Oi Meu nome é Andrey, sou estudante de graduação em uma das universidades técnicas de Moscou e trabalha meio período muito modesto empreendedor e desenvolvedor iniciante. Neste artigo, decidi compartilhar minha experiência de mudar do PHP (que eu gostei uma vez por causa de sua simplicidade, mas acabou sendo odiado por mim - explico por quê) no NodeJS. Tarefas muito triviais e aparentemente elementares podem ser dadas aqui, as quais, no entanto, fiquei pessoalmente curioso para resolver durante meu conhecimento do NodeJS e os recursos do desenvolvimento do servidor em JavaScript. Tentarei explicar e demonstrar claramente que o PHP finalmente entrou no por do sol e deu lugar ao NodeJS. Talvez até seja útil para alguém aprender alguns recursos de renderização de páginas HTML no Node, que não é originalmente adaptado a isso a partir da palavra.
1. Introdução
Enquanto escrevia o mecanismo, usei as técnicas mais simples. Sem gerenciadores de pacotes, sem roteamento. Somente pastas hardcore, cujo nome corresponde à rota solicitada, e index.php em cada uma delas, configuradas pelo PHP-FPM para suportar o pool de processos. Mais tarde, tornou-se necessário usar o Composer e o Laravel, que foi a gota d'água para mim. Antes de passar à história de por que decidi reescrever tudo, desde PHP até NodeJS, vou falar um pouco sobre o plano de fundo.
Gerenciador de pacotes
No final de 2018, tive a oportunidade de trabalhar com um projeto escrito no Laravel. Foi necessário corrigir vários bugs, fazer alterações na funcionalidade existente, adicionar alguns novos botões na interface. O processo começou instalando o gerenciador de pacotes e dependências. No PHP, o Composer é usado para isso. Em seguida, o cliente forneceu um servidor com 1 núcleo e 512 megabytes de RAM e essa foi minha primeira experiência com o Composer. Ao instalar dependências em um servidor privado virtual com 512 megabytes de memória, o processo travou devido à falta de memória.

Para mim, como uma pessoa familiarizada com Linux e com experiência em trabalhar com Debian e Ubuntu, a solução para este problema era óbvia - instalar um arquivo SWAP (um arquivo de troca - para aqueles que não estão familiarizados com a administração do Linux). Um desenvolvedor inexperiente iniciante que instalou sua primeira distribuição Laravel no Digital Ocean, por exemplo, apenas vai ao painel de controle e aumenta a tarifa até que a instalação de dependências pare com um erro de segmentação de memória. E o NodeJS?
E o NodeJS possui seu próprio gerenciador de pacotes - npm. É muito mais fácil de usar, mais compacto, pode funcionar mesmo em um ambiente com uma quantidade mínima de RAM. Em geral, não há nada para culpar o Composer contra o NPM; no entanto, em caso de erros ao instalar pacotes, o Composer falhará como um aplicativo PHP comum e você nunca saberá qual parte do pacote foi instalada e se foi instalada no final termina. Em geral, para o administrador do Linux, a instalação travada = flashbacks no Rescue Mode e dpkg --configure -a . Quando essas "surpresas" me alcançaram, eu não gostava de PHP, mas essas eram as últimas unhas do caixão do meu grande amor pelo PHP.
Problema de suporte e versão de longo prazo
Lembra-se de que tipo de hype e espanto causaram o PHP7 quando os desenvolvedores o apresentaram pela primeira vez? Aumente a produtividade em mais de 2 vezes e em alguns componentes até 5 vezes! Lembra quando nasceu a sétima versão do PHP? E com que rapidez o WordPress ganhou! Era dezembro de 2015. Você sabia que o PHP 7.0 agora é considerado uma versão obsoleta do PHP e é altamente recomendável atualizá-lo ... Não, não para a versão 7.1, mas para a versão 7.2. Segundo os desenvolvedores, a versão 7.1 já está privada de suporte ativo e recebe apenas atualizações de segurança. E depois de 8 meses isso vai parar. Parará, junto com o suporte ativo e a versão 7.2. Acontece que até o final deste ano, o PHP terá apenas uma versão atual - 7.3.

