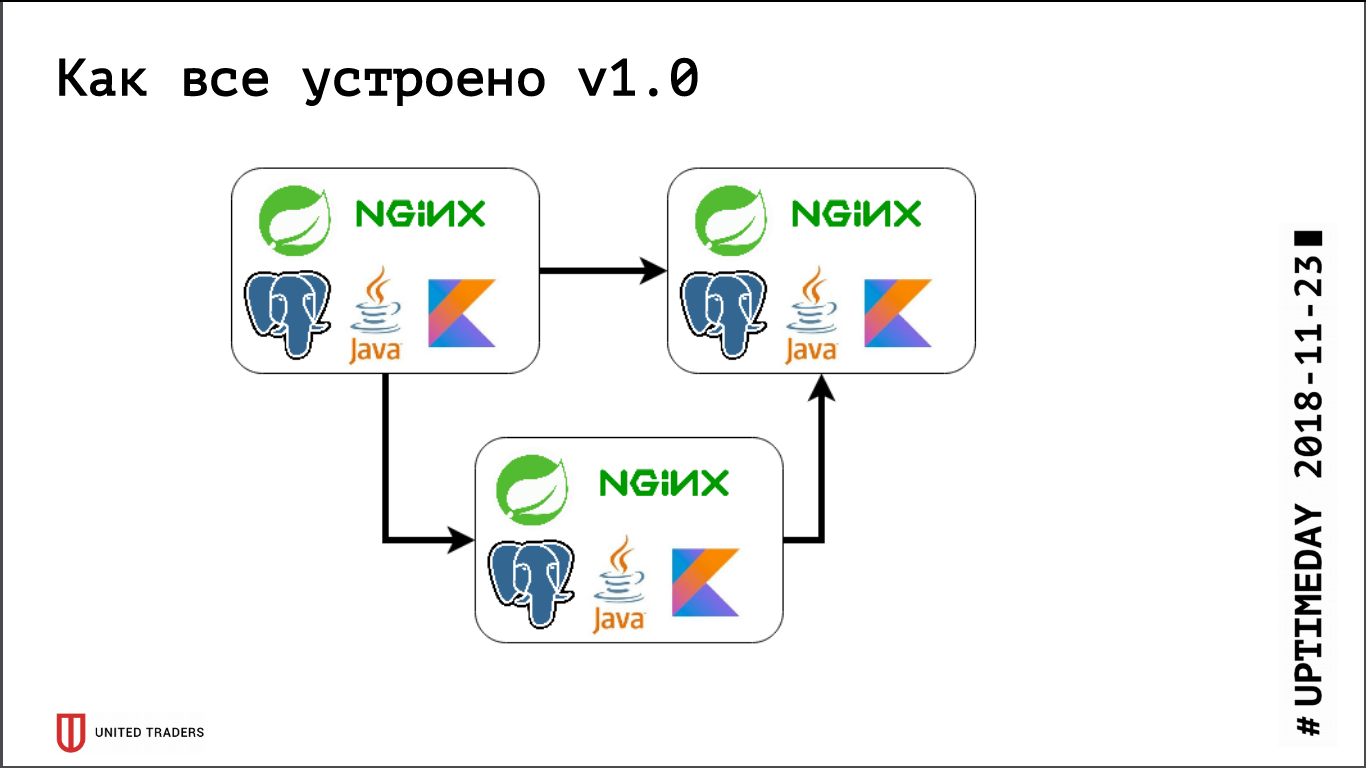
Anteriormente, quando éramos muito pequenos, mantivíamos vários servidores no DigitalOcean, Kafka ainda não estava lá, toda a comunicação era através do REST. Ou seja, pegamos uma gota, instalamos Java, PostgreSQL, nginx lá, lançamos o Zabbix lá para que ele monitore os recursos do servidor e a disponibilidade dos pontos de extremidade do serviço. Eles implantaram tudo com a ajuda da Ansible, tínhamos cartilhas padronizadas, quatro a cinco papéis implementados em todo o serviço. Contanto que tivéssemos, relativamente falando, 6 servidores em produção e 3 em teste - você poderia, de alguma forma, conviver com ele.
