O mais importante para o serviço Yandex.Zen é desenvolver e manter uma plataforma que conecta o público com os autores. Para ser uma plataforma atraente para bons autores, o Zen deve ser capaz de encontrar um público relevante para os canais que escrevem sobre qualquer tópico, incluindo o mais restrito. O chefe do grupo de felicidade dos autores Boris Sharchilev falou sobre o ranking autocêntrico, que seleciona os usuários mais relevantes para os autores. No relatório, você pode descobrir como essa abordagem difere da seleção de itens relevantes - mais populares nos sistemas de recomendação.
Ao equilibrar a classificação centrada no usuário e centrada no usuário, podemos alcançar o equilíbrio certo entre a felicidade do usuário e a felicidade dos autores.
- Colegas, olá pessoal. Meu nome é Borya. Eu lido com a qualidade do ranking no Zen. Estou certo de que este é um dos serviços Yandex mais interessantes, temos um aprendizado de máquina muito legal e, nos próximos 17 minutos, tentarei convencê-lo disso.
O que é Zen? Se bem simples, o Zen é um serviço de recomendação pessoal. Tentamos recomendar aos usuários conteúdo relevante com base no que sabemos sobre os interesses desses usuários. Nosso objetivo de alto nível é que os usuários passem um tempo no Zen. E o que é muito importante é que eles não se arrependam dessa vez.
Nossa forma básica de consumo de conteúdo se parece com isso. Este é um fluxo interminável de recomendações. E aqui está claro que, em princípio, estamos tentando recomendar muito material sobre tópicos muito diferentes. Existem tópicos diferentes: algo sobre negócios, algo sobre humor, até algo sobre fantasia. Ou seja, na fita você encontra artigos educacionais e educacionais, além de artigos mais divertidos. E, claro, personalização. O feed Zen para todos parece diferente - dependendo do interesse do usuário. Além disso, é claro, um pouco de publicidade.

Um ponto muito importante. No começo, quando aparecemos pela primeira vez, éramos um agregador de conteúdo da Internet. Ou seja, percorremos sites existentes, pegamos conteúdo deles e o mostramos ao usuário, dependendo dos interesses. Agora a situação é diferente. Agora, o Zen é uma plataforma de blogs inteira, na qual todos podem criar seu próprio canal, seja um blogueiro famoso ou um autor novato que tenha algo a dizer. Novos autores veem uma tela de boas-vindas tão agradável na qual falamos sobre o serviço - que o próprio Zen selecionará uma audiência e ele só precisará escrever bons materiais.
Agora, a plataforma responde por mais da metade do tráfego total no Zen. E esse número só vai crescer. Entendemos que todos podem classificar o conteúdo existente. Obviamente, faremos o melhor de tudo. Mas nem todos têm conteúdo exclusivo, e acreditamos que essa será nossa vantagem competitiva.

É importante entender que o Zen já é muito grande. De acordo com o Yandex.Radar, no final do ano passado, tínhamos entre 10 e 12 milhões de leitores diários por dia, cerca de 35 milhões de leitores diários, e mesmo de acordo com alguns dados do Yandex.Radar, no ano passado Pela primeira vez, eles foram ao redor do público Yandex.News. Isso significa que estamos criando a Internet com toda a seriedade, temos tarefas muito sérias, existem muitas e realmente esperamos sua ajuda.
Vamos falar sobre os detalhes de como funciona e discutir o que podemos fazer com um estagiário, como podemos ajudar nosso serviço.
