Sou um grande fã de tudo o que
Fabien Sanglard faz, gosto do blog dele e leio os
dois livros de capa a capa (descritos em um recente
podcast da Hansleminutes ).
Fabien recentemente escreveu um ótimo post onde
descriptografou um pequeno traçador de raios, desobstruindo o código e explicando a matemática de maneira fantástica. Eu realmente recomendo reservar um tempo para ler isso!
Mas isso me fez pensar
se é possível portar esse código C ++ para C # ? Como tenho escrito bastante C ++ no meu
trabalho principal ultimamente, achei que poderia tentar.
Mais importante, porém, eu queria ter uma idéia melhor de
se o C # é uma linguagem de baixo nível ?
Uma pergunta um pouco diferente, mas relacionada: quanto o C # é adequado para a "programação do sistema"? Sobre esse assunto, eu realmente recomendo
o excelente post de Joe Duffy de 2013 .
Porta de linha
Comecei simplesmente portando
código C ++ desofuscado linha por linha para C #. Era bem simples: parece que a verdade ainda está sendo dita que C # é C ++++ !!!
O exemplo mostra a estrutura de dados principal - 'vetor', aqui está uma comparação, C ++ à esquerda, C # à direita:

Portanto, existem algumas diferenças sintáticas, mas como o .NET permite que você defina
seus próprios tipos de valor , consegui obter a mesma funcionalidade. Isso é importante porque tratar 'vetor' como uma estrutura significa que podemos obter uma melhor "localidade de dados" e não precisamos envolver o coletor de lixo .NET, porque os dados serão enviados para a pilha (sim, eu sei que este é um detalhe de implementação).
Para obter mais informações sobre
structs ou "tipos de valor" no .NET, consulte aqui:
Em particular, no último post de Eric Lippert, encontramos uma citação tão útil que deixa claro o que realmente são “tipos de valor”:
Obviamente, o fato mais importante sobre os tipos de valores não são os detalhes da implementação, como eles são alocados , mas o significado semântico original do "tipo de valor", a saber, que ele sempre é copiado "por valor" . Se as informações de alocação fossem importantes, as chamaríamos de "tipos de heap" e "tipos de pilha". Mas na maioria dos casos isso não importa. Na maioria das vezes, a semântica da cópia e identificação é relevante.
Agora vamos ver como são outros métodos em comparação (novamente C ++ à esquerda, C # à direita), primeiro
RayTracing(..) :
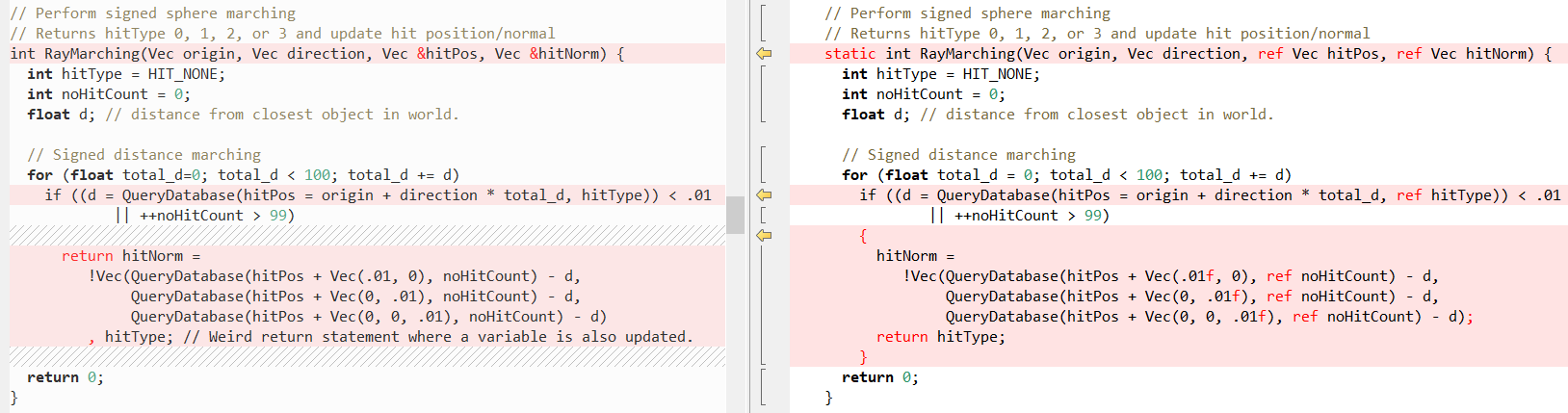
Em seguida,
QueryDatabase (..) :
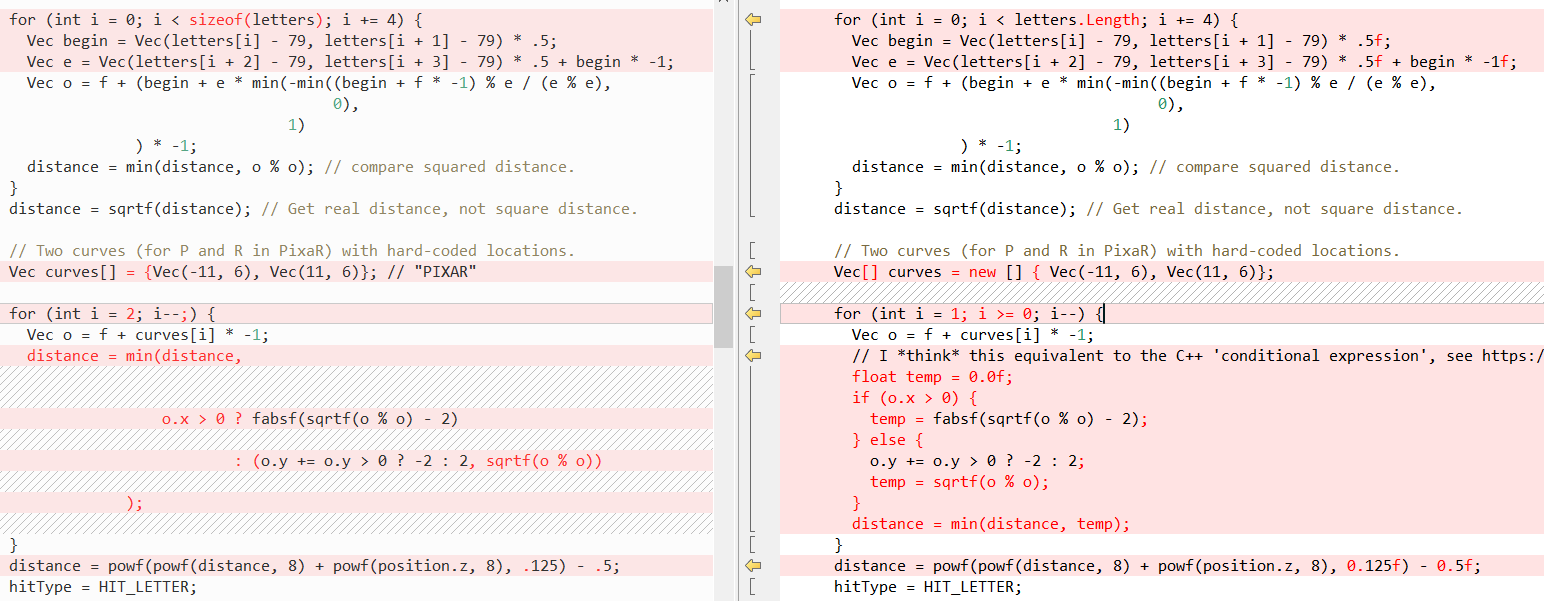
(veja
o post de Fabian para uma explicação do que essas duas funções fazem)
Mas, novamente, o fato é que o C # facilita a gravação de código C ++! Nesse caso, a palavra-chave
ref ajuda-nos ao máximo, o que nos permite passar um
valor por referência . Usamos
ref em chamadas de método há bastante tempo, mas recentemente foram feitos esforços para resolver
ref outros lugares:
Agora,
às vezes, usar
ref melhorará o desempenho, porque a estrutura não precisará ser copiada. Consulte os benchmarks no
post de Adam Stinix e
“Performance traps ref locals e ref return in C #” para obter mais informações.
Mas o mais importante é que esse script forneça à nossa porta C # o mesmo comportamento que o código-fonte C ++. Embora eu queira observar que os chamados "links gerenciados" não são exatamente os mesmos que "ponteiros", em particular, você não pode executar aritmética neles, veja mais aqui:
Desempenho
Assim, o código foi bem portado, mas o desempenho também importa. Especialmente no traçador de raios, que pode calcular o quadro por vários minutos. O código C ++ contém a variável
sampleCount , que controla a qualidade final da imagem, com
sampleCount = 2 seguinte maneira:

Obviamente, não é muito realista!
Mas quando você obtém
sampleCount = 2048 , tudo parece
muito melhor:

Mas começar com
sampleCount = 2048 consome
muito tempo, portanto, todas as outras execuções são executadas com um valor
2 para atender pelo menos um minuto. Alterar
sampleCount afeta apenas o número de iterações do loop de código mais externo; consulte
esta lista para obter uma explicação.
Resultados após uma porta de linha “ingênua”
Para comparar substancialmente C ++ e C #, usei a ferramenta
time-windows , esta é a porta do comando
time unix. Os resultados iniciais foram assim:
| C ++ (VS 2017) | .NET Framework (4.7.2) | .NET Core (2.2) |
|---|
| Tempo (s) | 47,40 | 80,14 | 78,02 |
| No núcleo (s) | 0,14 (0,3%) | 0,72 (0,9%) | 0,63 (0,8%) |
| No espaço do usuário (s) | 43,86 (92,5%) | 73,06 (91,2%) | 70,66 (90,6%) |
| Número de erros de falha de página | 1143 | 4818 | 5945 |
| Conjunto de trabalho (KB) | 4232 | 13 624 | 17 052 |
| Memória extrudada (KB) | 95 | 172 | 154 |
| Memória não preemptiva | 7 | 14 | 16 |
| Trocar arquivo (KB) | 1460 | 10 936 | 11 024 |
Inicialmente, vemos que o código C # é um pouco mais lento que a versão C ++, mas está melhorando (veja abaixo).
Mas vamos primeiro ver o que o .NET JIT faz conosco, mesmo com essa porta "ingênua" linha por linha. Primeiro, ele faz um bom trabalho ao incorporar métodos auxiliares menores. Isso pode ser visto na saída da excelente ferramenta
Inlining Analyzer (verde = embutido):
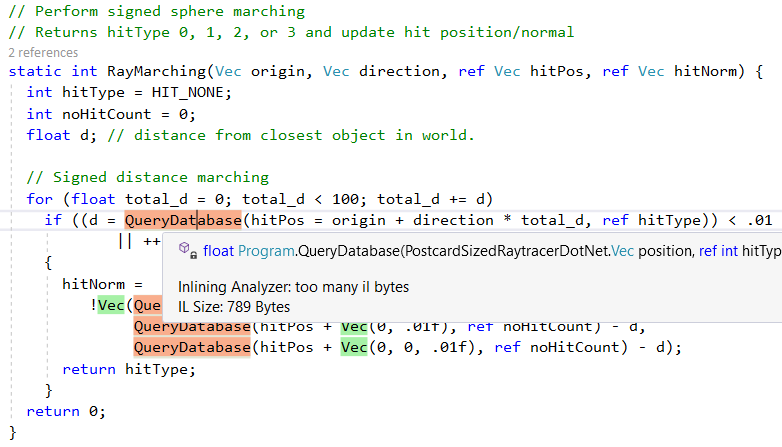
No entanto, ele não incorpora todos os métodos, por exemplo, devido à complexidade,
QueryDatabase(..) ignorado:
Outro recurso do compilador .NET Just-In-Time (JIT) é a conversão de chamadas de método específicas para as instruções de CPU correspondentes. Podemos ver isso em ação com a função shell
sqrt , aqui está o código fonte do C # (observe a chamada para
Math.Sqrt ):
E aqui está o código do assembler que o .NET JIT gera: não há chamada para
Math.Sqrt e a instrução do processador
vsqrtsd é usada :
; Assembly listing for method Program:sqrtf(float):float ; Emitting BLENDED_CODE for X64 CPU with AVX - Windows ; Tier-1 compilation ; optimized code ; rsp based frame ; partially interruptible ; Final local variable assignments ; ; V00 arg0 [V00,T00] ( 3, 3 ) float -> mm0 ;# V01 OutArgs [V01 ] ( 1, 1 ) lclBlk ( 0) [rsp+0x00] "OutgoingArgSpace" ; ; Lcl frame size = 0 G_M8216_IG01: vzeroupper G_M8216_IG02: vcvtss2sd xmm0, xmm0 vsqrtsd xmm0, xmm0 vcvtsd2ss xmm0, xmm0 G_M8216_IG03: ret ; Total bytes of code 16, prolog size 3 for method Program:sqrtf(float):float ; ============================================================
(para obter esse problema, siga
estas instruções , use o
complemento VS2019 "Disasmo" ou consulte o
SharpLab.io )
Essas substituições também são conhecidas como
intrínsecas e, no código abaixo, podemos ver como o JIT as gera. Esse trecho mostra o mapeamento apenas para
AMD64 , mas o JIT também tem como alvo
X86 ,
ARM e
ARM64 , o método completo
aqui .
bool Compiler::IsTargetIntrinsic(CorInfoIntrinsics intrinsicId) { #if defined(_TARGET_AMD64_) || (defined(_TARGET_X86_) && !defined(LEGACY_BACKEND)) switch (intrinsicId) {
Como você pode ver, alguns métodos são implementados, como
Sqrt e
Abs , enquanto outros usam funções de tempo de execução C ++, por exemplo,
powf .
Todo esse processo é muito bem explicado no artigo
"Como o Math.Pow () é implementado no .NET Framework?" , também pode ser visto na fonte CoreCLR:
Resultados após melhorias simples no desempenho
Gostaria de saber se você pode melhorar imediatamente a porta ingênua linha por porta. Após alguns perfis, fiz duas grandes mudanças:
- Removendo a inicialização de matriz embutida
- Substituindo as funções de
Math.XXX(..) por análogos de MathF.()
Essas alterações são explicadas em mais detalhes abaixo.
Removendo a inicialização de matriz embutida
Para obter mais informações sobre por que isso é necessário, consulte
esta excelente resposta de estouro de pilha de
Andrei Akinshin , juntamente com referências e código de montador. Ele chega à seguinte conclusão:
Conclusão
- O .NET armazena em cache matrizes locais codificadas? Como os que colocam o compilador Roslyn em metadados.
- Nesse caso, haverá sobrecarga? Infelizmente, sim: para cada chamada, o JIT copiará o conteúdo da matriz dos metadados, o que leva mais tempo em comparação com uma matriz estática. O tempo de execução também seleciona objetos e cria tráfego na memória.
- Existe alguma necessidade de se preocupar com isso? Possivelmente. Se esse for um método ativo e você desejar obter um bom nível de desempenho, precisará usar uma matriz estática. Se esse é um método frio que não afeta o desempenho do aplicativo, você provavelmente precisará escrever um código-fonte “bom” e colocar a matriz na área do método.
Você pode ver as alterações feitas
neste diff .
Usando funções MathF em vez de Math
Em segundo lugar, e mais importante, eu melhorei significativamente o desempenho fazendo as seguintes alterações:
#if NETSTANDARD2_1 || NETCOREAPP2_0 || NETCOREAPP2_1 || NETCOREAPP2_2 || NETCOREAPP3_0
A partir do .NET Standard 2.1, existem implementações concretas de funções matemáticas comuns de
float . Eles estão localizados na classe
System.MathF . Para saber mais sobre essa API e sua implementação, consulte aqui:
Após essas alterações, a diferença no desempenho do código C # e C ++ foi reduzida para cerca de 10%:
| C ++ (VS C ++ 2017) | .NET Framework (4.7.2) | TC do .NET Core (2.2) DESATIVADO | TC do .NET Core (2.2) ativado |
|---|
| Tempo (s) | 41,38 | 58,89 | 46,04 | 44,33 |
| No núcleo (s) | 0,05 (0,1%) | 0,06 (0,1%) | 0,14 (0,3%) | 0,13 (0,3%) |
| No espaço do usuário (s) | 41,19 (99,5%) | 58,34 (99,1%) | 44,72 (97,1%) | 44,03 (99,3%) |
| Número de erros de falha de página | 1119 | 4749 | 5776 | 5661 |
| Conjunto de trabalho (KB) | 4136 | 13.440 | 16.788 | 16.652 |
| Memória extrudada (KB) | 89 | 172 | 150 | 150 |
| Memória não preemptiva | 7 | 13 | 16 | 16 |
| Trocar arquivo (KB) | 1428 | 10 904 | 10 960 | 11 044 |
TC - compilação multinível, compilação em
camadas (
suponho que será ativada por padrão no .NET Core 3.0)
Para completar, eis os resultados de várias execuções:
| Executar | C ++ (VS C ++ 2017) | .NET Framework (4.7.2) | TC do .NET Core (2.2) DESATIVADO | TC do .NET Core (2.2) ativado |
|---|
| TestRun-01 | 41,38 | 58,89 | 46,04 | 44,33 |
| TestRun-02 | 41.19 | 57,65 | 46,23 | 45,96 |
| TestRun-03 | 42,17 | 62,64 | 46,22 | 48,73 |
Nota : a diferença entre o .NET Core e o .NET Framework se deve à ausência da API MathF no .NET Framework 4.7.2. Para obter mais informações, consulte
o tíquete de suporte .Net Framework (4.8?) Para o padrão de rede 2.1 .
Aumentar ainda mais a produtividade
Estou certo de que o código ainda pode ser melhorado!
Se você estiver interessado em resolver a diferença de desempenho,
aqui está o código C # . Para comparação, você pode assistir ao código do assembler C ++ no excelente serviço
Compiler Explorer .
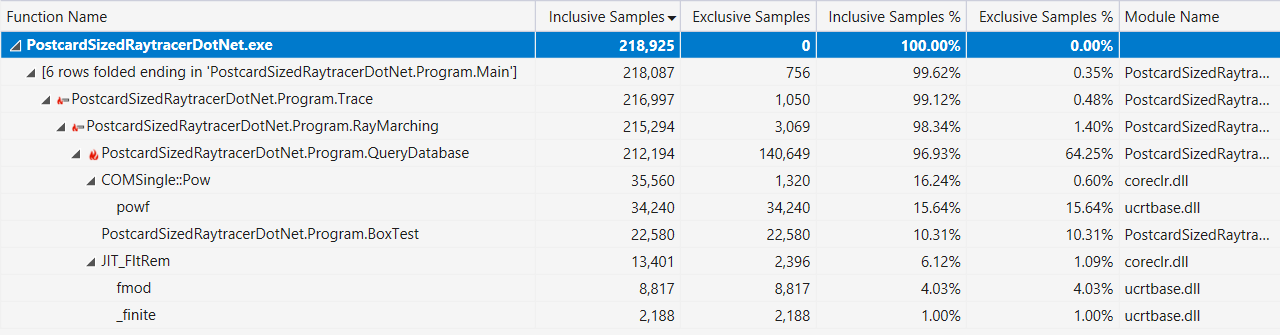
Por fim, se isso ajudar, aqui está a saída do criador de perfil do Visual Studio com uma exibição "hot path" (após as melhorias de desempenho descritas acima):
C # é um idioma de baixo nível?
Ou mais especificamente:
Quais recursos de idioma da funcionalidade C # / F # / VB.NET ou BCL / Runtime significam programação "baixo nível" *?
* Sim, entendo que "nível baixo" é um termo subjetivo.
Nota: cada desenvolvedor de C # tem sua própria idéia do que é o “baixo nível”, essas funções serão consideradas garantidas pelos programadores de C ++ ou Rust.
Aqui está a lista que eu fiz:
- ref retorna e ref locals
- “Passagem e retorno por referência para evitar a cópia de grandes estruturas. Tipos e memória seguros podem ser ainda mais rápidos do que inseguros! ”
- Código inseguro no .NET
- “A linguagem C # principal, conforme definida nos capítulos anteriores, é muito diferente de C e C ++, pois não possui ponteiros como tipo de dados. Em vez disso, o C # fornece links e a capacidade de criar objetos controlados pelo coletor de lixo. Esse design, combinado com outros recursos, torna o C # uma linguagem muito mais segura que o C ou C ++. ”
- Ponteiros gerenciados no .NET
- “Existe outro tipo de ponteiro no CLR - um ponteiro gerenciado. Ele pode ser definido como um tipo mais geral de link que pode apontar para outros locais, e não apenas para o início do objeto. ”
- Série C # 7, parte 10: Span <T> e gerenciamento de memória universal
- “System.Span <T> é apenas um tipo de pilha (
ref struct ) que agrupa todos os padrões de acesso à memória; é um tipo para acesso universal à memória contínua. Podemos imaginar uma implementação Span com uma referência fictícia e um comprimento que aceite todos os três tipos de acesso à memória ".
- Compatibilidade ("Guia de Programação em C #")
- "O .NET Framework fornece interoperabilidade com código não gerenciado por meio de serviços de chamada de plataforma, o
System.Runtime.InteropServices , compatibilidade com C ++ e compatibilidade COM (interoperabilidade COM)."
Também chorei no Twitter e tenho muito mais opções para inclusão na lista:
- Ben Adams : “Ferramentas internas para plataformas (instruções da CPU)”
- Mark Gravell : “O SIMD via Vector (que combina bem com o Span) é * bastante * baixo; O .NET Core deve (em breve?) Oferecer ferramentas incorporadas diretas à CPU para uso mais explícito de instruções específicas da CPU ”
- Mark Gravell : “JIT poderoso: coisas como elisão de intervalo em matrizes / intervalos, além de usar regras por estrutura-T para remover grandes partes de código que o JIT sabe com certeza que elas não estão disponíveis para esse T ou para o seu específico CPU (BitConverter.IsLittleEndian, Vector.IsHardwareAccelerated, etc.) "
- Kevin Jones : “Eu mencionaria especialmente as classes
MemoryMarshal e Unsafe , e talvez algumas outras coisas nos System.Runtime.CompilerServices ”
- Theodoros Chatsigiannakis : "Você também pode incluir
__makeref e o resto"
- damageeboy : "A capacidade de gerar dinamicamente um código que corresponda exatamente à entrada esperada, uma vez que este último só será conhecido em tempo de execução e poderá ser alterado periodicamente?"
- Robert Hacken : "Emissão dinâmica de IL"
- Victor Baybekov : “Stackalloc não foi mencionado. Também é possível escrever IL pura (não dinâmica, portanto, é salva em uma chamada de função), por exemplo, use
ldftn cache e chame-os através de calli . Há um modelo de projeto no VS2017 que torna isso trivial reescrevendo os métodos extern + MethodImplOptions.ForwardRef + ilasm.ex »
- Victor Baybekov : “MethodImplOptions.AggressiveInlining também“ ativa a programação de baixo nível ”no sentido em que permite escrever código de alto nível com muitos métodos pequenos e ainda controlar o comportamento do JIT para obter um resultado otimizado. Caso contrário, copie e cole centenas de métodos LOC ... "
- Ben Adams : “Usando as mesmas convenções de chamada (ABI) que na plataforma base ep / chama para interação?”
- Victor Baibekov : “Além disso, como você mencionou #fsharp - ela possui uma
inline que funciona no nível de IL até JIT, portanto foi considerada importante no nível de idioma. C # isso não é suficiente (até agora) para lambdas, que são sempre chamadas virtuais, e as soluções alternativas geralmente são estranhas (genéricos limitados) "
- Alexandre Mutel : “Novo SIMD incorporado, pós-processamento da classe Unsafe Utility / IL (por exemplo, personalizado, Fody, etc.). Para C # 8.0, próximos ponteiros de função ... "
- Alexandre Mutel : “Em relação à IL, o F # suporta diretamente a IL em um idioma, por exemplo”
- OmariO : “ Primários binários . Nível baixo, mas seguro "
- Koji Matsui : “E o seu próprio montador embutido? É difícil para o kit de ferramentas e o tempo de execução, mas pode substituir a solução p / invoke atual e implementar o código incorporado, se houver "
- Frank A. Kruger : "Ldobj, stobj, initobj, initblk, cpyblk"
- Conrad Coconut : “Talvez fazendo streaming de armazenamento local? Buffers de tamanho fixo? Você provavelmente deve mencionar restrições não gerenciadas e tipos blittable :) ”
- Sebastiano Mandala : “Apenas uma pequena adição a tudo o que foi dito: que tal algo simples, como organizar estruturas e como o preenchimento e o alinhamento da memória e da ordem dos campos podem afetar o desempenho do cache? Isso é algo que eu mesmo devo explorar.
- Nino Floris : "Constantes incorporadas via readonlyspan, stackalloc, finalizadores, WeakReference, representantes abertos, MethodImplOptions, MemoryBarriers, TypedReference, varargs, SIMD, Unsafe.AsRef, podem definir os tipos de estruturas exatamente de acordo com o layout (usado para TaskAwaiter e sua versão)"
Portanto, no final, eu diria que o C # certamente permite que você escreva um código parecido com o C ++ e, em combinação com as bibliotecas de tempo de execução e de classe base, fornece muitas funções de baixo nível.Leitura adicional
Compilador de explosão da unidade: