
Esta é a continuação de uma longa história sobre nosso caminho espinhoso para a criação de um sistema poderoso e altamente carregado que garante a operação do Exchange.
A primeira parte está aqui .
Erro misterioso
Após numerosos testes, o sistema de negociação e compensação atualizado foi colocado em operação e encontramos um bug sobre o qual era correto escrever uma história mística de detetive.
Logo após iniciar no servidor principal, uma das transações foi processada com um erro. Ao mesmo tempo, tudo estava em ordem no servidor de backup. Aconteceu que uma operação matemática simples de calcular o expoente no servidor principal deu um resultado negativo a partir de um argumento válido! As pesquisas continuaram e, no registro SSE2, eles encontraram uma diferença em um bit, responsável pelo arredondamento ao trabalhar com números de ponto flutuante.
Eles escreveram um utilitário de teste simples para calcular o expoente com o conjunto de bits de arredondamento. Descobriu-se que na versão do RedHat Linux que usamos, havia um erro ao trabalhar com uma função matemática quando o bit incorreto foi inserido. Relatamos isso ao RedHat, depois de um tempo recebemos um patch deles e o enrolamos. O erro não ocorreu mais, mas não estava claro de onde veio esse bit? A função
fesetround de C. foi responsável por isso. Analisamos cuidadosamente nosso código em busca do suposto erro: verificamos todas as situações possíveis; considerou todas as funções que usavam arredondamento; tentou reproduzir uma sessão com falha; usou compiladores diferentes com opções diferentes; utilizou análise estática e dinâmica.
Não foi possível encontrar a causa do erro.
Então eles começaram a verificar o hardware: executaram testes de carga dos processadores; checou a RAM; até executou testes para um cenário muito improvável de erro de vários bits em uma célula. Sem sucesso.
No final, eles adotaram teorias do mundo da física de alta energia: algumas partículas de alta energia voaram para o nosso data center, romperam a parede do gabinete, atingiram o processador e fizeram com que a trava do gatilho ficasse na mesma parte. Essa teoria absurda foi chamada de "neutrino". Se você está longe da física de partículas elementares: os neutrinos dificilmente interagem com o mundo exterior e, certamente, eles não são capazes de afetar o processador.
Como não foi possível encontrar a causa da falha, apenas no caso de eles excluírem o servidor “delinquente” da operação.
Depois de algum tempo, começamos a melhorar o sistema hot standby: introduzimos as chamadas "reservas quentes" (réplicas assíncronas). Eles receberam um fluxo de transações que podem estar em diferentes datacenters, mas o Warm não oferece suporte à interação ativa com outros servidores.
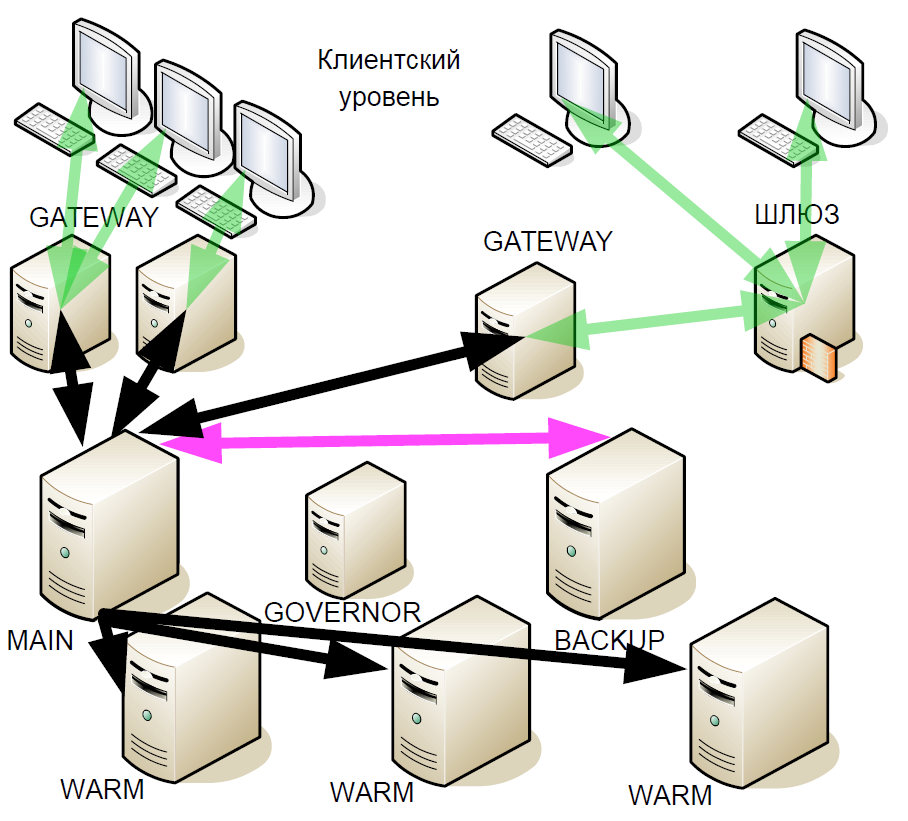
Por que isso foi feito? Se o servidor de backup falhar, o vínculo quente com o servidor principal se tornará o novo backup. Ou seja, após uma falha, o sistema não permanece até o final da sessão de negociação com um servidor principal.
E quando a nova versão do sistema foi testada e colocada em operação, ocorreu novamente um erro com um bit de arredondamento. Além disso, com o aumento do número de servidores quentes, o erro começou a aparecer com mais frequência. Nesse caso, o fornecedor não tinha nada a apresentar, pois não há evidências concretas.
Durante a próxima análise da situação, surgiu a teoria de que o problema poderia estar relacionado ao sistema operacional.
fesetround um programa simples que chama a função
fesetround em um loop infinito, lembra o estado atual e o verifica durante o sono, e isso é feito em muitos threads concorrentes. Depois de selecionar os parâmetros de suspensão e o número de threads, começamos a reproduzir de forma estável a falha de bits após cerca de 5 minutos do utilitário. No entanto, o suporte da Red Hat não conseguiu reproduzi-lo. O teste de nossos outros servidores mostrou que apenas aqueles com determinados processadores instalados são afetados pelo erro. Ao mesmo tempo, a transição para um novo núcleo resolveu o problema. No final, acabamos de substituir o sistema operacional e a verdadeira causa do bug ainda não estava clara.
E de repente, no ano passado, apareceu um artigo em Habré "
Como encontrei um bug nos processadores Intel Skylake ". A situação descrita era muito semelhante à nossa, mas o autor avançou mais na investigação e avançou na teoria de que o erro estava no microcódigo. E ao atualizar os kernels do Linux, os fabricantes também atualizam o microcódigo.
Desenvolvimento adicional do sistema
Embora tenhamos nos livrado do erro, essa história nos fez reconsiderar a arquitetura do sistema novamente. Afinal, não estávamos protegidos da repetição de tais bugs.
Os seguintes princípios formaram a base para melhorias adicionais no sistema de backup:
- Você não pode confiar em ninguém. Servidores podem não funcionar corretamente.
- Redundância de maioria.
- Construção de consenso. Como complemento lógico da redundância majoritária.
- São possíveis falhas duplas.
- Vitalidade. O novo esquema de hot spare não deve ser pior que o anterior. O comércio deve ocorrer sem problemas até o último servidor.
- Um ligeiro aumento no atraso. Qualquer tempo de inatividade acarreta enormes perdas financeiras.
- Interação mínima de rede para que o atraso seja o mais baixo possível.
- Selecione um novo servidor mestre em segundos.
Nenhuma das soluções disponíveis no mercado nos convinha, e o protocolo Raft ainda estava em sua infância, por isso criamos nossa própria solução.

Conectividade de rede
Além do sistema de backup, começamos a modernizar a conectividade de rede. O subsistema de E / S era uma infinidade de processos, que da pior maneira afetavam a instabilidade e o atraso. Tendo centenas de processos que processam conexões TCP, fomos forçados a alternar constantemente entre eles e, em uma escala de microssegundos, essa é uma operação bastante demorada. Mas a pior parte é que, quando um processo recebe um pacote para processamento, ele o envia para uma fila do SystemV e, em seguida, espera por eventos de outra fila do SystemV. No entanto, com um grande número de nós, a chegada de um novo pacote TCP em um processo e o recebimento de dados em uma fila em outro representam dois eventos concorrentes para o sistema operacional. Nesse caso, se não houver processadores físicos disponíveis para as duas tarefas, um será processado e o segundo permanecerá na fila de espera. É impossível prever as consequências.
Nessas situações, você pode aplicar o controle dinâmico de prioridade do processo, mas isso exigirá o uso de chamadas do sistema com muitos recursos. Como resultado, mudamos para um thread usando o epoll clássico, isso aumentou muito a velocidade e reduziu o tempo de processamento da transação. Também nos livramos de certos processos de interação de rede e interação através do SystemV, reduzimos significativamente o número de chamadas do sistema e começamos a controlar as prioridades das operações. Usando apenas um subsistema de E / S, foi possível economizar de 8 a 17 microssegundos, dependendo do cenário. Desde então, esse esquema de thread único foi aplicado inalterado; um fluxo de epoll com margem é suficiente para atender a todas as conexões.
Processamento de transação
A carga crescente em nosso sistema exigiu a modernização de quase todos os seus componentes. Infelizmente, porém, a estagnação no aumento da velocidade do clock do processador nos últimos anos não nos permitiu mais escalar os processos "de frente". Portanto, decidimos dividir o processo do mecanismo em três níveis, sendo o mais carregado o sistema de verificação de riscos, que avalia a disponibilidade de fundos nas contas e cria as próprias transações. Mas o dinheiro pode estar em moedas diferentes, e foi necessário descobrir em que princípio dividir o processamento de solicitações.
A solução lógica é dividir por moeda: um servidor negocia em dólares, outro em libras e um terceiro euro. Mas se, com esse esquema, duas transações forem enviadas para comprar moedas diferentes, haverá um problema de carteiras fora de sincronia. E sincronizar é difícil e caro. Portanto, será correto estilhaçar separadamente nas carteiras e nas ferramentas. A propósito, na maioria das trocas ocidentais, a tarefa de verificar riscos não é tão aguda quanto a nossa, portanto, na maioria das vezes, isso é feito offline. Precisávamos implementar uma verificação online.
Vamos ilustrar com um exemplo. O profissional deseja comprar US $ 30, e a solicitação é validada para a transação: verificamos se esse profissional está autorizado a esse modo de negociação, se possui os direitos necessários. Se tudo estiver em ordem, a solicitação será direcionada ao sistema de verificação de riscos, ou seja, verificar a suficiência de fundos para concluir uma transação. Há uma observação de que a quantidade necessária está atualmente bloqueada. Além disso, a solicitação é redirecionada para o sistema de negociação, que aprova ou não a transação. Digamos que a transação seja aprovada - então o sistema de verificação de riscos observa que o dinheiro é desbloqueado e os rublos são convertidos em dólares.
Em geral, o sistema de verificação de riscos contém algoritmos complexos e realiza uma grande quantidade de cálculos que consomem muitos recursos e não apenas verifica o “saldo da conta”, como pode parecer à primeira vista.
Quando começamos a dividir o processo do mecanismo em níveis, encontramos um problema: o código que estava disponível naquele momento nos estágios de validação e verificação usava ativamente a mesma matriz de dados, o que exigia a reescrita de toda a base de códigos. Como resultado, emprestamos uma metodologia para processar instruções dos processadores modernos: cada um deles é dividido em pequenos estágios e várias ações são executadas em paralelo em um ciclo.
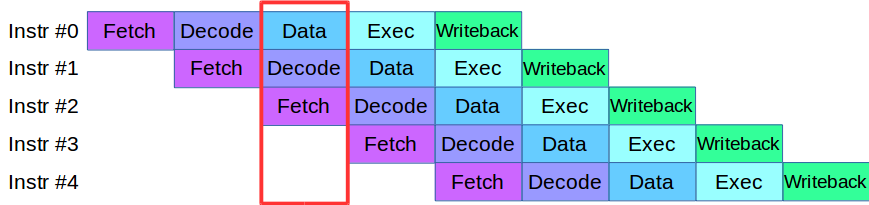
Após uma pequena adaptação do código, criamos um pipeline para processamento paralelo de transações, no qual a transação foi dividida em 4 etapas do pipeline: interação da rede, validação, execução e publicação do resultado

Considere um exemplo. Temos dois sistemas de processamento, serial e paralelo. A primeira transação chega e, nos dois sistemas, é validada. Em seguida, chega a segunda transação: em um sistema paralelo, ela é imediatamente levada ao trabalho e, em um sistema seqüencial, é enfileirada em antecipação até a primeira transação passar no estágio de processamento atual. Ou seja, a principal vantagem do pipelining é que processamos a fila de transações mais rapidamente.
Então, nós temos o sistema ASTS +.
É verdade que também com transportadores, nem tudo é tão suave. Suponha que tenhamos uma transação que afeta as matrizes de dados em uma transação vizinha, essa é uma situação típica da troca. Essa transação não pode ser executada no pipeline, porque pode afetar outras. Essa situação é chamada de risco de dados e essas transações são simplesmente processadas separadamente: quando as transações "rápidas" na fila terminam, o pipeline para, o sistema processa a transação "lenta" e inicia o pipeline novamente. Felizmente, a participação dessas transações no fluxo total é muito pequena; portanto, o pipeline para tão raramente que não afeta o desempenho geral.

Então começamos a resolver o problema de sincronizar três threads de execução. Como resultado, nasceu um sistema baseado em um buffer circular com células de tamanho fixo. Neste sistema, tudo está sujeito à velocidade de processamento, os dados não são copiados.
- Todos os pacotes de rede recebidos entram no estágio de alocação.
- Nós os colocamos em uma matriz e marcamos que eles estão disponíveis para o estágio n ° 1.
- A segunda transação chegou, está novamente disponível para o estágio número 1.
- O primeiro fluxo de processamento vê as transações disponíveis, as processa e as transfere para o próximo estágio do segundo fluxo de processamento.
- Em seguida, processa a primeira transação e marca a célula correspondente com o sinalizador
deleted - agora está disponível para novo uso.
Assim, toda a fila é processada.
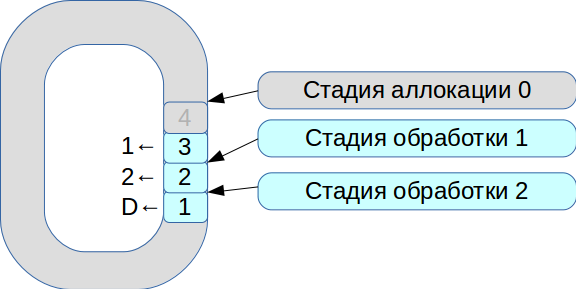
O processamento de cada estágio leva unidades ou dezenas de microssegundos. E se você usar esquemas de sincronização padrão do SO, perderemos mais tempo na própria sincronização. Portanto, começamos a usar o spinlock. No entanto, esse é um tom muito ruim em um sistema em tempo real, e o RedHat recomenda enfaticamente não fazer isso; portanto, usamos o spinlock por 100 ms e, em seguida, entramos no modo de semáforo para excluir a possibilidade de conflito.
Como resultado, alcançamos um desempenho de cerca de 8 milhões de transações por segundo. E apenas dois meses depois, em um
artigo sobre o LMAX Disruptor, eles viram uma descrição de um circuito com a mesma funcionalidade.
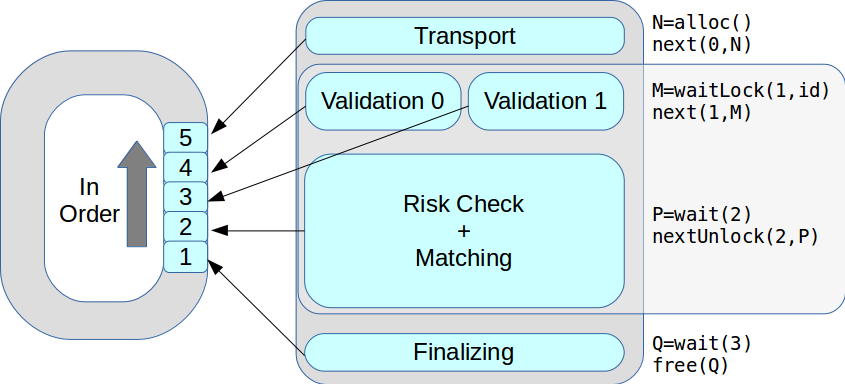
Agora, em um estágio, pode haver vários segmentos de execução. Todas as transações foram processadas por sua vez, na ordem recebida. Como resultado, o desempenho máximo aumentou de 18 mil para 50 mil transações por segundo.
Sistema de Gerenciamento de Risco de Câmbio
Não há limite para a perfeição e logo começamos a nos modernizar novamente: no âmbito do ASTS +, começamos a transferir sistemas de gerenciamento de riscos e operações de liquidação para componentes autônomos. Desenvolvemos uma arquitetura moderna flexível e um novo modelo de risco hierárquico, tentado sempre que possível usar a classe
fixed_point vez de
double .
Mas imediatamente surgiu o problema: como sincronizar toda a lógica de negócios que funciona há muitos anos e transferi-la para o novo sistema? Como resultado, a primeira versão do protótipo do novo sistema teve que ser abandonada. A segunda versão, que está atualmente trabalhando na produção, é baseada no mesmo código que funciona tanto na parte comercial quanto na de risco. Durante o desenvolvimento, a coisa mais difícil foi fazer a fusão do git entre as duas versões. Nosso colega Evgeny Mazurenok realizou essa operação toda semana e xingou por muito tempo.
Ao selecionar um novo sistema, imediatamente tivemos que resolver o problema de interação. Ao escolher um barramento de dados, era necessário garantir instabilidade estável e atraso mínimo. Para isso, a rede InfiniBand RDMA é mais adequada: o tempo médio de processamento é 4 vezes menor que nas redes Ethernet de 10 G. Mas a diferença real estava nos percentis - 99 e 99,9.
Obviamente, o InfiniBand tem suas próprias dificuldades. Primeiro, outra API é ibverbs em vez de soquetes. Em segundo lugar, quase não existem soluções de mensagens de código aberto amplamente disponíveis. Tentamos fazer nosso protótipo, mas ele se mostrou muito difícil, por isso escolhemos uma solução comercial - Confinity Low Latency Messaging (anteriormente IBM MQ LLM).
Surgiu então o problema da separação correta do sistema de riscos. Se você apenas remover o Mecanismo de Risco e não criar um nó intermediário, as transações de duas fontes poderão ser misturadas.
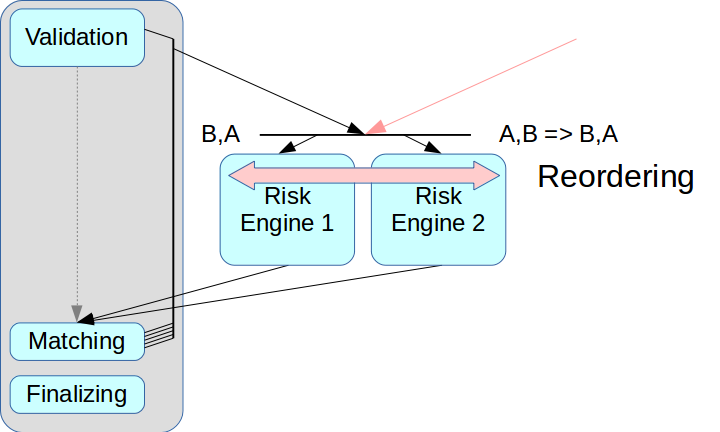
As chamadas soluções de ultra baixa latência têm um modo de reordenação: as transações de duas fontes podem ser organizadas na ordem correta após o recebimento, isso é realizado usando um canal separado para troca de informações sobre a sequência. Mas ainda não aplicamos esse modo: ele complica todo o processo e, em algumas soluções, ele não é suportado. Além disso, cada transação teria que receber os carimbos de data e hora apropriados e, em nosso esquema, esse mecanismo é muito difícil de implementar corretamente. Portanto, usamos o esquema clássico com o intermediário de mensagens, ou seja, com um despachante que distribui mensagens entre o Risk Engine.
O segundo problema estava relacionado ao acesso do cliente: se houver vários Gateways de Risco, o cliente precisará se conectar a cada um deles e, para isso, será necessário fazer alterações na camada do cliente. Queríamos nos afastar disso nesta fase; portanto, no atual esquema do Risk Gateway, eles processam todo o fluxo de dados. Isso limita severamente o rendimento máximo, mas simplifica bastante a integração do sistema.
Duplicação
Nosso sistema não deve ter um único ponto de falha, ou seja, todos os componentes devem ser duplicados, incluindo um intermediário de mensagens. Resolvemos esse problema usando o sistema CLLM: ele contém um cluster RCMS no qual dois despachantes podem trabalhar no modo mestre-escravo e, quando um falha, o sistema alterna automaticamente para o outro.
Trabalhar com um data center de backup
O InfiniBand é otimizado para funcionar como uma rede local, ou seja, para conectar equipamentos montados em rack, e não há como estabelecer uma rede InfiniBand entre dois data centers geograficamente distribuídos. Portanto, implementamos uma ponte / despachante que se conecta ao armazenamento de mensagens através de redes Ethernet regulares e retransmite todas as transações para a segunda rede IB. Quando você precisar migrar do data center, podemos escolher com que data center trabalhar agora.
Sumário
Todas as opções acima não foram feitas de uma só vez; foram necessárias várias iterações para o desenvolvimento de uma nova arquitetura. Criamos o protótipo em um mês, mas foram necessários mais de dois anos para finalizar a condição de trabalho. Tentamos alcançar o melhor compromisso entre aumentar a duração do processamento da transação e aumentar a confiabilidade do sistema.
Como o sistema foi fortemente atualizado, implementamos a recuperação de dados de duas fontes independentes. Se, por algum motivo, o armazenamento de mensagens não estiver funcionando corretamente, você poderá obter o log de transações de uma segunda fonte - no Risk Engine. Este princípio é respeitado em todo o sistema.
Entre outras coisas, conseguimos manter a API do cliente para que nem os corretores nem qualquer outra pessoa precisassem de uma alteração significativa para a nova arquitetura. Eu tive que mudar algumas interfaces, mas não precisei fazer alterações significativas no modelo de trabalho.
Chamamos a versão atual de nossa plataforma de Rebus - como uma abreviação para as duas inovações mais notáveis em arquitetura, Risk Engine e BUS.
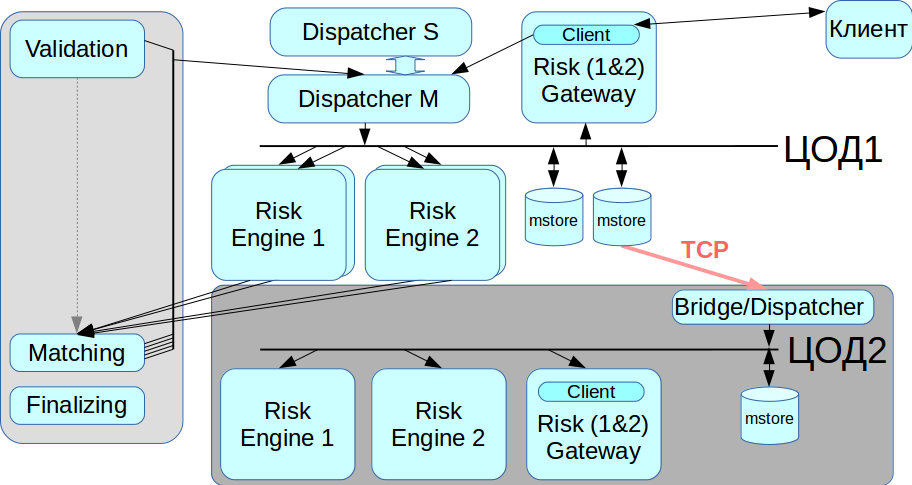
Inicialmente, queríamos destacar apenas a parte da compensação, mas o resultado foi um enorme sistema distribuído. Agora, os clientes podem interagir com o Gateway de negociação ou com a compensação ou com os dois ao mesmo tempo.
O que finalmente alcançamos:

Reduzido o nível de atraso. Com um pequeno volume de transações, o sistema funciona da mesma forma que na versão anterior, mas ao mesmo tempo suporta uma carga muito maior.
O pico de produtividade aumentou de 50 mil para 180 mil transações por segundo. Um fluxo adicional de informações está impedindo um crescimento maior.
: matching Gateway. Gateway , .
, -: