Somente nos Estados Unidos, existem 3 milhões de pessoas com deficiência que não podem deixar suas casas. Os robôs auxiliares que podem navegar automaticamente por longas distâncias podem tornar essas pessoas mais independentes, trazendo alimentos, remédios e pacotes. Estudos mostram que o aprendizado profundo com reforço (OP) é bem adequado para comparar dados e ações brutos de entrada, por exemplo, para aprender a
capturar objetos ou
mover robôs , mas geralmente os
agentes de OP não compreendem os grandes espaços físicos necessários para uma orientação segura a longa distância distâncias sem ajuda humana e adaptação a um novo ambiente.
Em três trabalhos recentes, “
Treinamento de orientação do zero com AOP ”, “
PRM-RL: implementando orientação robótica em longas distâncias usando uma combinação de aprendizado reforçado e planejamento baseado em padrões ” e “
Orientação de longo alcance com PRM-RL ”
, nós Estudamos robôs autônomos que se adaptam facilmente a um novo ambiente, combinando OP profundo com planejamento a longo prazo. Ensinamos aos agentes planejadores locais como executar as ações básicas necessárias para orientação e como percorrer curtas distâncias sem colisões com objetos em movimento. Planejadores locais realizam observações ambientais barulhentas usando sensores como lidares unidimensionais que fornecem distância a um obstáculo e fornecem velocidades lineares e angulares para controlar o robô. Treinamos o planejador local em simulações usando o aprendizado por reforço automático (AOP), um método que automatiza a busca por recompensas para o OP e a arquitetura da rede neural. Apesar do alcance limitado de 10 a 15 m, os planejadores locais se adaptam bem tanto ao uso em robôs reais quanto a novos ambientes previamente desconhecidos. Isso permite que você os use como blocos de construção para orientação em grandes espaços. Em seguida, construímos um roteiro, um gráfico em que os nós são seções separadas e as bordas conectam os nós somente se planejadores locais, imitando robôs reais usando sensores e controles ruidosos, podem se mover entre eles.
Aprendizagem por reforço automático (AOP)
Em
nosso primeiro trabalho, treinamos um planejador local em um pequeno ambiente estático. No entanto, ao aprender com o algoritmo OP profundo padrão, por exemplo, o gradiente determinístico profundo (
DDPG ), existem vários obstáculos. Por exemplo, o objetivo real dos planejadores locais é atingir um determinado objetivo, como resultado do qual eles recebem recompensas raras. Na prática, isso exige que os pesquisadores gastem um tempo considerável na implementação passo a passo do algoritmo e no ajuste manual dos prêmios. Os pesquisadores também precisam tomar decisões sobre a arquitetura das redes neurais sem ter receitas claras e bem-sucedidas. Finalmente, algoritmos como o DDPG aprendem de maneira instável e geralmente exibem
esquecimentos catastróficos .
Para superar esses obstáculos, automatizamos o aprendizado profundo com reforço. O AOP é um invólucro automático evolutivo em torno de um OP profundo, buscando recompensas e arquitetura de rede neural através da
otimização de hiperparâmetros em larga escala . Ele funciona em duas etapas, a busca por recompensas e a busca pela arquitetura. Durante a busca por recompensas, o AOP treina simultaneamente a população de agentes DDPG por várias gerações, e cada um tem sua própria função de recompensa ligeiramente modificada, otimizada para a verdadeira tarefa do planejador local: alcançar o ponto final do caminho. No final da fase de busca de recompensa, selecionamos uma que geralmente leva os agentes à meta. Na fase de busca da arquitetura da rede neural, repetimos esse processo, para esta corrida, utilizando o prêmio selecionado e ajustando as camadas da rede, otimizando o prêmio acumulado.
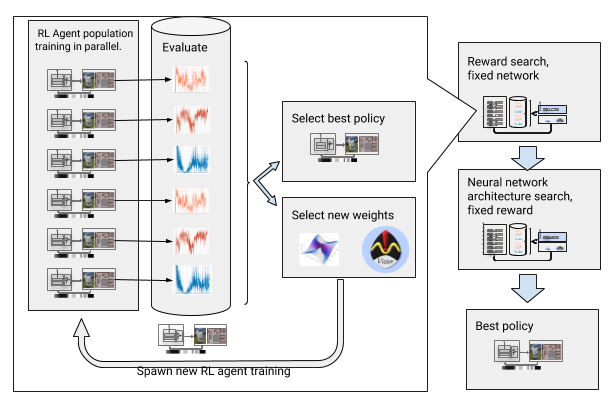 AOP com a busca por premiação e arquitetura da rede neural
AOP com a busca por premiação e arquitetura da rede neuralNo entanto, esse processo passo a passo torna a AOP ineficaz em termos de número de amostras. O treinamento em AOP com 10 gerações de 100 agentes requer 5 bilhões de amostras, o equivalente a 32 anos de estudo! A vantagem é que, após a AOP, o processo de aprendizado manual é automatizado e o DDPG não apresenta esquecimentos catastróficos. Mais importante ainda, a qualidade das políticas finais é mais alta - elas são resistentes ao ruído do sensor, unidade e localização e são bem generalizadas para novos ambientes. Nossa melhor política é 26% mais bem-sucedida do que outros métodos de orientação em nossos locais de teste.
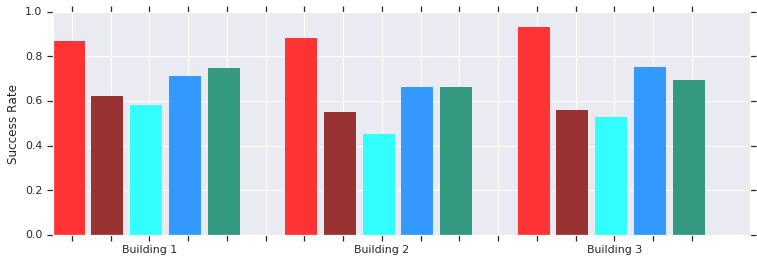 Vermelho - AOP obtém sucesso em distâncias curtas (até 10 m) em vários edifícios anteriormente desconhecidos. Comparação com DDPG treinado manualmente (vermelho escuro), campos de potencial artificial (azul), janela dinâmica (azul) e clonagem de comportamento (verde).A política do agendador local da AOP funciona bem com robôs em ambientes reais não estruturados
Vermelho - AOP obtém sucesso em distâncias curtas (até 10 m) em vários edifícios anteriormente desconhecidos. Comparação com DDPG treinado manualmente (vermelho escuro), campos de potencial artificial (azul), janela dinâmica (azul) e clonagem de comportamento (verde).A política do agendador local da AOP funciona bem com robôs em ambientes reais não estruturadosE embora esses políticos sejam capazes apenas de orientação local, são resistentes a obstáculos em movimento e são bem tolerados por robôs reais em ambientes não estruturados. E embora tenham sido treinados em simulações com objetos estáticos, eles efetivamente lidam com objetos em movimento. O próximo passo é combinar as políticas de AOP com o planejamento baseado em amostras, a fim de expandir sua área de trabalho e ensiná-los a navegar por longas distâncias.
Orientação a longa distância com PRM-RL
Planejadores baseados em padrões trabalham com orientação de longo alcance, aproximando os movimentos do robô. Por exemplo, um robô cria
roteiros probabilísticos (PRMs) desenhando caminhos de transição entre seções. Em nosso
segundo trabalho , que ganhou o prêmio na conferência
ICRA 2018 , combinamos o PRM com agendadores de OP locais manualmente ajustados (sem AOP) para treinar robôs localmente e depois adaptá-los a outros ambientes.
Primeiro, para cada robô, treinamos a política do planejador local em uma simulação generalizada. Em seguida, criamos um PRM levando em consideração essa política, a chamada PRM-RL, com base em um mapa do ambiente em que será usado. O mesmo cartão pode ser usado para qualquer robô que desejamos usar no prédio.
Para criar um PRM-RL, combinamos nós de amostras apenas se o agendador de OP local puder se mover confiável e repetidamente entre eles. Isso é feito em uma simulação de Monte Carlo. O mapa resultante se adapta às capacidades e geometria de um robô específico. Cartões para robôs com a mesma geometria, mas com diferentes sensores e unidades, terão conectividade diferente. Como o agente pode girar na esquina, os nós que não estão na linha de visão direta também podem ser ativados. No entanto, nós adjacentes às paredes e obstáculos terão menos probabilidade de serem incluídos no mapa devido ao ruído do sensor. No tempo de execução, o agente OP move-se pelo mapa de uma seção para outra.
 Um mapa é criado com três simulações de Monte Carlo para cada par de nós selecionado aleatoriamente
Um mapa é criado com três simulações de Monte Carlo para cada par de nós selecionado aleatoriamente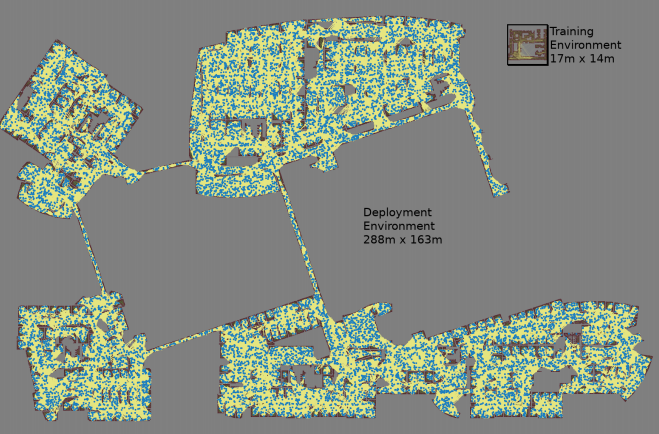 O maior mapa tinha 288x163 m de tamanho e continha quase 700.000 arestas. 300 trabalhadores a coletaram por 4 dias, tendo realizado 1,1 bilhão de verificações de colisão.O terceiro trabalho
O maior mapa tinha 288x163 m de tamanho e continha quase 700.000 arestas. 300 trabalhadores a coletaram por 4 dias, tendo realizado 1,1 bilhão de verificações de colisão.O terceiro trabalho fornece várias melhorias no PRM-RL original. Em primeiro lugar, estamos substituindo o DDPG ajustado manualmente por agendadores locais de AOP, o que proporciona uma melhoria na orientação em longas distâncias. Em segundo lugar, são adicionados
mapas de localização e marcação simultânea (
SLAM ), que os robôs usam em tempo de execução como fonte para a construção de roteiros. As placas SLAM estão sujeitas a ruído, e isso fecha a “lacuna entre o simulador e a realidade”, um problema conhecido em robótica, devido ao qual agentes treinados em simulações se comportam muito pior no mundo real. Nosso nível de sucesso na simulação coincide com o nível de sucesso de robôs reais. E, finalmente, adicionamos mapas de construção distribuídos, para que possamos criar mapas muito grandes contendo até 700.000 nós.
Avaliamos esse método com a ajuda do nosso agente de AOP, que criou mapas com base em desenhos de edifícios que excederam o ambiente de treinamento em 200 vezes na área, incluindo apenas costelas, que foram concluídas com sucesso em 90% dos casos em 20 tentativas. Comparamos o PRM-RL com vários métodos a distâncias de até 100 m, o que excedeu significativamente o alcance do planejador local. O PRM-RL obteve sucesso 2-3 vezes mais do que os métodos usuais devido à conexão correta dos nós, adequada às capacidades do robô.
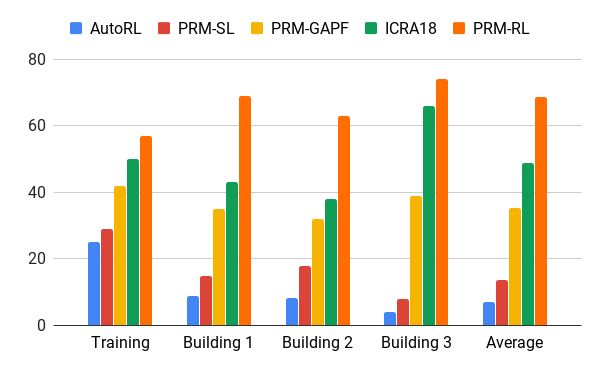 Taxa de sucesso na movimentação de 100 m em diferentes edifícios. Azul - agendador local de AOP, primeiro trabalho; vermelho - PRM original; amarelo - campos potenciais artificiais; verde é o segundo emprego; vermelho - o terceiro emprego, PRM com AOP.
Taxa de sucesso na movimentação de 100 m em diferentes edifícios. Azul - agendador local de AOP, primeiro trabalho; vermelho - PRM original; amarelo - campos potenciais artificiais; verde é o segundo emprego; vermelho - o terceiro emprego, PRM com AOP.Testamos o PRM-RL em muitos robôs reais em muitos edifícios. Abaixo está uma das suítes de teste; o robô se move de maneira confiável em quase todos os lugares, exceto nos lugares e áreas mais confusos que vão além da placa SLAM.

Conclusão
A orientação da máquina pode aumentar seriamente a independência das pessoas com problemas de mobilidade. Isso pode ser alcançado através do desenvolvimento de robôs autônomos que podem se adaptar facilmente ao ambiente e dos métodos disponíveis para implementação no novo ambiente, com base nas informações existentes. Isso pode ser feito automatizando o treinamento básico de orientação para distâncias curtas com o AOP e, em seguida, usando as habilidades adquiridas juntamente com os cartões SLAM para criar roteiros. Os roteiros consistem em nós conectados por nervuras, nos quais os robôs podem se mover com segurança. Como resultado, é desenvolvida uma política de comportamento do robô que, após um treinamento, pode ser usada em diferentes ambientes e emitir roteiros especialmente adaptados para um robô específico.