
O código é usado para criar interfaces. Mas o código em si é uma interface.
Apesar do fato de a legibilidade do código ser muito importante, esse conceito é mal definido - e geralmente na forma de apenas um conjunto de regras: use nomes de variáveis significativos, divida funções grandes em funções menores e use padrões de design padrão.
Ao mesmo tempo, com certeza, todos tiveram que lidar com um código que cumpra essas regras, mas por algum motivo há algum tipo de confusão.
Você pode tentar resolver esse problema adicionando novas regras: se os nomes das variáveis forem muito longos, será necessário refatorar a lógica principal; se muitos métodos auxiliares se acumularam em uma classe, talvez deva ser dividido em duas; Os padrões de design não podem ser aplicados no contexto errado.
Essas instruções se transformam em um labirinto de decisões subjetivas e, para navegar nelas, você precisará de um desenvolvedor que possa fazer a escolha certa - ou seja, ele já deve conseguir escrever código legível.
Portanto, um conjunto de instruções não é uma opção. Portanto, teremos que formular uma imagem mais ampla da legibilidade do código.
Por que a legibilidade é necessária
Na prática, boa legibilidade geralmente significa que o código é agradável de ler. No entanto, não se pode ir muito longe nessa definição: em primeiro lugar, é subjetiva e, em segundo lugar, nos vincula à leitura de um texto comum.
Um código ilegível é percebido como um romance que finge ser um código: muitos comentários revelando a essência do que está acontecendo, folhas de texto que precisam ser lidas sequencialmente, formulações inteligentes, cujo único significado é ser “inteligente”, medo de reutilizar palavras. O desenvolvedor está tentando tornar o código legível, mas está direcionando para o tipo errado de leitores.
Legibilidade de texto e legibilidade de código não são a mesma coisa.
Traduzido para AlconostO código é usado para criar interfaces. Mas o código em si é uma interface.
Se o código estiver bonito, significa que é legível? A estética é um agradável efeito colateral da legibilidade, mas como critério não é muito útil. Talvez em casos extremos, a estética do código no projeto ajude a reter funcionários - mas com o mesmo sucesso, você pode oferecer um bom pacote social. Além disso, todos têm sua própria idéia do que significa "código bonito". E, com o tempo, essa definição de legibilidade se transforma em um redemoinho de disputas sobre tabulação, espaços, colchetes, "notação de camelo" etc. É improvável que alguém perca a consciência ao ver o recuo errado, embora isso chame a atenção ao verificar o código.
Se o código produzir menos erros, ele poderá ser considerado mais legível? Quanto menos erros, melhor, mas que mecanismo existe? Como posso atribuir as vagas sensações agradáveis que você experimenta ao ler o código? Além disso, não importa o quanto as sobrancelhas franzidas estejam ao ler o código, isso não adicionará erros.
Se o código é fácil de editar, é legível? Mas essa talvez seja a direção correta do pensamento. Os requisitos mudam, as funções são adicionadas, os erros surgem - e em algum momento alguém precisa editar seu código. E, para não causar novos problemas, o desenvolvedor precisa entender o que exatamente ele está editando e como as alterações mudarão o comportamento do código. Portanto, encontramos uma nova regra heurística: o código legível deve ser fácil de editar.
Qual código é mais fácil de editar?
Eu quero imediatamente deixar claro: “O código é mais fácil de editar quando os nomes das variáveis são dados de maneira significativa”, mas apenas renomeamos “legibilidade” para “facilidade de edição”. Precisamos de um entendimento mais profundo, e não do mesmo conjunto de regras de forma diferente.
Vamos começar esquecendo por um momento que estamos falando de código. A programação, que tem várias décadas, é apenas um ponto na escala da história humana. Limitando-nos a este "ponto", não podemos cavar fundo.