Então, a fase de desenvolvimento ativo começou, o número de aplicativos cresceu, dez microsserviços transformados em quarenta, suas funcionalidades começaram a mudar, além da integração com sistemas externos, como CRM, sites de clientes e similares. Temos a primeira dor. Alguns aplicativos começaram a consumir mais recursos, pararam de entrar nos servidores existentes, obtivemos gotículas, arrastamos os aplicativos para frente e para trás e pegamos muitas mãos. Doeu muito - ninguém gosta de estúpido trabalho mecânico -, eu queria decidir rapidamente. Por isso, fomos de frente - pegamos apenas 3 grandes servidores dedicados em vez de 10 gotículas na nuvem. Isso encerrou o problema por um tempo, mas ficou óbvio que era hora de definir opções para algum tipo de orquestração e reequilíbrio de servidores. Começamos a olhar atentamente para soluções como DC / OS e Kubernetes e aumentar gradualmente nossa experiência nessa área.
Na mesma época, tínhamos um departamento analítico, que precisava fazer solicitações difíceis regularmente, preparar relatórios, ter painéis bonitos e isso nos trouxe uma segunda dor. Em primeiro lugar, os analistas carregaram muito a base e, em segundo lugar, precisavam de consultas entre bancos de dados, porque cada microsserviço mantinha uma fatia de dados bastante estreita. Testamos vários sistemas; no início, tentamos resolver tudo isso através da replicação em nível de tabela (ela estava no nono PostgreSQL, não havia replicação lógica pronta para uso), mas os trabalhos resultantes baseados em pglogical, Presto, Slony-I e Bucardo não o fizeram completamente. arranjado. Por exemplo, o pglogical não suportava a migração - uma nova versão do microsserviço foi lançada, a estrutura do banco de dados mudou, o próprio Java mudou a estrutura usando o Flyway e, nas réplicas do pglogical, tudo precisa ser alterado manualmente. Caso contrário, algo estava faltando ou era muito difícil.
Super escravo
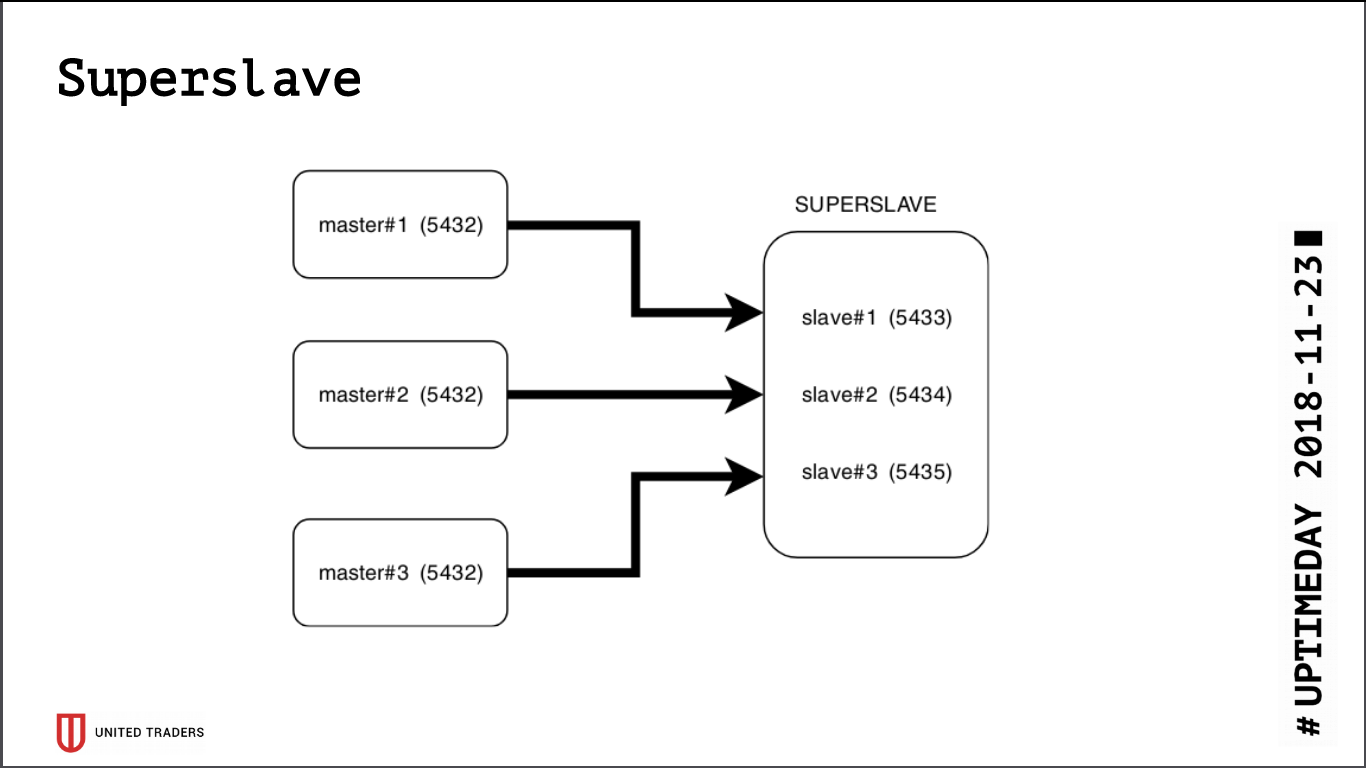