Na verdade, isso não seria muito difícil e eu não atribuiria isso aos motivos de minha saída do PHP se os projetos que eu escrevi no PHP 7.0. * Já não causou um aviso de descontinuação quando o abri. Voltemos ao projeto em que a instalação das dependências falhou. Este foi um projeto escrito em 2015 no Laravel 4 com PHP 5.6. Parecia que apenas quatro anos se passaram, mas não - um monte de avisos de descontinuação, módulos desatualizados, a incapacidade de atualizar para o Laravel 5 normalmente devido a várias atualizações do mecanismo raiz.
E isso não se aplica apenas ao Laravel. Tente escrever qualquer aplicativo PHP durante o suporte ativo das primeiras versões do PHP 7.0 e esteja preparado para passar a noite procurando soluções para problemas que surgiram em módulos PHP desatualizados. Finalmente, um fato interessante: o suporte ao PHP 7.0 foi descontinuado antes do suporte ao PHP 5.6. Por um segundo
E o NodeJS? Eu não diria que tudo está muito melhor aqui e que os períodos de suporte para o NodeJS são fundamentalmente diferentes do PHP. Não, é a mesma coisa aqui - cada versão do LTS é suportada por 3 anos. Mas o NodeJS possui um pouco mais dessas versões mais atuais.
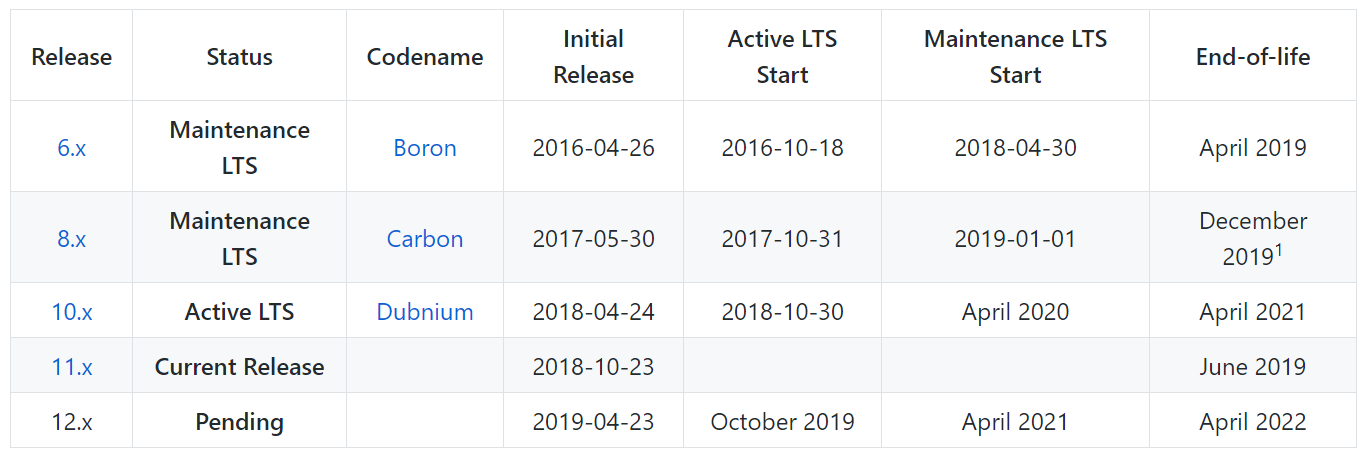
Se você precisar implantar um aplicativo escrito em 2016, verifique se não terá problemas com isso. Aliás, a versão 6. * não será mais suportada apenas em abril deste ano. E na frente há 8, 10, 11 e os próximos 12.
