
Olá pessoal! Meu nome é Sergey Kostanbaev, na Bolsa estou desenvolvendo o núcleo do sistema de negociação.
Quando a Bolsa de Nova York é exibida nos filmes de Hollywood, ela sempre se parece com isso: multidões gritando alguma coisa, agitando papel, há um caos completo. Nunca tivemos isso na Bolsa de Moscou, porque quase desde o início, as negociações eram realizadas eletronicamente e são baseadas em duas plataformas principais - Spectra (mercado de derivativos) e ASTS (mercados de moeda, ações e dinheiro). E hoje quero falar sobre a evolução da arquitetura do sistema de negociação e compensação ASTS, sobre várias soluções e descobertas. A história será longa, então tive que dividi-la em duas partes.
Somos uma das poucas trocas no mundo a negociar ativos de todas as classes e fornecer uma gama completa de serviços de troca. Por exemplo, no ano passado, ocupamos o segundo lugar no mundo em termos de volume de negociação de títulos, 25º lugar entre todas as bolsas de valores, 13º lugar em capitalização entre as bolsas públicas.
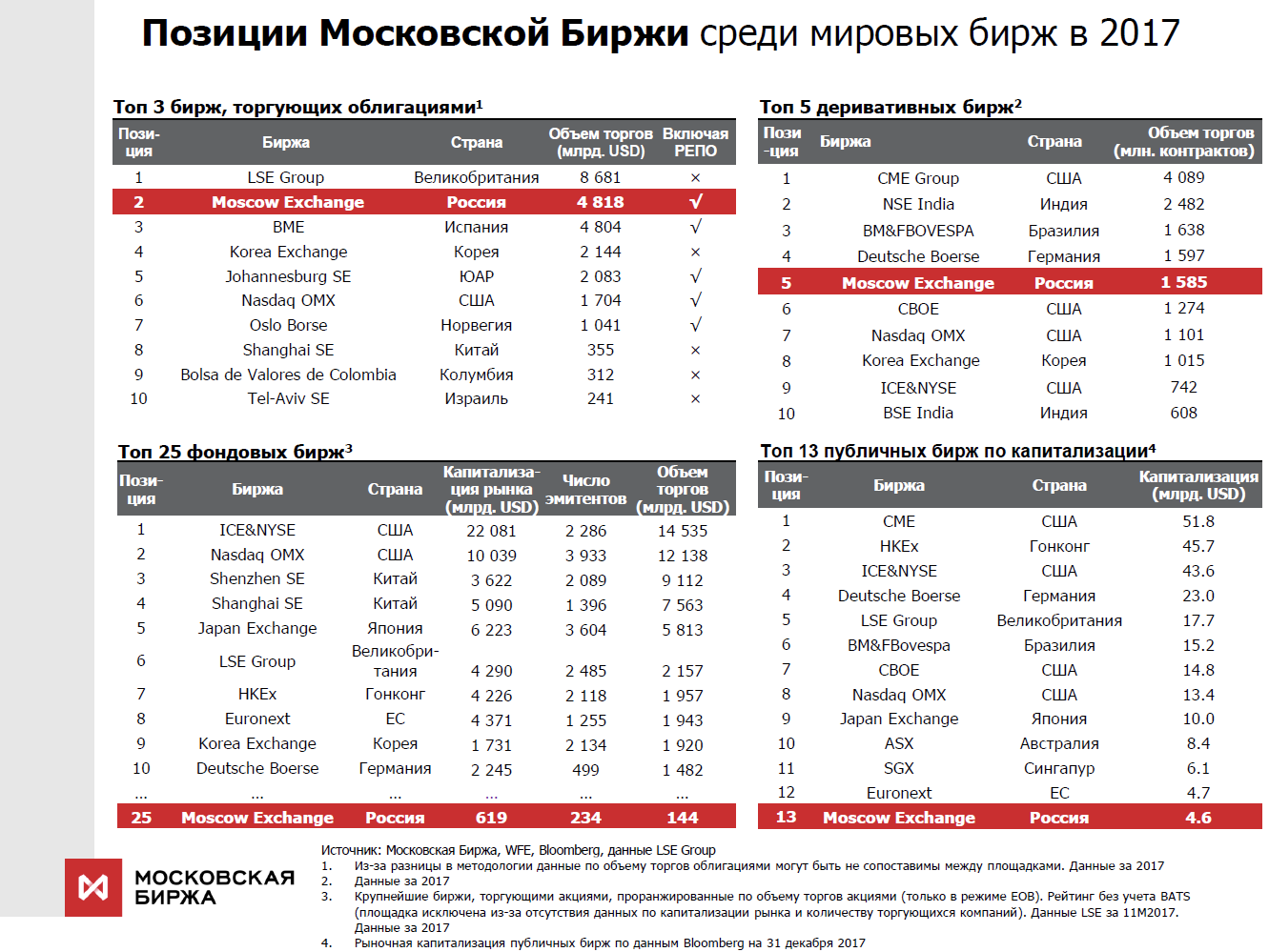
Para licitantes profissionais, parâmetros como tempo de resposta, estabilidade da distribuição do tempo (instabilidade) e confiabilidade de todo o complexo são críticos. Atualmente, processamos dezenas de milhões de transações por dia. O processamento de cada transação pelo núcleo do sistema leva dezenas de microssegundos. É claro que, com as operadoras de celular no Ano Novo ou nos mecanismos de pesquisa, a carga em si é maior que a nossa, mas em termos de carga, juntamente com as características acima, poucas podem se comparar conosco, como me parece. Ao mesmo tempo, é importante para nós que o sistema não fique lento por um segundo, funcione absolutamente estável e todos os usuários estejam em pé de igualdade.
Um pouco de história
Em 1994, o sistema ASTS australiano foi lançado na Bolsa de Câmbio Interbancária de Moscou (MICEX) e, a partir deste momento, você pode contar a história russa do comércio eletrônico. Em 1998, a arquitetura da bolsa foi modernizada para a introdução do comércio pela Internet. Desde então, a velocidade de introdução de novas soluções e mudanças arquiteturais em todos os sistemas e subsistemas está apenas ganhando força.
Naqueles anos, o sistema de troca trabalhava com hardware de ponta - os servidores HP Superdome 9000 altamente confiáveis (criados na
arquitetura PA-RISC ), que duplicavam absolutamente tudo: os subsistemas de E / S, a rede e a RAM (na verdade, havia um array RAID da RAM ), processadores (hot swapping suportado). Foi possível alterar qualquer componente do servidor sem parar a máquina. Contamos com esses dispositivos, considerados virtualmente sem problemas. O sistema operacional era semelhante ao Unix, HP UX.
Mas desde 2010, um fenômeno como o comércio de alta frequência (HFT), ou comércio de alta frequência, simplesmente, robôs de troca, surgiu. Em apenas 2,5 anos, a carga em nossos servidores aumentou 140 vezes.
