
Parte 1/3 aqui .
Parte 2/3 aqui .
Olá pessoal! E aqui está a terceira parte dos Kubernetes no guia bare metal! Vou prestar atenção no monitoramento do cluster e na coleta de logs, também lançaremos um aplicativo de teste para usar os componentes de cluster pré-configurados. Em seguida, realizaremos vários testes de estresse e verificaremos a estabilidade desse esquema de cluster.
A ferramenta mais popular que a comunidade Kubernetes oferece para fornecer uma interface baseada na Web e obter estatísticas de cluster é o Painel Kubernetes . Na verdade, ele ainda está em desenvolvimento, mas mesmo agora pode fornecer alguns dados adicionais para solucionar problemas de aplicativos e gerenciar recursos de cluster.
O tópico é parcialmente controverso. É verdade que você precisa de algum tipo de interface da web para gerenciar o cluster ou é suficiente usar a ferramenta de console kubectl ? Bem, algumas vezes essas opções se complementam.
Vamos expandir nosso Painel Kubernetes e ver. Com uma implantação padrão, esse painel será iniciado apenas no endereço do host local. Portanto, você precisa usar o comando kubectl proxy para expansão , mas ele ainda está disponível apenas no seu dispositivo de controle local do kubectl. Nada mal do ponto de vista da segurança, mas eu quero ter acesso no navegador, fora do cluster, e estou pronto para correr alguns riscos (afinal, o SSL com um token efetivo é usado).
Para aplicar meu método, você precisa modificar levemente o arquivo de implantação padrão na seção de serviço. Para abrir esse painel em um endereço aberto, usamos nosso balanceador de carga.
Entramos no sistema da máquina com o utilitário kubectl configurado e criamos:
control# vi kube-dashboard.yaml # Copyright 2017 The Kubernetes Authors. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # ------------------- Dashboard Secret ------------------- # apiVersion: v1 kind: Secret metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard-certs namespace: kube-system type: Opaque --- # ------------------- Dashboard Service Account ------------------- # apiVersion: v1 kind: ServiceAccount metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system --- # ------------------- Dashboard Role & Role Binding ------------------- # kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: name: kubernetes-dashboard-minimal namespace: kube-system rules: # Allow Dashboard to create 'kubernetes-dashboard-key-holder' secret. - apiGroups: [""] resources: ["secrets"] verbs: ["create"] # Allow Dashboard to create 'kubernetes-dashboard-settings' config map. - apiGroups: [""] resources: ["configmaps"] verbs: ["create"] # Allow Dashboard to get, update and delete Dashboard exclusive secrets. - apiGroups: [""] resources: ["secrets"] resourceNames: ["kubernetes-dashboard-key-holder", "kubernetes-dashboard-certs"] verbs: ["get", "update", "delete"] # Allow Dashboard to get and update 'kubernetes-dashboard-settings' config map. - apiGroups: [""] resources: ["configmaps"] resourceNames: ["kubernetes-dashboard-settings"] verbs: ["get", "update"] # Allow Dashboard to get metrics from heapster. - apiGroups: [""] resources: ["services"] resourceNames: ["heapster"] verbs: ["proxy"] - apiGroups: [""] resources: ["services/proxy"] resourceNames: ["heapster", "http:heapster:", "https:heapster:"] verbs: ["get"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: kubernetes-dashboard-minimal namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: kubernetes-dashboard-minimal subjects: - kind: ServiceAccount name: kubernetes-dashboard namespace: kube-system --- # ------------------- Dashboard Deployment ------------------- # kind: Deployment apiVersion: apps/v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system spec: replicas: 1 revisionHistoryLimit: 10 selector: matchLabels: k8s-app: kubernetes-dashboard template: metadata: labels: k8s-app: kubernetes-dashboard spec: containers: - name: kubernetes-dashboard image: k8s.gcr.io/kubernetes-dashboard-amd64:v1.10.1 ports: - containerPort: 8443 protocol: TCP args: - --auto-generate-certificates # Uncomment the following line to manually specify Kubernetes API server Host # If not specified, Dashboard will attempt to auto discover the API server and connect # to it. Uncomment only if the default does not work. # - --apiserver-host=http://my-address:port volumeMounts: - name: kubernetes-dashboard-certs mountPath: /certs # Create on-disk volume to store exec logs - mountPath: /tmp name: tmp-volume livenessProbe: httpGet: scheme: HTTPS path: / port: 8443 initialDelaySeconds: 30 timeoutSeconds: 30 volumes: - name: kubernetes-dashboard-certs secret: secretName: kubernetes-dashboard-certs - name: tmp-volume emptyDir: {} serviceAccountName: kubernetes-dashboard # Comment the following tolerations if Dashboard must not be deployed on master tolerations: - key: node-role.kubernetes.io/master effect: NoSchedule --- # ------------------- Dashboard Service ------------------- # kind: Service apiVersion: v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kube-system spec: type: LoadBalancer ports: - port: 443 targetPort: 8443 selector: k8s-app: kubernetes-dashboard
Em seguida, execute:
control# kubectl create -f kube-dashboard.yaml control# kubectl get svc --namespace=kube-system kubernetes-dashboard LoadBalancer 10.96.164.141 192.168.0.240 443:31262/TCP 8h
Bem, como você pode ver, nosso BN adicionou IP 192.168.0.240 para este serviço. Agora tente abrir https://192.168.0.240 para visualizar o Kubernetes Dashboard.
Existem duas maneiras de obter acesso: use o arquivo admin.conf do nó principal, que usamos anteriormente ao configurar o kubectl, ou crie uma conta de serviço especial com um token de segurança.
Vamos criar um usuário administrador:
control# vi kube-dashboard-admin.yaml apiVersion: v1 kind: ServiceAccount metadata: name: admin-user namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: admin-user roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: admin-user namespace: kube-system control# kubectl create -f kube-dashboard-admin.yaml serviceaccount/admin-user created clusterrolebinding.rbac.authorization.k8s.io/admin-user created
Agora você precisa de um token para entrar no sistema:
control# kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}') Name: admin-user-token-vfh66 Namespace: kube-system Labels: <none> Annotations: kubernetes.io/service-account.name: admin-user kubernetes.io/service-account.uid: 3775471a-3620-11e9-9800-763fc8adcb06 Type: kubernetes.io/service-account-token Data ==== ca.crt: 1025 bytes namespace: 11 bytes token: erJhbGciOiJSUzI1NiIsImtpZCI6IiJ9.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwna3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJr dWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VmLXRva2VuLXZmaDY2Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZ XJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiIzNzc1NDcxYS0zNjIwLTExZTktOTgwMC03Nj NmYzhhZGNiMDYiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZS1zeXN0ZW06YWRtaW4tdXNlciJ9.JICASwxAJHFX8mLoSikJU1tbij4Kq2pneqAt6QCcGUizFLeSqr2R5x339ZR8W4 9cIsbZ7hbhFXCATQcVuWnWXe2dgXP5KE8ZdW9uvq96rm_JvsZz0RZO03UFRf8Exsss6GLeRJ5uNJNCAr8No5pmRMJo-_4BKW4OFDFxvSDSS_ZJaLMqJ0LNpwH1Z09SfD8TNW7VZqax4zuTSMX_yVS ts40nzh4-_IxDZ1i7imnNSYPQa_Oq9ieJ56Q-xuOiGu9C3Hs3NmhwV8MNAcniVEzoDyFmx4z9YYcFPCDIoerPfSJIMFIWXcNlUTPSMRA-KfjSb_KYAErVfNctwOVglgCISA
Copie o token e cole-o no campo token na tela de login.
Depois de entrar no sistema, você pode estudar o cluster um pouco mais fundo - eu gosto dessa ferramenta.
O próximo passo para aprofundar o sistema de monitoramento de nosso cluster é instalar o heapster .
O Heapster permite monitorar o cluster de contêineres e analisar o desempenho do Kubernetes (versão v1.0.6 e superior). Oferece plataformas apropriadas.
Essa ferramenta oferece estatísticas sobre o uso do cluster por meio do console e também adiciona mais informações sobre os recursos do nó e da lareira ao Painel Kubernetes.
Há pouca dificuldade em instalá-lo no bare metal, e eu precisava realizar algumas investigações: por que a ferramenta não funciona na versão original, mas eu encontrei uma solução.
Então, vamos continuar e endossar este complemento:
control# vi heapster.yaml apiVersion: v1 kind: ServiceAccount metadata: name: heapster namespace: kube-system --- apiVersion: extensions/v1beta1 kind: Deployment metadata: name: heapster namespace: kube-system spec: replicas: 1 template: metadata: labels: task: monitoring k8s-app: heapster spec: serviceAccountName: heapster containers: - name: heapster image: gcr.io/google_containers/heapster-amd64:v1.4.2 imagePullPolicy: IfNotPresent command: - /heapster - --source=kubernetes.summary_api:''?useServiceAccount=true&kubeletHttps=true&kubeletPort=10250&insecure=true --- apiVersion: v1 kind: Service metadata: labels: task: monitoring # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons) # If you are NOT using this as an addon, you should comment out this line. kubernetes.io/cluster-service: 'true' kubernetes.io/name: Heapster name: heapster namespace: kube-system spec: ports: - port: 80 targetPort: 8082 selector: k8s-app: heapster --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: heapster roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:heapster subjects: - kind: ServiceAccount name: heapster namespace: kube-system
Este é o arquivo de implantação padrão mais comum da comunidade Heapster, com apenas uma pequena diferença: para que funcione em nosso cluster, a linha " source = " na implantação do heapster é alterada da seguinte forma:
--source=kubernetes.summary_api:''?useServiceAccount=true&kubeletHttps=true&kubeletPort=10250&insecure=true
Nesta descrição, você encontrará todas essas opções. Alterei a porta do kubelet para 10250 e desliguei a verificação do certificado ssl (havia um pequeno problema).
Também precisamos adicionar permissões para obter estatísticas de nós na função Heapster RBAC; adicione estas poucas linhas no final da função:
control# kubectl edit clusterrole system:heapster ...... ... - apiGroups: - "" resources: - nodes/stats verbs: - get
Em resumo, sua função RBAC deve ficar assim:
# Please edit the object below. Lines beginning with a '#' will be ignored, # and an empty file will abort the edit. If an error occurs while saving this file will be # reopened with the relevant failures. # apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: annotations: rbac.authorization.kubernetes.io/autoupdate: "true" creationTimestamp: "2019-02-22T18:58:32Z" labels: kubernetes.io/bootstrapping: rbac-defaults name: system:heapster resourceVersion: "6799431" selfLink: /apis/rbac.authorization.k8s.io/v1/clusterroles/system%3Aheapster uid: d99065b5-36d3-11e9-a7e6-763fc8adcb06 rules: - apiGroups: - "" resources: - events - namespaces - nodes - pods verbs: - get - list - watch - apiGroups: - extensions resources: - deployments verbs: - get - list - watch - apiGroups: - "" resources: - nodes/stats verbs: - get
Ok, agora vamos executar o comando para garantir que a implantação do heapster seja iniciada com sucesso.
control# kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% kube-master1 183m 9% 1161Mi 60% kube-master2 235m 11% 1130Mi 59% kube-worker1 189m 4% 1216Mi 41% kube-worker2 218m 5% 1290Mi 44% kube-worker3 181m 4% 1305Mi 44%
Bem, se você recebeu alguns dados na saída, tudo é feito corretamente. Vamos voltar à nossa página do painel e verificar os novos gráficos que estão agora disponíveis.