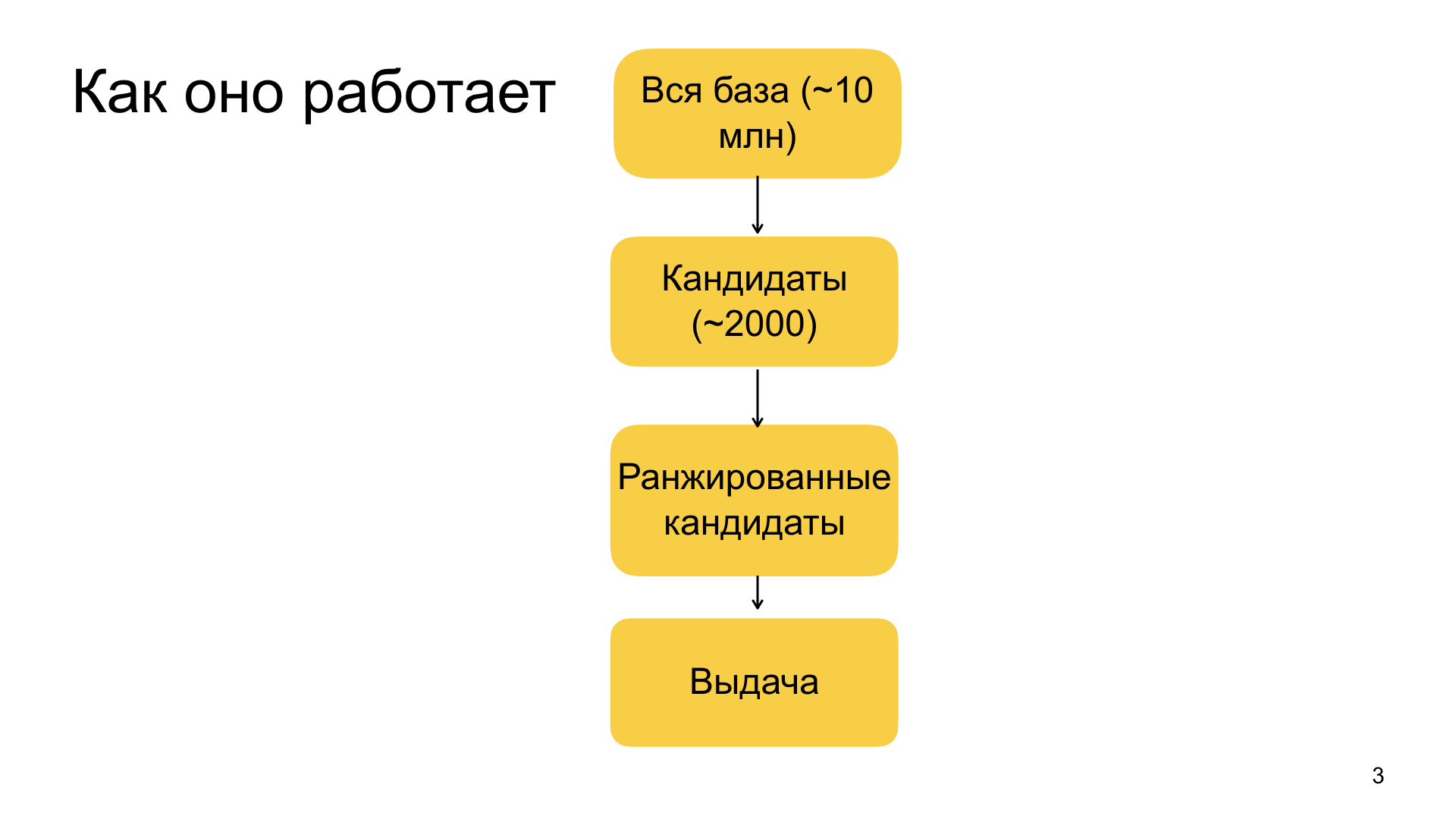
O esboço geral das recomendações que temos é organizado dessa maneira. Tudo começa com nosso grande banco de dados de documentos, a partir do qual selecionamos materiais para recomendações. Consiste em dezenas de milhões de documentos. Além disso, esse banco de dados é constantemente reabastecido - cerca de um milhão de novos documentos chegam diariamente nele. Idealmente, gostaríamos de aplicar toda a nossa máquina de aprendizado de máquina a todas essas dezenas de milhões de documentos pessoalmente para cada usuário e escolher o mais relevante para ele. Infelizmente, isso não funciona na prática, porque o Zen é um serviço que funciona em tempo real. Temos garantias muito rigorosas sobre a rapidez com que estamos prontos para responder, portanto, por razões práticas, somos forçados a restringir a base de dezenas de milhões de documentos a milhares de recomendações em potencial no primeiro estágio, que já podemos classificar completamente com nosso modelo e escolher os mais relevantes. Esse estágio de estreitamento da base de dezenas de milhões para milhares é chamado seleção de candidatos ou classificação fácil.
