Prefácio
Existe um utilitário tão simples e muito útil no mundo - o
BDelta , e aconteceu que ele se enraizou no nosso processo de produção por um longo tempo (embora sua versão não possa ser instalada, mas certamente não foi a última disponível). Nós o usamos para a finalidade a que se destina - a construção de patches binários. Se você olhar para o que está no repositório, fica um pouco triste: na verdade, foi abandonado há muito tempo e muito estava desatualizado (uma vez que meu ex-colega fez várias correções no local, mas isso foi há muito tempo). Em geral, decidi ressuscitar esse negócio: bifurquei-me, joguei fora o que não planejava usar, superei o projeto no
cmake , inline as microfunções "quentes", removi grandes matrizes da pilha (e matrizes de comprimento variável, das quais francamente "bombardei") , mais uma vez dirigiu o criador de perfil - e descobriu que cerca de 40% do tempo é gasto em
fwrite ...
Então, o que há com fwrite?
Nesse código, fwrite (no meu caso de teste específico: criando um patch entre arquivos próximos de 300 MB, os dados de entrada estão completamente na memória) é chamado milhões de vezes com um pequeno buffer. Obviamente, isso diminuirá a velocidade e, portanto, eu gostaria de influenciar de alguma forma essa desgraça. Não há desejo de implementar qualquer tipo de fonte de dados, entrada-saída assíncrona, eu queria encontrar uma solução mais fácil. A primeira coisa que veio à mente foi aumentar o tamanho do buffer
setvbuf(file, nullptr, _IOFBF, 64* 1024)
mas não obtive uma melhora significativa no resultado (agora a fwrite representava cerca de 37% do tempo) - significa que o problema ainda não está na gravação frequente de dados no disco. Olhando fwrite "under the hood", você pode ver que a estrutura FILE de bloqueio / desbloqueio está acontecendo dentro desta forma (pseudo-código, todas as análises foram feitas no Visual Studio 2017):
size_t fwrite (const void *buffer, size_t size, size_t count, FILE *stream) { size_t retval = 0; _lock_str(stream); __try { retval = _fwrite_nolock(buffer, size, count, stream); } __finally { _unlock_str(stream); } return retval; }
De acordo com o criador de perfil, _fwrite_nolock é responsável por apenas 6% do tempo, o restante é indireto. No meu caso particular, a segurança do encadeamento é um excesso óbvio, e eu o sacrificarei substituindo a chamada fwrite por
_fwrite_nolock - mesmo com argumentos de que não preciso ser
inteligente . Total: essa manipulação simples às vezes reduzia o custo de registrar o resultado, que na versão original representava quase metade do tempo. A propósito, no mundo POSIX, existe uma função semelhante -
fwrite_unlocked . De um modo geral, o mesmo vale para o medo. Portanto, com a ajuda do par #define, você pode obter uma solução de plataforma cruzada sem bloqueios desnecessários, se não forem necessários (e isso acontece com bastante frequência).
fwrite, _fwrite_nolock, setvbuf
Vamos abstrair do projeto original e começar a testar um caso específico: gravar um arquivo grande (512 MB) em partes extremamente pequenas - 1 byte. Sistema de teste: AMD Ryzen 7 1700, 16 GB RAM, HDD 3,5 "7200 rpm, cache de 64 MB, Windows 10 1809, o binário foi construído em 32 bits, otimizações incluídas, otimizações incluídas, a biblioteca está vinculada estaticamente.
Amostra para o experimento:
#include <chrono> #include <cstdio> #include <inttypes.h> #include <memory> #ifdef _MSC_VER #define fwrite_unlocked _fwrite_nolock #endif using namespace std::chrono; int main() { std::unique_ptr<FILE, int(*)(FILE*)> file(fopen("test.bin", "wb"), fclose); if (!file) return 1; constexpr size_t TEST_BUFFER_SIZE = 256 * 1024; if (setvbuf(file.get(), nullptr, _IOFBF, TEST_BUFFER_SIZE) != 0) return 2; auto start = steady_clock::now(); const uint8_t b = 77; constexpr size_t TEST_FILE_SIZE = 512 * 1024 * 1024; for (size_t i = 0; i < TEST_FILE_SIZE; ++i) fwrite_unlocked(&b, sizeof(b), 1, file.get()); auto end = steady_clock::now(); auto interval = duration_cast<microseconds>(end - start); printf("Time: %lld\n", interval.count()); return 0; }
As variáveis serão TEST_BUFFER_SIZE e, em alguns casos, substituiremos fwrite_unlocked por fwrite. Vamos começar com o caso de fwrite sem definir explicitamente o tamanho do buffer (comente o setvbuf e o código associado): tempo 27048906 μs, velocidade de gravação - 18,93 Mb / s. Agora defina o tamanho do buffer para 64 Kb: tempo - 25037111 μs, velocidade - 20,44 Mb / s. Agora testamos a operação de _fwrite_nolock sem chamar setvbuf: 7262221 ms, a velocidade é de 70,5 Mb / s!
Em seguida, experimente o tamanho do buffer (setvbuf):
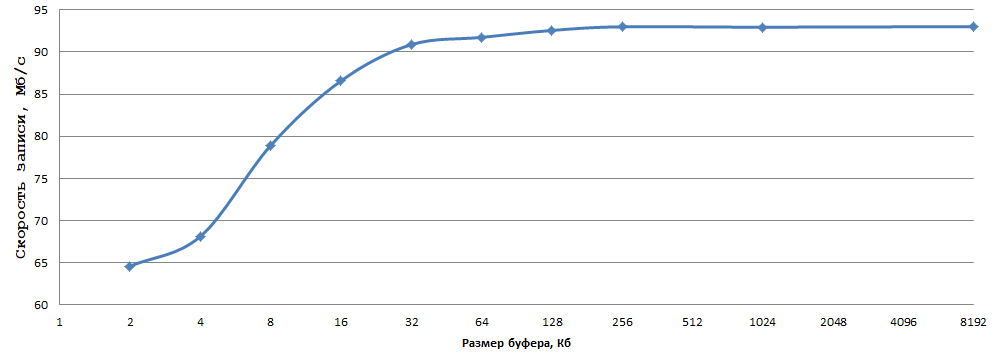
Os dados foram obtidos com média de cinco experimentos; eu estava com preguiça de considerar os erros. Quanto a mim, 93 MB / s ao gravar 1 byte em um disco rígido normal é um resultado muito bom, basta selecionar o tamanho ideal do buffer (no meu caso, 256 KB - à direita) e substituir fwrite por _fwrite_nolock / fwrite_unlocked (em se a segurança da linha não for necessária, é claro).
Da mesma forma com medo em condições semelhantes. Agora vamos ver como estão as coisas no Linux, a configuração de teste é a seguinte: AMD Ryzen 7 1700X, 16 GB de RAM, HDD 3,5 "7200 rpm, cache de 64 MB, OpenSUSE 15 OS, GCC 8.3.1, testaremos o binário x86-64, sistema de arquivos em seção de teste ext4 O resultado de fwrite sem definir explicitamente o tamanho do buffer neste teste é 67,6 Mb / s, ao definir o buffer para 256 Kb, a velocidade aumentou para 69,7 Mb / s. Agora, realizaremos medições semelhantes para fwrite_unlocked - os resultados são 93,5 e 94,6 Mb / s, respectivamente. A variação do tamanho do buffer de 1 KB para 8 MB levou-me às seguintes conclusões: aumentar o buffer aumenta a velocidade de gravação, mas a diferença no meu caso era de apenas 3 Mb / s, não notei nenhuma diferença de velocidade entre o buffer de 64 Kb e 8 Mb. Dos dados recebidos nesta máquina Linux, podemos tirar as seguintes conclusões:
- fwrite_unlocked é mais rápido que fwrite, mas a diferença na velocidade de gravação não é tão grande quanto no Windows
- O tamanho do buffer no Linux não tem um efeito tão significativo na velocidade de gravação através de fwrite / fwrite_unlocked como no Windows
No total, o método proposto é eficaz no Windows, mas também no Linux (embora em menor grau).
Posfácio
O objetivo deste artigo era descrever uma técnica simples e eficaz em muitos casos (não encontrei as funções _fwrite_nolock / fwrite_unlocked anteriormente, elas não são muito populares - mas em vão). Não pretendo ser novo no material, mas espero que o artigo seja útil para a comunidade.