As redes neurais convolucionais fazem um excelente trabalho ao classificar imagens distorcidas, diferentemente dos humanos.

Neste artigo, mostrarei por que redes neurais profundas avançadas podem reconhecer perfeitamente imagens distorcidas e como isso ajuda a revelar a estratégia surpreendentemente simples usada por redes neurais para classificar fotografias naturais. Essas descobertas,
publicadas no ICLR 2019, têm muitas consequências: em primeiro lugar, demonstram que é muito mais fácil encontrar uma solução “
ImageNet ” do que se pensava. Em segundo lugar, eles nos ajudam a criar sistemas de classificação de imagem mais interpretáveis e compreensíveis. Em terceiro lugar, eles explicam vários fenômenos observados nas redes neurais convolucionais modernas (SNA), por exemplo, sua tendência a procurar texturas (veja nosso outro
trabalho no ICLR 2019 e a
entrada de blog correspondente) e ignorando o arranjo espacial de partes do objeto.
Bons velhos modelos "saco de palavras"
Nos bons velhos tempos, antes do advento do aprendizado profundo, o reconhecimento de imagens naturais era bastante simples: definimos um conjunto de recursos visuais principais (“palavras”), determinamos com que frequência cada recurso visual ocorre em uma imagem (“bolsa”) e classificamos a imagem com base nelas. números. Portanto, esses modelos em visão computacional são chamados de "saco de palavras" (saco de palavras ou BoW). Por exemplo, suponha que tenhamos duas características visuais, o olho humano e a caneta, e desejemos classificar as imagens em duas classes, "pessoas" e "pássaros". O modelo mais simples de BoW seria este: para cada olho encontrado na imagem, aumentamos o testemunho em favor da "pessoa" em 1. E vice-versa, para cada caneta aumentamos o testemunho em favor do "pássaro" em 1. Qual classe obtém mais evidências, será essa.