Quando temos este kit, aplicamos a ele nosso modelo complexo de aprendizado de máquina grande, que no nível superior aumenta o gradiente. Tudo isso sem surpresas, mas temos fatores muito diversos - desde alguns simples que caracterizam, por exemplo, quão relevante o domínio é para o usuário, a fonte, a frequência com que ele visita, clica, deixa comentários, gosta e não gosta. O mesmo acontece com fatores mais complexos, baseados, por exemplo, em recursos de redes neurais. Processamos o texto do artigo, processamos imagens, outras fontes de dados e também usamos esses recursos compostos. Todo esse esquema é bastante complicado, não terei tempo para lhe contar em detalhes.
Depois de classificarmos nossos 2 mil candidatos, selecionamos o topo deles. O tamanho da parte superior depende de quanto precisamos recomendar materiais. É sempre definido de forma diferente. E assim formamos a questão final.
É assim que o circuito fica em um nível alto. Agora vamos falar sobre quais componentes de todo o processo estamos interessados em melhorar.

Acontece que estamos interessados em fazer quase tudo. Existem muitas tarefas. Queremos aumentar a velocidade da entrega de dados para classificação: quanto mais recentes tivermos dados, mais relevantes faremos recomendações. Quero acelerar o serviço: quanto mais rápido trabalhamos, melhor a experiência do usuário. Queremos aumentar a confiabilidade do serviço.
É importante para nós melhorar o ranking. Ou seja, precisamos aplicar novos modelos de aprendizado de máquina e melhorar nossos modelos atuais em outros países. Somos recomendados não apenas na Rússia, mas também em muitos outros países do mundo.
Também queremos levar em consideração a regionalidade e recomendar às pessoas o conteúdo relacionado à sua região.
E é muito importante - precisamos desenvolver nossa plataforma de criação. Este é o nosso futuro, precisamos investir nele. Também há muitas tarefas. Em particular, precisamos encontrar e lançar conteúdo de qualidade. É importante mostrar bons materiais, não lixo. Precisamos ser capazes de classificar novos formatos de conteúdo. Temos não apenas artigos, mas também vídeos curtos e postagens que os usuários assistem diretamente no feed. Todos esses formatos precisam poder ser classificados.