Dificuldades e surpresas ao mudar para o NodeJS
Começarei, talvez, com a pergunta mais interessante para mim sobre como renderizar páginas HTML no NodeJS. Mas vamos primeiro lembrar como isso é feito no PHP:
- Incorpore HTML diretamente no código PHP. O mesmo acontece com todos os novatos que ainda não chegaram ao MVC. E assim é feito no WordPress, o que é absolutamente horrível.
- Use o MVC, que deve simplificar a interação do desenvolvedor e fornecer algum tipo de divisão do projeto em partes, mas, na realidade, essa abordagem apenas complica tudo às vezes.
- Use um mecanismo de modelo. A opção mais conveniente, mas não no PHP. Basta olhar para a sintaxe sugerida no Twig ou Blade com chaves e porcentagens.
Sou um oponente ardente da combinação ou fusão de várias tecnologias. O HTML deve existir separadamente, os estilos separadamente, o JavaScript separadamente (em React, isso geralmente parece monstruoso - HTML e JavaScript são mistos). É por isso que a opção ideal para desenvolvedores com preferências como a minha é um mecanismo de modelo. Não precisei procurar por um aplicativo da Web no NodeJS por muito tempo e optei pelo Jade (PugJS). Apenas aprecie a simplicidade de sua sintaxe:
div.row.links div.col-lg-3.col-md-3.col-sm-4 h4.footer-heading . div.copyright div.copy-text 2017 - #{current_year} . div.contact-link span : a(href='mailto:hello@flaut.ru') hello@flaut.ru
Tudo é bem simples aqui: escrevi um modelo, baixei-o no aplicativo, compilei uma vez e depois o usei em qualquer lugar conveniente e a qualquer momento conveniente. Na minha opinião, o desempenho do PugJS é cerca de 2 vezes melhor que a renderização, incorporando HTML no código PHP. Se anteriormente no PHP uma página estática foi gerada pelo servidor em cerca de 200-250 milissegundos, agora é de 90-120 milissegundos (não estamos falando sobre a renderização no PugJS, mas sobre o tempo gasto na solicitação da página para a resposta do servidor ao cliente com HTML pronto ) É assim que o carregamento e a compilação de modelos e seus componentes no estágio de inicialização do aplicativo se parecem:
const pugs = {} fs.readdirSync(__dirname + '/templates/').forEach(file => { if(file.endsWith('.pug')) { try { var filepath = __dirname + '/templates/' + file pugs[file.split('.pug')[0]] = pug.compile(fs.readFileSync(filepath, 'utf-8'), { filename: filepath }) } catch(e) { console.error(e) } } })
Parece incrivelmente simples, mas com Jade havia um pouco de complexidade no estágio de trabalhar com HTML já compilado. O fato é que, para implementar scripts na página, é usada uma função assíncrona, que retira todos os arquivos .js do diretório e adiciona a data da última alteração a cada um deles. A função tem o seguinte formato:
for(let i = 0; i < files.length; i++) { let period = files[i].lastIndexOf('.')
Na saída, obtemos uma matriz de objetos com duas propriedades - o caminho para o arquivo e a hora em que ele foi editado pela última vez no registro de data e hora (para atualizar o cache do cliente). O problema é que, mesmo na fase de coleta dos arquivos de script de um diretório, todos eles são carregados na memória estritamente em ordem alfabética (pois estão localizados no próprio diretório e os arquivos são coletados de cima para baixo - do primeiro ao último). Isso levou ao fato de o arquivo app.js ter sido carregado primeiro e já após o arquivo core.min.js com polyfills e vendor.min.js no final. Esse problema foi resolvido de maneira simples - classificação muito banal:
scripts.sort((a, b) => { if(a.path.includes('core.min.js')) { return -1 } else if(a.path.includes('vendor.min.js')) { return 0 } return 1 })
No PHP, tudo tinha uma aparência monstruosa na forma de caminhos para arquivos JS pré-gravados em uma string. Simples, mas impraticável.