Portanto, vejamos a legibilidade através do prisma de projetar interfaces que encontramos em quase todas as etapas - e não apenas nas digitais. O brinquedo tem uma funcionalidade que o faz andar ou guinchar. A porta possui uma interface que permite abrir, fechar e trancá-la. Os dados no livro são coletados em páginas, o que fornece acesso aleatório mais rápido que a rolagem. Ao estudar design, você pode aprender muito mais sobre essas interfaces - pergunte à equipe de design se puder. No caso geral, todos nós preferimos boas interfaces, mesmo que nem sempre saibamos o que as torna boas.
O código é usado para criar interfaces. Mas o próprio código, combinado com o IDE, é uma interface. Uma interface projetada para um grupo muito pequeno de usuários - nossos colegas. Além disso, os chamaremos de "usuários" - para permanecer no espaço de criação da interface do usuário.
Com isso em mente, considere estes exemplos de caminhos do usuário:
- O usuário deseja adicionar uma nova função. Isso requer encontrar o lugar certo e adicionar uma função sem gerar novos erros.
- O usuário deseja corrigir o erro. Ele precisará encontrar a fonte do problema e editar o código para que o erro desapareça e novos erros não apareçam.
- O usuário deseja garantir que, em casos limítrofes, o código se comporte de uma certa maneira. Ele precisará encontrar um pedaço de código específico, rastrear a lógica e simular o que acontece.
E assim por diante: a maioria dos caminhos segue um padrão semelhante. Para não complicar as coisas, considere exemplos específicos - mas não esqueça que esta é uma busca por princípios gerais, não uma lista de regras.
Podemos assumir com confiança que o usuário não poderá abrir imediatamente a seção de código desejada. Isso também se aplica aos seus próprios projetos de hobby: mesmo que a função seja escrita por você, é muito fácil esquecer onde ela está localizada. Portanto, o código deve ser tal que seja fácil encontrar o correto nele.
Para implementar uma pesquisa conveniente, você precisará de alguma otimização do mecanismo de pesquisa - aqui é para nós que nomes significativos de variáveis vêm em socorro. Se o usuário não conseguir encontrar a função, movendo-se ao longo da pilha de chamadas a partir de um ponto conhecido, ele poderá iniciar uma pesquisa por palavras-chave. No entanto, você não pode incluir muitas palavras-chave nos nomes. Ao pesquisar por código, o único ponto de entrada é procurado, de onde você pode continuar a trabalhar mais. Portanto, o usuário precisa ajudar a chegar a um local específico e, se você exagerar nas palavras-chave, haverá muitos resultados de pesquisa inúteis.
Se o usuário puder verificar imediatamente se tudo está correto em um nível específico de lógica, ele poderá esquecer as camadas anteriores da abstração e liberar sua mente para a próxima.
Você pode pesquisar usando o preenchimento automático: se tiver uma ideia geral de qual função deseja chamar ou qual enumeração usar, poderá começar a digitar o nome pretendido e selecionar a opção apropriada na lista de preenchimento automático. Se a função for destinada apenas a determinados casos ou se você precisar ler atentamente sua implementação devido aos recursos de seu uso, poderá indicá-lo dando um nome mais autêntico: percorrendo a lista de preenchimento automático, o usuário evitará o que parecer complicado - a menos que, é claro, ele tenha certeza o que faz
Portanto, nomes curtos e regulares têm maior probabilidade de serem percebidos como opções padrão, adequadas para usuários "casuais". Não deve haver surpresas em funções com esses nomes: você não pode inserir setters em funções que se parecem com getters simples, pelo mesmo motivo que o botão Exibir na interface não deve alterar os dados do usuário.

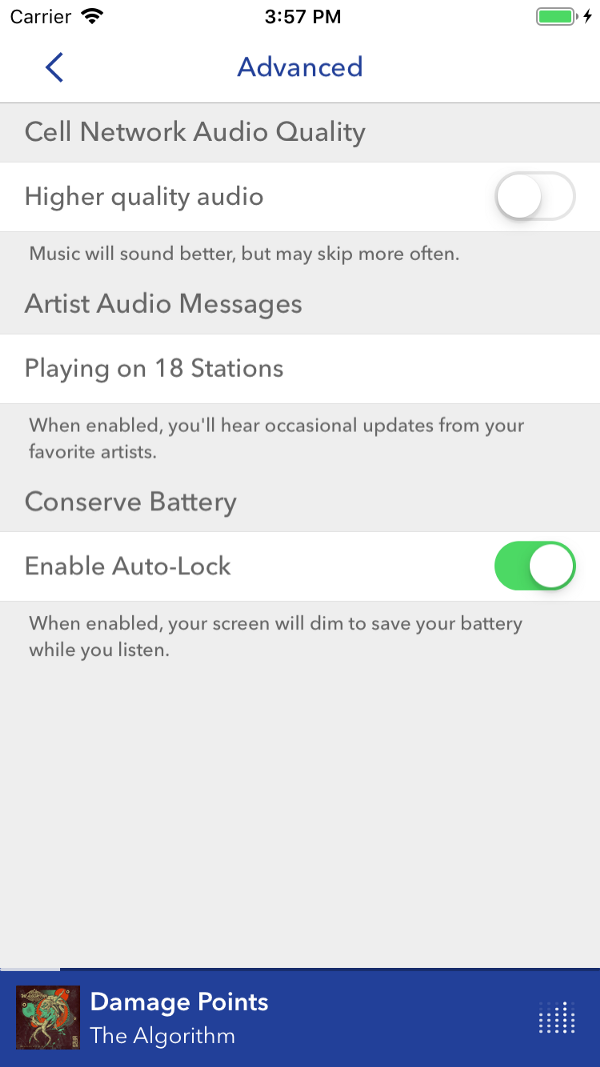 Na interface voltada para o cliente, funções familiares, como uma pausa, ficam quase sem texto. À medida que a funcionalidade se torna mais complexa, os nomes aumentam, o que faz com que os usuários desacelerem e pensem. Captura de tela - Pandora
Na interface voltada para o cliente, funções familiares, como uma pausa, ficam quase sem texto. À medida que a funcionalidade se torna mais complexa, os nomes aumentam, o que faz com que os usuários desacelerem e pensem. Captura de tela - PandoraOs usuários desejam encontrar as informações corretas rapidamente. Na maioria dos casos, a compilação leva um tempo considerável e, em um aplicativo em execução, você terá que verificar manualmente muitos casos de borda diferentes. Se possível, nossos usuários preferem ler o código e entender como ele se comporta, em vez de definir pontos de interrupção e executar o código.
Para não executar o código, duas condições devem ser atendidas:
- O usuário entende o que o código está tentando fazer.
- O usuário tem certeza de que o código faz o que afirma.
As abstrações ajudam a satisfazer a primeira condição: os usuários devem poder mergulhar em camadas de abstração até o nível de detalhe desejado. Imagine uma interface hierárquica do usuário: nos primeiros níveis, a navegação é realizada em seções extensas e depois cada vez mais concretizadas - no nível da lógica que precisa ser estudada com mais detalhes.
A leitura seqüencial de um arquivo ou método é realizada em tempo linear. Mas se o usuário puder mover para cima e para baixo as pilhas de chamadas - esta é uma pesquisa na árvore e se a hierarquia estiver bem equilibrada, essa ação será executada em um tempo logarítmico. Certamente, há espaço para listas nas interfaces, mas você deve considerar cuidadosamente se deve haver mais de duas ou três chamadas de método em algum contexto.