Uma propriedade conveniente de um modelo de BoW tão simples é a interpretabilidade e a clareza do processo de tomada de decisão: podemos verificar com precisão quais recursos específicos da imagem falam em favor de uma classe específica, a integração espacial de recursos é muito simples (em comparação com a integração não linear de recursos em redes neurais profundas), portanto apenas entenda como o modelo toma suas decisões.
Os modelos tradicionais de BoW eram extremamente populares e funcionavam muito bem antes da invasão do aprendizado profundo, mas rapidamente saíram de moda devido à eficiência relativamente baixa. Mas temos certeza de que as redes neurais usam uma estratégia de decisão fundamentalmente diferente da BoW?
Rede Interpretada em Profundidade com Recursos de Bolsa (BagNet)
Para testar essa suposição, combinamos a interpretabilidade e a clareza dos modelos de BoW com a eficiência das redes neurais. A estratégia é assim:
- Divida a imagem em pedaços pequenos qx q.
- Passamos as peças pela rede neural para obter evidências de associação de classe (logits) para cada peça.
- Resuma as evidências em todas as peças para obter uma solução no nível de toda a imagem.
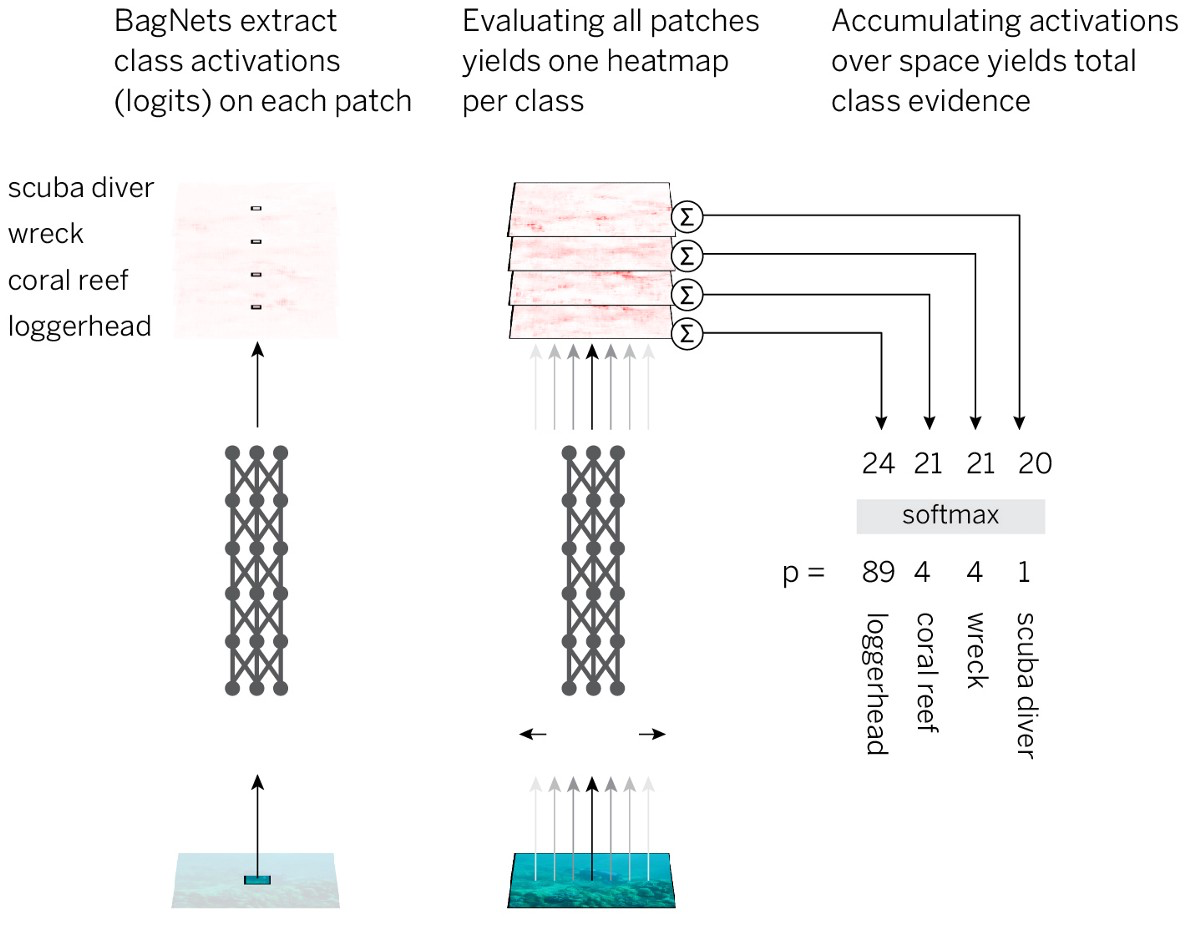
Para implementar essa estratégia, da maneira mais simples, adotamos a arquitetura padrão ResNet-50 e substituímos quase todas as convoluções 3x3 por convoluções 1x1. Como resultado, cada elemento oculto na última camada convolucional "vê" apenas uma pequena parte da imagem (ou seja, seu campo de percepção é muito menor que o tamanho da imagem). Portanto, evitamos a marcação imposta da imagem e o mais próximo possível do SNA padrão, enquanto aplicamos uma estratégia pré-planejada. Chamamos a arquitetura resultante BagNet-q, em que q denota o tamanho do campo de percepção da camada superior (testamos o modelo com q = 9, 17 e 33). O BagNet-q roda cerca de 2,5 a mais que o ResNet-50.
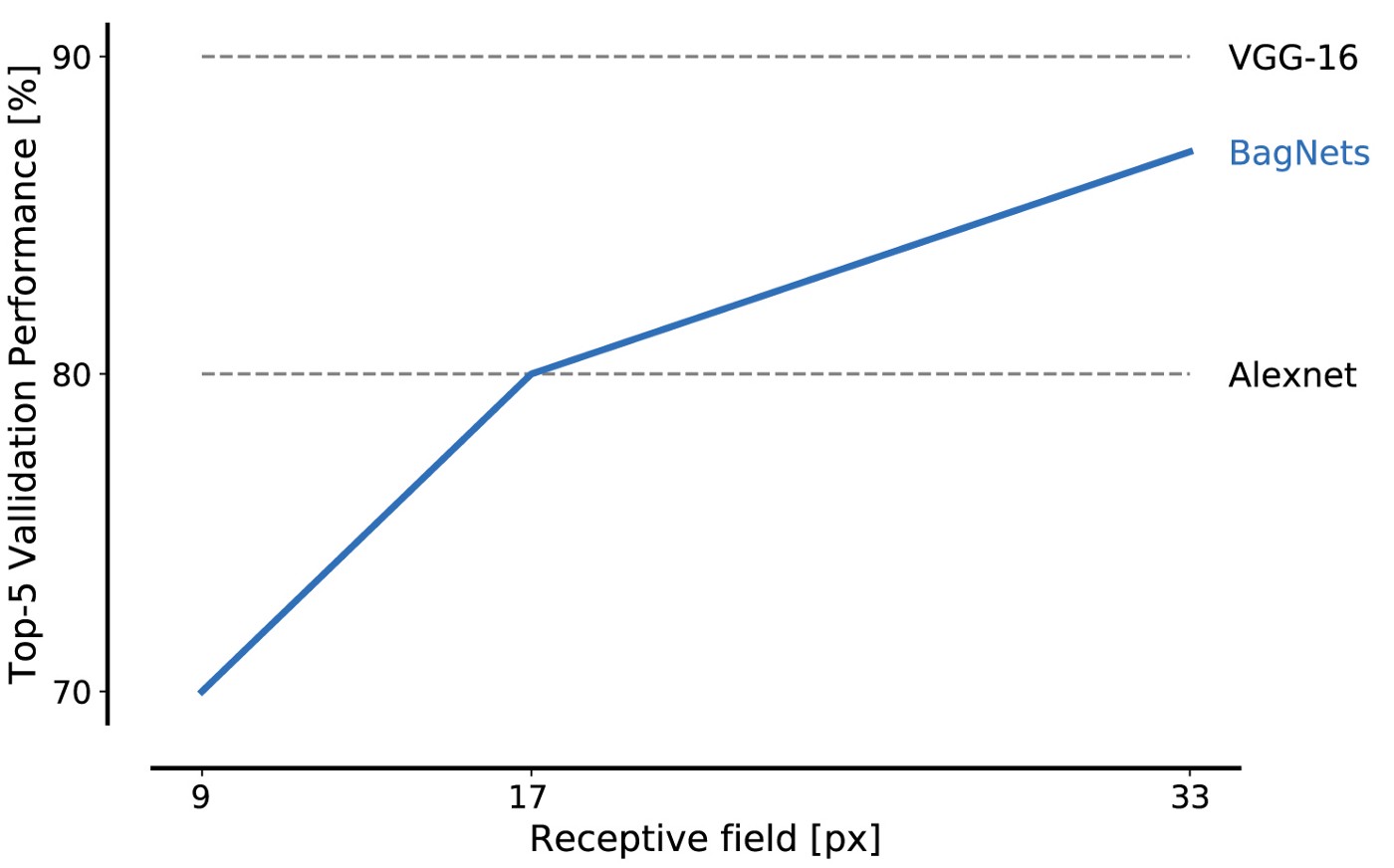
O desempenho da BagNet em dados do banco de dados ImageNet é impressionante, mesmo quando se usa pedaços pequenos: fragmentos de 17x17 pixels são suficientes para atingir a eficiência do nível AlexNet, e fragmentos de 33x33 pixels são suficientes para atingir 87% de precisão, entrando no top 5. Você pode aumentar a eficiência colocando os pacotes 3x3 com mais cuidado e ajustando os hiperparâmetros.
Este é o nosso primeiro grande resultado: o ImageNet pode ser resolvido usando apenas um conjunto de pequenos recursos de imagem. As relações espaciais distantes das partes da composição, como a forma dos objetos ou a interação entre partes do objeto, podem ser completamente ignoradas; eles não são absolutamente necessários para resolver o problema.
Uma característica notável do BagNet'ov é a transparência do seu sistema de tomada de decisão. Por exemplo, você pode descobrir quais recursos das imagens serão mais característicos para uma determinada classe. Por exemplo, tenca, um peixe grande, é geralmente reconhecida pela imagem dos dedos em um fundo verde. Porque Porque na maioria das fotos desta categoria, há um pescador segurando uma tenca como seu troféu. E quando o BagNet reconhece incorretamente a imagem como uma linha, isso geralmente acontece porque em algum lugar da foto há dedos em um fundo verde.
 As partes mais características das imagens. A linha superior em cada célula corresponde ao reconhecimento correto e a parte inferior aos fragmentos que causam distração que levaram ao reconhecimento incorreto
As partes mais características das imagens. A linha superior em cada célula corresponde ao reconhecimento correto e a parte inferior aos fragmentos que causam distração que levaram ao reconhecimento incorretoTambém obtemos o "mapa de calor" exato, que mostra quais partes da imagem contribuíram para a decisão.
 Os mapas de calor não são uma aproximação; eles mostram com precisão a contribuição de cada parte da imagem.
Os mapas de calor não são uma aproximação; eles mostram com precisão a contribuição de cada parte da imagem.Os BagNet demonstram que você pode obter alta precisão com o ImageNet apenas com base em correlações estatísticas fracas entre os recursos locais das imagens e a categoria de objetos. Se isso é suficiente, por que as redes neurais padrão ResNet-50 aprendem algo fundamentalmente diferente? Por que o ResNet-50 deveria estudar relações complexas de larga escala, como a forma de um objeto, se a abundância de recursos locais da imagem é suficiente para resolver o problema?
Para testar a hipótese de que os SNAs modernos aderem a uma estratégia semelhante à operação das redes BoW mais simples, testamos redes diferentes - ResNet, DenseNet e VGG nos seguintes "sinais" do BagNet:
- As soluções são independentes do embaralhamento espacial dos recursos da imagem (isso só pode ser verificado nos modelos VGG).
- Modificações de diferentes partes da imagem não devem depender umas das outras (no sentido de sua influência na participação na classe).
- Os erros cometidos pelo SNA padrão e pelo BagNet'ami devem ser semelhantes.
- O SNS padrão e o BagNet devem ser sensíveis a recursos semelhantes.
Nas quatro experiências, descobrimos comportamentos surpreendentemente semelhantes do SNS e da BagNet. Por exemplo, no último experimento, mostramos que o BagNet é mais sensível (se, por exemplo, eles se sobrepõem) aos mesmos lugares nas imagens que o SNA. De fato, os mapas de calor BagNet (mapas de sensibilidade espacial) preveem melhor a sensibilidade do DenseNet-169 do que os mapas de calor obtidos por métodos de atribuição como o DeepLift (cálculo direto dos mapas de calor para o DenseNet-169). Obviamente, o SNA não repete exatamente o comportamento do BagNet, mas certos desvios demonstram. Em particular, quanto mais profundas as redes se tornam, maiores os tamanhos dos recursos e mais ampliadas as dependências. Portanto, redes neurais profundas são de fato uma melhoria em relação aos modelos BagNet, mas não acho que a base de sua classificação esteja de alguma forma mudando.
Indo além da classificação BoW
Observar a tomada de decisão do SNA no estilo das estratégias de BoW pode explicar algumas das características estranhas do SNA. Em primeiro lugar, isso explica por que o SNA está tão
ligado às texturas . Em segundo lugar, por que o SNA não é sensível à
mistura de partes da imagem. Isso pode até explicar a existência de adesivos contraditórios e distúrbios contraditórios: sinais confusos podem ser colocados em qualquer lugar da imagem, e o SNS certamente captará esse sinal, independentemente de ele se encaixar no restante da imagem.
De fato, nosso trabalho mostra que o SNA, ao reconhecer imagens, usa muitas leis estatísticas fracas e não procede à integração de partes da imagem no nível dos objetos, como as pessoas fazem. O mesmo é provavelmente verdadeiro para outras tarefas e modalidades sensoriais.
Precisamos planejar cuidadosamente nossas arquiteturas, tarefas e métodos de treinamento para superar a tendência de usar correlações estatísticas fracas. Uma abordagem é traduzir a distorção do treinamento de SNA de pequenos recursos locais para outros mais globais. Outra é remover ou substituir os recursos nos quais a rede neural não deve confiar, o que fizemos em outra
publicação para o ICLR 2019, usando o pré-processamento de transferência de estilo para eliminar a textura de um objeto natural.
Um dos maiores problemas, no entanto, continua sendo a classificação das imagens: se as características locais são suficientes, não há incentivo para estudar a verdadeira "física" do mundo natural. Precisamos reestruturar a tarefa de maneira a mover modelos para estudar a natureza física dos objetos. Para fazer isso, muito provavelmente, você terá que ir além do ensino puramente observacional até as correlações dos dados de entrada e saída, para que os modelos possam extrair relacionamentos causais.
Juntos, nossos resultados sugerem que o SNA pode seguir uma estratégia de classificação extremamente simples. O fato de que tal descoberta possa ser feita em 2019 enfatiza o quão pouco ainda entendemos os recursos internos do trabalho de redes neurais profundas. A falta de entendimento não nos permite desenvolver modelos e arquiteturas fundamentalmente aprimorados que preenchem a lacuna entre a percepção do homem e da máquina. Aprofundar nossa compreensão nos permitirá descobrir maneiras de diminuir essa lacuna. Isso pode ser extremamente útil: tentando mudar o SNA para as propriedades físicas dos objetos, de repente alcançamos
resistência ao ruído no nível humano. Espero o aparecimento de um grande número de outros resultados interessantes em nosso caminho para o desenvolvimento do SNA, que realmente compreendem a natureza física e causal do nosso mundo.