Para quem tem preguiça de ler tudo: é sugerida uma refutação de sete mitos populares, que no campo da pesquisa em aprendizado de máquina é frequentemente considerada verdadeira a partir de fevereiro de 2019. Este artigo está disponível no
site do ArXiv em formato pdf [em inglês].
Mito 1: TensorFlow é uma biblioteca de tensores.
Mito 2: Os bancos de dados de imagens refletem fotos reais encontradas na natureza.
Mito 3: Os pesquisadores do MO não usam kits de teste para testar.
Mito 4: O treinamento em rede neural usa todos os dados de entrada.
Mito 5: A normalização de lotes é necessária para treinar redes residuais muito profundas.
Mito 6: Redes com atenção são melhores que convolução.
Mito 7: Mapas de significância são uma maneira confiável de interpretar redes neurais.
E agora para os detalhes.
Mito 1: TensorFlow é uma biblioteca de tensores
De fato, esta é uma biblioteca para trabalhar com matrizes, e essa diferença é muito significativa.
Em
Computação Derivadas de Ordem Superior de Expressões Matriciais e de Tensores. Laue et al. Os autores do
NeurIPS 2018 demonstram que sua biblioteca de diferenciação automática, baseada em cálculo de tensor real, possui árvores de expressão muito mais compactas. O fato é que o cálculo do tensor usa notação de índice, o que permite trabalhar igualmente com os modos direto e reverso.
A numeração de matrizes oculta os índices de conveniência da notação, e é por isso que as árvores de expressão de diferenciação automática geralmente se tornam muito complexas.
Considere a multiplicação da matriz C = AB. Nós temos
para o modo direto e
pelo contrário. Para executar corretamente a multiplicação, é necessário observar rigorosamente a ordem e o uso da hifenização. Do ponto de vista da gravação, isso parece confuso para uma pessoa envolvida no MO, mas do ponto de vista dos cálculos, essa é uma carga extra para o programa.
Outro exemplo, menos trivial: c = det (A). Nós temos
para o modo direto e
pelo contrário. Nesse caso, é obviamente impossível usar a árvore de expressão para os dois modos, uma vez que eles consistem em operadores diferentes.
Em geral, a maneira como o TensorFlow e outras bibliotecas (por exemplo, Mathematica, Maple, Sage, SimPy, ADOL-C, TAPENADE, TensorFlow, Theano, PyTorch, HIPS autograd) implementaram diferenciação automática, o que leva ao fato de que, direta e reversa Árvores de expressão diferentes e ineficazes são construídas no modo. A numeração do tensor contorna esses problemas devido à comutatividade da multiplicação devido à notação do índice. Para detalhes sobre como isso funciona, consulte o artigo científico.
Os autores testaram seu método realizando diferenciação automática do regime reverso, também conhecido como propagação reversa, em três tarefas diferentes e mediram o tempo necessário para calcular os hessianos.

No primeiro problema, a função quadrática x
T Ax foi otimizada. No segundo, a regressão logística foi calculada, na fatoração da terceira matriz.
Na CPU, seu método acabou sendo duas ordens de magnitude mais rápido do que bibliotecas populares como TensorFlow, Theano, PyTorch e HIPS autograd.
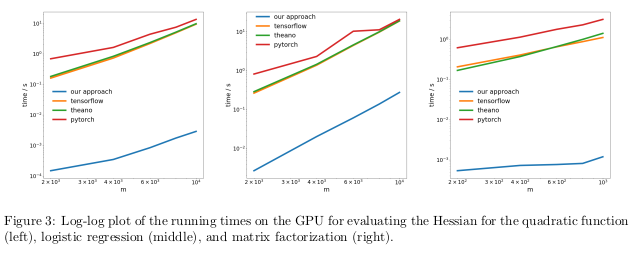
Na GPU, eles observaram uma aceleração ainda maior, em até três ordens de magnitude.
As consequências:Computar derivadas para funções de segunda ordem ou superior usando as bibliotecas atuais de aprendizado profundo é muito caro do ponto de vista computacional. Isso inclui o cálculo de tensores gerais de quarta ordem, como Hessians (por exemplo, na MAML e na otimização de segunda ordem de Newton). Felizmente, as fórmulas quadráticas são raras no aprendizado profundo. No entanto, eles são freqüentemente encontrados no aprendizado de máquina “clássico” -
SVM , método dos mínimos quadrados, LASSO, processos gaussianos etc.
Mito 2: Os bancos de dados de imagens refletem fotos do mundo real
Muitas pessoas gostam de pensar que as redes neurais aprenderam a reconhecer objetos melhor do que as pessoas. Isto não é verdade. Eles podem estar à frente das pessoas com base em imagens selecionadas, por exemplo, ImageNet, mas no caso de reconhecimento de objetos de fotos reais da vida comum, eles definitivamente não serão capazes de ultrapassar um adulto comum. Isso ocorre porque a seleção de imagens nos conjuntos de dados atuais não coincide com a seleção de todas as imagens possíveis naturalmente encontradas na realidade.
Em um trabalho bastante antigo, Não
Verificado, Viés no Viés do Conjunto de Dados. Torralba e Efros. CVPR 2011. , Os autores propuseram estudar as distorções associadas a um conjunto de imagens em doze bancos de dados populares, descobrindo se é possível treinar o classificador para determinar o conjunto de dados do qual essa imagem foi obtida.

As chances de adivinhar acidentalmente o conjunto de dados correto são de 1/12 ± 8%, enquanto os próprios cientistas lidaram com a tarefa com uma taxa de sucesso> 75%.
Eles treinaram o SVM em um
histograma de gradiente direcional (HOG) e descobriram que o classificador concluiu a tarefa em 39% dos casos, o que excede significativamente os acertos aleatórios. Se repetíssemos esse experimento hoje, com as redes neurais mais avançadas, certamente veríamos um aumento na precisão do classificador.
Se os bancos de dados de imagens exibissem corretamente as imagens reais do mundo real, não precisaríamos determinar de qual conjunto de dados uma determinada imagem é originada.

No entanto, existem características nos dados que tornam cada conjunto de imagens diferente dos outros. O ImageNet possui muitos carros de corrida com pouca probabilidade de descrever o carro médio "teórico" como um todo.

Os autores também determinaram o valor de cada conjunto de dados medindo o quão bem um classificador treinado em um conjunto trabalha com imagens de outros conjuntos. De acordo com essa métrica, os bancos de dados LabelMe e ImageNet foram os menos tendenciosos, tendo recebido uma classificação de 0,58 usando o método de “cesta de moedas”. Todos os valores acabaram sendo inferiores à unidade, o que significa que o treinamento em um conjunto de dados diferente sempre leva a um desempenho ruim. Em um mundo ideal sem conjuntos tendenciosos, alguns números deveriam ter excedido um.
Os autores concluíram pessimista:
Então, qual é o valor dos conjuntos de dados existentes para algoritmos de treinamento projetados para o mundo real? A resposta resultante pode ser descrita como "melhor que nada, mas não muito".
Mito 3: Pesquisadores do MO não usam kits de teste para testar
No livro de aprendizado de máquina, somos ensinados a dividir o conjunto de dados em treinamento, avaliação e verificação. A eficácia do modelo, treinada no conjunto de treinamento e avaliada na avaliação, ajuda a pessoa envolvida no MO a ajustar o modelo para maximizar a eficiência em seu uso real. O conjunto de testes não precisa ser tocado até que a pessoa termine o ajuste para fornecer uma avaliação imparcial da real eficácia do modelo no mundo real. Se uma pessoa trapaceia usando um conjunto de testes nos estágios de treinamento ou avaliação, o modelo corre o risco de se tornar muito adaptado para um conjunto de dados específico.
No mundo hipercompetitivo da pesquisa em MO, novos algoritmos e modelos são frequentemente julgados pela eficácia de seu trabalho com dados de verificação. Portanto, não faz sentido para os pesquisadores escrever ou publicar trabalhos descrevendo métodos que funcionam mal com conjuntos de dados de teste. E isso, em essência, significa que a comunidade da região de Moscou como um todo usa um conjunto de testes para avaliação.
Quais são as consequências desse golpe?

Autores dos
Classificadores CIFAR-10 generalizam para CIFAR-10? Recht et al. O ArXiv 2018 investigou esse problema criando um novo conjunto de testes para o CIFAR-10. Para fazer isso, eles fizeram uma seleção de imagens da Tiny Images.
Eles escolheram o CIFAR-10 porque é um dos conjuntos de dados mais usados no MO, o segundo conjunto mais popular no NeurIPS 2017 (depois do MNIST). O processo de criação de um conjunto de dados para o CIFAR-10 também é bem descrito e transparente; no grande banco de dados da Tiny Images existem muitos rótulos detalhados, para que você possa executar um novo conjunto de testes, minimizando a mudança de distribuição.

Eles descobriram que um grande número de modelos diferentes de redes neurais no novo conjunto de testes mostrou uma queda significativa na precisão (4% - 15%). No entanto, a classificação de desempenho relativo de cada modelo permaneceu bastante estável.
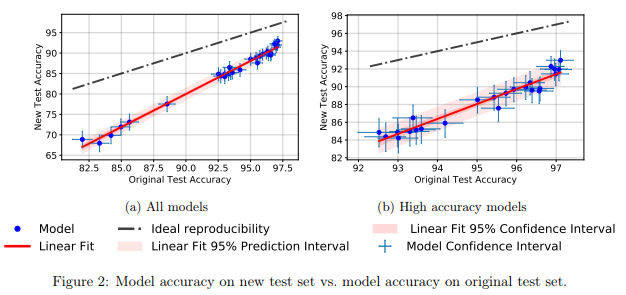
Em geral, os modelos com melhor desempenho mostraram uma queda de precisão mais baixa em comparação aos modelos com pior desempenho. Isso é bom porque segue-se que a perda de generalização do modelo devido a trapaça, pelo menos no caso do CIFAR-10, diminui à medida que a comunidade inventa métodos e modelos aprimorados de MO.
Mito 4: O treinamento em rede neural usa toda a entrada
É geralmente aceito que os
dados são um novo óleo e, quanto mais dados tivermos, melhor poderemos treinar modelos de aprendizado profundo que agora são ineficientes em termos de amostra e superparametrizados.
Em
um estudo empírico de exemplo de esquecimento durante o aprendizado em rede neural profunda. Toneva et al. Os autores do
ICLR 2019 demonstram redundância significativa em vários conjuntos comuns de pequenas imagens. Surpreendentemente, 30% dos dados do CIFAR-10 podem ser simplesmente removidos sem alterar a precisão da verificação em uma quantidade significativa.
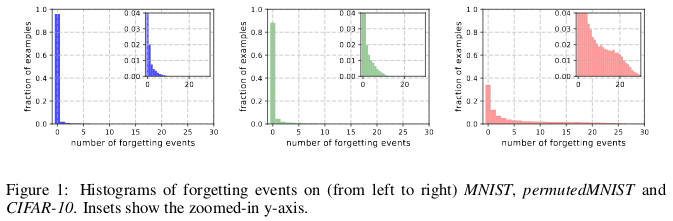 Histórias de esquecimento do MNIST (da esquerda para a direita), permutadas pelo NIST e pelo CIFAR-10.
Histórias de esquecimento do MNIST (da esquerda para a direita), permutadas pelo NIST e pelo CIFAR-10.O esquecimento acontece quando uma rede neural classifica incorretamente uma imagem no tempo t + 1, enquanto no tempo t foi capaz de classificar uma imagem corretamente. O fluxo de tempo é medido pelas atualizações do SGD. Para rastrear o esquecimento, os autores lançaram sua rede neural em um pequeno conjunto de dados após cada atualização do SGD, e não em todos os exemplos disponíveis no banco de dados. Exemplos que não estão sujeitos a esquecimento são chamados de exemplos inesquecíveis.
Eles descobriram que 91,7% MNIST, 75,3% permutaram MIST, 31,3% CIFAR-10 e 7,62% CIFAR-100 são exemplos inesquecíveis. Isso é intuitivamente compreensível, pois aumentar a diversidade e a complexidade do conjunto de dados deve fazer a rede neural esquecer mais exemplos.

Exemplos esquecidos parecem exibir características mais raras e estranhas em comparação com os inesquecíveis. Os autores os comparam com vetores de suporte no SVM, pois parecem traçar o contorno dos limites da decisão.
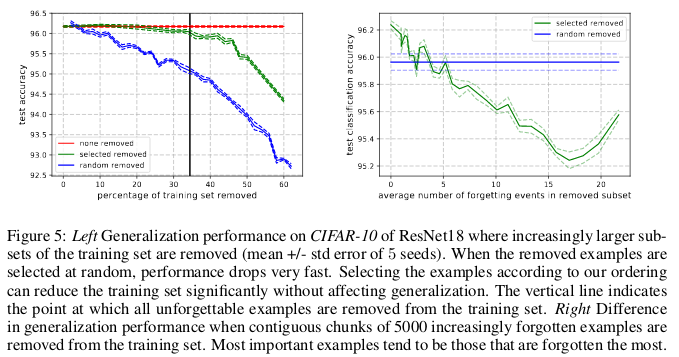
Exemplos inesquecíveis, por sua vez, codificam informações principalmente redundantes. Se ordenarmos os exemplos pelo grau de inesquecibilidade, podemos compactar o conjunto de dados excluindo os mais inesquecíveis.
30% dos dados do CIFAR-10 podem ser excluídos sem afetar a precisão das verificações, e a exclusão de 35% dos dados leva a uma leve queda na precisão das verificações em 0,2%. Se você selecionar 30% dos dados aleatoriamente, excluí-los resultará em uma perda significativa na precisão da verificação de 1%.
Da mesma forma, 8% dos dados podem ser removidos do CIFAR-100 sem uma queda na precisão da validação.
Esses resultados mostram que há redundância significativa nos dados para o treinamento de redes neurais, semelhante ao treinamento SVM, em que vetores não suportados podem ser removidos sem afetar a decisão do modelo.
As consequências:Se pudermos determinar quais dados são inesquecíveis antes de iniciar o treinamento, podemos economizar espaço excluindo-os e tempo sem usá-los ao treinar uma rede neural.
Mito 5: A normalização de lotes é necessária para treinar redes residuais muito profundas.
Por um longo tempo, acreditava-se que “treinar uma rede neural profunda para otimização direta apenas para um propósito controlado (por exemplo, a probabilidade logarítmica de uma classificação correta) usando descida gradiente, começando com parâmetros aleatórios, não funciona bem”.
A pilha de métodos engenhosos de inicialização aleatória, funções de ativação, técnicas de otimização e outras inovações, como conexões residuais, que surgiram desde então, facilitaram o treinamento de redes neurais profundas usando o método de descida gradiente.
Mas um verdadeiro avanço ocorreu após a introdução da normalização de lotes (e outras técnicas de normalização seqüencial), limitando o tamanho das ativações para cada camada da rede, a fim de eliminar o problema de gradientes de desaparecimento e explosivos.
Em um trabalho recente,
Inicialização do Fixup: aprendizado residual sem normalização. Zhang et al. O ICLR 2019 mostrou que é possível treinar uma rede com 10.000 camadas usando SGD puro sem aplicar nenhuma normalização.

Os autores compararam o treinamento de rede neural residual para diferentes profundidades no CIFAR-10 e descobriram que, embora os métodos padrão de inicialização não funcionassem para 100 camadas, os métodos de normalização de correção e lote tiveram sucesso com 10.000 camadas.

Eles realizaram uma análise teórica e mostraram que “a normalização do gradiente de certas camadas é limitada pelo número infinitamente crescente de uma rede profunda”, o que é um problema de gradientes explosivos. Para evitar isso, o Foxup é usado, cuja ideia principal é dimensionar os pesos em camadas m para cada um dos ramos residuais L pelo número de vezes que depende de me L.

O Fixup ajudou a treinar uma rede residual profunda com 110 camadas no CIFAR-10, com uma alta velocidade de aprendizado comparável ao comportamento de uma rede de arquitetura semelhante treinada usando a normalização de lotes.
Os autores mostraram ainda resultados de testes semelhantes usando o Fixup na rede sem normalização, trabalhando com o banco de dados ImageNet e com traduções do inglês para o alemão.
Mito 6: Redes com atenção são melhores que redes convolucionais.
A ideia de que os mecanismos de “atenção” são superiores às redes neurais convolucionais está ganhando popularidade na comunidade de pesquisadores do MO. No trabalho de
Vaswani e colegas , observou-se que "o custo computacional de convoluções destacáveis é igual à combinação de uma camada de auto-atenção e uma camada pontual de feed-forward".
Mesmo redes avançadas de geração competitiva mostram a vantagem da atenção própria em relação à convolução padrão ao modelar dependências de longo alcance.
Os colaboradores
prestam menos atenção nas convoluções leves e dinâmicas. Wu et al. O ICLR 2019 lança dúvidas sobre a eficiência paramétrica e a eficácia da atenção pessoal ao modelar dependências de longo alcance e oferece novas opções de convolução, parcialmente inspiradas na atenção pessoal, mais eficazes em termos de parâmetros.
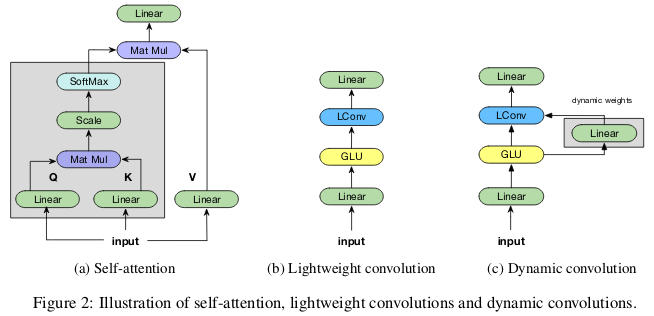
As convoluções “leves” são separáveis em profundidade, normalizadas softmax na dimensão temporal, separadas pelo peso na dimensão do canal e reutilizam os mesmos pesos a cada etapa do tempo (como redes neurais recorrentes). As convoluções dinâmicas são convoluções leves que usam pesos diferentes a cada etapa do tempo.
Esses truques tornam as convoluções leves e dinâmicas várias ordens de magnitude mais efetivas que as convoluções indivisíveis padrão.

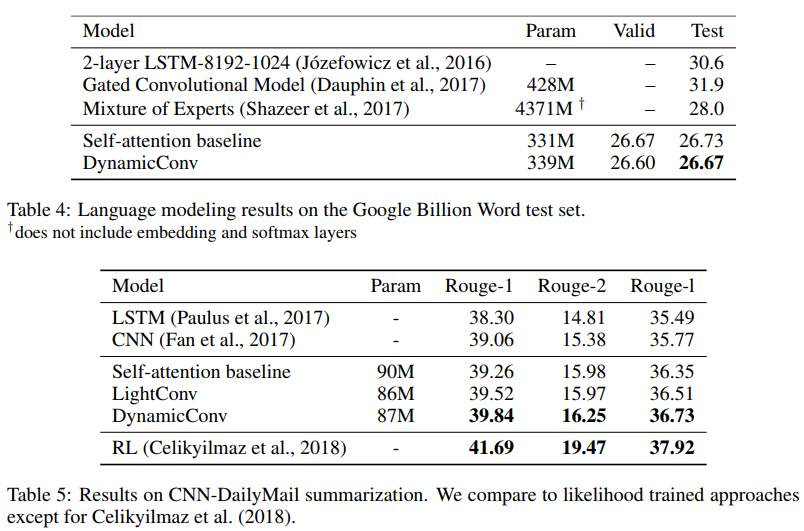
Os autores mostram que essas novas convoluções correspondem ou excedem redes auto-absorventes em tradução automática, modelagem de linguagem, problemas abstratos de soma, usando os mesmos ou menos parâmetros.
Mito 7: Cartões de significado - uma maneira confiável de interpretar redes neurais
Embora exista uma opinião de que as redes neurais são caixas pretas, houve muitas tentativas para interpretá-las. Os mais populares são mapas de significância ou outros métodos semelhantes que atribuem avaliações de importância a características ou exemplos de treinamento.
É tentador concluir que uma determinada imagem foi classificada de uma certa maneira devido a certas partes da imagem que são significativas para a rede neural. Para calcular mapas de significância, existem vários métodos que costumam usar a ativação de redes neurais em uma determinada imagem e os gradientes que passam pela rede.
Na
interpretação de redes neurais é frágil. Ghorbani et al. Os autores da
AAAI 2019 mostram que podem introduzir uma mudança ilusória na imagem, o que, no entanto, distorcerá seu mapa de significância.

A rede neural determina a borboleta monarca não pelo padrão em suas asas, mas por causa da presença de folhas verdes sem importância no fundo da foto.

Imagens multidimensionais costumam estar mais próximas dos limites de decisão feitos por redes neurais profundas, daí a sua sensibilidade a ataques adversos. E se os ataques competitivos movem as imagens além dos limites da solução, os ataques interpretativos competitivos os deslocam ao longo dos limites da solução sem sair do território da mesma solução.
O método básico desenvolvido pelos autores é uma modificação do método Goodfello de marcação rápida por gradiente, que foi um dos primeiros métodos bem-sucedidos de ataques competitivos. Pode-se supor que outros ataques novos e mais complexos também possam ser usados para ataques à interpretação de redes neurais.
As consequências:Devido à crescente disseminação do aprendizado profundo em áreas críticas de aplicação como a imagem médica, é importante abordar cuidadosamente a interpretação das decisões tomadas pelas redes neurais. Por exemplo, embora fosse ótimo se a rede neural convolucional pudesse reconhecer o ponto na imagem da RM como um tumor maligno, esses resultados não devem ser confiáveis se forem baseados em métodos de interpretação não confiáveis.