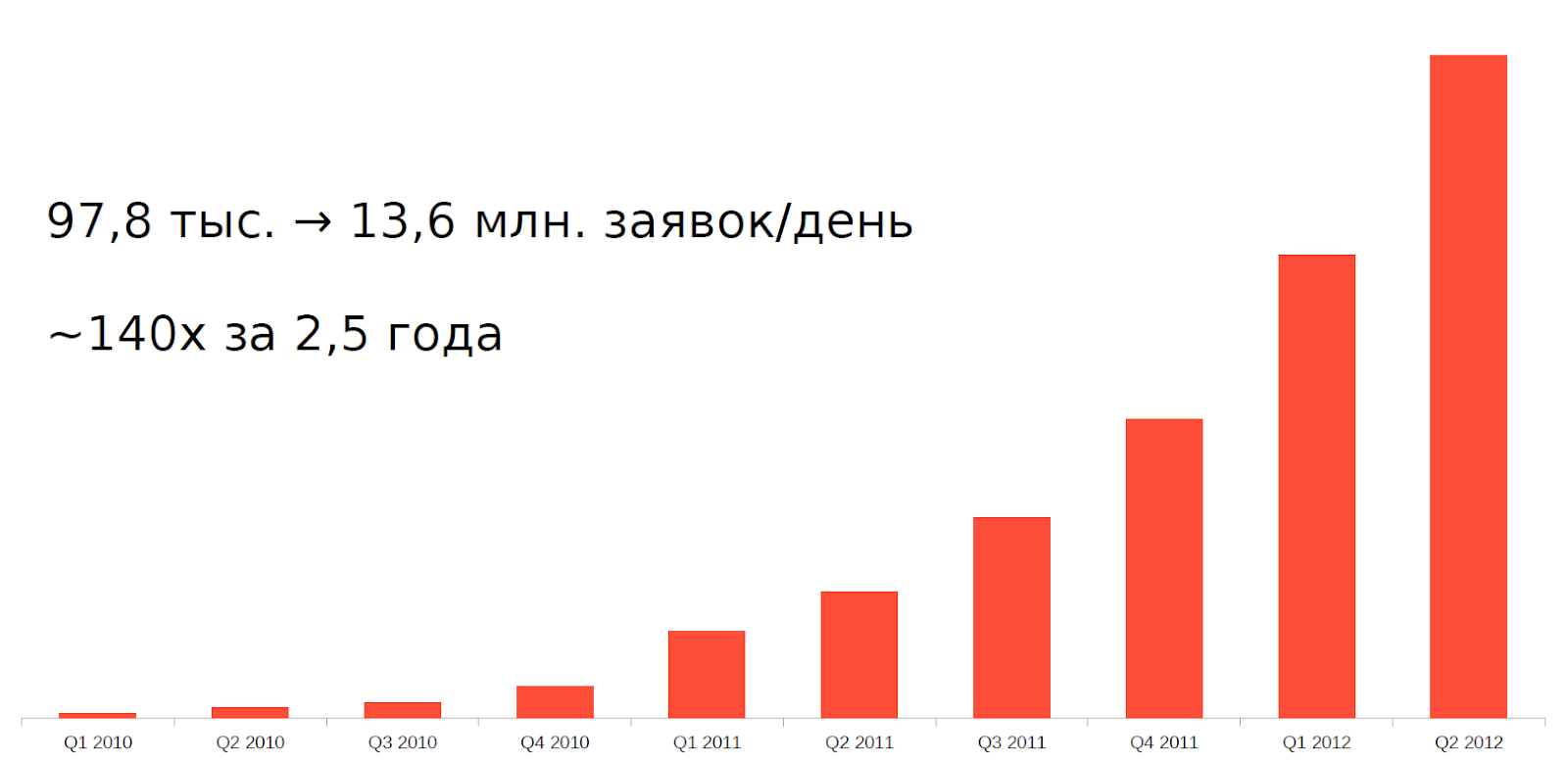
Suportar tal carga com a arquitetura e o equipamento antigos era impossível. Era necessário se adaptar de alguma forma.
Iniciar
As solicitações para o sistema de troca podem ser divididas em dois tipos:
- Transações Se você deseja comprar dólares, ações ou qualquer outra coisa, envie uma transação para o sistema de negociação e obtenha uma resposta sobre o sucesso.
- Pedidos de informação. Se você deseja saber o preço atual, consulte a carteira de pedidos ou os índices e envie solicitações de informações.
