No
artigo anterior, falamos sobre os novos recursos da versão 4 da atualização do Veeam Backup & Replication 9.5 (VBR), lançada em janeiro, onde os backups na fita não foram mencionados conscientemente. A história sobre esta área merece um artigo separado, porque havia realmente muitos recursos novos.
- QA pessoal, escrevem um artigo?
- porque não!Unidades de fita no século XXI
O armazenamento de dados em fitas magnéticas (cassetes,
teips , como os chamamos em P&D) não se limita ao computador ZX-Spectrum, que era coisa do passado, um jogo para o qual poderia ser carregado na RAM de 48 kb de uma
fita por vários minutos. Durante um quarto de século, a velocidade e a capacidade dos cassetes aumentaram em 6-7 ordens de magnitude. Essa comparação não está totalmente correta e o padrão
LTO não está acompanhando
a lei de Moore . No entanto, as tecnologias modernas permitem gravar 12 terabytes de dados em um quilômetro de fita (até 30 terabytes no modo de compactação), de modo que a unidade de 160 dólares deixa os concorrentes para trás no custo do armazenamento de longo prazo de uma grande quantidade de dados, mesmo levando em consideração os investimentos em equipamentos de gravação / leia. Os dados nessas fitas são armazenados de maneira confiável por 15 a 30 anos.
Eu virei do outro lado.
Os vírus de ransomware atingiram um novo nível recentemente. Eles podem esperar seu tempo na infraestrutura de uma grande empresa por semanas e meses e, com o advento de outra vulnerabilidade de dia zero, podem destruir (não sem ajuda humana, porque há muito dinheiro em jogo) não apenas todos os dados, mas também todos os backups que podem ser alcançados. . Aqui está um
novo exemplo de quando uma empresa teve que pagar ransomware. O chamado
gap aéreo , ou seja, backups fisicamente isolados da infraestrutura, tornou-se, de fato, a única salvação confiável de tais histórias. A fita magnética aqui é uma das soluções atemporais.

Mas uma especificação e as novidades tecnológicas de ferro e bário-ferrita dos principais fabricantes (IBM, HPE, Oracle, Dell) para proteção confiável de dados não são suficientes, você precisa de um bom software. Na Veeam, toda a nossa equipe está envolvida em backups em fita, cerca de 10 pessoas analisam, planejam, pesquisam, desenvolvem e testam diariamente. Você pode ver os resultados deste trabalho em artigos anteriores (
um ,
dois ). O que foi feito no ano passado?
Glossário
Há uma escolha entre liberdades em relação à língua nativa e complicando a legibilidade do clericalismo. Eu prefiro o primeiro, então peço desculpas antecipadamente se alguém gíria da lista abaixo machucar os olhos. Aqui vou relembrar brevemente o que um termo específico significa.
Luminares VBR esta parte pode ser puladaJoba - trabalho - trabalho de backup. Na verdade, todo o VBR é construído no trabalho. Além de backup e replicação, também pode ser copiado para fita magnética (trabalho de backup em fita, trabalho de fita). Farei uma reserva de que a restauração de uma cópia de backup (restauração) também é um trabalho, mas neste artigo, essa palavra significa backup.
Storaj - armazenamento - nome estabelecido historicamente. Estes são arquivos no
repositório (repositório - armazenamento), contendo cópias de backup -
completas e
incrementais . Em uma história, pode haver uma ou várias máquinas virtuais.
Cadeia - uma cadeia é uma sequência de histórias relacionadas. Para restaurar dados do n-ésimo armazenamento incremental, são necessários todos os anteriores do (n-1) -st para o 1º e para o armazenamento completo, aos quais o primeiro incremental se refere.
Fonte ,
destino - fonte, destino. Origem é a entidade original que o trabalho processa. No caso de backups / réplicas, geralmente é uma máquina virtual no hipervisor. No caso de trabalho de fita, o backup é o próprio trabalho de backup (bem, ou arquivos no caso de arquivo em trabalhos de fita). Um destino da tarefa de backup é um repositório onde os backups são armazenados. Para trabalhos em fita, esse é um pool de mídias.
Pool de mídia -
pool de mídia - um pool de mídia de armazenamento, no nosso caso - fitas. Um contêiner lógico criado pelo usuário e contendo os cassetes de uma ou mais bibliotecas. Portanto, o trabalho de fita sempre tem um pool de mídias como destino, ou seja, os dados são gravados não em uma fita específica ou em qualquer fita da biblioteca, mas em um conjunto específico deles. O pool de mídias possui uma configuração para o tempo de armazenamento de dados, após o qual o cartucho pode ser substituído. O usuário pode criar
conjuntos padrão e
conjuntos GFS . Agora, cada uma dessas espécies pode ser WORM e não WORM, mais sobre isso abaixo.
Conjunto de mídias -
conjunto de mídias - um conjunto de fitas no pool de mídias em que os backups / arquivos são gravados continuamente. Para conjuntos GFS, os conjuntos de mídias também estão vinculados a um intervalo (por exemplo, anual - anualmente), os cassetes giram apenas dentro do intervalo.
Drive , changer - elementos da biblioteca de fitas. Uma unidade lê e rebobina uma fita; um trocador é um robô que move as fitas entre os slots de armazenamento, descarrega e a unidade. Existem
unidades independentes (independentes - independentes), o papel do trocador aqui é desempenhado por uma pessoa. Para uma unidade, é necessário um driver do fabricante instalado corretamente na máquina Windows em que a biblioteca está conectada; podemos trabalhar com um trocador sem drivers, usando SCSI nativo.
Inquilino para fita. Provedor protegido - clientes protegidos
Imediatamente trunfo na mesa. O recurso mais ambicioso de nossa atualização, projetado para
provedores de nuvem que usam VBR em sua infraestrutura. O desenvolvimento foi iniciado há dois anos. Logo percebemos que não teríamos tempo de lidar com uma tarefa tão séria para o próximo lançamento, fizemos uma breve pausa e finalmente lançamos um recurso na 9.5 Atualização 4.
Em resumo, agora os provedores têm a oportunidade de copiar backups de seus clientes em cassetes usando trabalho de fita no pool GFS. Isso oferece aos provedores - e esses são caras muito grandes, queridos pelo nosso coração e pelo departamento comercial - duas possibilidades:
- proteja seus clientes (inquilinos, inquilinos - inquilinos) da perda de dados como resultado de exclusão acidental ou problemas de infraestrutura ("inundação na sala do servidor");
- forneça aos inquilinos um serviço adicional para restaurar dados de um backup antigo, que há muito tempo foi removido do repositório na nuvem de acordo com a política de armazenamento de dados, mas ainda permanece em fita.
Do ponto de vista do marketing, a funcionalidade é muito "saborosa", da nossa - não menos difícil de implementar.
Desenvolvimento
O principal problema encontrado é a criptografia de dados. A maioria dos backups na nuvem é criptografada, dizem estatísticas sobre ⅔ do total. Para nós, esse número foi uma surpresa, assumiu-se que quase tudo está criptografado, mas não - muitos clientes parecem estar incondicionalmente confiantes em seus fornecedores.
O paradigma é simples: o provedor não deve ser capaz de descriptografar os dados de seus inquilinos. Ao mesmo tempo, como parte do novo recurso, é necessário que o lado do provedor abra o armazenamento com backups. Isso é necessário para transferir blocos de dados, por exemplo, para criar um
backup completo virtual . O principal é fazer isso independentemente do inquilino, quando as chaves necessárias não são transmitidas ao provedor durante a execução do trabalho.
A solução para esse problema, usada, aliás, em outro recurso importante do complemento lançado -
Nível de Capacidade - consiste em adicionar uma chave de criptografia adicional. A chave de arquivamento (chave de arquivamento) é armazenada no banco de dados do provedor em formato criptografado. De acordo com um esquema complicado do lado do provedor, ele pode ser usado para abrir a loja, mover e criptografar novamente os blocos de dados entre as lojas (cada um tem sua própria chave), mas os dados em si não podem ser descriptografados.
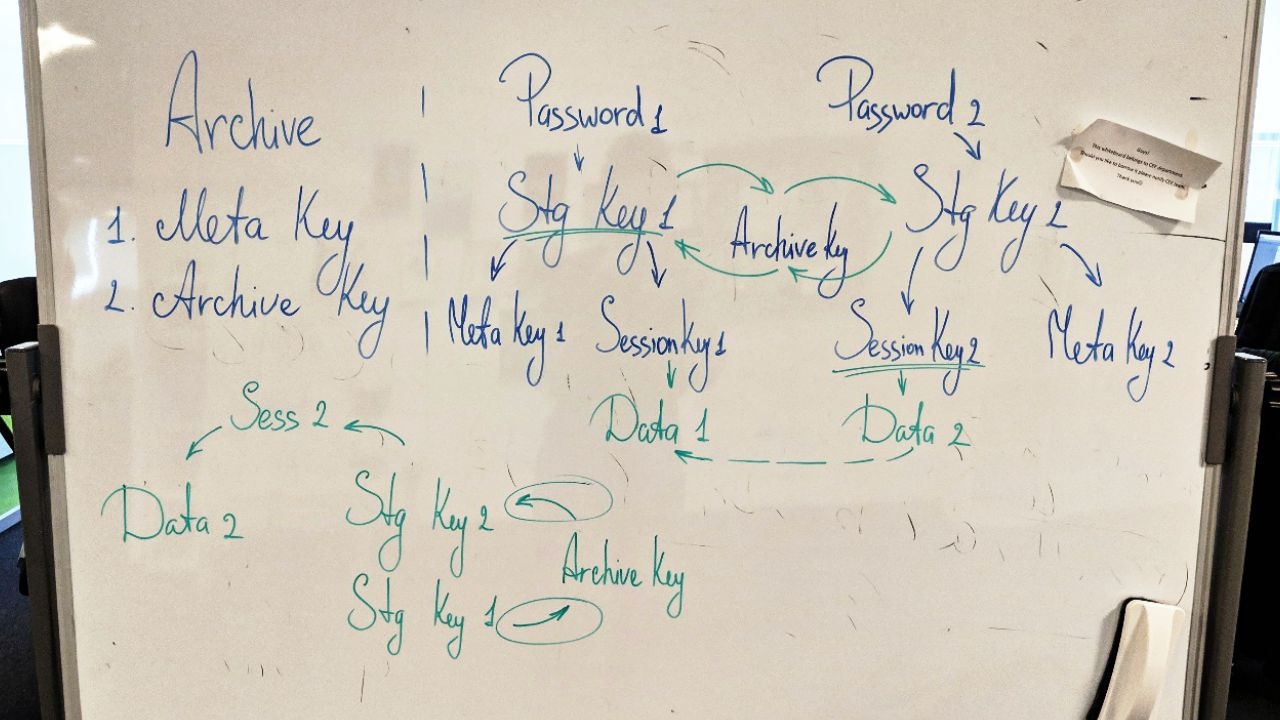 Esquema complicado (versão de trabalho)
Esquema complicado (versão de trabalho)Acrescento que todos os engenheiros de P&D gostam muito de criptografia em nosso produto, no entanto, ninguém sabe em detalhes como ele funciona. (Ainda havia uma piada "e por que funciona", mas os editores não sentiam falta dela.)
Teste
Centenas de bugs foram registrados no recurso. As áreas mais difíceis são criptografia, interface do usuário, problemas com a restauração.
Do ponto de vista dos testes, a grande variabilidade representava a “combinatória” dos tipos e tipos de trabalhos e repositórios de inquilinos - quero dizer a origem e o destino ao restaurar backups na infraestrutura. Tudo isso está ligado à lógica dentro da estrutura do
modelo GFS (incluindo o novo - paralelismo e conjuntos de mídia diários, mais sobre isso abaixo) e, em geral, às especificidades da nuvem que são incomuns para as dicas. Lembre-se de temperar com bastante criptografia. Para continuar a metáfora, comemos muito desse prato - mas também provamos de todos os lados.
 Fragmento do plano de teste
Fragmento do plano de testeComo resultado
Uma descrição detalhada pode ser encontrada no
manual do usuário (até agora em inglês):
backup ,
recuperação . Vou me debruçar sobre os pontos principais.
Backup
O provedor adiciona inquilinos ao trabalho teip com o pool GFS como destino. Se houver uma licença na nuvem na segunda etapa do assistente, a opção
Inquilinos estará disponível. Você pode adicionar todos os inquilinos de uma vez ou separadamente, ou pode escolher apenas uma cota separada (mas não uma subcota) de um inquilino individual. Você não pode misturar backups de inquilino e backups locais regulares no mesmo trabalho.

O restante das tinturas é quase completamente idêntico ao trabalho usual no pool do GFS.
A restauração de dados é possível tanto no lado do provedor quanto no próprio inquilino.
Recuperação do lado do provedor
Realizado através de um novo assistente. Aqui você já pode ir para um trabalho separado, toda a cadeia que estava no repositório em um determinado dia é restaurada.