Como resultado da pesquisa, nasceu uma solução simples e brutal chamada Superslave: pegamos um servidor separado, configuramos um escravo para cada servidor de produção em portas diferentes e criamos um banco de dados virtual que combina os bancos de dados dos escravos via postgres_fdw (invólucro de dados externos). Ou seja, tudo isso foi implementado por meio do postgres padrão, sem a introdução de entidades adicionais, de maneira simples e confiável: com uma única solicitação, foi possível obter dados de vários bancos de dados. Demos essa base virtual aos analistas. Uma vantagem adicional é que a réplica somente leitura, mesmo com um erro nos direitos de acesso, não conseguiu gravar nada lá.
Pegamos o
Redash para visualização, ele sabe desenhar gráficos, executar solicitações de acordo com um cronograma, por exemplo, uma vez por dia, e possui um sistema de direitos pesado, então deixamos analistas e desenvolvedores irem até lá.

Paralelamente, o crescimento continuou, Kafka apareceu na infraestrutura como um barramento e ClickHouse para armazenamento de análises. Eles são facilmente agrupados fora da caixa, nosso super escravo contra o fundo deles parecia um fóssil desajeitado. Além disso, o PostgreSQL, de fato, permaneceu o único estado que precisava ser arrastado após o aplicativo (se ainda tivesse que ser transferido para outro servidor), e realmente queríamos que um aplicativo sem estado se envolvesse em experimentos com Kubernetes e ele. plataformas semelhantes.
Começamos a procurar uma solução que atenda aos seguintes requisitos:
- tolerância a falhas: quando N servidores caem, o cluster continua funcionando;
- para aplicativos, tudo deve permanecer como antes, sem alterações no código;
- facilidade de implantação e gerenciamento;
- menos camadas de abstração sobre o PostgreSQL regular;
- idealmente, balanceamento de carga para que nem todas as solicitações sejam enviadas para um servidor;
- Idealmente, está escrito em uma linguagem familiar.
Não havia muitos candidatos:
- replicação de streaming padrão (repmgr, Patroni, Stolon);
- replicação baseada em gatilho (Londiste, Slony);
- replicação de consulta da camada intermediária (pgpool-II);
- replicação síncrona com vários servidores principais (Bucardo).
Em grande parte, já tivemos experiências ruins durante a construção da base, então Patroni e Stolon permaneceram. Patroni é escrito em Python, Stolon in Go, temos experiência suficiente em ambos os idiomas. Além disso, eles têm arquitetura e funcionalidade semelhantes; portanto, a escolha foi feita por razões subjetivas: o Patroni foi desenvolvido por Zalando e tentamos trabalhar com o projeto Nakadi (API REST para Kafka), onde encontramos uma grave falta de documentação.
Stolon
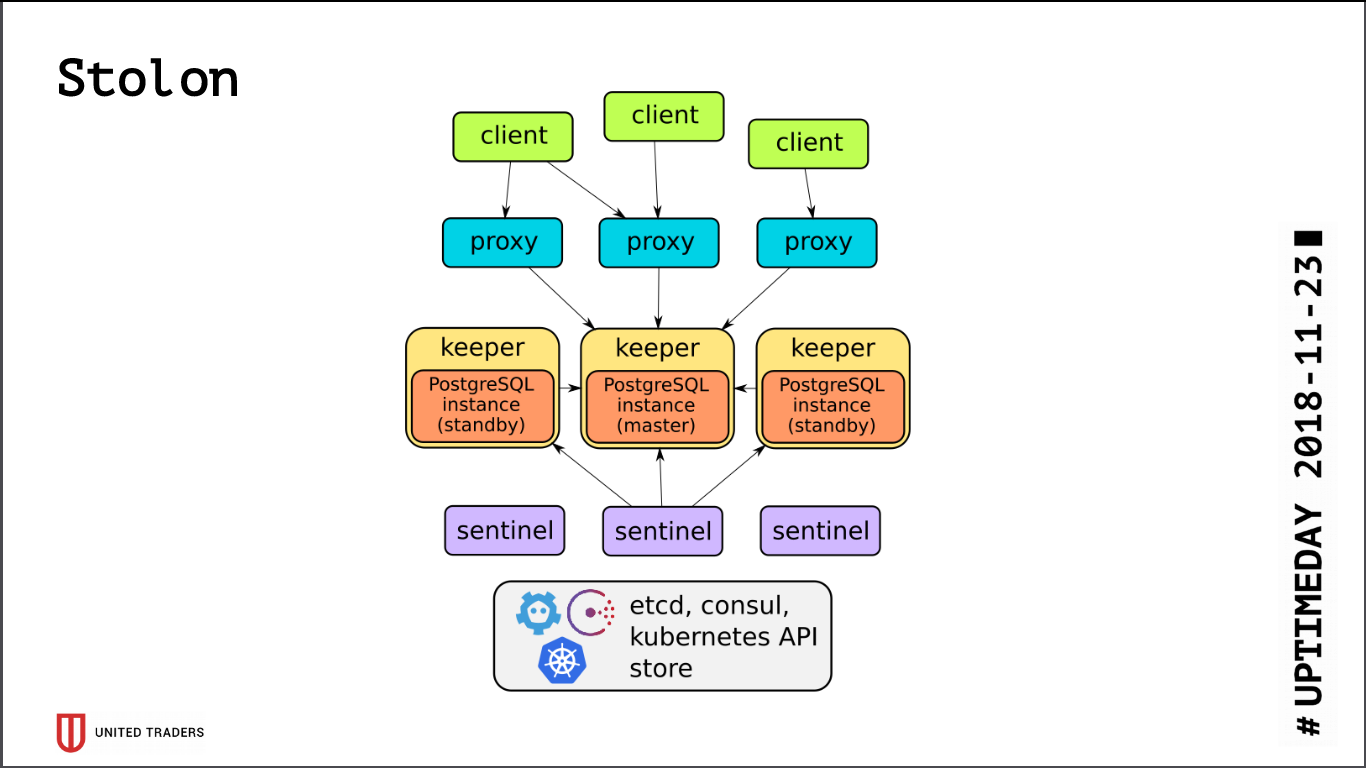
A arquitetura do
Stolon é bastante simples: existem N servidores, com a ajuda do etcd / consul, um líder é selecionado, o PostgreSQL é iniciado no modo assistente e é replicado para outros servidores. Em seguida, os proxies stolon acessam esse mestre do PostgreSQL, fingindo ser aplicativos com postgres comuns, e os clientes acessam esses proxies. No caso de desaparecimento de um mestre, ocorrem reeleições, alguém se torna mestre e o restante fica em espera. Existem poucas camadas de abstração, o PostgreSQL é instalado como de costume, a única ressalva é que a configuração do PostgreSQL é armazenada no etcd e é configurada de maneira um pouco diferente.
Ao testar o cluster, detectamos alguns problemas:
- Stolon não sabe trabalhar em cima do ZooKeeper, apenas cônsul ou etcd;
- O etcd é muito sensível ao IO. Se você mantém o PostgreSQL e o etcd no mesmo servidor, definitivamente precisa de SSDs rápidos;
- mesmo no SSD, é necessário configurar os tempos limites do etcd, caso contrário, tudo será interrompido sob carga - o cluster pensará que o mestre caiu e quebrará constantemente as conexões;
- Por padrão, max_connections no PostgreSQL é pequeno (200), você precisa aumentá-lo para suas necessidades;
- um cluster de três etcd sobreviverá à morte de apenas um servidor; idealmente, você precisa ter uma configuração, por exemplo, 5 etcd + 3 Stolon;
- fora da caixa, todas as conexões vão para o mestre, os escravos não são acessíveis para a conexão.
Como todas as conexões com o PostgreSQL vão para o assistente, novamente encontramos um problema com solicitações analíticas pesadas. O etcd às vezes reagiu dolorosamente à alta carga no mestre e o trocou. E alternar o assistente está sempre interrompendo as conexões. A solicitação foi reiniciada, tudo começou novamente. Para uma solução alternativa, foi escrito
um script Python que solicitou endereços stolonctl de escravos ativos e gerou uma configuração para o HAProxy, redirecionando solicitações para eles.
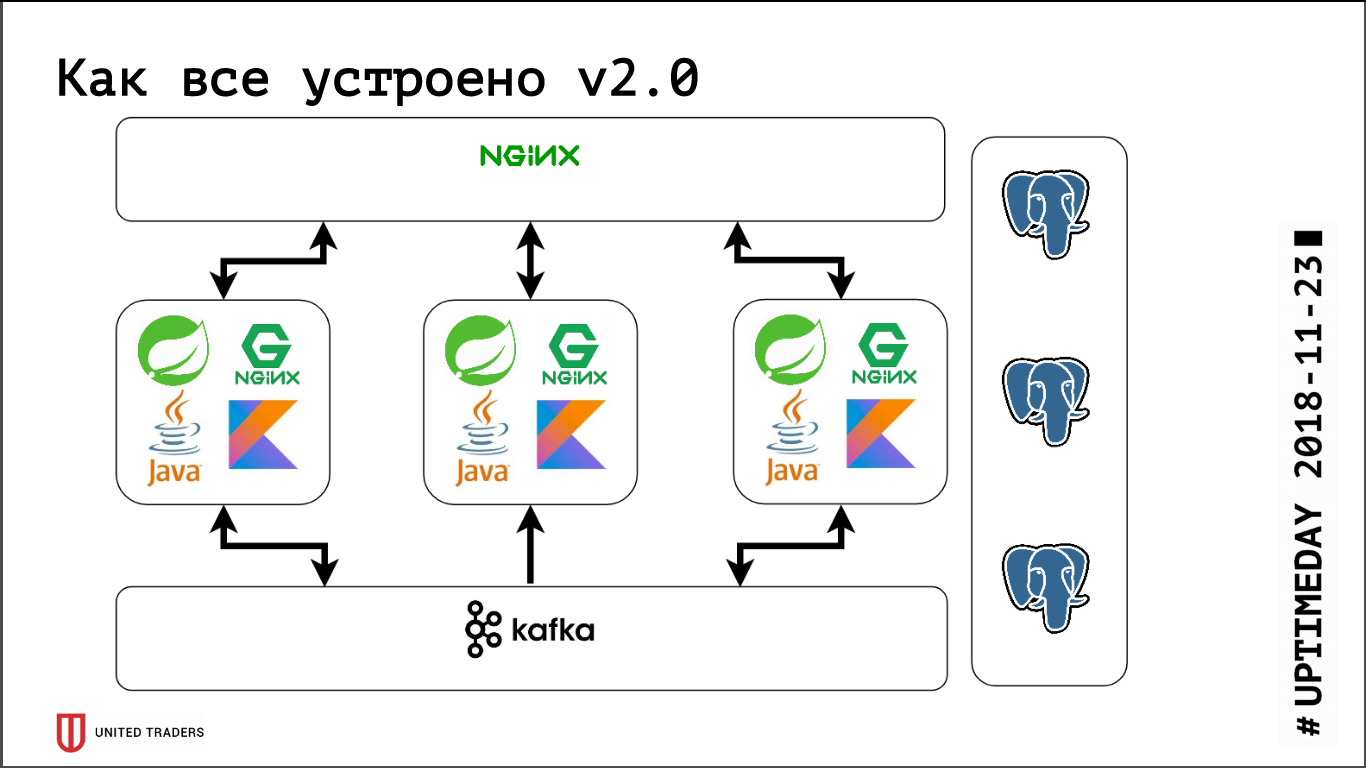
A imagem a seguir foi mostrada: solicitações de aplicativos vão para a porta stolon-proxy, que os redireciona para o mestre, e solicitações de analistas (sempre são somente leitura) vão para a porta HAProxy, que as lança para algum escravo.
Além disso, literalmente hoje, um PR foi adotado na Stolon, o que permitiu o envio de informações sobre instâncias do Stolon para uma descoberta de serviço de terceiros.
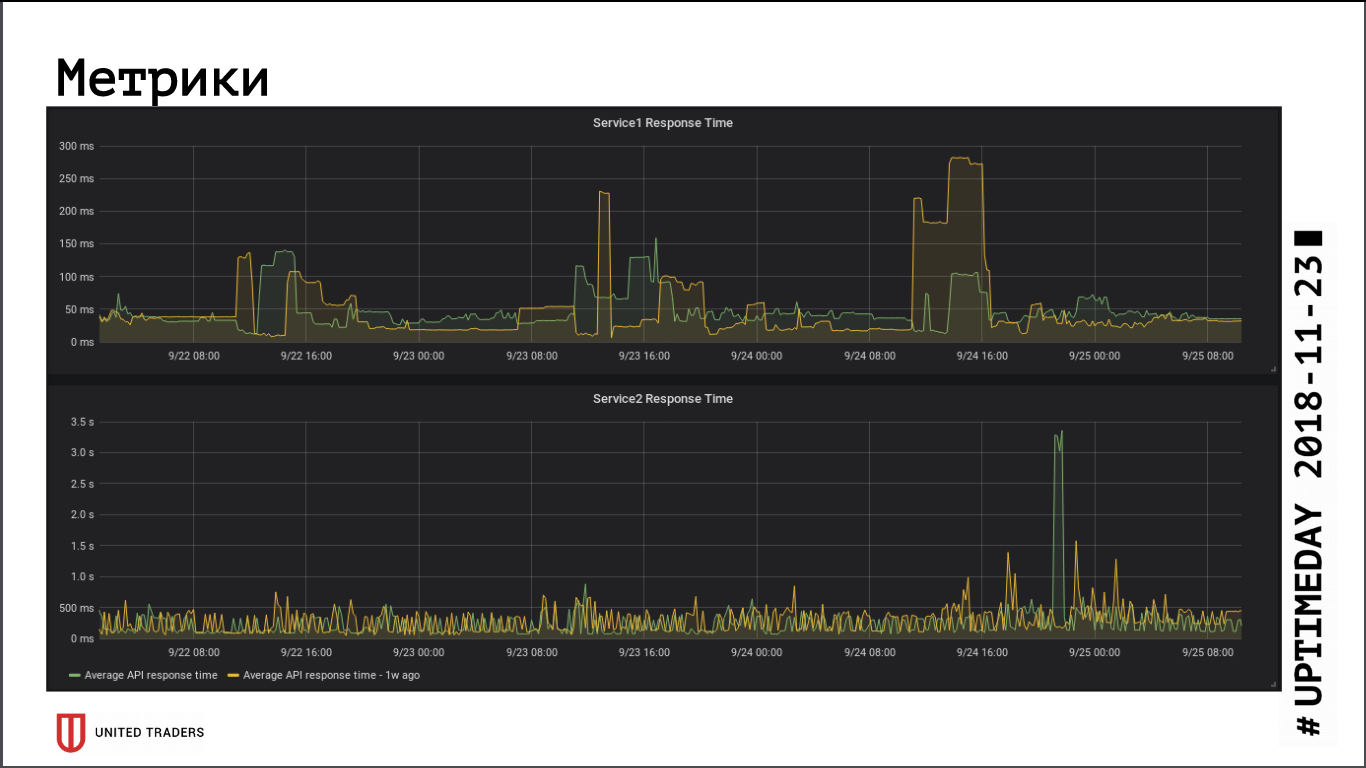
No que diz respeito às métricas de velocidade de resposta do aplicativo, a transição para um cluster remoto não teve um impacto significativo no desempenho, o tempo médio de resposta não mudou. A latência resultante da rede, aparentemente, foi compensada pelo fato de o banco de dados agora estar em um servidor dedicado.
O Stolon sem problemas sobrevive a uma falha do assistente (perda do servidor, perda de rede, perda de disco), quando o servidor ganha vida - ele redefine automaticamente a réplica. O ponto mais fraco do Stolon é o etcd, falhas nele colocam o cluster. Tivemos um acidente típico: um cluster de três nós etcd, dois foram cortados. Tudo, o quorum foi quebrado, etcd entrou em status não íntegro, o cluster Stolon não aceita nenhuma conexão, incluindo solicitações do stolonctl. Esquema de recuperação: transforme o etcd no servidor sobrevivente em um cluster de nó único e adicione os membros novamente. Conclusão: para sobreviver à morte de dois servidores, você deve ter pelo menos 5 instâncias etcd.
Monitorando e capturando erros
Com o crescimento da infraestrutura e a complexidade dos microsserviços, eu queria coletar mais informações sobre o que está acontecendo dentro do aplicativo e da máquina Java. Não conseguimos adaptar o Zabbix ao novo ambiente: é muito inconveniente nas condições de uma infraestrutura em mudança. Eu tive que moer muletas através da API ou subir com as mãos, o que é ainda pior. Seu banco de dados é pouco adaptado a cargas pesadas e, em geral, é muito inconveniente colocar tudo isso em um banco de dados relacional.
Como resultado, escolhemos o Prometheus para monitoramento. Ele tem um atuador pronto para aplicações Spring para fornecer métricas; para a Kafka, eles ferraram o JMX Exporter, que também fornece métricas de maneira confortável. Os exportadores que não foram encontrados “na caixa”, escrevemos em Python, existem cerca de dez deles. Nós visualizamos Grafana, coletamos os logs com Graylog (já que ele agora suporta Beats).
Usamos o
Sentry para coletar erros. Ele escreve tudo de forma estruturada, desenha gráficos, mostra o que aconteceu com mais frequência e com menos frequência. Geralmente, os desenvolvedores vão imediatamente para o Sentry imediatamente após a implantação, verificam se há algum pico ou precisam urgentemente ser revertidos. Acontece que ele rapidamente captura erros sem selecionar os logs.
Por enquanto, se o formato dos artigos se adequar aos leitores, continuaremos a falar sobre nossa infraestrutura, ainda há muita diversão: soluções Kafka e analíticas para eventos que passam por ela, canal CI / CD para aplicativos do Windows e aventuras com o Openshift.