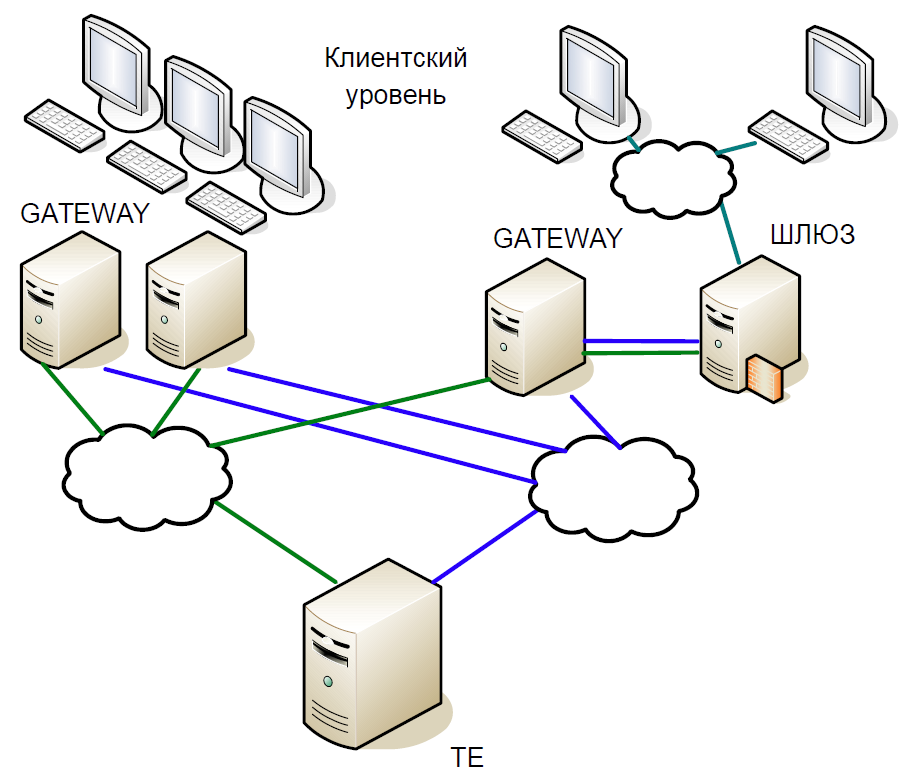
Esquematicamente, o núcleo do sistema pode ser dividido em três níveis:
- O nível do cliente no qual corretores e clientes trabalham. Todos eles interagem com os servidores de acesso.
- Servidores de acesso (Gateways) são servidores de cache que processam localmente todas as solicitações de informações. Quer saber a que preço as ações do Sberbank agora são negociadas? A solicitação vai para o servidor de acesso.
- Mas se você deseja comprar ações, a solicitação já está no servidor central (Trade Engine). Há um desses servidores para cada tipo de mercado, eles desempenham um papel crucial e foi por eles que criamos esse sistema.
O núcleo do sistema de negociação é um banco de dados complicado na memória, no qual todas as transações são transações de câmbio. A base foi escrita em C, das dependências externas havia apenas a biblioteca libc e não havia completamente nenhuma alocação dinâmica de memória. Para reduzir o tempo de processamento, o sistema inicia com um conjunto estático de matrizes e com uma realocação estática de dados: primeiro, todos os dados do dia atual são carregados na memória e, em seguida, nenhum acesso ao disco, todo o trabalho é feito apenas na memória. Quando o sistema inicia, todos os dados de referência já estão classificados, portanto, a pesquisa funciona com muita eficiência e leva pouco tempo em tempo de execução. Todas as tabelas são feitas com listas e árvores intrusivas para estruturas de dados dinâmicas, para que não exijam alocação de memória em tempo de execução.
Vamos examinar brevemente a história do desenvolvimento do nosso sistema de negociação e compensação.
A primeira versão da arquitetura do sistema de negociação e compensação foi construída na chamada interação Unix: memória compartilhada, semáforos e filas foram utilizados, e cada processo consistia em um encadeamento. Essa abordagem foi difundida no início dos anos 90.
A primeira versão do sistema continha dois níveis de Gateway e um servidor central do sistema de negociação. O esquema de trabalho foi o seguinte:
- O cliente envia uma solicitação que atinge o Gateway. Ele verifica a validade do formato (mas não os dados em si) e rejeita a transação errada.
- Se uma solicitação de informações foi enviada, ela é executada localmente; se for uma transação, será redirecionado para o servidor central.
- Em seguida, o mecanismo de negociação processa a transação, altera a memória local e envia uma resposta para a transação, e ela própria - para replicação usando um mecanismo de replicação separado.
- O gateway recebe uma resposta do nó central e a redireciona para o cliente.
- Depois de um tempo, o Gateway recebe a transação usando o mecanismo de replicação e, desta vez, executa-a localmente, alterando suas estruturas de dados para que as seguintes solicitações de informações exibam os dados reais.
De fato, o modelo de replicação é descrito aqui, no qual o Gateway repetiu completamente as ações executadas no sistema de negociação. Um canal de replicação separado forneceu a mesma ordem de execução da transação em vários nós de acesso.
Como o código era de thread único, um esquema clássico com processos bifurcados era usado para atender muitos clientes. No entanto, fazer uma bifurcação para todo o banco de dados era muito caro, então processos de serviço leves foram usados para coletar pacotes das sessões TCP e transferi-los para uma fila (SystemV Message Queue). O Gateway e o Trade Engine trabalharam apenas com essa fila, levando as transações para execução a partir daí. Já era impossível enviar uma resposta, porque não está claro qual processo de serviço deve lê-lo. Por isso, recorremos a um truque: cada processo bifurcado criou uma fila de resposta para si próprio e, quando uma solicitação entrou na fila de entrada, uma tag para a fila de resposta foi imediatamente adicionada a ela.
A cópia constante da fila para a fila de grandes quantidades de dados criava problemas, especialmente características das solicitações de informações. Portanto, aproveitamos outro truque: além da fila de resposta, cada processo também criava memória compartilhada (SystemV Shared Memory). Os próprios pacotes foram colocados nele e apenas a tag foi salva na fila, permitindo encontrar o pacote de origem. Isso ajudou a armazenar dados no cache do processador.
O SystemV IPC inclui utilitários para exibir o status dos objetos de fila, memória e semáforo. Utilizamos isso ativamente para entender o que está acontecendo no sistema em um momento específico, onde os pacotes estão se acumulando, o que está bloqueado etc.
Primeira modernização
Primeiro, nos livramos do Gateway de processo único. Sua desvantagem significativa era poder processar uma transação de replicação ou uma solicitação de informações de um cliente. E com o aumento da carga, o Gateway processará solicitações por mais tempo e não poderá processar o fluxo de replicação. Além disso, se o cliente enviou uma transação, você só precisa verificar sua validade e encaminhá-la ainda mais. Portanto, substituímos um processo de Gateway por muitos componentes que podem funcionar em paralelo: informações multithread e processos transacionais que funcionam independentemente um do outro por uma área de memória comum usando bloqueio de RW. E, ao mesmo tempo, introduzimos os processos de agendamento e replicação.
O impacto do comércio de alta frequência
A versão acima da arquitetura durou até 2010. Enquanto isso, não estávamos mais satisfeitos com o desempenho dos servidores HP Superdome. Além disso, a arquitetura do PA-RISC realmente morreu; o fornecedor não ofereceu atualizações significativas. Como resultado, começamos a mudar do HP UX / PA RISC para Linux / x86. A transição começou com a adaptação dos servidores de acesso.
Por que tivemos que mudar a arquitetura novamente? O fato é que as negociações de alta frequência alteraram significativamente o perfil de carga do núcleo do sistema.
Suponha que tenhamos uma pequena transação que causou uma mudança significativa no preço - alguém comprou meio bilhão de dólares. Após alguns milissegundos, todos os participantes do mercado percebem isso e começam a fazer uma correção. Naturalmente, as solicitações são alinhadas em uma fila enorme, que o sistema processará por um longo tempo.

Nesse intervalo de 50 ms, a velocidade média é de cerca de 16 mil transações por segundo. Se você reduzir a janela para 20 ms, obtemos uma velocidade média de 90 mil transações por segundo e, no pico, haverá 200 mil transações. Em outras palavras, a carga é instável, com rajadas acentuadas. E a fila de solicitações sempre deve ser processada rapidamente.
Mas por que existe uma fila? Portanto, em nosso exemplo, muitos usuários notaram uma alteração de preço e enviaram as transações correspondentes. Os que chegam ao Gateway, ele os serializa, define uma determinada ordem e os envia para a rede. Os roteadores misturam pacotes e os encaminham. Cujo pacote veio antes, essa transação "ganhou". Como resultado, os clientes de câmbio começaram a perceber que, se a mesma transação fosse enviada de vários Gateways, as chances de seu processamento rápido aumentariam. Logo, robôs de câmbio começaram a bombardear a Gateway com pedidos, e uma avalanche de transações surgiu.

Uma nova rodada de evolução
Após extensos testes e pesquisas, mudamos para o kernel em tempo real do sistema operacional. Para fazer isso, eles escolheram o RedHat Enterprise MRG Linux, onde MRG representa a grade de mensagens em tempo real. A vantagem dos patches em tempo real é que eles otimizam o sistema para a execução mais rápida possível: todos os processos são organizados em uma fila FIFO, você pode isolar kernels, sem descargas, todas as transações são processadas em sequência estrita.
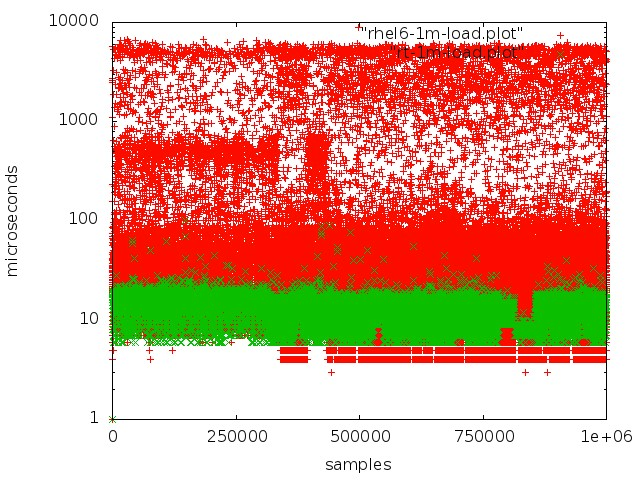 Vermelho - trabalhe com uma fila em um kernel regular, verde - trabalhe em um kernel em tempo real.
Vermelho - trabalhe com uma fila em um kernel regular, verde - trabalhe em um kernel em tempo real.Mas alcançar baixa latência em servidores regulares não é tão simples:
- O modo SMI, que na arquitetura x86 está no coração do trabalho com periféricos importantes, interfere bastante. O processamento de vários eventos de hardware e o gerenciamento de componentes e dispositivos são realizados por firmware no chamado modo SMI transparente, no qual o sistema operacional não vê o que o firmware está fazendo. Como regra, todos os principais fornecedores oferecem extensões especiais para servidores de firmware, o que permite reduzir a quantidade de processamento SMI.
- Não deve haver controle dinâmico da frequência do processador, isso leva a tempo de inatividade adicional.
- Quando o log do sistema de arquivos é redefinido, certos processos ocorrem no kernel que levam a atrasos imprevisíveis.
- Você precisa prestar atenção em coisas como afinidade da CPU, afinidade de interrupção e NUMA.
Devo dizer que o tópico de configuração do hardware e do kernel Linux para processamento em tempo real merece um artigo separado. Passamos muito tempo em experimentos e pesquisas antes de alcançarmos um bom resultado.
Ao mudar dos servidores PA-RISC para o x86, praticamente não tivemos que alterar muito o código do sistema, apenas o adaptamos e reconfiguramos. Ao mesmo tempo, vários bugs foram corrigidos. Por exemplo, surgiram rapidamente as consequências de que o PA RISC era um sistema Big endian e x86 um sistema little endian: por exemplo, os dados não foram lidos corretamente. Um bug mais complicado foi o PA RISC usar acesso
seqüencial à memória
consistente , enquanto o x86 pode reordenar as operações de leitura, para que o código absolutamente válido em uma plataforma se torne inoperante em outra.
Depois de mudar para x86, a produtividade aumentou quase três vezes, o tempo médio de processamento da transação diminuiu para 60 μs.
Vamos agora dar uma olhada mais de perto nas principais alterações feitas na arquitetura do sistema.
Épico em espera quente
Em relação aos servidores de commodities, sabíamos que eles eram menos confiáveis. Portanto, ao criar uma nova arquitetura, assumimos a priori a possibilidade de falha de um ou mais nós. Portanto, precisávamos de um sistema de espera quente capaz de alternar muito rapidamente para máquinas de backup.
Além disso, havia outros requisitos:
- Em nenhum caso você deve perder transações processadas.
- O sistema deve ser absolutamente transparente para nossa infraestrutura.
- Os clientes não devem ver quebras de conexão.
- A reserva não deve apresentar um atraso significativo, porque esse é um fator crítico para a troca.
Ao criar um sistema de espera em espera, não consideramos cenários como falhas duplas (por exemplo, a rede em um servidor parou de funcionar e o servidor principal travou); não considerou a possibilidade de erros no software, porque são detectados durante o teste; e não considerou o mau funcionamento do ferro.
Como resultado, chegamos ao seguinte esquema:
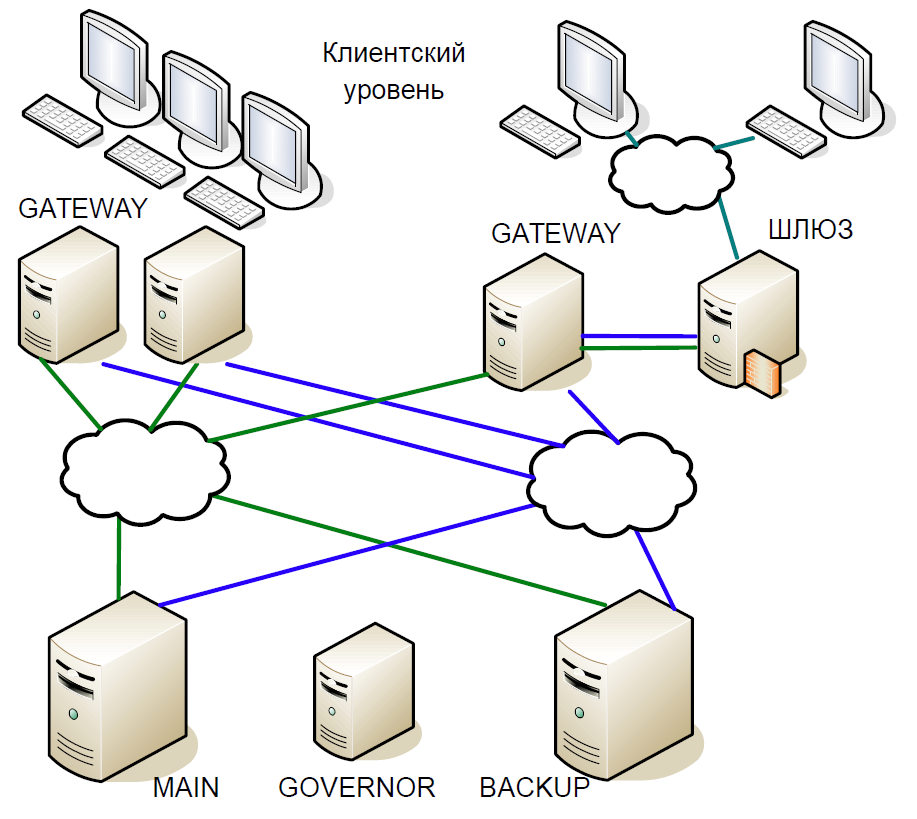
- O servidor principal interagiu diretamente com os servidores Gateway.
- Todas as transações recebidas no servidor principal foram instantaneamente replicadas no servidor de backup por meio de um canal separado. O árbitro (governador) coordenou a troca quando ocorreu algum problema.
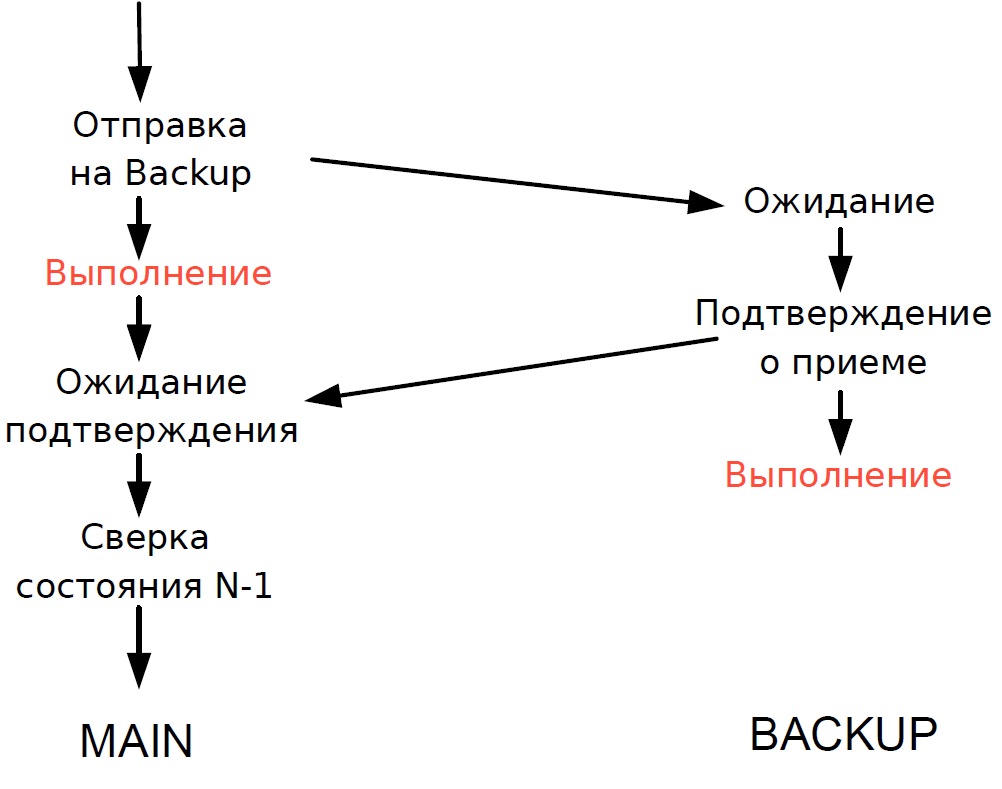
- O servidor principal processou cada transação e aguardou a confirmação do servidor de backup. Para minimizar o atraso, recusamos aguardar a conclusão da transação no servidor de backup. Como a duração da transação na rede era comparável à duração da transação, nenhum atraso adicional foi adicionado.
- Nós poderíamos verificar o status de processamento do servidor principal e de backup apenas para a transação anterior, e o status de processamento da transação atual era desconhecido. Como os processos de thread único ainda eram usados aqui, aguardar uma resposta do Backup diminuiria todo o fluxo de processamento e, portanto, fizemos um compromisso razoável: verificamos o resultado da transação anterior.

O esquema funcionou da seguinte maneira.
Suponha que o servidor principal pare de responder, mas o Gateway continue se comunicando. No servidor de backup, um tempo limite é acionado, ele se volta para o Governor e ele atribui a ele a função de servidor principal, e todos os Gateways alternam para o novo servidor principal.
Se o servidor principal estiver de volta em operação, também será acionado um tempo limite interno, porque por algum tempo não houve chamadas para o servidor do Gateway. Depois, ele também se volta para o governador e o exclui do esquema. Como resultado, a bolsa trabalha com um servidor até o final do período de negociação. Como a probabilidade de um servidor travar é bastante baixa, esse esquema foi considerado bastante aceitável, não continha lógica complexa e foi facilmente testado.
Para ser continuado.