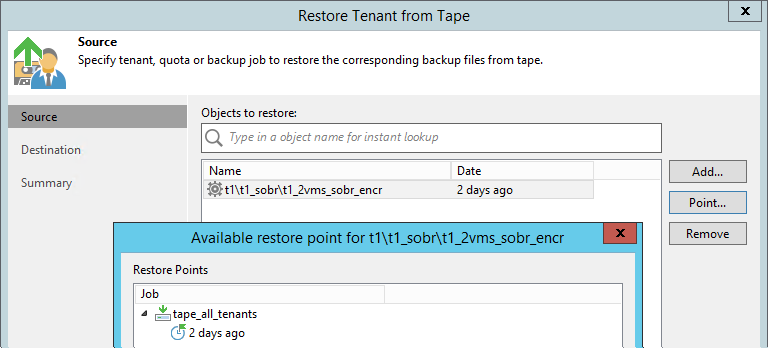
Existem três opções de restaurantes:
- Na localização original. Nesse caso, o backup original, se houver, é excluído; trabalhos de inquilino são reconfigurados automaticamente para a cadeia restaurada. Entende-se que essa restauração será geralmente invisível para o cliente, apenas por um curto período de tempo será desconectada do repositório na nuvem.
- Em uma nova cota / repositório. Um provedor pode, por exemplo, criar uma conta temporária separada para esse fim, que será excluída posteriormente. O backup aparece na infraestrutura do inquilino após a sincronização com o banco de dados do provedor.
- Apenas em uma unidade de servidor Linux ou Windows registrada na infraestrutura do provedor. Além disso, essa cadeia pode ser gravada em uma unidade flash e enviar inquilino.

Recuperação de inquilino
Essa opção implica que o cliente tenha sua própria infraestrutura de serviços e uma grande quantidade de dados para o restaurante. O provedor pode enviar fisicamente a fita com os backups gravados para o cliente pelo serviço de entrega, ele a cataloga em seu equipamento, descriptografa as fitas e os backups e trabalha com os backups como se ele mesmo os tivesse gravado em fita. Aqui está um truque para não baixar terabytes na WAN.
Melhorias em larga escala no pool GFS
Os pools de mídias
GFS apareceram no VBR há dois anos, na versão 9.5. Na atualização mais recente, tanto em relação à aparência do recurso Inquilino para fita, quanto a pedido dos usuários, aprimoramos bem essa funcionalidade.
Conjuntos diários de mídia
Um novo conjunto
diário de mídia apareceu. Agora, no pool do GFS, você pode armazenar backups todos os dias e não apenas concluir, mas também incrementalmente. Estes últimos ocupam significativamente menos espaço, e isso foi feito para economizar fita. Entende-se que esses cassetes são rotacionados constantemente na biblioteca, não transportados para armazenamento remoto. Ao mesmo tempo, para um restaurante a partir de um ponto incremental, você precisará das fitas de um dos principais meios de comunicação (semanal, mensal, trimestral ou anual). É impossível ativar a mídia diária definida sem incluir a semanal, para que na maioria dos casos sejam necessários cassetes semanais para restaurar a partir de uma cópia incremental. Eles estão sempre na biblioteca ou são armazenados em um armazém não tão remoto.

A lógica para trabalhar com trabalhos de fita no pool de mídia GFS
não é
a mais fácil , os escritores técnicos não permitem mentir. Se, em poucas palavras, omitir os detalhes, apenas os backups completos (incluindo backups virtuais completos) são copiados para os conjuntos de mídias semanais e sênior, um para cada data, e para o backup diário todos os backups que estão no repositório do dia atual, porque o backup -O trabalho pode começar mais de uma vez por dia.
Simultaneidade, hora de início e espera nos pools de GFS
Agora, a gravação paralela de várias cadeias ou o trabalho em várias unidades de biblioteca também é possível em pools de mídia GFS (anteriormente - apenas em comum). Ele está incluído na etapa
Opções do pool de mídias.
 Um esclarecimento importante
Um esclarecimento importante : o mesmo arquivo é sempre gravado no mesmo fluxo; portanto, no caso de várias máquinas virtuais grandes, é recomendável ativar
a configuração por VM no repositório para que o backup consista em várias cadeias.
Além disso, tornou-se possível escolher
o horário de início do trabalho do GFS . Muitos usuários não gostaram de começar à meia-noite e esperar quase o dia inteiro até o término do trabalho de fornecimento. Agora, esse horário pode ser definido, por exemplo, no final da noite, quando já existe algo para copiar em fita. Além disso, a pedido dos usuários, colocamos nas configurações avançadas uma opção que anteriormente só podia ser ativada com a chave do registro. Basta selecionar
Processar o ponto de restauração mais recente em vez de esperar - e o que está no repositório no momento do início do trabalho de fita (o ponto de ontem, por exemplo) é copiado para a fita, não há nenhuma espera.
