 Postado por Denis Tsyplakov , arquiteto de soluções, DataArt
Postado por Denis Tsyplakov , arquiteto de soluções, DataArtAo longo dos anos, descobri que os programadores repetem os mesmos erros de tempos em tempos. Infelizmente, livros sobre aspectos teóricos do desenvolvimento não ajudam a evitá-los: os livros geralmente não têm conselhos práticos e concretos. E até acho que por que ...
A primeira recomendação que vem à mente quando se trata, por exemplo, de
log ou design de classe é muito simples: "Não faça besteira direta". Mas a experiência mostra que definitivamente não é suficiente. Apenas o design das classes, neste caso, é um bom exemplo - uma dor de cabeça eterna que surge do fato de todos olharem para esse problema à sua maneira. Portanto, decidi reunir dicas básicas em um artigo, após o qual você evitará vários problemas típicos e, o mais importante, salve seus colegas deles. Se alguns princípios lhe parecem banais (porque são realmente banais!) - bem, eles já se estabeleceram no seu subcórtex e sua equipe pode ser parabenizada.
Farei uma reserva, na verdade, focaremos nas aulas apenas por simplicidade. Quase o mesmo pode ser dito sobre as funções ou qualquer outro componente do aplicativo.
Se o aplicativo funcionar e executar a tarefa, seu design será bom. Ou não? Depende da função objetivo do aplicativo; o que é bastante adequado para um aplicativo móvel que precisa ser exibido uma vez na exposição pode não ser adequado para a plataforma de negociação que qualquer banco vem desenvolvendo há anos. Até certo ponto, a resposta a essa pergunta pode ser chamada de princípio do
SOLID , mas é muito geral - quero instruções mais específicas que possam ser mencionadas em uma conversa com colegas.
Aplicativo de destino
Como não pode haver resposta universal, proponho restringir o escopo. Vamos supor que estamos escrevendo um aplicativo de negócios padrão que aceita solicitações via HTTP ou outra interface, implementa alguma lógica acima delas e, em seguida, faz uma solicitação para o próximo serviço da cadeia ou armazena os dados recebidos em algum lugar. Por uma questão de simplicidade, vamos supor que estamos usando o Spring IoC Framework, pois ele é bastante comum agora e o restante dos frameworks é bastante semelhante a ele. O que podemos dizer sobre esse aplicativo?
- O tempo que o processador gasta processando uma solicitação é importante, mas não crítico - um aumento de 0,1% no clima não.
- Não há terabytes de memória à nossa disposição, mas se o aplicativo consumir 50 a 100 Kbytes extras, isso não será um desastre.
- Obviamente, quanto menor a hora de início, melhor. Mas não há diferença fundamental entre 6 e 5,9 segundos.
Critérios de otimização
O que é importante para nós neste caso?
É provável que o código do projeto seja usado pela empresa por vários, talvez mais de dez anos.
O código em momentos diferentes será modificado por vários desenvolvedores não familiarizados.
É possível que em alguns anos os desenvolvedores desejem usar a nova biblioteca LibXYZ ou a estrutura FrABC.
Em algum momento, parte do código ou o projeto inteiro pode ser mesclado com a base de código de outro projeto.
No meio dos gerentes, geralmente é aceito que esses problemas sejam resolvidos com a ajuda da documentação. A documentação, é claro, é boa e útil, porque é tão boa quando você começa a trabalhar no projeto que tem cinco tickets abertos pendurados, o gerente do projeto pergunta como você progrediu e você precisa ler (e lembrar) cerca de 150 páginas de texto escritas longe de escritores brilhantes. Obviamente, você teve alguns dias ou até algumas semanas para entrar no projeto, mas, se você usar aritmética simples, por um lado, 5.000.000 bytes de código, por outro, digamos, 50 horas de trabalho. Acontece que, em média, era necessário injetar 100 Kb de código por hora. E aqui tudo depende muito da qualidade do código. Se estiver limpo: fácil de montar, bem estruturado e previsível, a participação em um projeto parece ser um processo notavelmente menos doloroso. Nem o último papel nisso é desempenhado pelo design da classe. Não é o último.
O que queremos do design de classe
De todas as alternativas acima, muitas conclusões interessantes podem ser tiradas sobre a arquitetura geral, a pilha de tecnologias, o processo de desenvolvimento etc. Mas, desde o início, decidimos falar sobre o design de classes, vamos ver as coisas úteis que podemos aprender com o que foi dito anteriormente em relação a ele.
- Eu gostaria que um desenvolvedor que não estivesse totalmente familiarizado com o código do aplicativo pudesse entender o que esta classe está fazendo ao olhar para uma classe. E vice-versa - olhando para um requisito funcional ou não-funcional, eu poderia adivinhar rapidamente onde o aplicativo está localizado nas classes responsáveis por ele. Bem, é desejável que a implementação dos requisitos não seja "espalhada" por todo o aplicativo, mas concentrada em uma classe ou em um grupo compacto de classes. Deixe-me explicar com um exemplo que tipo de antipadrão eu quero dizer. Suponha que precisamos verificar se 10 solicitações de um determinado tipo só podem ser executadas por usuários que possuem mais de 20 pontos em sua conta (não importa o que isso signifique). Uma maneira ruim de implementar esse requisito é inserir uma verificação no início de cada solicitação. Em seguida, a lógica será espalhada por 10 métodos, em diferentes controladores. Uma boa maneira é criar um filtro ou WebRequestInterceptor e verificar tudo em um só lugar.
- Quero que as mudanças em uma classe que não afetem o contrato da classe não afetem, bem, ou (sejamos realistas!) Pelo menos não afetem muito outras classes. Em outras palavras, quero encapsular a implementação de um contrato de classe.
- Eu gostaria que fosse possível, ao alterar o contrato de classe, percorrendo a cadeia de chamadas e fazendo usos de encontrar, encontre as classes que essa alteração afeta. Ou seja, quero que as classes não tenham dependências indiretas.
- Se possível, gostaria de ver que os processos de processamento de solicitação que consistem em várias etapas de nível único não são manchados pelo código de várias classes, mas são descritos no mesmo nível. É muito bom se o código que descreve esse processo de processamento se encaixa em uma tela dentro de um método com um nome claro. Por exemplo, precisamos encontrar todas as palavras em uma linha, fazer uma chamada para um serviço de terceiros para cada palavra, obter uma descrição da palavra, aplicar formatação à descrição e salvar os resultados no banco de dados. Esta é uma sequência de ações em 4 etapas. É muito conveniente entender o código e alterar sua lógica quando houver um método em que essas etapas sigam uma após a outra.
- Eu realmente quero que as mesmas coisas no código sejam implementadas da mesma maneira. Por exemplo, se acessarmos o banco de dados imediatamente a partir do controlador, é melhor fazer isso em qualquer lugar (embora eu não chamaria essa prática de bom design). E se já inserimos os níveis de serviços e repositórios, é melhor não entrar em contato com o banco de dados diretamente do controlador.
- Eu gostaria que o número de classes / interfaces não diretamente responsáveis por requisitos funcionais e não funcionais não fosse muito grande. Trabalhar com um projeto no qual existem duas interfaces para cada classe com lógica, uma hierarquia complexa de herança de cinco classes, uma fábrica de classes e uma fábrica de classes abstrata, é bastante difícil.
Recomendações práticas
Tendo formulado desejos, podemos delinear etapas específicas que nos permitirão alcançar nossos objetivos.
Métodos estáticos
Como aquecimento, começarei com uma regra relativamente simples. Você não deve criar métodos estáticos, a menos que sejam necessários para a operação de uma das bibliotecas usadas (por exemplo, você precisa criar um serializador para um tipo de dados).
Em princípio, não há nada de errado em usar métodos estáticos. Se o comportamento de um método depende inteiramente de seus parâmetros, por que não torná-lo realmente estático. Mas você precisa levar em conta o fato de que usamos o Spring IoC, que serve para vincular os componentes de nosso aplicativo. O Spring IoC lida com os conceitos de beans (Beans) e seu escopo (Scope). Essa abordagem pode ser combinada com métodos estáticos agrupados em classes, mas entender uma aplicação e até alterar algo nela (se, por exemplo, você precisar passar algum parâmetro global para um método ou classe) pode ser muito difícil.
Ao mesmo tempo, métodos estáticos em comparação com os compartimentos de IoC oferecem uma vantagem muito insignificante na velocidade de invocação do método. E nisso, talvez, as vantagens terminem.
Se você não estiver criando uma função comercial que exija um grande número de chamadas ultra-rápidas entre diferentes classes, é melhor não usar métodos estáticos.
Aqui o leitor pode perguntar: "Mas e as classes StringUtils e IOUtils?" De fato, uma tradição se desenvolveu no mundo Java - para colocar funções auxiliares para trabalhar com strings e fluxos de entrada e saída em métodos estáticos e coletá-los sob o guarda-chuva das classes SomethingUtils. Mas essa tradição me parece bastante musgosa. Se você segui-lo, é claro, não se espera grandes danos - todos os programadores Java estão acostumados. Mas não há sentido em tal ação ritual. Por um lado, por que não tornar o bean StringUtils, por outro lado, se você não tornar o bean e todos os métodos auxiliares estáticos, vamos tornar as classes guarda-chuva estáticas StockTradingUtils e BlockChainUtils. Começando a colocar a lógica em métodos estáticos, é difícil desenhar uma borda e parar. Eu aconselho você a não começar.
Por fim, não esqueça que, pelo Java 11, muitos dos métodos auxiliares que vinham vagando pelos desenvolvedores de projeto em projeto por décadas, tornaram-se parte da biblioteca padrão ou mesclados em bibliotecas, por exemplo, no Google Guava.
Contrato de classe atômica e compacta
Existe uma regra simples que se aplica ao desenvolvimento de qualquer sistema de software. Olhando para qualquer classe, você deve ser capaz de explicar de forma rápida e compacta, sem recorrer a escavações longas, o que essa classe faz. Se for impossível encaixar a explicação em um parágrafo (não é necessário, no entanto, expresso em uma frase), pode valer a pena pensar e dividir essa classe em várias classes atômicas. Por exemplo, a classe “Procura arquivos de texto em um disco e conta o número de letras Z em cada um deles” - um bom candidato para a decomposição “procura em um disco” + “conta o número de letras”.
Por outro lado, não faça classes muito pequenas, cada uma delas projetada para uma ação. Mas qual o tamanho da classe então? As regras básicas são as seguintes:
- Idealmente, quando o contrato de classe corresponde à descrição da função comercial (ou subfunção, dependendo de como os requisitos são organizados). Isso nem sempre é possível: se uma tentativa de cumprir essa regra levar à criação de um código complicado e não óbvio, é melhor dividir a classe em partes menores.
- Uma boa métrica para avaliar a qualidade de um contrato de classe é a razão entre sua complexidade intrínseca e a complexidade do contrato. Por exemplo, um contrato de classe muito bom (embora fantástico) pode ser assim: "A classe tem um método que recebe uma linha com uma descrição do assunto em russo na entrada e compõe uma história de qualidade ou até mesmo uma história sobre um determinado tópico". Aqui, o contrato é simples e geralmente entendido. Sua implementação é extremamente complexa, mas a complexidade está oculta dentro da classe.
Por que essa regra é importante?
- Em primeiro lugar, a capacidade de explicar claramente a si mesmo o que cada uma das classes faz é sempre útil. Infelizmente, longe de todos os desenvolvedores de projetos, isso é possível. Você pode ouvir algo do tipo: “Bem, esse é um invólucro da classe Path, que de alguma forma criamos e às vezes usamos em vez de Path. Ela também possui um método que pode duplicar todos os caminhos do File.separator - precisamos desse método ao salvar relatórios na nuvem e, por algum motivo, ele acabou na classe Path. "
- O cérebro humano é capaz de operar simultaneamente com não mais que cinco a dez objetos. A maioria das pessoas não tem mais que sete. Portanto, se um desenvolvedor precisar operar com mais de sete objetos para resolver um problema, ele perderá algo ou será forçado a embalar vários objetos em um "guarda-chuva" lógico. E se você ainda precisa empacotá-lo, por que não fazê-lo imediatamente, conscientemente, e dê a esse guarda-chuva um nome significativo e um contrato claro.
Como verificar se tudo é granular o suficiente? Peça a um colega que lhe dê 5 (cinco) minutos. Faça parte do aplicativo que você está trabalhando atualmente para criar. Para cada aula, explique a um colega o que exatamente essa aula faz. Se você não se encaixa em 5 minutos ou um colega não consegue entender por que essa ou aquela aula é necessária, talvez você deva mudar alguma coisa. Bem, ou não, para mudar e conduzir o experimento novamente, com outro colega.
Dependências de classe
Suponha que precisamos selecionar seções de texto vinculadas com mais de 100 bytes para um arquivo PDF compactado em um arquivo ZIP e salvá-las no banco de dados. Um antipadrão popular nesses casos é assim:
- Existe uma classe que abre um arquivo ZIP, procura um arquivo PDF e o retorna como um InputStream.
- Esta classe possui um link para uma classe que pesquisa em parágrafos de texto em PDF.
- A classe que trabalha com PDF, por sua vez, possui um link para a classe que armazena dados no banco de dados.
Por um lado, tudo parece lógico: dados recebidos, chamados diretamente a próxima classe da cadeia. Mas, ao mesmo tempo, os contratos da classe no topo da cadeia se misturam nos contratos e dependências de todas as classes que estão na cadeia por trás dela. É muito mais correto tornar essas classes atômicas e independentes uma da outra e criar outra classe que realmente implemente a lógica de processamento, conectando essas três classes uma à outra.
Como não fazer: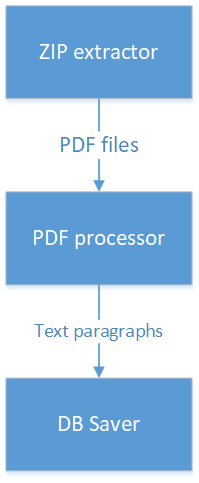
O que há de errado aqui? A classe que trabalha com arquivos ZIP passa os dados para a classe que processa o PDF e, por sua vez, os dados para a classe que trabalha com o banco de dados. Isso significa que a classe que trabalha com ZIP, como resultado, por algum motivo depende das classes que trabalham com o banco de dados. Além disso, a lógica de processamento está espalhada por três classes e, para entendê-la, precisamos passar por todas as três classes. E se você precisar que parágrafos de texto obtidos em PDF sejam transferidos para um serviço de terceiros por meio de uma chamada REST? Você precisará alterar a classe que trabalha com PDF e desenhar nela também funciona com REST.
Como fazer: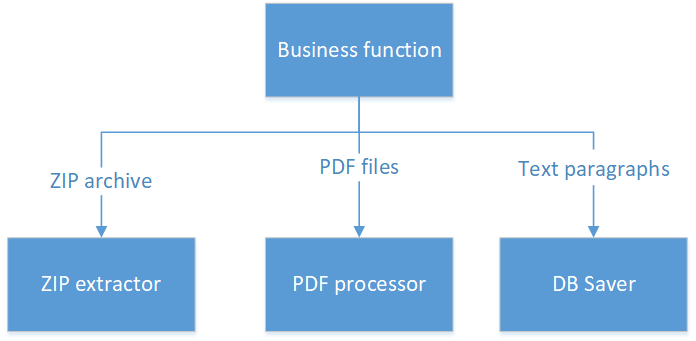
Aqui temos quatro classes:
- Uma classe que funciona apenas com um arquivo ZIP e retorna uma lista de arquivos PDF (pode-se argumentar - retornar arquivos ruins - eles são grandes e quebram o aplicativo. Mas, neste caso, vamos ler a palavra "retorna" em um sentido amplo. Por exemplo, retorna Stream from InputStream )
- A segunda classe é responsável por trabalhar com PDF.
- A terceira classe não sabe e não pode fazer nada, exceto salvar parágrafos no banco de dados.
- E a quarta classe, que consiste literalmente em várias linhas de código, contém toda a lógica de negócios que cabe em uma tela.
Enfatizo mais uma vez que em 2019 em Java há pelo menos duas boas (e um pouco menos
bom) maneiras de não transferir arquivos e uma lista completa de todos os parágrafos como objetos na memória. Isto é:
- API de fluxo Java
- Retornos de chamada Ou seja, uma classe com uma função comercial não transfere dados diretamente, mas diz ZIP Extractor: aqui está um retorno de chamada para você, procure arquivos PDF em um arquivo ZIP, crie um InputStream para cada arquivo e chame o retorno transferido com ele.
Comportamento implícito
Quando não estamos tentando resolver um problema completamente novo que não foi resolvido anteriormente por ninguém, mas fazer algo que outros desenvolvedores já fizeram várias centenas (ou centenas de milhares) de vezes antes, todos os membros da equipe têm algumas expectativas em relação à complexidade ciclomática e intensidade de recursos da solução . Por exemplo, se precisarmos encontrar em um arquivo todas as palavras que começam com a letra z, essa é uma leitura sequencial única do arquivo em blocos do disco. Ou seja, se você se concentrar em
https://gist.github.com/jboner/2841832 - essa operação levará vários microssegundos por 1 MB, talvez, dependendo do ambiente de programação e da carga do sistema, várias dezenas ou até cem microssegundos, mas nem um segundo. Serão necessárias várias dezenas de kilobytes de memória (deixamos de fora a questão do que estamos fazendo com os resultados, essa é a preocupação de outra classe) e o código provavelmente levará cerca de uma tela. Ao mesmo tempo, esperamos que nenhum outro recurso do sistema seja usado. Ou seja, o código não cria threads, grava dados em disco, envia pacotes pela rede e salva dados no banco de dados.
Esta é a expectativa usual de uma chamada de método:
zWordFinder.findZWords(inputStream). ...
Se o código da sua classe não atender a esses requisitos por algum motivo razoável, por exemplo, para classificar uma palavra em z e não z, você precisará chamar o método REST todas as vezes (não sei por que isso pode ser necessário, mas vamos imaginar isso) é necessário escrever com muito cuidado no contrato da classe e é muito bom se o nome do método indicar que o método está sendo executado em algum lugar para consulta.
Se você não tiver um motivo razoável para um comportamento implícito, reescreva a classe.
Como entender as expectativas da complexidade e intensidade dos recursos do método? Você precisa recorrer a uma destas maneiras simples:
- Com a experiência, obtenha horizontes bastante amplos.
- Pergunte a um colega - isso sempre pode ser feito.
- Antes de iniciar o desenvolvimento, converse com os membros da equipe sobre o plano de implementação.
- Para se perguntar: "Mas não uso muitos recursos redundantes nesse método?" Isso geralmente é suficiente.
Você também não precisa se envolver na otimização - salvar 100 bytes quando usado pela classe 100.000 não faz muito sentido para a maioria dos aplicativos.
Essa regra abre uma janela para o rico mundo da engenharia excedente, ocultando respostas a perguntas como "por que você não gasta um mês para salvar 10 bytes de memória em um aplicativo que precisa de 10 GB para funcionar"? Mas não vou desenvolver esse tópico aqui. Ela merece um artigo separado.
Nomes de métodos implícitos
Na programação Java, atualmente existem várias convenções implícitas sobre nomes de classes e seu comportamento. Não existem muitos, mas é melhor não quebrá-los. Vou tentar listar aqueles que vêm à minha mente:
- Construtor - cria uma instância da classe, pode criar algumas estruturas de dados razoavelmente ramificadas, mas não funciona com o banco de dados, não grava em disco, não envia dados pela rede (eu digo, o criador de logs incorporado pode fazer tudo isso, mas essa é uma história diferente em de qualquer forma, está na consciência do configurador de registro).
- Getter - getSomething () - retorna algum tipo de estrutura de memória das profundezas do objeto. Novamente, ele não grava no disco, não realiza cálculos complexos, não envia dados pela rede, não funciona com o banco de dados (exceto quando este é um campo ORM lento e essa é apenas uma das razões pelas quais os campos preguiçosos devem ser usados com muito cuidado) .
- Setter - setSomething (Algo algo) - define o valor da estrutura de dados, não faz cálculos complexos, não envia dados pela rede, não funciona com o banco de dados. Normalmente, não é esperado que o configurador implique comportamento ou consumo de quaisquer recursos de computação significativos.
- equals () e hashcode () - nada é esperado, exceto cálculos e comparações simples em uma quantidade linearmente dependente do tamanho da estrutura de dados. Ou seja, se chamarmos código hash para um objeto de três campos primitivos, espera-se que N * 3 instruções computacionais simples sejam executadas.
- toSomething () - também é esperado que esse método converta um tipo de dados para outro e, para a conversão, ele precise apenas de uma quantidade de memória comparável ao tamanho das estruturas e do tempo do processador, que depende linearmente do tamanho das estruturas. Aqui, note-se que nem sempre a conversão de tipo pode ser feita linearmente, por exemplo, converter uma imagem de pixel em um formato SVG pode ser uma ação não trivial, mas, nesse caso, é melhor nomear o método de maneira diferente. Por exemplo, o nome computeAndConvertToSVG () parece um pouco estranho, mas sugere imediatamente que alguns cálculos significativos estão ocorrendo dentro dele.
Eu darei um exemplo Recentemente, fiz uma auditoria de aplicativos. Pela lógica do trabalho, eu sei que o aplicativo em algum lugar do código assina a fila RabbitMQ. Estou seguindo o código - não consigo encontrar este lugar. Estou procurando um apelo direto ao coelho, estou começando a subir, vou para o local do fluxo de negócios em que a assinatura realmente ocorre - estou começando a jurar. Como fica no código:
- O método service.getQueueListener (tickerName) é chamado - o resultado retornado é ignorado. Isso pode alertar, mas um pedaço de código em que os resultados do método são ignorados não é o único no aplicativo.
- Dentro, tickerName é verificado como nulo e outro método getQueueListenerByName (tickerName) é chamado.
- Dentro dela, uma instância da classe QueueListener é obtida do hash pelo nome do ticker (se não estiver, é criada) e o método getSubscription () é chamado nela.
- E agora, dentro do método getSubscription (), a assinatura realmente ocorre. E acontece em algum lugar no meio de um método do tamanho de três telas.
Vou lhe dizer francamente - sem percorrer toda a cadeia e sem ler uma dúzia de telas de código atentas, não era realista adivinhar onde está a assinatura. Se o método fosse chamado subscribeToQueueByTicker (tickerName), pouparia muito tempo.
Classes de utilidade
Há um livro maravilhoso Design Patterns: Elements of Reusable Object-Oriented Software (1994), muitas vezes chamado GOF (Gang of Four, pelo número de autores). O benefício deste livro é principalmente o fato de oferecer aos desenvolvedores de diferentes países um único idioma para descrever os padrões de design de classe. Agora, em vez de "garantir que a classe exista em apenas uma instância e ter um ponto de acesso estático", podemos dizer "singleton". O mesmo livro causou danos visíveis a mentes frágeis. Esse dano é bem descrito por uma citação de um dos fóruns "Colegas, preciso criar uma loja on-line, diga-me com quais modelos preciso começar". Em outras palavras, alguns programadores tendem a abusar dos padrões de design e, onde quer que você possa gerenciar com uma classe, às vezes eles criam cinco ou seis de uma vez - apenas por precaução, “para maior flexibilidade”.
Como decidir se você precisa de uma fábrica de classes abstratas (ou outro padrão mais complicado que uma interface) ou não? Existem algumas considerações simples:
- Se você estiver escrevendo um aplicativo no Spring, 99% do tempo não será necessário. O Spring oferece blocos de construção de nível superior, use-os. O máximo que você pode achar útil é uma classe abstrata.
- Se o ponto 1 ainda não lhe deu uma resposta clara - lembre-se de que cada modelo tem +1000 pontos para a complexidade do aplicativo. Analise cuidadosamente se os benefícios do uso do modelo superam os danos causados por ele. Voltando a uma metáfora, lembre-se de que cada medicamento não apenas cura, mas também prejudica levemente. Não beba todos os comprimidos de uma só vez.
Um bom exemplo de como você não precisa, pode ver
aqui .
Conclusão
Para resumir, quero observar que listei as recomendações mais básicas. Eu nem os mostraria na forma de um artigo - eles são tão óbvios. Mas, no ano passado, me deparei com aplicativos com muita frequência nas quais muitas dessas recomendações foram violadas. Vamos escrever um código simples, fácil de ler e manter.