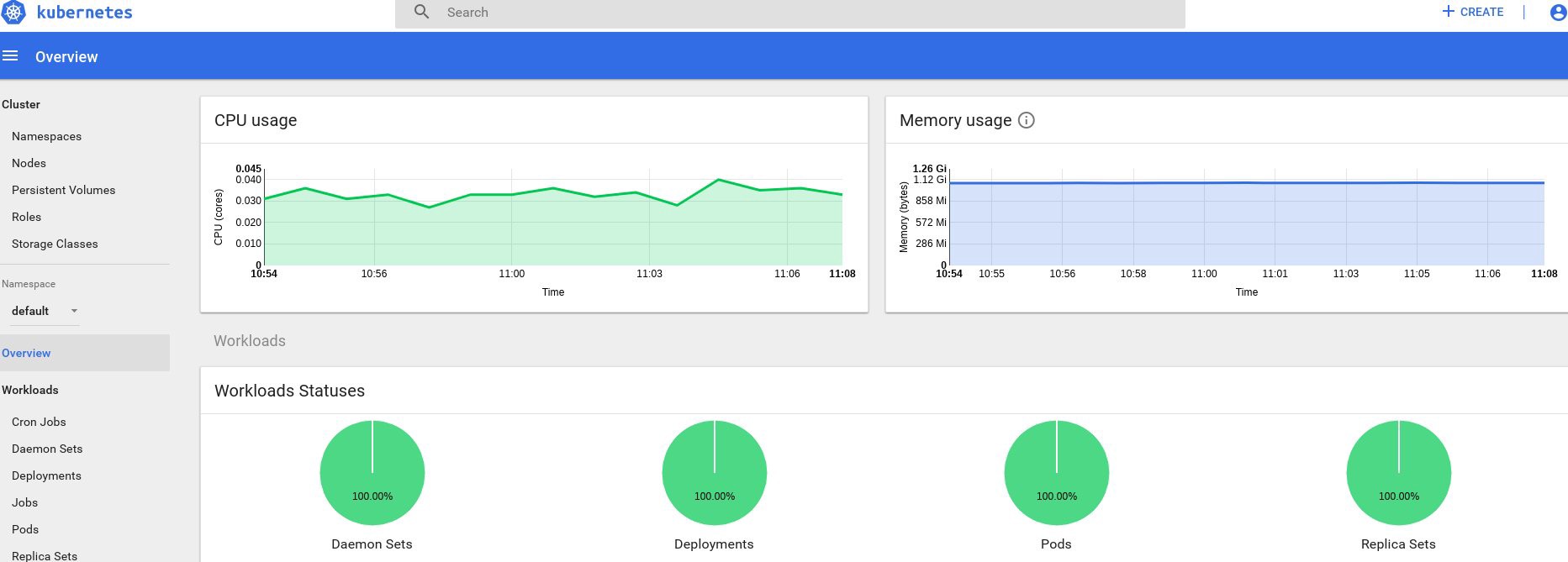

A partir de agora, também podemos rastrear o uso real de recursos para nós de cluster, lareiras, etc.
Se isso não for suficiente, você poderá melhorar ainda mais as estatísticas adicionando o InfluxDB + Grafana. Isso adicionará a capacidade de desenhar seus próprios painéis Grafana.
Usaremos esta versão da instalação do InfluxDB + Grafana na página Heapster Git, mas, como sempre, faremos as correções. Como já configuramos a implantação do heapster, precisamos apenas adicionar o Grafana e o InfluxDB e modificar a implantação do heapster existente para que ele também coloque métricas no Influx.
Ok, vamos criar as implantações do InfluxDB e Grafana:
control# vi influxdb.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: name: monitoring-influxdb namespace: kube-system spec: replicas: 1 template: metadata: labels: task: monitoring k8s-app: influxdb spec: containers: - name: influxdb image: k8s.gcr.io/heapster-influxdb-amd64:v1.5.2 volumeMounts: - mountPath: /data name: influxdb-storage volumes: - name: influxdb-storage emptyDir: {} --- apiVersion: v1 kind: Service metadata: labels: task: monitoring # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons) # If you are NOT using this as an addon, you should comment out this line. kubernetes.io/cluster-service: 'true' kubernetes.io/name: monitoring-influxdb name: monitoring-influxdb namespace: kube-system spec: ports: - port: 8086 targetPort: 8086 selector: k8s-app: influxdb
O próximo é o Grafana, e não esqueça de alterar as configurações do serviço para ativar o balanceador de carga MetaLB e obter o endereço IP externo para o serviço Grafana.
control# vi grafana.yaml apiVersion: extensions/v1beta1 kind: Deployment metadata: name: monitoring-grafana namespace: kube-system spec: replicas: 1 template: metadata: labels: task: monitoring k8s-app: grafana spec: containers: - name: grafana image: k8s.gcr.io/heapster-grafana-amd64:v5.0.4 ports: - containerPort: 3000 protocol: TCP volumeMounts: - mountPath: /etc/ssl/certs name: ca-certificates readOnly: true - mountPath: /var name: grafana-storage env: - name: INFLUXDB_HOST value: monitoring-influxdb - name: GF_SERVER_HTTP_PORT value: "3000" # The following env variables are required to make Grafana accessible via # the kubernetes api-server proxy. On production clusters, we recommend # removing these env variables, setup auth for grafana, and expose the grafana # service using a LoadBalancer or a public IP. - name: GF_AUTH_BASIC_ENABLED value: "false" - name: GF_AUTH_ANONYMOUS_ENABLED value: "true" - name: GF_AUTH_ANONYMOUS_ORG_ROLE value: Admin - name: GF_SERVER_ROOT_URL # If you're only using the API Server proxy, set this value instead: # value: /api/v1/namespaces/kube-system/services/monitoring-grafana/proxy value: / volumes: - name: ca-certificates hostPath: path: /etc/ssl/certs - name: grafana-storage emptyDir: {} --- apiVersion: v1 kind: Service metadata: labels: # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons) # If you are NOT using this as an addon, you should comment out this line. kubernetes.io/cluster-service: 'true' kubernetes.io/name: monitoring-grafana name: monitoring-grafana namespace: kube-system spec: # In a production setup, we recommend accessing Grafana through an external Loadbalancer # or through a public IP. # type: LoadBalancer # You could also use NodePort to expose the service at a randomly-generated port # type: NodePort type: LoadBalancer ports: - port: 80 targetPort: 3000 selector: k8s-app: grafana
E crie-os:
control# kubectl create -f influxdb.yaml deployment.extensions/monitoring-influxdb created service/monitoring-influxdb created control# kubectl create -f grafana.yaml deployment.extensions/monitoring-grafana created service/monitoring-grafana created
Está na hora de alterar a implantação do heapster e adicionar a conexão do InfluxDB a ele; você precisa adicionar apenas uma linha:
- --sink=influxdb:http://monitoring-influxdb.kube-system.svc:8086
Edite a implementação do heapster:
control# kubectl get deployments --namespace=kube-system NAME READY UP-TO-DATE AVAILABLE AGE coredns 2/2 2 2 49d heapster 1/1 1 1 2d12h kubernetes-dashboard 1/1 1 1 3d21h monitoring-grafana 1/1 1 1 115s monitoring-influxdb 1/1 1 1 2m18s control# kubectl edit deployment heapster --namespace=kube-system ... beginning bla bla bla spec: containers: - command: - /heapster - --source=kubernetes.summary_api:''?useServiceAccount=true&kubeletHttps=true&kubeletPort=10250&insecure=true - --sink=influxdb:http://monitoring-influxdb.kube-system.svc:8086 image: gcr.io/google_containers/heapster-amd64:v1.4.2 imagePullPolicy: IfNotPresent .... end
Agora encontre o endereço IP externo do serviço Grafana e faça o login no sistema dentro dele:
control# kubectl get svc --namespace=kube-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ..... some other services here monitoring-grafana LoadBalancer 10.98.111.200 192.168.0.241 80:32148/TCP 18m
Abra http://192.168.0.241 em um navegador e, pela primeira vez, use as credenciais de administrador / administrador:

Quando eu entrei, meu Grafana estava vazio, mas, felizmente, podemos obter todos os painéis necessários em grafana.com . Você precisa importar os painéis nº 3649 e 3646. Ao importar, selecione a fonte de dados correta.