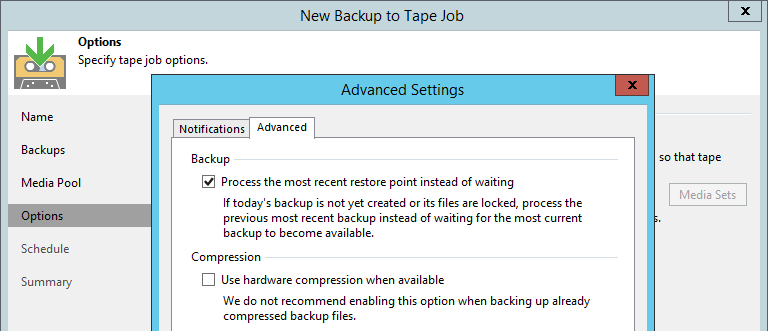
Trabalho aprimorado com várias bibliotecas
Será sobre a situação em que mais de uma biblioteca é adicionada a um pool de mídias. Nós já apoiamos isso antes, mas, de tempos em tempos, os clientes vinham com queixas sobre comportamentos não muito previsíveis.
Was
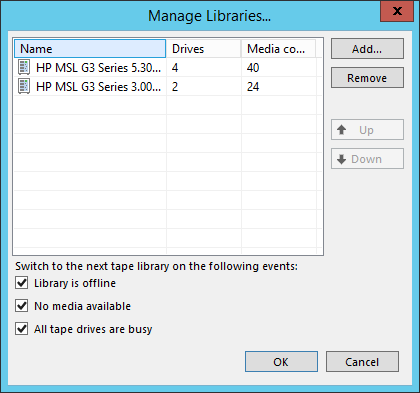
Por exemplo, o trabalho de fita foi iniciado, foram necessárias duas unidades na primeira biblioteca, mas as configurações de simultaneidade permitem o uso de 4 unidades ao mesmo tempo. Esse trabalho deve mudar para a segunda biblioteca do pool de mídias e usá-lo também, ou será um desperdício de recursos?
Outro caso. Foi selecionada uma opção para alternar pela condição “não há cassetes disponíveis”; na primeira biblioteca, há apenas um cassete, mas todos os dados são potencialmente colocados nele. No entanto, as configurações permitem escrever em paralelo em duas fitas. A segunda biblioteca deve estar envolvida neste caso?
Decidimos colocar essa área em ordem, possibilitando a personalização explícita do comportamento.
Tornou-se
 As bibliotecas no pool de mídias
As bibliotecas no pool de mídias pareciam funções -
ativas e
passivas . E o próprio pool de mídias possui dois modos: à prova de falhas ou failover e
paralelo . Agora, dependendo dos requisitos, você pode configurar o pool de mídias de maneiras diferentes.
- Se você possui várias bibliotecas de pares e precisa paralelizar a gravação, ative o modo de gravação paralela, para que todas as bibliotecas precisem receber funções ativas. Nesse caso, as novas fitas e unidades serão ativadas imediatamente, assim que surgir a necessidade, independentemente da biblioteca em que estejam. Ainda há prioridade - primeiro, tentaremos encontrar recursos na biblioteca localizada mais acima na lista.
- Se houver uma biblioteca principal e uma unidade antiga ou autônoma em reserva, ative o modo feylover colocando a biblioteca principal no topo da lista e escolhendo uma função passiva para dispositivos de backup. A mudança para esse dispositivo ocorrerá somente quando for realmente necessário que o trabalho funcione pelo menos de alguma forma. Essa situação será considerada anormal, a qual receberá uma notificação por correio.
Há uma situação mais complicada que ainda não suportamos - várias bibliotecas ativas com passivas. O feedback mostrará se há necessidade de tais configurações e se é necessário "concluir" o recurso no futuro. Prática padrão.
Suporte WORM
WORM - Write Once Read Many - fitas que não podem ser apagadas ou sobrescritas
no nível do ferro só podem acrescentar dados. Seu uso obrigatório é regulado pelas regras de algumas organizações, por exemplo, aquelas que trabalham no campo da medicina. O principal problema com essas fitas antes era que o VBR durante o
inventário ou a
catalogação registrava um cabeçalho que não podia mais ser apagado no futuro, e os trabalhos de fita caíam com um erro durante essa tentativa.
Na atualização 9.5 9, o suporte completo para essas fitas é implementado. Adicionados pools de mídia WORM, regulares e GFS, onde você pode colocar apenas fitas desse tipo.
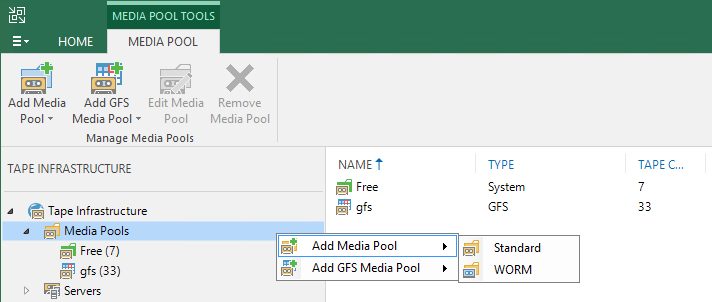
As cassetes novas têm um ícone azul "congelado". Do ponto de vista do usuário, trabalhar com cassetes WORM não é diferente de trabalhar com cassetes comuns.
A "alimentação" dos cassetes é determinada inicialmente pelo sufixo do
código de barras ; se o código de barras neles for regular ou ilegível, a unidade fornecerá informações quando o cartucho for inserido pela primeira vez. Coloque as fitas WORM em um pool de mídia comum e grave nelas não funcionará. Do engraçado: já havia usuários que colavam códigos de barras WORM em cassetes comuns e ficaram surpresos com as mudanças em sua infraestrutura após a atualização.
Chip de cartucho
Juntamente com a introdução de cassetes não regraváveis, eles começaram a trabalhar com o
chip . Nós não usamos atributos padrão no chip antes, agora escrevemos e lemos alguns deles, mas não os percebemos como a principal fonte de dados. A principal diretriz ainda é o título da fita. Essa decisão ficou correta: após um mês após o lançamento, vemos como o "zoológico" do ferro do usuário traz surpresas em termos de trabalho com o chip.
Backup em fita de volumes NDMP
Concluindo, sobre o recurso mais solicitado pelo número de comentários desta atualização. O backup dos volumes NDMP para fitas ficou disponível. É necessário
adicionar um servidor NDMP à infraestrutura VBR, após o qual será possível selecionar volumes desse host no trabalho de arquivo. Eles caem no cassete na forma de arquivos com um atributo especial para distingui-los da catalogação usual.
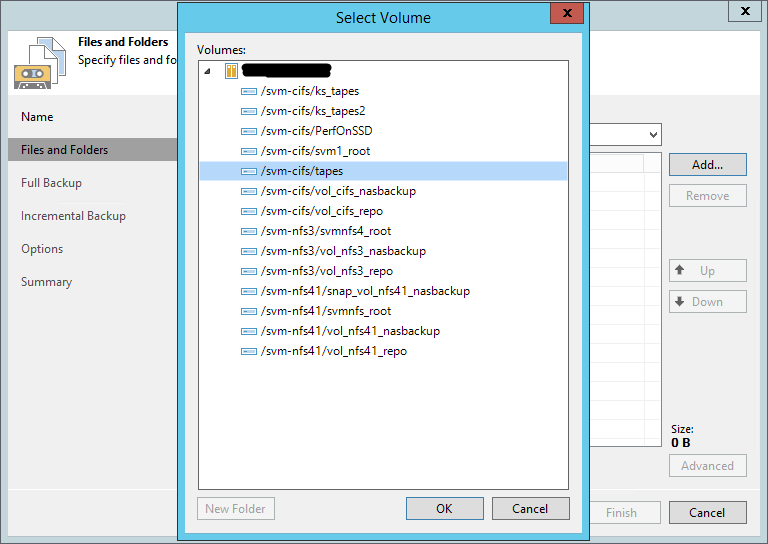
Na primeira implementação, existem algumas limitações: extensões não são suportadas, além de backup e restauração de apenas o volume completo, mas não de arquivos individuais, é possível. O backup funciona através do
dump (no caso da NetApp -
ufsdump ), existem algumas peculiaridades: o número máximo de pontos incrementais é 9, após o qual um backup completo é forçado.
Em conclusão
VBR 9.5 Update 4. :
- - -;
- Tape Operator ( , – Restore Operator);
- include/exclude- - ( NDMP);
- - ( , , , - – , );
- ;
- , , / , ;
- .
Links úteis
: