
Olá pessoal!
Sou desenvolvedor de back-end na equipe de servidores do Badoo. Na conferência HighLoad do ano passado,
fiz uma apresentação , cuja versão em texto quero compartilhar com você. Esta postagem será mais útil para aqueles que escrevem testes para o back-end e enfrentam problemas com o teste de código legado, bem como para quem deseja testar lógica de negócios complexa.
Sobre o que vamos falar? Primeiro, falarei brevemente sobre nosso processo de desenvolvimento e como isso afeta nossa necessidade de testes e o desejo de escrevê-los. Em seguida, subiremos e desceremos a pirâmide de automação de testes, discutiremos os tipos de testes que usamos, falaremos sobre as ferramentas dentro de cada um deles e quais problemas resolveremos com a ajuda deles. No final, considere como manter e executar todas essas coisas.
Nosso processo de desenvolvimento
Ilustramos nosso processo de desenvolvimento:
Um jogador de golfe é um desenvolvedor de back-end. Em algum momento, uma tarefa de desenvolvimento chega a ele, geralmente na forma de dois documentos: requisitos do lado comercial e um documento técnico que descreve as alterações em nosso protocolo de interação entre o back-end e os clientes (aplicativos móveis e o site).
O desenvolvedor grava o código e o coloca em operação, e antes de todos os aplicativos clientes. Toda a funcionalidade é protegida por alguns sinalizadores de recurso ou testes A / B, conforme prescrito em um documento técnico. Depois disso, de acordo com as prioridades atuais e o roteiro do produto, os aplicativos clientes são liberados. Para nós, desenvolvedores de back-end, é completamente imprevisível quando um recurso específico será implementado nos clientes. O ciclo de lançamento para aplicativos clientes é um pouco mais complicado e mais longo que o nosso, portanto nossos gerentes de produto literalmente fazem malabarismos com prioridades.
A cultura de desenvolvimento adotada pela empresa é de grande importância: o desenvolvedor de back-end é responsável pelo recurso desde o momento de sua implementação no back-end até a última integração na última plataforma em que foi originalmente planejado para implementar esse recurso.
Essa situação é bem possível: seis meses atrás, você lançou algum recurso, as equipes dos clientes não o implementaram por um longo tempo, porque as prioridades da empresa mudaram, você já está ocupado trabalhando em outras tarefas, tem novos prazos, prioridades - e aqui seus colegas vêm correndo e eles dizem: “Você se lembra dessa coisa que lavou seis meses atrás? Ela não está trabalhando. E, em vez de se envolver em novas tarefas, você apaga os incêndios.

Portanto, nossos desenvolvedores têm uma motivação incomum para programadores PHP - para garantir que haja o mínimo de problemas possível durante a fase de integração.
O que você deseja fazer antes de tudo para garantir que o recurso funcione?
Obviamente, a primeira coisa que vem à mente é realizar testes manuais. Você escolhe o aplicativo, mas ele não sabe como - como o recurso é novo, os clientes cuidam dele em seis meses. Bem, o teste manual não garante que, durante o tempo decorrido entre o lançamento do back-end e o início da integração, ninguém quebrará nada nos clientes.
E aqui os testes automatizados vêm em nosso auxílio.
Testes unitários
Os testes mais simples que escrevemos são testes de unidade. Usamos PHP como idioma principal para o back-end e PHPUnit como estrutura para teste de unidade. Olhando para o futuro, direi que todos os nossos testes de back-end foram escritos com base nessa estrutura.
Testes de unidade na maioria das vezes cobrimos alguns pequenos pedaços de código isolados, verificamos o desempenho de métodos ou funções, ou seja, estamos falando de pequenas unidades da lógica de negócios. Nossos testes de unidade não devem interagir com nada, acessar bancos de dados ou serviços.
Softmocks
A principal dificuldade que os desenvolvedores enfrentam ao escrever testes de unidade é um código não testável, e geralmente esse é um código legado.
Um exemplo simples. O Badoo tem 12 anos, uma vez que era uma startup muito pequena, desenvolvida por várias pessoas. A inicialização existiu com sucesso sem nenhum teste. Então ficamos grandes o suficiente e percebemos que você não pode viver sem testes. Mas, nessa época, havia sido escrito muito código que funcionava. Não o reescreva apenas para testar! Isso não seria muito razoável do ponto de vista comercial.
Portanto, desenvolvemos uma pequena
biblioteca de software livre SoftMocks , que torna nosso processo de gravação de testes mais barato e mais rápido. Ele intercepta todos incluem / requer arquivos PHP e on-the-fly substitui o arquivo de origem pelo conteúdo modificado, ou seja, código reescrito. Isso nos permite criar stubs para qualquer código.
Ele detalha como a biblioteca funciona.
Isto é o que parece para um desenvolvedor:
Com a ajuda de construções simples, podemos redefinir globalmente tudo o que queremos. Em particular, eles nos permitem contornar as limitações do criador padrão do PHPUnit. Ou seja, podemos zombar de métodos estáticos e privados, redefinir constantes e fazer muito mais, o que é impossível no PHPUnit comum.
No entanto, encontramos um problema: parece aos desenvolvedores que, se houver SoftMocks, não há necessidade de escrever o código testado - você sempre pode “pentear” o código com nossos mocks globais, e tudo funcionará bem. Mas essa abordagem leva a um código mais complexo e ao acúmulo de "muletas". Portanto, adotamos várias regras que nos permitem manter a situação sob controle:
- Todo novo código deve ser facilmente testado com zombarias padrão do PHPUnit. Se essa condição for atendida, o código poderá ser testado e você poderá selecionar facilmente um pequeno pedaço e testá-lo apenas.
- O SoftMocks pode ser usado com código antigo escrito de uma maneira que não é adequada para testes de unidade, bem como nos casos em que é muito caro / longo / difícil de fazer o contrário (enfatize o necessário).
A conformidade com essas regras é cuidadosamente monitorada no estágio de revisão do código.
Teste de mutação
Separadamente, quero dizer sobre a qualidade dos testes de unidade. Eu acho que muitos de vocês usam métricas como cobertura de código. Mas ela, infelizmente, não responde a uma pergunta: "Eu escrevi um bom teste de unidade?" É possível que você tenha escrito esse teste, que na verdade não verifica nada, não contém uma única declaração, mas gera excelente cobertura de código. Obviamente, o exemplo é exagerado, mas a situação não está tão longe da realidade.
Recentemente, começamos a introduzir testes mutacionais. Este é um conceito bastante antigo, mas não muito conhecido. O algoritmo para esses testes é bastante simples:
- pegue o código e a cobertura do código;
- analisar e começar a mudar o código: verdadeiro para falso,> para> =, + para - (em geral, prejudicar de todas as formas);
- para cada alteração de mutação, execute conjuntos de testes que cubram a sequência alterada;
- se os testes caem, eles são bons e realmente não nos permitem quebrar o código;
- se os testes foram aprovados, provavelmente, eles não são eficazes o suficiente, apesar da cobertura, e pode valer a pena examiná-los mais de perto, para dar alguma afirmação (ou se houver uma área não coberta pelo teste).
Existem várias estruturas prontas para PHP, como Humbug e Infection. Infelizmente, eles não nos agradaram, porque são incompatíveis com o SoftMocks. Portanto, criamos nosso próprio pequeno utilitário de console, que faz o mesmo, mas usa nosso formato de cobertura de código interno e é amigo do SoftMocks. Agora, o desenvolvedor o inicia manualmente e analisa os testes escritos por ele, mas estamos trabalhando para introduzir a ferramenta em nosso processo de desenvolvimento.
Teste de integração
Com a ajuda dos testes de integração, verificamos a interação com vários serviços e bancos de dados.
Para entender melhor a história, vamos desenvolver uma promoção fictícia e cobri-la com testes. Imagine que nossos gerentes de produto decidiram distribuir tickets de conferência para nossos usuários mais dedicados:
A promoção deve ser exibida se:
- o usuário no campo "Trabalho" indica "programador",
- o usuário participa do teste A / B HL18_promo,
- O usuário está registrado há mais de dois anos.
Ao clicar no botão "Obter um ticket", precisamos salvar os dados deste usuário em alguma lista para transferi-los para nossos gerentes que distribuem os tickets.
Mesmo neste exemplo bastante simples, há algo que não pode ser verificado usando testes de unidade - interação com o banco de dados. Para fazer isso, precisamos usar testes de integração.
Considere a maneira padrão de testar a interação do banco de dados oferecida pelo PHPUnit:
- Aumente o banco de dados de teste.
- Preparamos DataTables e DataSets.
- Execute o teste.
- Limpamos o banco de dados de teste.
Que dificuldades estão à espera de tal abordagem?
- Você precisa dar suporte às estruturas do DataTables e DataSets. Se alteramos o layout da tabela, é necessário refletir essas alterações no teste, o que nem sempre é conveniente e requer tempo adicional.
- Leva tempo para preparar o banco de dados. Sempre que configuramos o teste, precisamos fazer o upload de algo lá, criar algumas tabelas, e isso é longo e problemático se houver muitos testes.
- E a desvantagem mais importante: executar esses testes em paralelo os torna instáveis. Começamos o teste A, ele começou a escrever na tabela de teste que ele criou. Ao mesmo tempo, lançamos o teste B, que deseja trabalhar com a mesma tabela de teste. Como resultado, surgem bloqueios mútuos e outras situações imprevistas.
Para evitar esses problemas, desenvolvemos nossa própria pequena biblioteca DBMocks.
DBMocks
O princípio de operação é o seguinte:
- Com a ajuda do SoftMocks, interceptamos todos os wrappers pelos quais trabalhamos com bancos de dados.
- Quando
a consulta passa por simulação, analisa a consulta SQL e extrai DB + TableName dela e obtém o host da conexão.
- No mesmo host em tmpfs, criamos uma tabela temporária com a mesma estrutura que a original (copiamos a estrutura usando SHOW CREATE TABLE).
- Depois disso, redirecionaremos todas as solicitações que passarão por simulação para esta tabela para uma temporária recém-criada.
O que isso nos dá:
- não há necessidade de cuidar constantemente das estruturas;
- os testes não podem mais corromper dados nas tabelas de origem, porque os redirecionamos para tabelas temporárias em tempo real;
- ainda estamos testando a compatibilidade com a versão do MySQL com a qual estamos trabalhando e, se a solicitação deixar de ser compatível com a nova versão de repente, nosso teste a verá e trará.
- e o mais importante, agora os testes estão isolados e, mesmo que você os execute paralelamente, os threads serão dispersos em diferentes tabelas temporárias, pois adicionamos uma chave exclusiva para cada teste nos nomes das tabelas de teste.
Teste de API
A diferença entre os testes de unidade e API é bem ilustrada por este GIF:
 A fechadura funciona bem, mas está presa à porta errada.
A fechadura funciona bem, mas está presa à porta errada.Nossos testes simulam uma sessão do cliente, são capazes de enviar solicitações ao back-end, seguindo nosso protocolo, e o back-end responde a eles como um cliente real.
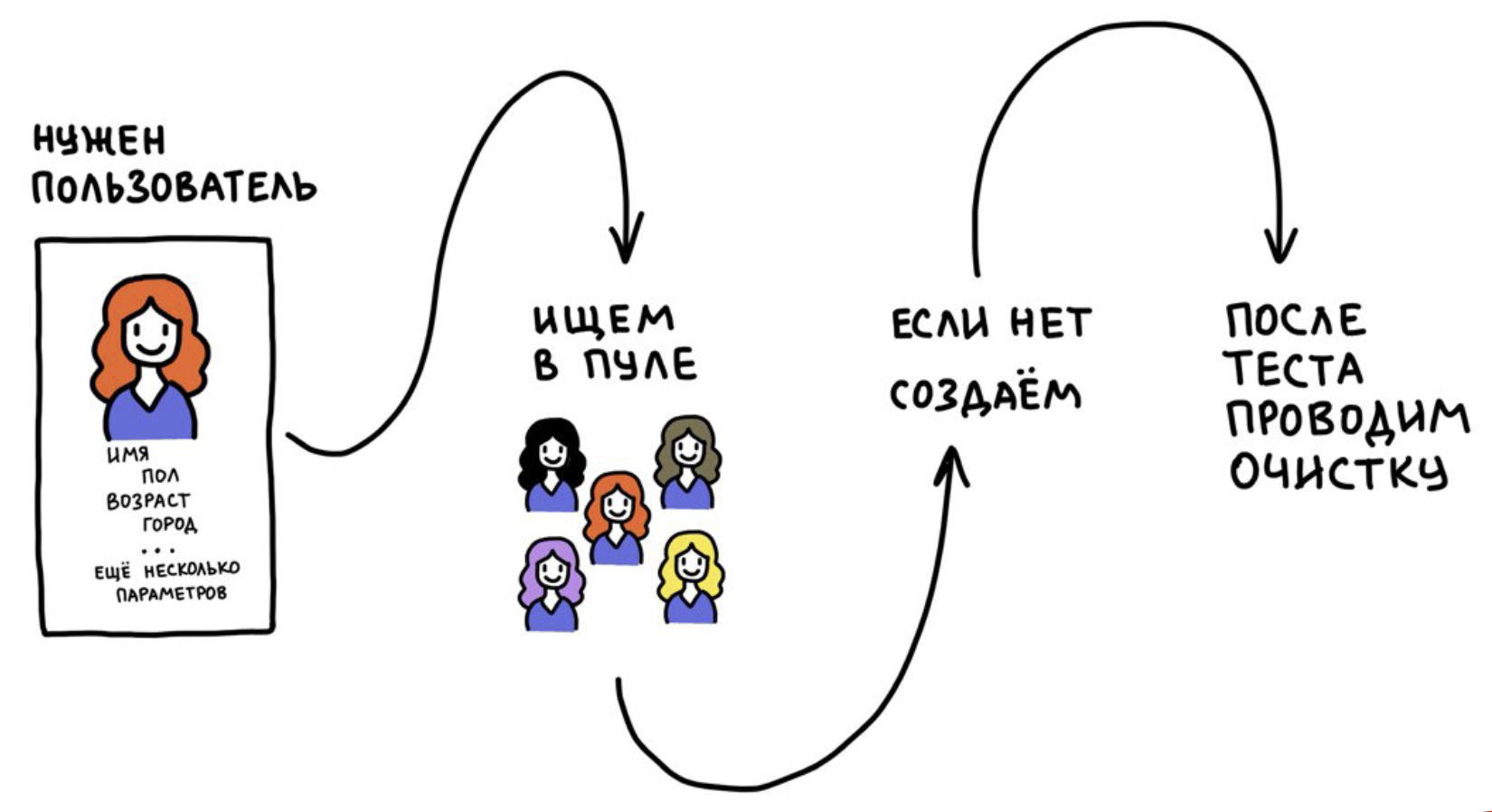
Pool de usuários de teste
O que precisamos para escrever com sucesso esses testes? Vamos voltar às condições do show da nossa promoção:
- o usuário no campo "Trabalho" indica "programador",
- o usuário participa do teste A / B HL18_promo,
- O usuário está registrado há mais de dois anos.
Aparentemente, aqui tudo é sobre o usuário. E, na realidade, 99% dos testes de API requerem um usuário registrado autorizado, presente em todos os serviços e bancos de dados.
Onde conseguir? Você pode tentar registrá-lo no momento do teste, mas:
- é longo e consome recursos;
- após a conclusão do teste, esse usuário precisa ser removido de alguma forma, o que é uma tarefa não trivial se estivermos falando de grandes projetos;
- finalmente, como em muitos outros projetos altamente carregados, realizamos muitas operações em segundo plano (adicionando um usuário a vários serviços, replicação para outros data centers etc.); os testes não sabem nada sobre esses processos, mas se eles implicitamente dependem dos resultados de sua execução, há um risco de instabilidade.
Desenvolvemos uma ferramenta chamada Test Users Pool. É baseado em duas idéias:
- Não registramos usuários o tempo todo, mas o usamos muitas vezes.
- Após o teste, redefinimos os dados do usuário para seu estado original (no momento do registro). Se isso não for feito, os testes se tornarão instáveis ao longo do tempo, porque os usuários serão "poluídos" com informações de outros testes.
Funciona mais ou menos assim:
Em algum momento, queríamos executar nossos testes de API em um ambiente de produção. Por que queremos isso? Porque a infraestrutura de desenvolvimento não é a mesma que produção.
Embora tentemos repetir constantemente a infraestrutura de produção em um tamanho reduzido, o desenvolvimento nunca será uma cópia completa dela. Para ter certeza absoluta de que a nova compilação atende às expectativas e não há problemas, carregamos o novo código no cluster de pré-produção, que trabalha com dados e serviços de produção, e executamos nossos testes de API lá.
Nesse caso, é muito importante pensar em como isolar usuários de teste dos reais.
O que acontecerá se os usuários de teste começarem a parecer reais em nosso aplicativo. Como isolar? Cada um de nossos usuários tem um sinalizador
is_test_user . No estágio de registro, torna-se
yes ou
no e não muda mais. Com esse sinalizador, isolamos os usuários em todos os serviços. Também é importante excluirmos os usuários de teste das análises de negócios e dos resultados dos testes A / B para não distorcer as estatísticas.
Você pode seguir de uma maneira mais simples: começamos com o fato de que todos os usuários de teste foram "realocados" para a Antártica. Se você possui um serviço geográfico, esta é uma maneira completamente funcional.
API de controle de qualidade
Não precisamos apenas de um usuário - precisamos dele com certos parâmetros: trabalhar como programador, participar de um determinado teste A / B e foi registrado há mais de dois anos. Para usuários de teste, podemos facilmente atribuir uma profissão usando nossa API de back-end, mas entrar nos testes A / B é probabilístico. E a condição de registro há mais de dois anos atrás é geralmente difícil de cumprir, porque não sabemos quando o usuário apareceu no pool.
Para resolver esses problemas, temos uma API de controle de qualidade. Na verdade, esse é um backdoor para testes, que é um método API bem documentado que permite gerenciar de maneira rápida e fácil os dados do usuário e alterar seu estado, ignorando o protocolo principal de nossa comunicação com os clientes. Os métodos são escritos por desenvolvedores de back-end para engenheiros de controle de qualidade e para uso em testes de interface do usuário e API.
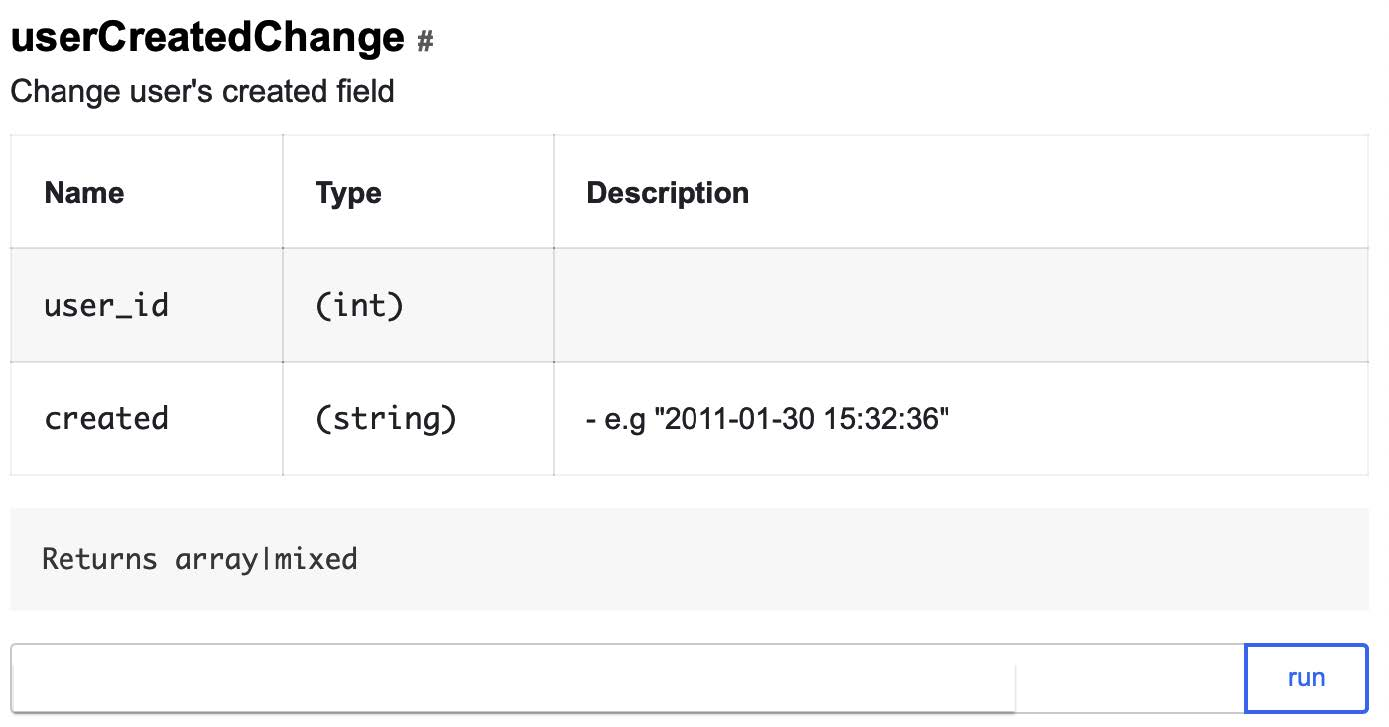
A API de controle de qualidade pode ser aplicada apenas no caso de usuários de teste: se não houver um sinalizador correspondente, o teste cairá imediatamente. Aqui está um dos métodos da API de controle de qualidade que permite alterar a data de registro do usuário para uma data arbitrária:
E assim parecerão três chamadas que permitirão alterar rapidamente os dados do usuário de teste, para que eles satisfaçam as condições de exibição da promoção:
- No campo "Trabalho", o "programador" é indicado:
addUserWorkEducation?user_id=ID&works[]=Badoo,
- O usuário participa do teste A / B HL18_promo:
forceSplitTest?user_id=ID&test=HL18_promo
- Registrado há mais de dois anos:
userCreatedChange?user_id=ID&created=2016-09-01
Como esse é um backdoor, é imperativo pensar em segurança. Protegemos nosso serviço de várias maneiras:
- isolado no nível da rede: os serviços podem ser acessados somente a partir da rede do escritório;
- com cada solicitação, passamos um segredo, sem o qual é impossível acessar a API de controle de qualidade, mesmo a partir da rede do escritório;
- Os métodos funcionam apenas com usuários de teste.
Remotemocks
Para trabalhar com o back-end remoto de testes de API, podemos precisar de zombarias. Para que? Por exemplo, se o teste da API no ambiente de produção começar a acessar o banco de dados, precisamos garantir que os dados contidos nele sejam limpos dos dados de teste. Além disso, as zombarias ajudam a tornar a resposta do teste mais adequada para o teste.
Temos três textos:
O Badoo é um aplicativo multilíngue, temos um componente de localização complexo que permite traduzir e receber traduções rapidamente para a localização atual do usuário. Nossos localizadores estão trabalhando constantemente para melhorar as traduções, realizar testes A / B com tokens e procurar formulações mais bem-sucedidas. E, durante a realização do teste, não podemos saber qual texto será retornado pelo servidor - ele pode ser alterado a qualquer momento. Mas podemos usar o RemoteMocks para verificar se o componente de localização é acessado corretamente.
Como o RemoteMocks funciona? O teste solicita que o back-end os inicialize para sua sessão e, após o recebimento de todas as solicitações subsequentes, o back-end verifica zombarias para a sessão atual. Se estiverem, basta inicializá-los usando o SoftMocks.
Se queremos criar uma simulação remota, indicamos qual classe ou método precisa ser substituído e com o quê. Todas as solicitações de back-end subsequentes serão executadas levando em consideração este mock:
$this->remoteInterceptMethod( \Promo\HighLoadConference::class, 'saveUserEmailToDb', true );
Bem, agora vamos coletar nosso teste de API:
De uma maneira tão simples, podemos testar qualquer funcionalidade que venha ao desenvolvimento no back-end e exija alterações no protocolo móvel.
Regras de uso de teste da API
Tudo parece estar bem, mas novamente encontramos um problema: os testes da API se mostraram muito convenientes para o desenvolvimento e houve uma tentação de usá-los em qualquer lugar. Como resultado, uma vez que percebemos que estávamos começando a resolver problemas com a ajuda de testes de API para os quais eles não eram destinados.
Por que isso é ruim? Porque os testes da API são muito lentos. Eles acessam a rede, recorrem ao back-end, que inicia a sessão, acessam o banco de dados e vários serviços. Portanto, desenvolvemos um conjunto de regras para o uso de testes de API:
- O objetivo dos testes de API é verificar o protocolo de interação entre o cliente e o servidor, bem como a correta integração do novo código;
- é permitido cobrir processos complexos com eles, por exemplo, cadeias de ações;
- eles não podem ser usados para testar a pequena variabilidade da resposta do servidor - esta é a tarefa dos testes de unidade;
- durante a revisão do código, verificamos incluindo os testes.
Testes de interface do usuário
Como estamos considerando uma pirâmide de automação, vou falar um pouco sobre os testes de interface do usuário.
Os desenvolvedores de back-end do Badoo não escrevem testes de interface do usuário - para isso, temos uma equipe dedicada no departamento de controle de qualidade. Cobrimos o recurso com testes de interface do usuário quando ele já é lembrado e estabilizado, porque acreditamos que não é razoável gastar recursos em uma automação bastante cara do recurso, que talvez não vá além do teste A / B.
Usamos o Calabash para testes automáticos para dispositivos móveis e o Selenium para a web.
Ele fala sobre a nossa plataforma para automação e teste.
Execução de teste
Agora, temos 100.000 testes de unidade, 6.000 - testes de integração e 14.000 testes de API. Se você tentar executá-los em um encadeamento, mesmo em nossa máquina mais poderosa, uma execução completa levará: modular - 40 minutos, integração - 90 minutos, testes de API - dez horas. É muito longo.
Paralelização
Falamos sobre nossa experiência de testes de unidade paralelos neste artigo .A primeira solução, que parece óbvia, é executar testes em vários threads. Mas fomos além e criamos uma nuvem para o lançamento paralelo para poder escalar recursos de hardware. Simplificado, seu trabalho se parece com o seguinte:
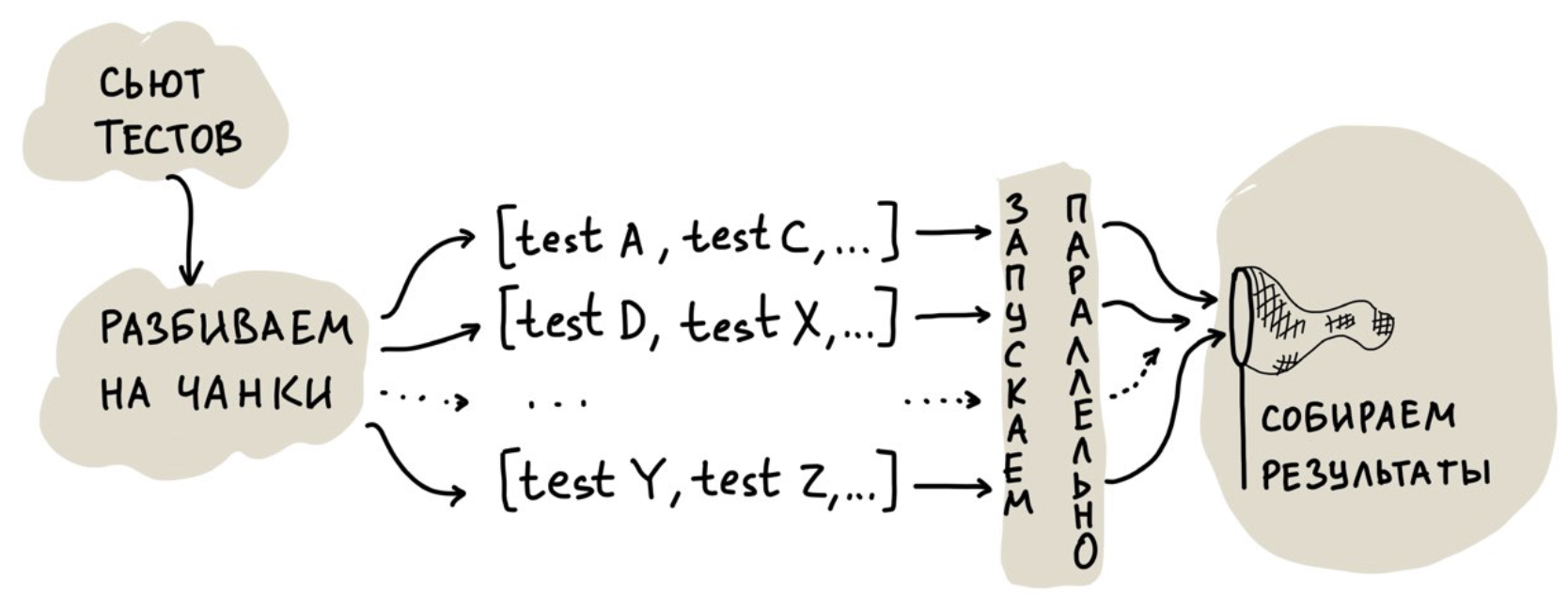
A tarefa mais interessante aqui é a distribuição de testes entre os threads, ou seja, sua divisão em partes.
Você pode dividi-los igualmente, mas todos os testes são diferentes, portanto, pode haver um forte viés no tempo de execução de um encadeamento: todos os encadeamentos já foram atingidos e um trava por meia hora, pois teve "sorte" com testes muito lentos.
Você pode iniciar vários threads e alimentá-los com um teste de cada vez. Nesse caso, a desvantagem é menos óbvia: há custos indiretos para inicializar o ambiente que, com um grande número de testes e essa abordagem, começam a desempenhar um papel importante.
O que fizemos? Começamos a coletar estatísticas sobre o tempo necessário para executar cada teste e, em seguida, começamos a compor partes de maneira que, de acordo com as estatísticas, um encadeamento fosse executado por não mais que 30 segundos. Ao mesmo tempo, empacotamos os testes em pedaços para torná-los menores.
No entanto, nossa abordagem também tem uma desvantagem. Está associado a testes de API: eles são muito lentos e consomem muitos recursos, impedindo a execução de testes rápidos.
Portanto, dividimos a nuvem em duas partes: na primeira, apenas os testes rápidos são lançados; na segunda, os rápidos e os lentos podem ser lançados. Com essa abordagem, sempre temos um pedaço da nuvem que pode lidar com testes rápidos.
Como resultado, os testes de unidade começaram a ser executados em um minuto, os testes de integração em cinco minutos e os testes de API em 15 minutos. Ou seja, uma execução completa em vez de 12 horas não leva mais que 22 minutos.
Execução do teste de cobertura de código
Temos um grande monólito complexo e, de uma maneira boa, precisamos executar todos os testes constantemente, pois uma mudança em um lugar pode quebrar algo em outro. Essa é uma das principais desvantagens da arquitetura monolítica.
Em algum momento, chegamos à conclusão de que você não precisa executar todos os testes todas as vezes - você pode executar com base na cobertura do código:
- Veja o nosso diferencial.
- Criamos uma lista de arquivos modificados.
- Para cada arquivo, obtemos uma lista de testes,
que cobrem isso.
- A partir desses testes, criamos um conjunto e o executamos em uma nuvem de teste.
Onde obter cobertura? Coletamos dados uma vez por dia quando a infraestrutura do ambiente de desenvolvimento está ociosa. O número de testes executados diminuiu acentuadamente, a velocidade de receber feedback deles, pelo contrário, aumentou significativamente. Lucro!
Um bônus adicional foi a capacidade de executar testes de patches. Apesar de o Badoo não ser uma startup há muito tempo, ainda podemos implementar rapidamente mudanças na produção, aplicar hot fix, distribuir recursos rapidamente e alterar a configuração. Como regra, a velocidade de lançamento de patches é muito importante para nós.
A nova abordagem deu um grande aumento na velocidade de feedback dos testes, porque agora não precisamos esperar muito tempo para uma execução completa.Mas sem as falhas, em lugar nenhum. Lançaremos o back-end duas vezes por dia, e a cobertura é relevante apenas para o primeiro lançamento, até o primeiro build, após o qual ele fica para trás em um build. Portanto, para compilações, executamos um conjunto de testes completo. Para nós, isso é uma garantia de que a cobertura do código não está muito atrás e que todos os testes necessários foram concluídos. O pior que pode acontecer é que pegaremos alguns testes caídos no estágio de criação do build, e não nos estágios anteriores. Mas isso acontece muito raramente.API-, code coverage. , , . - , API- .
Conclusão
- , . - , , - .
- ≠ . code review , .
- , , . .
- . .
- , ! , .
, Badoo PHP Meetup 16 . PHP-. , . ! 12:00, — YouTube- .