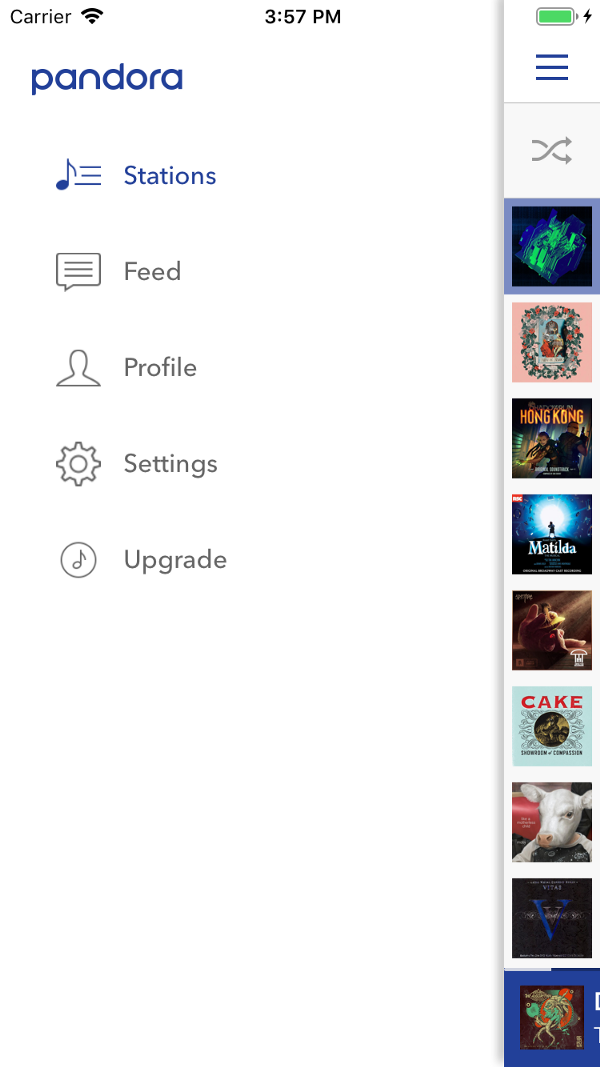
 Em menus curtos, a navegação hierárquica é muito mais rápida. No menu "longo" à direita - apenas 11 linhas. Com que frequência nos encaixamos nesse número no código do método? Captura de tela - Pandora
Em menus curtos, a navegação hierárquica é muito mais rápida. No menu "longo" à direita - apenas 11 linhas. Com que frequência nos encaixamos nesse número no código do método? Captura de tela - PandoraUsuários diferentes têm estratégias diferentes para a segunda condição. Em situações de baixo risco, comentários ou nomes de métodos são evidências suficientes. Em áreas mais arriscadas e complexas, bem como quando o código está sobrecarregado com comentários irrelevantes, é provável que estes últimos sejam ignorados. Às vezes, até os nomes dos métodos e variáveis estarão em dúvida. Nesses casos, o usuário deve ler muito mais código e ter em mente um modelo lógico mais amplo. Limitar o contexto a pequenas áreas fáceis de segurar também ajudará aqui. Se o usuário puder verificar imediatamente se tudo está correto em um nível específico de lógica, ele poderá esquecer as camadas anteriores da abstração e liberar sua mente para a próxima.
Nesse modo de operação, os tokens individuais começam a ter maior importância. Por exemplo, um sinalizador booleano
element.visible = true/false
é fácil entender isso isoladamente do restante do código, mas isso requer a combinação de dois tokens diferentes na mente. Se usar
element.visibility = .visible/.hidden
então, o valor do sinalizador pode ser entendido imediatamente: nesse caso, você não precisa ler o nome da variável para descobrir que está relacionado à visibilidade. Vimos abordagens semelhantes ao projetar interfaces orientadas para o cliente. Nas últimas décadas, os botões OK e Cancelar se transformaram em elementos de interface mais descritivos: "Salvar" e "Cancelar", "Enviar" e "Continuar editando" etc., para entender o que será feito, basta que o usuário analise as opções propostas sem ler o contexto inteiro.
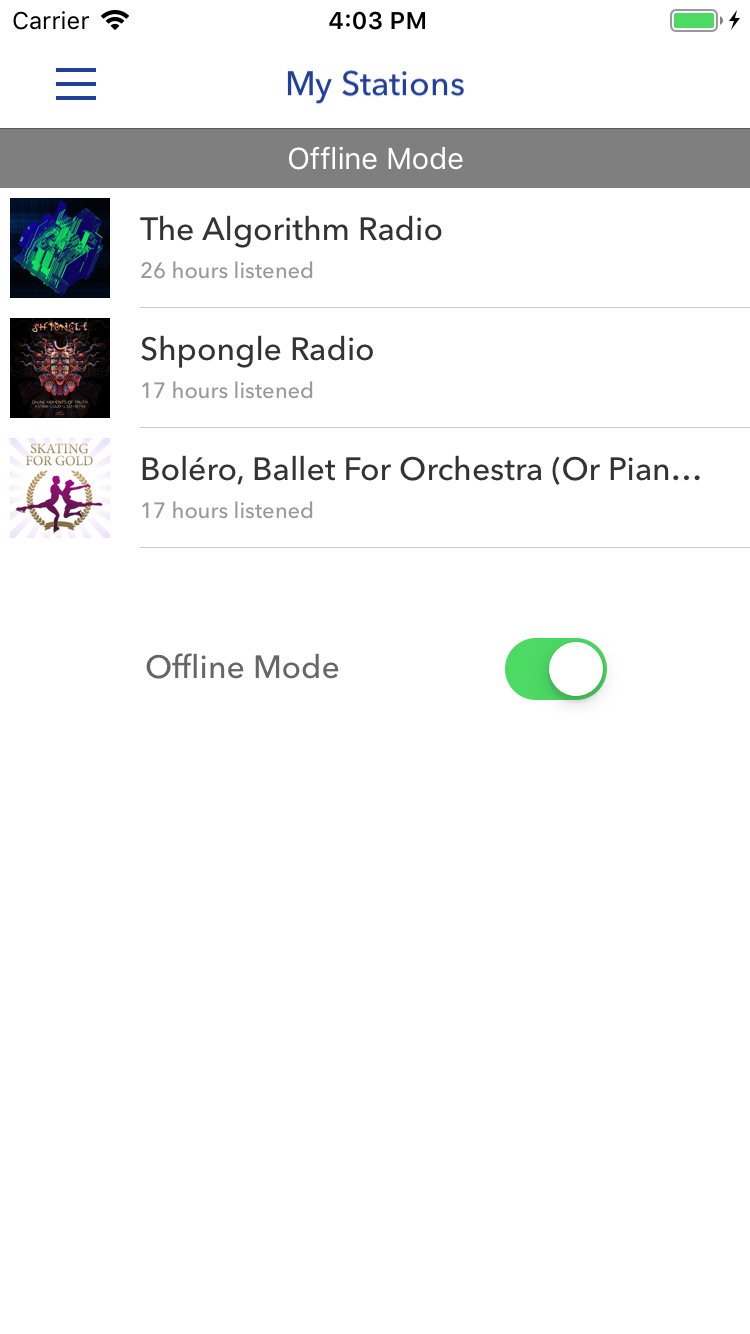 A linha "Modo offline" no exemplo acima indica que o aplicativo está offline. A opção no exemplo abaixo tem o mesmo significado, mas para entendê-lo, é necessário olhar o contexto. Captura de tela - Pandora
A linha "Modo offline" no exemplo acima indica que o aplicativo está offline. A opção no exemplo abaixo tem o mesmo significado, mas para entendê-lo, é necessário olhar o contexto. Captura de tela - PandoraOs testes de unidade também ajudam a confirmar o comportamento esperado do código: eles agem como comentários - que, no entanto, podem ser confiáveis em maior medida, pois são mais relevantes. É verdade que eles também precisam concluir a montagem. Porém, no caso de um pipeline de IC bem estabelecido, os testes são executados regularmente, para que você possa pular esta etapa ao fazer alterações no código existente.
Em teoria, a segurança segue de um entendimento suficiente: assim que nosso usuário entender o comportamento do código, ele poderá fazer alterações com segurança. Na prática, você deve considerar que os desenvolvedores são pessoas comuns: nosso cérebro usa os mesmos truques e também é preguiçoso. Portanto, quanto menos esforço você precisar para entender o código, mais seguras serão nossas ações.
O código legível deve passar a maioria das verificações de erro para o computador. Uma das maneiras de fazer isso é usar as verificações de depuração "assert", no entanto, elas também exigem montagem e inicialização. Pior ainda, se o usuário se esqueceu de casos limítrofes, a afirmação não ajudará. Os testes de unidade para verificar casos de borda frequentemente esquecidos podem ter um desempenho melhor, mas depois que o usuário fizer alterações, será necessário aguardar a execução dos testes.
Em resumo: o código legível deve ser fácil de usar. E - como efeito colateral - pode parecer bonito.
Para acelerar o ciclo de desenvolvimento, usamos a função de verificação de erros incorporada no compilador. Normalmente, nesses casos, uma montagem completa não é necessária e os erros são exibidos em tempo real. Como aproveitar esta oportunidade? De um modo geral, você precisa encontrar situações em que as verificações do compilador se tornam muito rigorosas. Por exemplo, a maioria dos compiladores não analisa a abrangência da instrução "if", mas verifica cuidadosamente a opção "switch" quanto a condições ausentes. Se um usuário tentar adicionar ou alterar uma condição, será mais seguro se todos os operadores semelhantes anteriores fossem abrangentes. E quando a condição "case" for alterada, o compilador marcará todas as outras condições que precisam ser verificadas.
Outro problema de legibilidade comum é o uso de primitivas em expressões condicionais. Esse problema é especialmente grave quando o aplicativo analisa JSON, porque você deseja adicionar instruções "if" em torno da igualdade de cadeias ou números inteiros. Isso não apenas aumenta a probabilidade de erros de digitação, mas também complica a tarefa dos usuários de determinar possíveis valores. Ao verificar casos limítrofes, há uma grande diferença entre quando qualquer linha é possível e quando - apenas duas ou três opções separadas. Mesmo que as primitivas sejam fixadas em constantes, você deve se apressar uma vez, tentando finalizar o projeto no prazo, e um valor arbitrário aparecerá. Mas se você usar objetos ou enumerações especialmente criados, o compilador bloqueia os argumentos inválidos e fornece uma lista específica de argumentos válidos.
Da mesma forma, se algumas combinações de sinalizadores booleanos não forem permitidas, substitua-as por uma única enumeração. Pegue, por exemplo, uma composição que pode estar nos seguintes estados: ela é armazenada em buffer, totalmente carregada e reproduzida. Se você imaginar os estados de carregamento e reprodução como dois sinalizadores booleanos
(loaded, playing)
o compilador permitirá a entrada de valores inválidos
(loaded: false, playing: true)
E se você usar a enumeração
(.buffering/.loaded/.playing)
será impossível indicar um estado inválido. Na interface orientada para o cliente, o padrão deve ser proibir combinações inválidas de configurações. Mas quando escrevemos código dentro do aplicativo, geralmente esquecemos de nos fornecer a mesma proteção.
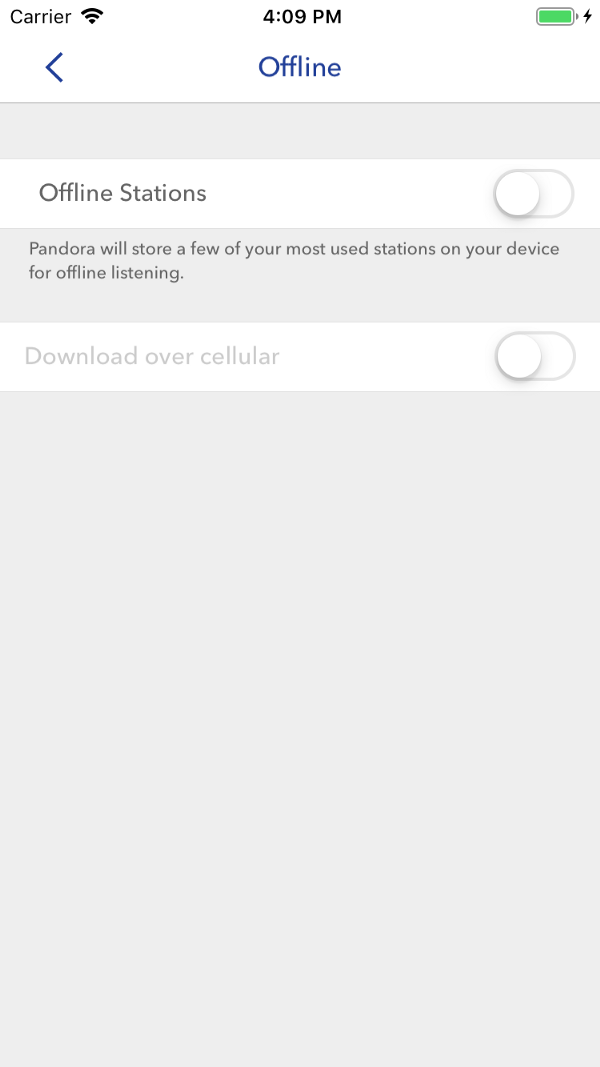
 Combinações inválidas são desabilitadas antecipadamente; os usuários não precisam pensar em quais configurações são incompatíveis. Captura de tela - Apple
Combinações inválidas são desabilitadas antecipadamente; os usuários não precisam pensar em quais configurações são incompatíveis. Captura de tela - AppleSeguindo os caminhos do usuário considerados, chegamos às mesmas regras do início. Mas agora temos um princípio pelo qual eles podem ser formulados de forma independente e alterados de acordo com a situação. Para fazer isso, nos perguntamos:
- Será fácil para o usuário procurar o trecho de código desejado? Os resultados da pesquisa ficarão repletos de funções não relacionadas à consulta?
- Um usuário, tendo encontrado o código necessário, pode verificar rapidamente a correção de seu comportamento?
- O ambiente de desenvolvimento fornece edição segura e reutilização de código?
Em resumo: o código legível deve ser fácil de usar. E - como efeito colateral - pode parecer bonito.
Nota
- Pode parecer que as variáveis booleanas são mais convenientes para reutilizar, mas essa opção de reutilização implica intercambiabilidade. Tomemos, por exemplo, os sinalizadores tocáveis e em cache , que representam conceitos localizados em planos completamente diferentes: a capacidade de clicar em um elemento e o estado do cache. Mas se os dois sinalizadores forem booleanos, você poderá trocá-los acidentalmente, obtendo uma expressão não trivial em uma linha de código, o que significa que o cache está associado à capacidade de clicar em um elemento. Ao usar enumerações, para formar tais relações, seremos forçados a criar uma lógica explícita e verificável para a conversão das "unidades de medida" usadas por nós.
Sobre o tradutorO artigo foi traduzido por Alconost.
A Alconost
localiza jogos ,
aplicativos e sites em 70 idiomas. Tradutores em idioma nativo, teste linguístico, plataforma em nuvem com API, localização contínua, gerentes de projeto 24/7, qualquer formato de recursos de string.
Também criamos
vídeos de publicidade e treinamento - para sites que vendem, imagem, publicidade, treinamento, teasers, exploradores, trailers do Google Play e da App Store.
→
Leia mais