Depois disso, monitore o uso de recursos de nós e lares e, é claro, crie seus próprios painéis exclusivos.
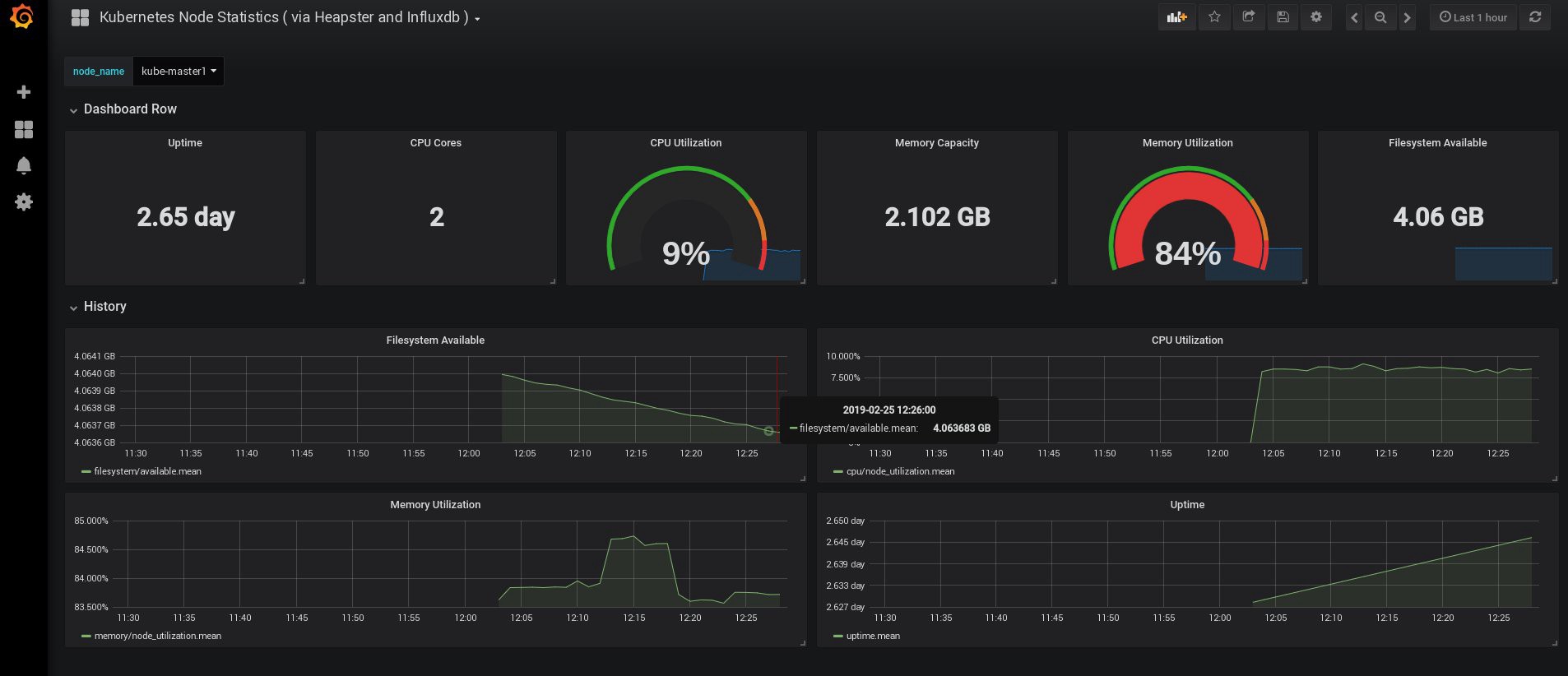
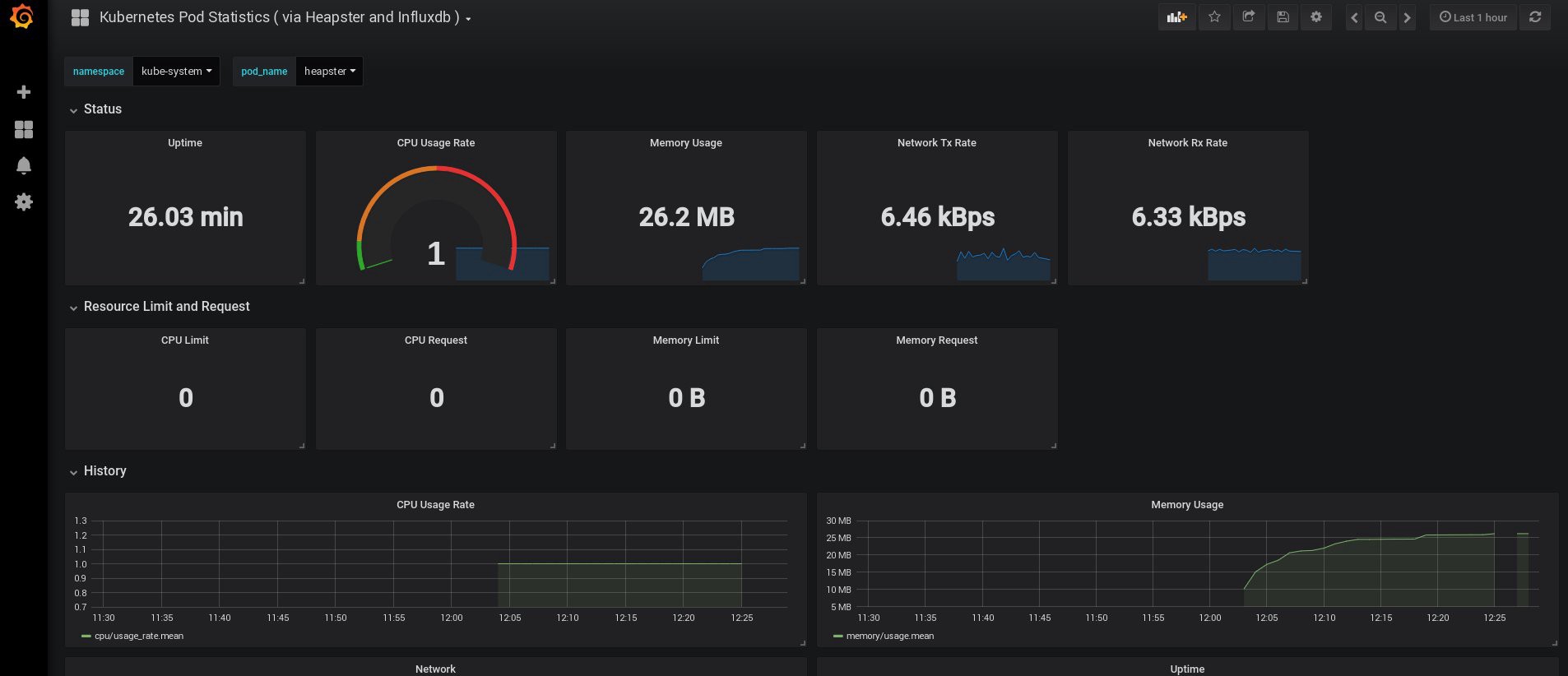
Bem, por enquanto, vamos terminar com o monitoramento; Os seguintes elementos que podemos precisar são os logs para armazenar nossos aplicativos e o cluster. Existem várias maneiras de implementar isso, e todas são descritas na documentação do Kubernetes. Com base em minha própria experiência, prefiro usar instalações externas dos serviços Elasticsearch e Kibana, bem como apenas agentes de registro que são executados em cada nó de trabalho do Kubernetes. Isso protegerá o cluster contra sobrecargas associadas a um grande número de logs e outros problemas e permitirá receber logs, mesmo se o cluster se tornar completamente completamente inoperante.
A pilha de coleta de logs mais popular para os fãs do Kubernetes é Elasticsearch, Fluentd e Kibana (pilha EFK). Neste exemplo, executaremos o Elasticsearch e o Kibana em um nó externo (você pode usar a pilha ELK existente), bem como o Fluentd dentro de nosso cluster como daemonset para cada nó como um agente de coleta de logs.
Vou pular a parte sobre a criação de uma VM com as instalações Elasticsearch e Kibana; Este é um tópico bastante popular, para que você possa encontrar muito material sobre a melhor forma de fazê-lo. Por exemplo, no meu artigo . Apenas remova o fragmento de configuração do logstash do arquivo docker-compose.yml e também remova 127.0.0.1 da seção elasticsearch ports.
Depois disso, você deve ter uma pesquisa elástica em funcionamento conectada à porta VM-IP: 9200. Para maior segurança, configure o login: passe ou chaves de segurança entre a pesquisa fluente e elástica. No entanto, geralmente os protejo simplesmente com as regras do iptables.
Tudo o que precisa ser feito é criar um daemonset fluente no Kubernetes e especificar o nó elasticsearch : endereço externo da porta na configuração.
Usamos o complemento oficial do Kubernetes com a configuração yaml daqui , com pequenas modificações:
control# vi fluentd-es-ds.yaml apiVersion: v1 kind: ServiceAccount metadata: name: fluentd-es namespace: kube-system labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluentd-es labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile rules: - apiGroups: - "" resources: - "namespaces" - "pods" verbs: - "get" - "watch" - "list" --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluentd-es labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile subjects: - kind: ServiceAccount name: fluentd-es namespace: kube-system apiGroup: "" roleRef: kind: ClusterRole name: fluentd-es apiGroup: "" --- apiVersion: apps/v1 kind: DaemonSet metadata: name: fluentd-es-v2.4.0 namespace: kube-system labels: k8s-app: fluentd-es version: v2.4.0 kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile spec: selector: matchLabels: k8s-app: fluentd-es version: v2.4.0 template: metadata: labels: k8s-app: fluentd-es kubernetes.io/cluster-service: "true" version: v2.4.0 # This annotation ensures that fluentd does not get evicted if the node # supports critical pod annotation based priority scheme. # Note that this does not guarantee admission on the nodes (#40573). annotations: scheduler.alpha.kubernetes.io/critical-pod: '' seccomp.security.alpha.kubernetes.io/pod: 'docker/default' spec: priorityClassName: system-node-critical serviceAccountName: fluentd-es containers: - name: fluentd-es image: k8s.gcr.io/fluentd-elasticsearch:v2.4.0 env: - name: FLUENTD_ARGS value: --no-supervisor -q resources: limits: memory: 500Mi requests: cpu: 100m memory: 200Mi volumeMounts: - name: varlog mountPath: /var/log - name: varlibdockercontainers mountPath: /var/lib/docker/containers readOnly: true - name: config-volume mountPath: /etc/fluent/config.d terminationGracePeriodSeconds: 30 volumes: - name: varlog hostPath: path: /var/log - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers - name: config-volume configMap: name: fluentd-es-config-v0.2.0
Em seguida, faremos uma configuração específica do fluentd:
control# vi fluentd-es-configmap.yaml kind: ConfigMap apiVersion: v1 metadata: name: fluentd-es-config-v0.2.0 namespace: kube-system labels: addonmanager.kubernetes.io/mode: Reconcile data: system.conf: |- <system> root_dir /tmp/fluentd-buffers/ </system> containers.input.conf: |-
@id fluentd-containers.log @type tail path /var/log/containers/*.log pos_file /var/log/es-containers.log.pos tag raw.kubernetes.* read_from_head true <parse> @type multi_format <pattern> format json time_key time time_format %Y-%m-%dT%H:%M:%S.%NZ </pattern> <pattern> format /^(?<time>.+) (?<stream>stdout|stderr) [^ ]* (?<log>.*)$/ time_format %Y-%m-%dT%H:%M:%S.%N%:z </pattern> </parse>
# Detect exceptions in the log output and forward them as one log entry. <match raw.kubernetes.**> @id raw.kubernetes @type detect_exceptions remove_tag_prefix raw message log stream stream multiline_flush_interval 5 max_bytes 500000 max_lines 1000 </match> # Concatenate multi-line logs <filter **> @id filter_concat @type concat key message multiline_end_regexp /\n$/ separator "" </filter> # Enriches records with Kubernetes metadata <filter kubernetes.**> @id filter_kubernetes_metadata @type kubernetes_metadata </filter> # Fixes json fields in Elasticsearch <filter kubernetes.**> @id filter_parser @type parser key_name log reserve_data true remove_key_name_field true <parse> @type multi_format <pattern> format json </pattern> <pattern> format none </pattern> </parse> </filter> output.conf: |- <match **> @id elasticsearch @type elasticsearch @log_level info type_name _doc include_tag_key true host 192.168.1.253 port 9200 logstash_format true <buffer> @type file path /var/log/fluentd-buffers/kubernetes.system.buffer flush_mode interval retry_type exponential_backoff flush_thread_count 2 flush_interval 5s retry_forever retry_max_interval 30 chunk_limit_size 2M queue_limit_length 8 overflow_action block </buffer> </match>
A configuração é elementar, mas é suficiente para um início rápido; ele coletará logs do sistema e de aplicativos. Se você precisar de algo mais complicado, consulte a documentação oficial sobre plugins fluentes e configurações do Kubernetes.
Agora vamos criar um daemonset fluente em nosso cluster:
control# kubectl create -f fluentd-es-ds.yaml serviceaccount/fluentd-es created clusterrole.rbac.authorization.k8s.io/fluentd-es created clusterrolebinding.rbac.authorization.k8s.io/fluentd-es created daemonset.apps/fluentd-es-v2.4.0 created control# kubectl create -f fluentd-es-configmap.yaml configmap/fluentd-es-config-v0.2.0 created
Verifique se todos os pods fluentes e outros recursos estão funcionando com êxito e abra o Kibana. No Kibana, encontre e adicione um novo índice do fluentd. Se você encontrar algo, tudo será feito corretamente; caso contrário, verifique as etapas anteriores e recrie o daemonset ou edite o configmap:

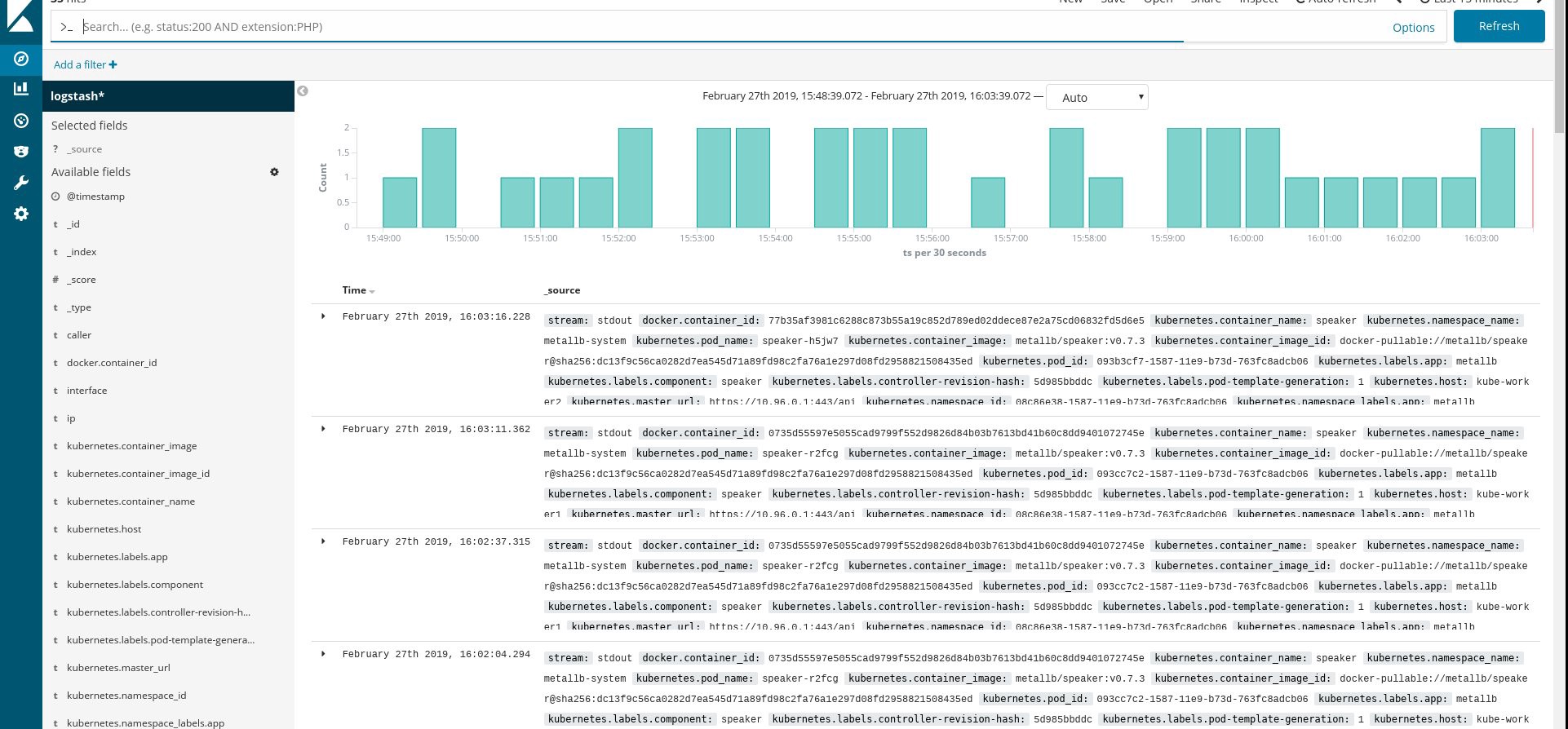
Bem, agora que obtemos os logs do cluster, você pode criar qualquer painel. Obviamente, a configuração é a mais simples, portanto você provavelmente precisará alterá-la por si mesmo. O objetivo principal era mostrar como isso é feito.
Após concluir todas as etapas anteriores, obtivemos um cluster Kubernetes realmente bom e pronto para uso. É hora de incorporar algum aplicativo de teste e ver o que acontece.
Neste exemplo, pegue meu pequeno aplicativo Python / Flask Kubyk, que já possui um contêiner do Docker, então use-o no registro aberto do docker. Agora, adicionaremos um arquivo de banco de dados externo a este aplicativo - para isso, usaremos o armazenamento GlusterFS configurado.
Primeiro, criamos um novo volume de pvc para este aplicativo (solicitação de volume permanente), onde armazenaremos o banco de dados SQLite com credenciais de usuário. Você pode usar a classe de memória pré-criada da parte 2 deste guia.
control# mkdir kubyk && cd kubyk control# vi kubyk-pvc.yaml kind: PersistentVolumeClaim apiVersion: v1 metadata: name: kubyk annotations: volume.beta.kubernetes.io/storage-class: "slow" spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi control# kubectl create -f kubyk-pvc.yaml
Depois de criar um novo PVC para o aplicativo, estamos prontos para a implantação.
control# vi kubyk-deploy.yaml apiVersion: apps/v1 kind: Deployment metadata: name: kubyk-deployment spec: selector: matchLabels: app: kubyk replicas: 1 template: metadata: labels: app: kubyk spec: containers: - name: kubyk image: ratibor78/kubyk ports: - containerPort: 80 volumeMounts: - name: kubyk-db mountPath: /kubyk/sqlite volumes: - name: kubyk-db persistentVolumeClaim: claimName: kubyk control# vi kubyk-service.yaml apiVersion: v1 kind: Service metadata: name: kubyk spec: type: LoadBalancer selector: app: kubyk ports: - port: 80 name: http
Agora vamos criar uma implantação e serviço:
control# kubectl create -f kubyk-deploy.yaml deployment.apps/kubyk-deployment created control# kubectl create -f kubyk-service.yaml service/kubyk created
Verifique o novo endereço IP atribuído ao serviço, bem como o status do sub:
control# kubectl get po NAME READY STATUS RESTARTS AGE glusterfs-2wxk7 1/1 Running 1 2d1h glusterfs-5dtdj 1/1 Running 1 41d glusterfs-zqxwt 1/1 Running 0 2d1h heketi-b8c5f6554-f92rn 1/1 Running 0 8d kubyk-deployment-75d5447d46-jrttp 1/1 Running 0 11s control# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE ... some text.. kubyk LoadBalancer 10.109.105.224 192.168.0.242 80:32384/TCP 10s
Então, parece que lançamos com sucesso um novo aplicativo; se abrirmos o endereço IP http://192.168.0.242 no navegador, deveremos ver a página de login deste aplicativo. Você pode usar as credenciais de administrador / administrador para efetuar login, mas se tentarmos fazer login nesse estágio, receberemos um erro porque ainda não há um banco de dados disponível.
Aqui está um exemplo de uma mensagem de erro de log da lareira no painel do Kubernetes:
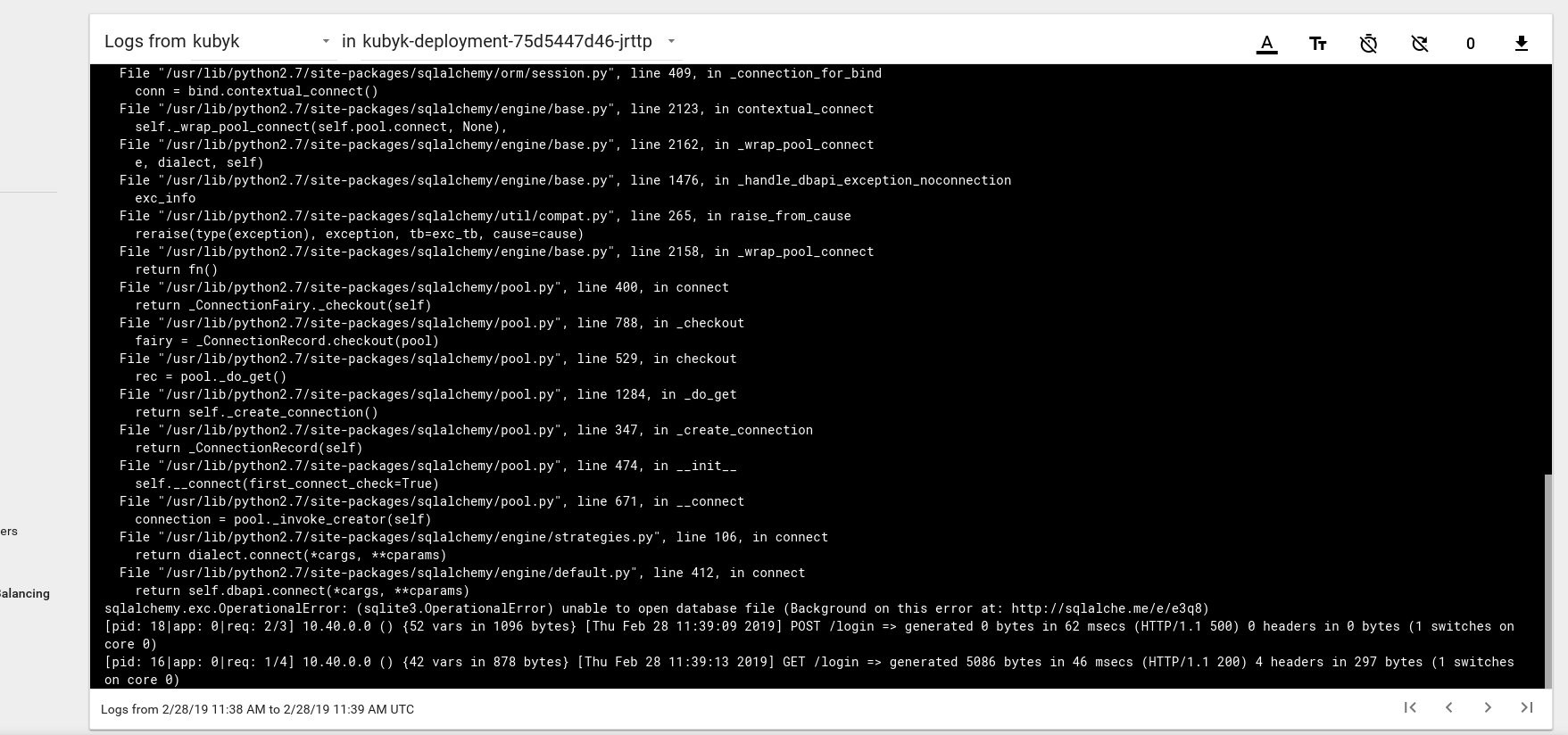
Para corrigir isso, você precisa copiar o arquivo SQlite DB do meu repositório git para o volume pvc criado anteriormente. O aplicativo começará a usar esse banco de dados.
control# git pull https://github.com/ratibor78/kubyk.git control# kubectl cp ./kubyk/sqlite/database.db kubyk-deployment-75d5447d46-jrttp:/kubyk/sqlite
Usamos o under do aplicativo e o comando kubectl cp para copiar esse arquivo no volume.
Você também deve conceder acesso de gravação do usuário nginx a este diretório; meu aplicativo é iniciado pelo usuário nginx usando supervisord .
control# kubectl exec -ti kubyk-deployment-75d5447d46-jrttp -- chown -R nginx:nginx /kubyk/sqlite/
Vamos tentar fazer login novamente:
Ótimo, agora nosso aplicativo funciona corretamente e podemos dimensionar a implantação do kubyk para três réplicas, por exemplo, para colocar uma cópia do aplicativo em um nó de trabalho. Como criamos anteriormente o volume pvc, todos os nossos pods com réplicas de aplicativos usarão o mesmo banco de dados, e o serviço distribuirá o tráfego entre as réplicas de maneira circular.
control# kubectl get deployments NAME READY UP-TO-DATE AVAILABLE AGE heketi 1/1 1 1 39d kubyk-deployment 1/1 1 1 4h5m control# kubectl scale deployments kubyk-deployment --replicas=3 deployment.extensions/kubyk-deployment scaled control# kubectl get po NAME READY STATUS RESTARTS AGE glusterfs-2wxk7 1/1 Running 1 2d5h glusterfs-5dtdj 1/1 Running 21 41d glusterfs-zqxwt 1/1 Running 0 2d5h heketi-b8c5f6554-f92rn 1/1 Running 0 8d kubyk-deployment-75d5447d46-bdnqx 1/1 Running 0 26s kubyk-deployment-75d5447d46-jrttp 1/1 Running 0 4h7m kubyk-deployment-75d5447d46-wz9xz 1/1 Running 0 26s
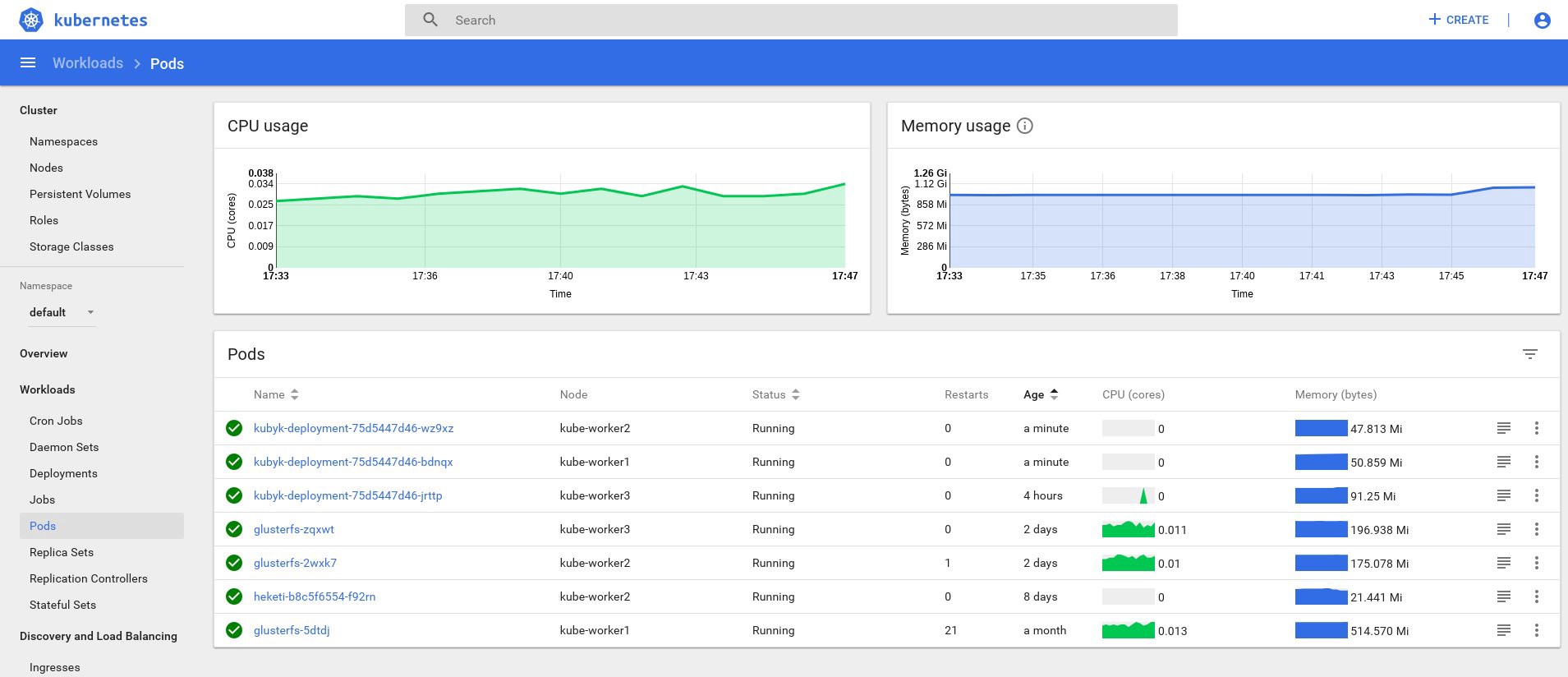
Agora, temos réplicas de aplicativos para cada nó de trabalho, para que o aplicativo não pare de funcionar se perder algum nó. Além disso, temos uma maneira simples de equilibrar a carga, como eu disse anteriormente. Não é um mau lugar para começar.
Vamos criar um novo usuário em nosso aplicativo:
Todas as novas solicitações serão processadas no próximo coração da lista. Isso pode ser verificado pelos registros das lareiras. Por exemplo, um novo usuário é criado pelo aplicativo em um sub, em seguida o próximo sub responde à próxima solicitação e assim por diante. Como esse aplicativo usa um único volume persistente para armazenar o banco de dados, todos os dados estarão seguros, mesmo que todas as réplicas sejam perdidas.
Em aplicativos grandes e complexos, você precisará não apenas de um volume designado para o banco de dados, mas de vários volumes para acomodar informações persistentes e muitos outros elementos.
Bem, estamos quase terminando. Você pode adicionar muitos outros aspectos, já que o Kubernetes é um tópico volumoso e dinâmico, mas vamos parar por aí. O principal objetivo desta série de artigos era mostrar como criar seu próprio cluster Kubernetes, e espero que essas informações tenham sido úteis para você.
PS
Testes de estabilidade e testes de estresse, é claro.
O diagrama de cluster do nosso exemplo funciona sem 2 nós em funcionamento, 1 nós principais e 1 nós etcd. Se desejar, desative-os e verifique se o aplicativo de teste funcionará.
Ao compilar esses guias, preparei um cluster de produção para um esquema quase semelhante. Uma vez, tendo criado um cluster e implantado um aplicativo nele, encontrei uma grande falha de energia; absolutamente todos os servidores do cluster foram cortados - um animado pesadelo para o administrador do sistema. Alguns servidores foram desligados por um longo período de tempo e, em seguida, ocorreram erros no sistema de arquivos. Mas o relançamento me surpreendeu muito: o cluster Kubernetes se recuperou totalmente. Todos os volumes e implantações do GlusterFS foram lançados. Para mim, isso é uma demonstração do grande potencial dessa tecnologia.
Tudo de bom e, espero, até breve!