NodeJS mantém sua aplicação na RAM
Esta é uma enorme vantagem. Tudo está organizado para mim, para que, no servidor, paralelamente e independentemente um do outro, existam dois sites separados - a versão para o desenvolvedor e a versão de produção. Imagine que eu fiz algumas alterações nos arquivos PHP no site de desenvolvimento e preciso implantar essas alterações na produção. Para fazer isso, é necessário parar o servidor ou colocar um stub "desculpe, técnico. Trabalho" e, neste momento, copiar arquivos individualmente da pasta de desenvolvedor para a pasta de produção. Isso causa algum tipo de tempo de inatividade e pode resultar em perda de conversões. A vantagem do aplicativo na memória do NodeJS é para mim que todas as alterações nos arquivos do mecanismo serão feitas somente após a reinicialização. Isso é muito conveniente, porque você pode copiar todos os arquivos necessários com as alterações e só então reiniciar o servidor. O processo não leva mais que 1-2 segundos e não causa tempo de inatividade.
A mesma abordagem é usada no nginx, por exemplo. Você primeiro edita a configuração, verifica-a com nginx -t e só depois faz alterações com o service nginx reload
Agrupando um Aplicativo NodeJS
O NodeJS possui uma ferramenta muito conveniente - o gerenciador de processos pm2 . Como geralmente executamos aplicativos no Node? Entramos no console e escrevemos o node index.js . Assim que fechamos o console, o aplicativo é fechado. Pelo menos é o que acontece em um servidor com o Ubuntu. Para evitar isso e manter o aplicativo sempre em execução, basta adicioná-lo ao pm2 com o comando pm2 start index.js --name production simples. Mas isso não é tudo. A ferramenta permite monitoramento ( pm2 monit ) e cluster de aplicativos.
Vamos lembrar como os processos são organizados em PHP. Suponha que tenhamos o nginx atendendo solicitações http e precisamos passar a solicitação para o PHP. Você pode fazer isso diretamente e, a cada solicitação, um novo processo PHP será gerado e, quando concluído, será eliminado. Ou você pode usar um servidor fastcgi. Acho que todo mundo sabe o que é e não há necessidade de entrar em detalhes, mas, no caso, vou esclarecer que o PHP-FPM é mais frequentemente usado como fastcgi e sua tarefa é gerar muitos processos PHP prontos para aceitar e processar uma nova solicitação a qualquer momento. Qual é a desvantagem dessa abordagem?
A primeira é que você nunca sabe quanta memória seu aplicativo consumirá. Em segundo lugar, você sempre estará limitado no número máximo de processos e, consequentemente, com um salto acentuado no tráfego, seu aplicativo PHP usará toda a memória disponível e travará, ou ficará contra o limite permitido de processos e começará a matar os antigos. Isso pode ser evitado definindo Não lembro qual parâmetro no arquivo de configuração do PHP-FPM é dinâmico e, em seguida, quantos processos serão gerados conforme necessário no momento. Mas, novamente, um ataque DDoS elementar consome toda a RAM e coloca seu servidor. Ou, por exemplo, um script de bug consumirá toda a RAM e o servidor congelará por algum tempo (houve precedentes no processo de desenvolvimento).
A diferença fundamental no NodeJS é que o aplicativo não pode consumir mais de 1,5 gigabytes de RAM. Não há restrições de processo, há apenas um limite de memória. Isso incentiva você a escrever os programas mais leves possíveis. Além disso, é muito simples calcular o número de clusters que podemos pagar, dependendo do recurso de CPU disponível. É recomendável que você desligue não mais que um cluster em cada núcleo (exatamente como no nginx, não mais que um trabalhador por núcleo da CPU).

Uma vantagem dessa abordagem é que o PM2 recarrega todos os clusters por vez. Voltando ao parágrafo anterior, que falou sobre o tempo de inatividade de 1-2 segundos durante a reinicialização. No modo de cluster, quando você reinicia o servidor, seu aplicativo não terá um milissegundo de tempo de inatividade.
NodeJS é uma boa faca suíça
Agora existe uma situação em que o PHP age como uma linguagem para escrever sites e o Python atua como uma ferramenta para rastrear esses sites. NodeJS é 2 em 1, por um lado é um garfo, por outro é uma colher. Você pode escrever aplicativos e rastreadores da Web rápidos e poderosos no mesmo servidor dentro do mesmo aplicativo. Parece tentador. Mas como isso pode ser percebido, você pergunta? O próprio Google lançou a API oficial do Chromium - Puppeteer. Você pode iniciar o Headless Chrome (um navegador sem uma interface de usuário - Chrome "sem cabeça") e obter o acesso mais amplo possível à API do navegador para rastrear páginas. A maneira mais simples e acessível de trabalhar com o Puppeteer .
Por exemplo, no nosso grupo VKontakte, há uma publicação regular de descontos e ofertas especiais para vários destinos das cidades da CEI. Geramos imagens para postagens no modo automático e, para torná-las bonitas, precisamos de belas imagens. Como não gosto de vincular várias APIs e criar contas em dezenas de sites, escrevi um aplicativo simples que imita um usuário comum com o navegador Google Chrome que percorre o site com imagens de estoque e escolhe aleatoriamente a imagem encontrada pela palavra-chave. Eu costumava usar Python e BeautifulSoup para isso, mas agora isso não é mais necessário. E a principal característica e vantagem do Puppeteer é que você pode facilmente enganar até sites de SPA, porque você tem à sua disposição um navegador completo que entende e executa o código JavaScript nos sites. É dolorosamente simples:
const browser = await puppeteer.launch({headless: true, args:['--no-sandbox']}) const page = (await browser.pages())[0] await page.goto(`https://pixabay.com/photos/search/${imageKeyword}/?cat=buildings&orientation=horizontal`, { waitUntil: 'networkidle0' })
Assim, em três linhas de código, lançamos o navegador e abrimos a página do site com imagens. Agora podemos selecionar um bloco aleatório com a imagem na página e adicionar uma classe a ela, na qual mais tarde poderemos virar da mesma maneira e ir para a página diretamente com a própria imagem para carregamento adicional:
var imagesLength = await page.evaluate(() => { var photos = document.querySelectorAll('.search_results > .item') if(photos.length > 0) { photos[Math.floor(Math.random() * photos.length)].className += ' --anomaly_selected' } return photos.length })
Lembre-se de quanto código seria necessário para escrever isso no PhantomJS (que, aliás, fechou e entrou em estreita colaboração com a equipe de desenvolvimento do Puppeteer). Uma ferramenta tão maravilhosa pode impedir alguém de mudar para o NodeJS?
O NodeJS fornece assincronia fundamental
Isso pode ser considerado uma enorme vantagem do NodeJS e JavaScript, especialmente com o advento do async / wait no ES2017. Ao contrário do PHP, onde qualquer chamada é feita de forma síncrona. Vou dar um exemplo simples. Anteriormente, no mecanismo de pesquisa, as páginas eram geradas no servidor, mas algo precisava ser exibido na página já no cliente usando JavaScript, mas naquele momento o Yandex ainda não era capaz de usar o JavaScript em sites e precisava implementar um mecanismo de captura instantânea (captura instantânea de página) especificamente para ele. usando o Prerender. Os instantâneos foram armazenados em nosso servidor e emitidos para o robô mediante solicitação. O dilema era que essas imagens eram geradas em 3-5 segundos, o que é completamente inaceitável e pode afetar a classificação do site nos resultados da pesquisa. Para resolver esse problema, um algoritmo simples foi inventado: quando o robô solicita alguma página, uma captura instantânea da qual já possuímos, fornecemos apenas a captura instantânea existente, após a qual realizamos a operação para criar uma nova captura instantânea em segundo plano e substituí-la já está disponível. Como foi feito no PHP:
exec('/usr/bin/php ' . __DIR__ . '/snapshot.php -a ' . $affiliation_type . ' -l ' . urlencode($full_uri) . ' > /dev/null 2>/dev/null &');
Nunca faça isso.
No NodeJS, isso pode ser alcançado chamando a função assíncrona:
async function saveSnapshot() { getSnapshot().then((res) => { db.saveSnapshot().then((status) => { if(status.err) console.error(err) }) }) } saveSnapshot()
Em resumo, você não está tentando ignorar o sincronismo, mas decide quando usar a execução de código síncrono e quando usar assíncrono. E é realmente conveniente. Especialmente quando você aprende sobre as possibilidades de Promise.all ()
O próprio mecanismo de pesquisa de vôo é projetado de tal maneira que envia uma solicitação para um segundo servidor que coleta e agrega dados e, em seguida, recorre a ele para obter dados prontos para emissão. As páginas de direção são usadas para atrair tráfego orgânico.
Por exemplo, para a consulta "Voos Moscou São Petersburgo", uma página será emitida com o endereço / tickets / moscow / saint-petersburg / e precisará de dados:
- Preços das companhias aéreas nessa direção para o mês atual
- Preços das companhias aéreas nessa direção para o próximo ano (preço médio para cada mês nos próximos 12 meses)
- Programe voos nessa direção
- Destinos populares da cidade de expedição - de Moscou (para ligação)
- Os destinos populares da cidade de chegada são de São Petersburgo (para vinculação)
No PHP, todos esses pedidos foram executados de forma síncrona - um após o outro. O tempo médio de resposta da API por solicitação é de 150-200 milissegundos. Multiplicamos 200 por 5 e obtemos, em média, um segundo apenas para atender solicitações ao servidor com dados. O NodeJS possui uma excelente função chamada Promise.all , que executa todos os pedidos em paralelo, mas grava o resultado um a um. Por exemplo, o código de execução para todas as cinco solicitações acima ficaria assim:
var [montlyPrices, yearlyPrices, flightsSchedule, originPopulars, destPopulars] = await Promise.all([ getMontlyPrices(), getYearlyPrices(), getFlightSchedule(), getOriginPopulars(), getDestPopulars() ])
E obtemos todos os dados em 200 a 300 milissegundos, reduzindo o tempo de geração de dados da página de 1 a 1,5 segundos para ~ 500 milissegundos.
Conclusão
A mudança do PHP para o NodeJS me ajudou a familiarizar-me com o JavaScript assíncrono, aprender a trabalhar com promessas e assíncrono / aguardar. Depois que o mecanismo foi reescrito, a velocidade de carregamento da página foi otimizada e diferiu drasticamente dos resultados que o mecanismo mostrou em PHP. Neste artigo, também poderíamos falar sobre como os módulos simples são usados para trabalhar com o cache (Redis) e o pg-promessa (PostgreSQL) no NodeJS e compará-los com o Memcached e o php-pgsql, mas este artigo mostrou-se bastante volumoso. E conhecendo meu "talento" para escrever, ela também se mostrou mal estruturada. O objetivo deste artigo é atrair a atenção de desenvolvedores que ainda estão trabalhando com PHP e não estão cientes das delícias do NodeJS e do desenvolvimento de aplicativos baseados na Web usando um exemplo de projeto da vida real que já foi escrito em PHP, mas devido a preferências seu dono foi para outra plataforma.
Espero poder transmitir meus pensamentos e mais ou menos estruturados para expressá-los neste material. Pelo menos eu tentei :)
Escreva qualquer comentário - amigável ou com raiva. Eu responderei a qualquer construtivo.