E um ponto muito importante, sobre o qual quero falar um pouco mais detalhadamente em detalhes mais técnicos - é importante que cada autor consiga encontrar um público que seja relevante para ele, mesmo que se trate de autores e tópicos de nicho bonito. Vamos falar com mais detalhes qual é o problema aqui e como o solucionamos.
Vejamos um exemplo.
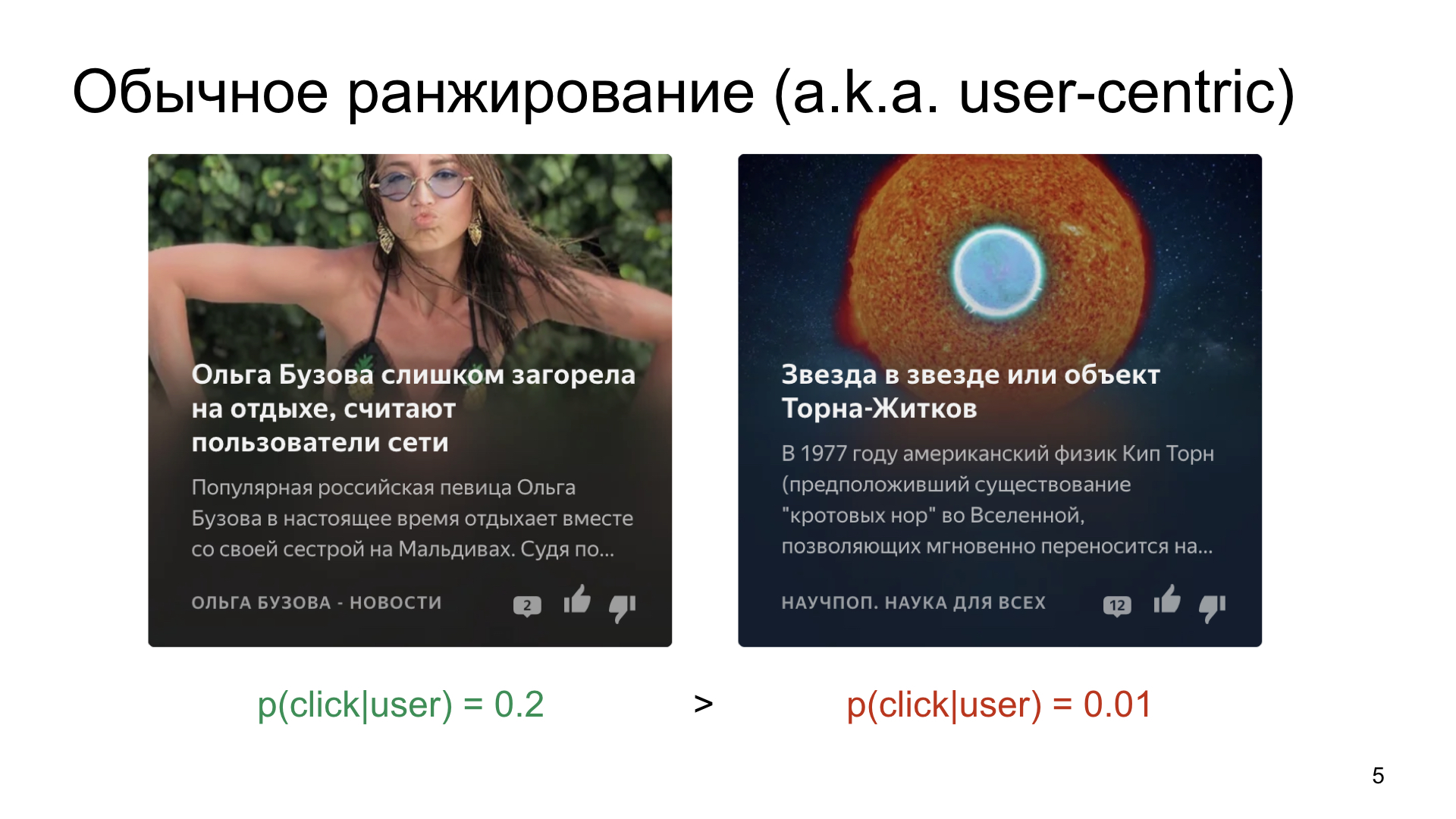
Selecionamos, suponha, dois cartões que queremos mostrar ao usuário.
É assim que o mundo funciona e a maneira como as pessoas trabalham, que há algo mais médio, onde a probabilidade de um clique é em média 20%, e há algo mais nicho, por exemplo, artigos sobre ciência ou espaço.
Se simplesmente classificarmos as cartas de acordo com a probabilidade de um clique, é claro que um conteúdo mais clicável e mais simples coletará um número muito grande de impressões, e mesmo um artigo muito bom sobre ciência não. Claro, não queremos isso. Queremos encontrar públicos-alvo interessados mesmo para canais de nicho.

Por que você quer fazer isso? De fato, existem duas razões. O primeiro é o supermercado. Ou seja, queremos que o Zen seja algum tipo de corte na Internet. Para que tudo o que o usuário possa encontrar e o que ele está interessado na grande Internet seja apresentado no Zen. E para que ele receba o que é interessante para ele.
Os canais científicos têm seu próprio público. Mas existe essa nuance. Se os amantes da ciência mostram ciência e conteúdo popular, é mais provável que cliquem nela do que na ciência. Mas se você mostrar apenas ciência, eles também clicarão em ciência e nem se arrependerão. A questão é como encontrar essas pessoas e como exibir conteúdo, focando não no usuário, mas no autor.

Como fazer isso? A fórmula de classificação usual, que prevê a probabilidade de cliques, não nos ajudará aqui, porque, em média, mais artigos de nicho perderão. Mas você pode seguir o outro caminho - alocar uma cota e, de maneira mais ou menos uniforme, dar impressões aos autores, dar a eles uma espécie de garantia mínima. Isso pode ser feito e isso tornará os autores um pouco mais felizes, mas, infelizmente, isso deixará nossos usuários menos felizes. Os usuários clicam menos, ficam mais chateados e saem. Claro, não queremos isso.
Como estar aqui?
Pensamos por um longo tempo e criamos um novo conceito. Nós o chamamos de classificações ou impressões autocêntricas para o autor.
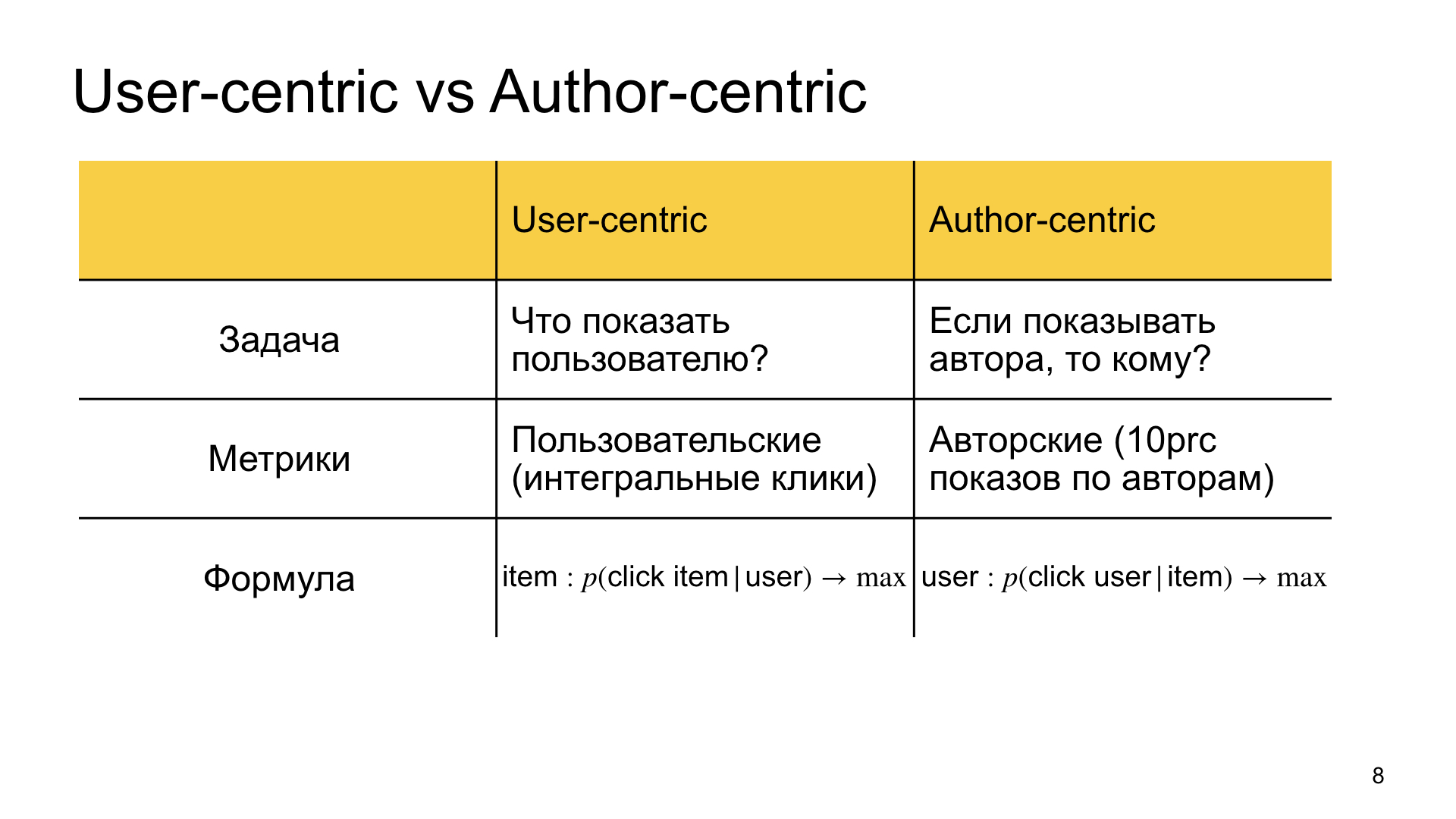
Qual é o nosso objetivo na classificação regular, a que chamamos usercêntrico? Encontre o material que é mais relevante para o usuário. Respondemos à pergunta sobre o que mostrar ao usuário.
No ranking autocêntrico, meio que anulamos a declaração do problema e dizemos que queremos mostrar esse autor, e a pergunta é para quem ele deve ser mostrado, para quem ele é mais relevante. Daí a diferença nas métricas. No primeiro caso, estamos mais interessados em métricas personalizadas, ou seja, cliques integrais, tempo integral no Zen e assim por diante. No segundo caso, estamos interessados nas chamadas métricas de autor. Por exemplo, medimos o quão bem o Zen vive, por exemplo, 10% dos autores. Se eles vivem bem o suficiente, todos os demais também são felizes.

Como fazemos isso? Suponha que tenhamos a fórmula de classificação usual. Por uma questão de simplicidade, suponha que ele preveja a probabilidade de um usuário clicar em um determinado item, em um determinado cartão. O que vamos fazer? Agora vamos corrigi-lo para cada artigo e aplicar nosso modelo para este artigo, idealmente - para todos os usuários, na prática - para algum tipo de amostra de usuário. E construiremos uma distribuição de nossas pontuações, ou seja, estimativas da probabilidade de clicar em um artigo, para cada artigo pelos usuários. Agora, para cada artigo, temos uma distribuição como a do gráfico (slide acima - aprox. Ed.). Depois disso, classificaremos os artigos para o usuário e selecionaremos o topo não apenas pela probabilidade de um clique, mas também pelo percentil em que esse usuário se enquadra neste artigo. Ou seja, estimamos a probabilidade de um clique, vemos onde o usuário se enquadra nessa distribuição e organizamos por esse valor.

Aqui temos as mesmas duas cartas, uma delas é mais clicável, 20% e a outra - menos de 1%. Agora, se você escolher um usuário específico, é possível que ele tenha uma chance de clicar em um cartão mais popular do que em um cartão menos popular, por exemplo, 10% versus 3%. Mas como a probabilidade média de um clique em um cartão popular é de 20% e o usuário tem 10%, ele é, em média, menos relevante para esta publicação do que o usuário Zen comum. E em outra situação, o oposto: ele tem 3% de chance de clicar, mas o artigo médio tem 1%. Portanto, é um público médio mais relevante para o artigo do que outros usuários do Zen. Portanto, a principal ideia aqui é que, mesmo que a probabilidade de um clique em um artigo seja menor, com a ajuda de uma estrutura, temos a chance de mostrar um artigo menos popular se o usuário estiver no núcleo mais confiável desta publicação.

Se os usuários chegarem até nós de maneira mais ou menos uniforme, a pontuação fornecida pela classificação, ou seja, o percentil em que cada usuário chega, será distribuída igualmente entre os usuários. Isso significa que, se todos os artigos forem classificados dessa maneira, todos eles coletarão mais ou menos o mesmo número de impressões. Não haverá emissões de dezenas de milhões de impressões em comparação com as 10 impressões de alguns cartões menos relevantes. Assim, equilibrando a classificação centrada no usuário e centrada no usuário, podemos alcançar a proporção de felicidade do usuário e do autor que consideramos correta.
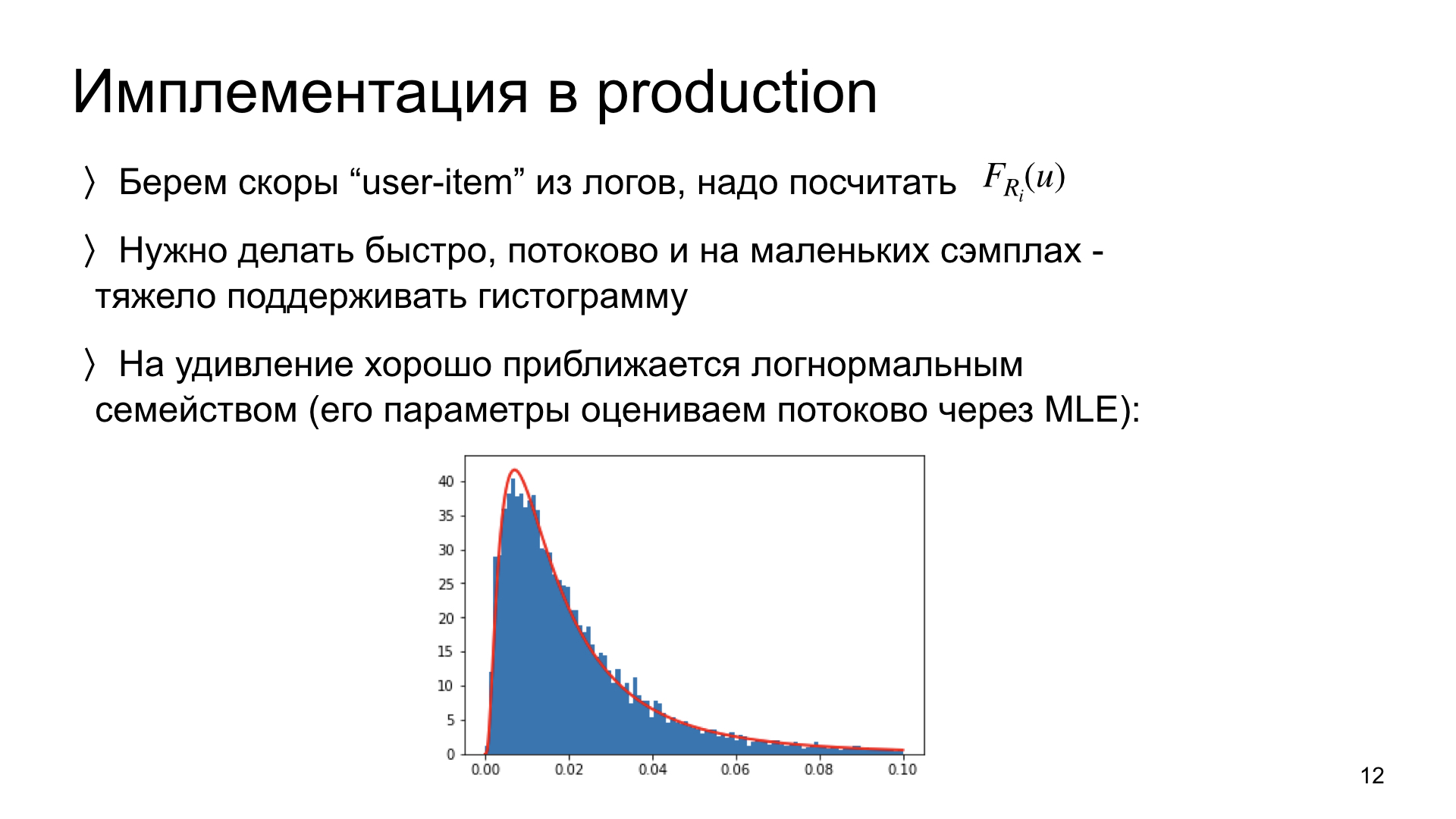
Algumas palavras sobre como implementamos isso na produção. Precisamos examinar nossos logs e calcular a distribuição de cada artigo a partir deles. Uma limitação importante: precisamos ser capazes de fazer isso, primeiro, rápido e, em segundo lugar, no modo de streaming. Ou seja, idealmente, para atualizar a estimativa de distribuição para novos dados, precisamos ter na memória não todos os dados anteriores, mas apenas a estimativa atual. Esse sistema é escalável, esse esquema funciona. Idealmente, precisamos ser capazes de fazer isso em pequenos dados. Se algum artigo tiver apenas 300 impressões, será necessário estimar adequadamente a distribuição para esse número de observações.
Realizamos experimentos e descobrimos que essas distribuições de escores são surpreendentemente próximas das distribuições log-normais. Ou seja, esta é uma observação empírica. E se sim, então, em vez de estimar todo o histograma da distribuição não parametricamente, podemos avaliar apenas dois parâmetros dessa distribuição. E podemos fazer isso no fluxo, usando apenas a estimativa de parâmetros atual e novas observações. Esse esquema é muito rápido e funciona muito bem. Agora ela está em produção conosco.
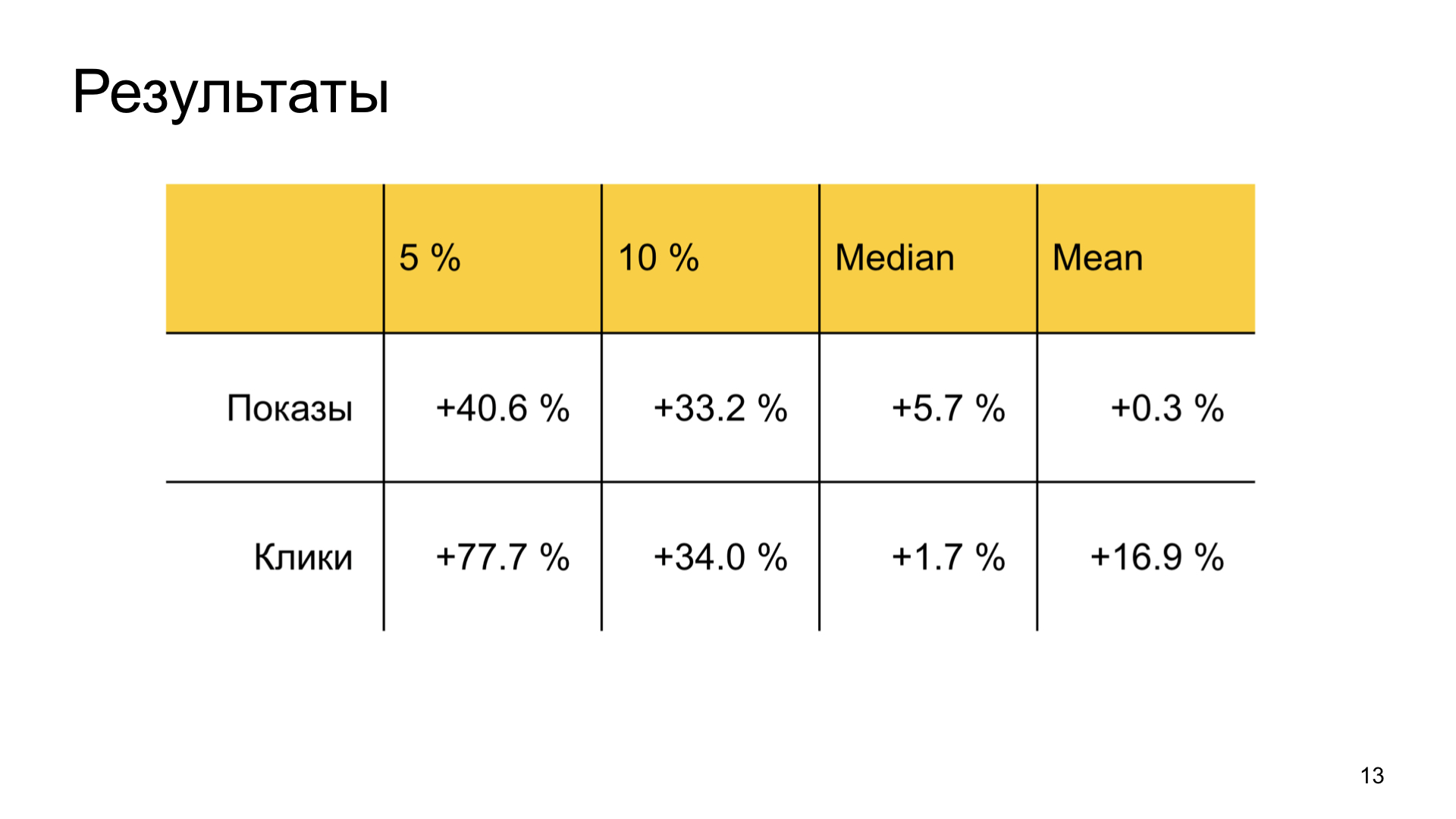
Os resultados também são bons. Aumentamos bastante a felicidade de bons autores negligenciados no Zen e não desperdiçamos métricas comuns de usuário. Ou seja, a tarefa de negócios é totalmente realizada.
Agora mostrei um dos exemplos de tarefas com as quais podemos lidar. Obviamente, existem muitas dessas tarefas e, com cada uma delas, precisamos da sua ajuda. Realmente esperamos que você queira
trabalhar conosco . No final, vou dizer algumas palavras sobre o que esperamos dos estagiários e o que não esperamos deles. Do estagiário, esperamos a coisa mais importante - a capacidade de escrever código. Não temos cientistas puros no serviço. Somos todos engenheiros de ML, eles devem ser capazes de executar todo o ciclo de tarefas. Eles devem ser capazes e implementar sua solução na produção e aplicar o ML. Ou seja, esperamos que você possa escrever código em um nível básico, entender as abordagens, conhecer os algoritmos, estruturas de dados e o básico do aprendizado de máquina.
O que não esperamos dos estagiários? Antes de tudo, não esperamos um conhecimento profundo de nenhuma linguagem ou estrutura. Ou seja, se você não sabe como as corotinas funcionam no Python - tudo bem, ensinaremos tudo. E não esperamos muita experiência de você. Esperamos conhecimento de você, um desejo de trabalhar. Se não houver experiência, tudo bem. Vamos ensinar tudo, e tudo ficará bem. Obrigada